
基於實數編碼的遺傳算-論文復現(matlab程式碼)
由於應用需要,最近復現了一個尋優效果不過的遺傳演算法,演算法的參考文獻:
[3] Yao-Chen Chuang, Chyi-Tsong Chen, Chyi Hwang,A simple and efficient real-coded genetic algorithm for constrained optimization, Applied Soft Computing, Volume 38,2016,Pages 87-105,ISSN 1568-4946.
論文下載:https://pan.baidu.com/s/14XA1hk_tIgrfb7lgSsAziw
簡單介紹一下演算法操作運算元和流程:由於我的問題的約束是明確的區間,而不是不等式和等式約束,所以適應度函式的計算中沒有用加論文中提到的懲罰函式。
1.選擇運算元:
論文采取的選擇運算元是Ranking Selection, 其原理如下圖所示:

其中0<Pr<1, 表示一個保留的比例,在選擇運算元的操作過程中,首先按照種群中可行解的適應度值,對可行解進行排序。排序後,用種群中前Pr*N個個體代替後Pr*N個個體。(N是種群規模),再將替換後的種群按照適應度值進行排序
2.交叉運算元 (Direct Based crossover, DBX)
將排序選擇後的種群分為A,B兩部分


設定變異概率 ,其中
,
在集合A,B中各選取第i

其中: 是兩個向量的差,按照如下規則計算:

其中 是(0,1)之間的隨機數。
3. 變異運算元:(Dynamic Random Mutation, DRM)
按照如下的規則對種群進行變異操作:
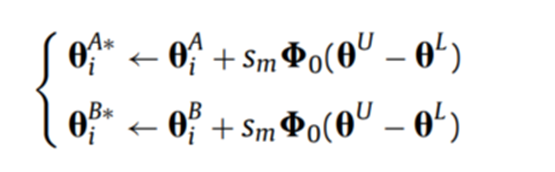
其中: 是一個與
維度相同的隨機向量,向量中的每個元素介於
之間。 其中
sm的計算規則:
按照原論文中的寫法,sm的計算方法如下:
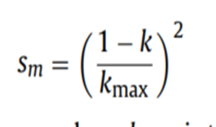
當時個人懷疑這是一種錯誤的寫法,與論文中描述的不一致, 正確的寫法應該是:

種群的變異範圍應該是隨著迭代次數的增加而減小的。所以原文章中的sm計算公式是錯誤的。
後來證實我的懷疑是對的,在作者的另一篇文章中,將上述錯誤的sm的計算公式進行了改正。
演算法的流程:
在傳統的遺傳演算法的基礎上,作者對演算法的結構做了一些調整,無論是對進行了交叉操作還是變異操作的運算元,都執行replacement operation,這樣就能夠對種群中的個體做到擇優保留!
演算法的具體流程如下圖所示:

matlab程式碼:
clc;
clear all;
% 復現論文:[3] Yao-Chen Chuang, Chyi-Tsong Chen, Chyi Hwang,A simple and
% efficient real-coded genetic algorithm for constrained optimization,
% Applied Soft Computing, Volume 38,2016,Pages 87-105,ISSN 1568-4946.
% mode引數可設定為不同的值,選擇不同的測試函式
mode = 'Schaffer';
% mode = 'Rastrigin';
% mode = 'self_define';
% mode = 'Rosenbrock';
if strcmp(mode, 'Schaffer')
figure(1)
x = -4:0.1:4;
y = -4:0.1:4;
[X,Y] = meshgrid(x,y);
% Z = 3*cos(X.*Y)+X+Y.^2;
Z = 0.5-((sin(sqrt(X.^2+Y.^2)).^2)-0.5)./(1+0.001.*(X.^2+Y.^2)).^2;
surf(X,Y,Z);
title('Schaffer Function');
xlabel('X-軸');
ylabel('Y-軸');
zlabel('Z-軸');
figure(2);
contour(X, Y, Z, 8);
title('Schaffer函式等高線');
xlabel('X-軸');
ylabel('Y-軸');
end
if strcmp(mode, 'self_define')
figure(1);
x = -4:0.1:4;
y = -4:0.1:4;
[X,Y] = meshgrid(x,y);
% Z = 100.*(Y-X.^2).^2+(1-X).^2;
Z = (cos(X.^2+Y.^2)-0.1)./(1+0.3*(X.^2+Y.^2).^2)+3;
surf(X,Y,Z);
%title('Rosen Brock valley Function');
title('Self define Function');
xlabel('X-軸');
ylabel('Y-軸');
zlabel('Z-軸');
figure(2);
contour(X, Y, Z, 8);
title('self_define函式等高線');
xlabel('X-軸');
ylabel('Y-軸');
end
if strcmp(mode, 'Rastrigin')
figure(1);
x = -4:0.1:4;
y = -4:0.1:4;
[X,Y] = meshgrid(x,y);
% Z = 100.*(Y-X.^2).^2+(1-X).^2;
%Z = (cos(X.^2+Y.^2)-0.1)./(1+0.3*(X.^2+Y.^2).^2)+3;
Z = -1.*(20+X.^2+Y.^2-10.*(cos(2.*pi.*X)+cos(2.*pi.*Y)));
surf(X,Y,Z);
%title('Rosen Brock valley Function');
title('Rastrigin Function');
xlabel('X-軸');
ylabel('Y-軸');
zlabel('Z-軸');
end
if strcmp(mode, 'Rosenbrock')
figure(1);
x_min = -2.048;
x_max = 2.048;
y_min = -2.048;
y_max = 2.048;
x = x_min:0.1:x_max;
y = y_min:0.1:y_max;
[X, Y] = meshgrid(x, y);
Z = 100.*(Y-X.^2).^2+(1-X).^2;
surf(X, Y, Z);
title('Rosenbrock Function');
xlabel('X-軸');
ylabel('Y-軸');
zlabel('Z-軸');
end
clc;
clearvars -except mode;
NP=100;
Pr = 0.10; % Ranking selection的比例
Pc=0.65; % 將Pc,Pm引數改進為自適應引數
% Pm=0.20;
G=50; % 記得改
D=2; % 變數個數
if strcmp(mode, 'Schaffer')
X_min=-4; % 變數上下界
X_max=4;
Y_min=-4;
Y_max=4;
end
if strcmp(mode, 'Rastrigin')
X_min=-4; % 變數上下界
X_max=4;
Y_min=-4;
Y_max=4;
end
if strcmp(mode, 'self_define')
X_min=-4; % 變數上下界
X_max=4;
Y_min=-4;
Y_max=4;
end
if strcmp(mode, 'Rosenbrock')
X_min=-2.048; % 變數上下界
X_max=2.048;
Y_min=-2.048;
Y_max=2.048;
end
% 產生初始種群x:
for count=1:NP % 產生初始解
temp1 = X_min+rand()*(X_max-X_min);
temp2 = Y_min+rand()*(Y_max-Y_min);
x(count,:) = [temp1,temp2];
end
save_pic_cnt = 1;
A = figure(3);
for gen=1:G
% 計算種群的適應度
pause(0.05);
if rem(gen, 2)==1
scatter(x(:,1), x(:, 2));
bias_axis = 0.5;
axis([X_min-bias_axis, X_max+bias_axis, Y_min-bias_axis, Y_max+bias_axis]);
title(['第', num2str(gen), '次迭代', ' Pr=',num2str(Pr*100), '%', ' NP=', num2str(NP)]);
xlabel('變數X');
ylabel('變數Y');
base_path = 'C:\Users\18811\Desktop\er\rosenbrock\'; % 儲存圖片的路徑
cnt = num2str(save_pic_cnt);
tail_path = '.jpg';
frame = getframe(A);
im=frame2im(frame);
path_img = [base_path, cnt, tail_path];
% imwrite(im, path_img); % 將圖片儲存到設定的路徑中
save_pic_cnt = save_pic_cnt + 1;
end
for count=1:NP
fitness(count)=func(x(count,:), mode);
end
fitness_max = max(fitness); % 適應度最大值
best(gen) = fitness_max; % 每一代的最優個體
fitness_min = min(fitness); % 適應度最小值
[fitness_sorted, index] = sort(fitness, 'descend'); % 對適應度降序排列
x = x(index, :); % 按照適應度值調整種群中個體的位置
proportion = NP*Pr; % Ranking selection中需要替換的個數
x(NP-proportion+1:end, :) = x(1:proportion, :); % 用好的部分解替代壞的解
% 交叉操作:directed-based crossver DBX
group_A = x(1:NP/2, :);
group_B = x(NP/2+1:end, :); % 將種群分為AB兩個群體:
fitness_A = fitness_sorted(1:NP/2);
fitness_B = fitness_sorted(NP/2+1:end); % 將適應度也分為A B
for cross_cnt=1:NP/2
if rand()>Pc % 交叉概率
if all(group_A(cross_cnt, :)==group_B(cross_cnt)) || fitness_A(cross_cnt)==fitness_B(cross_cnt)
% DRM operation
group_A(cross_cnt, :) = Dynamic_random_mutation(group_A(cross_cnt, :), gen, G, X_min, X_max, Y_min, Y_max, mode);
group_B(cross_cnt, :) = Dynamic_random_mutation(group_B(cross_cnt, :), gen, G, X_min, X_max, Y_min, Y_max, mode);
else
for cnt_temp=1:D % 生成方向向量
if rand()>=0.5
D_arrow(1, cnt_temp) = group_A(cross_cnt, cnt_temp) - group_B(cross_cnt, cnt_temp);
else
D_arrow(1, cnt_temp) = 0;
end
end
S_ci = abs(fitness_A(cross_cnt)-fitness_B(cross_cnt))/(fitness_max-fitness_min); % 計算步長
group_A_new(cross_cnt, :) = group_A(cross_cnt, :) + S_ci*D_arrow;
group_B_new(cross_cnt, :) = group_B(cross_cnt, :) + S_ci*D_arrow; % 更新種群AB
% group_A_new 邊界條件檢查
if group_A_new(cross_cnt, 1)>X_max
group_A_new(cross_cnt, 1) = X_max;
end
if group_A_new(cross_cnt, 1)<X_min
group_A_new(cross_cnt, 1) = X_min;
end
if group_A_new(cross_cnt, 2)>Y_max
group_A_new(cross_cnt, 2) = Y_max;
end
if group_A_new(cross_cnt, 2)<Y_min
group_A_new(cross_cnt, 2) = Y_min;
end
% group_B_new 邊界條件檢查
if group_B_new(cross_cnt, 1)>X_max
group_B_new(cross_cnt, 1) = X_max;
end
if group_B_new(cross_cnt, 1)<X_min
group_B_new(cross_cnt, 1) = X_min;
end
if group_B_new(cross_cnt, 2)>Y_max
group_B_new(cross_cnt, 2) = Y_max;
end
if group_B_new(cross_cnt, 2)<Y_min
group_B_new(cross_cnt, 2) = Y_min;
end
% replace operation
if func(group_A_new(cross_cnt, :), mode)>fitness_A(cross_cnt)
group_A(cross_cnt, :) = group_A_new(cross_cnt, :); % replace
disp('DBX replacement');
end
if func(group_B_new(cross_cnt, :), mode)>fitness_B(cross_cnt)
group_B(cross_cnt, :) = group_B_new(cross_cnt, :); % replace
disp('DBX replacement');
end
end
else
% r_i<lambda
% DRM operation
group_A(cross_cnt, :) = Dynamic_random_mutation(group_A(cross_cnt, :), gen, G, X_min, X_max, Y_min, Y_max, mode);
group_B(cross_cnt, :) = Dynamic_random_mutation(group_B(cross_cnt, :), gen, G, X_min, X_max, Y_min, Y_max, mode);
end
end
x = [group_A; group_B]; % AB合併
end
figure(4);
plot(best);
title(['適應度進化曲線', ' Pr=',num2str(Pr*100),'%', ' NP=', num2str(NP)]);
xlabel('迭代次數');
ylabel('適應度值');
function f=func(buf, md)
if strcmp(md, 'Schaffer')
f=0.5-((sin(sqrt(buf(1).^2+buf(2).^2)).^2)-0.5)./(1+0.001.*(buf(1).^2+buf(2).^2)).^2;
end
if strcmp(md,'self_define')
% f = 100*(buf(2)-buf(1).^2).^2+(1-buf(1)).^2;
f = (cos(buf(1).^2+buf(2).^2)-0.1)./(1+0.3*(buf(1).^2+buf(2).^2).^2)+3;
end
if strcmp(md,'Rastrigin')
f = -(20+buf(1)^2+buf(2)^2-10*(cos(2*pi*buf(1))+cos(2*pi*buf(2))));
end
if strcmp(md, 'Rosenbrock')
f = 100*(buf(2)-buf(1)^2)^2+(1-buf(1))^2;
end
end
function individual_new = Dynamic_random_mutation(individual, generation_cnt, gen_max, X_min, X_max, Y_min, Y_max, mode) % 定義變異運算元DRM
theta_U = [X_max, Y_max]; % 解空間的上界
theta_L = [X_min, Y_min]; % 解空間的下界
S_m = (1-generation_cnt/gen_max)^2;
temp = rand();
phi_0 = [-temp, -temp] + rand(1,2).*[2*temp, 2*temp]; % 隨機擾動向量
individual_new = individual + S_m.*phi_0.*(theta_U - theta_L);
% 邊界條件處理
if individual_new(1)<X_min
individual_new(1) = X_min;
end
if individual_new(1)>X_max
individual_new(1) = X_max;
end
if individual_new(2)<Y_min
individual_new(2) = Y_min;
end
if individual_new(2)>Y_max
individual_new(2) = Y_max;
end
% replacement operation
if func(individual_new, mode)<func(individual, mode)
individual_new = individual;
disp('DRM replacement');
end
end
幾個執行結果:
1.Schaffer測試函式

種群分佈:
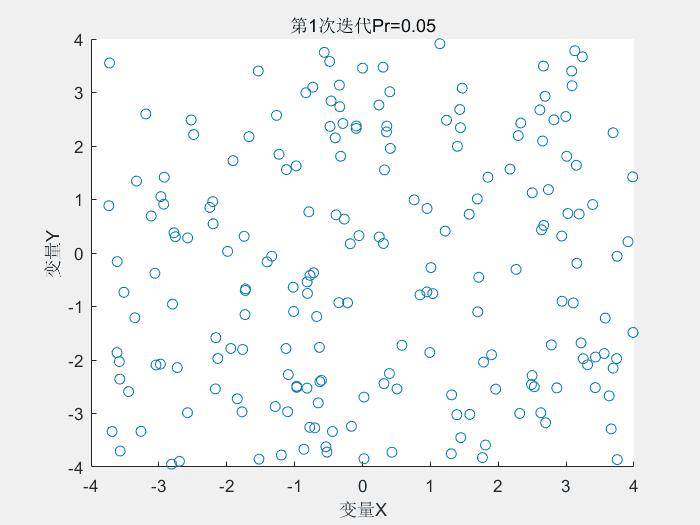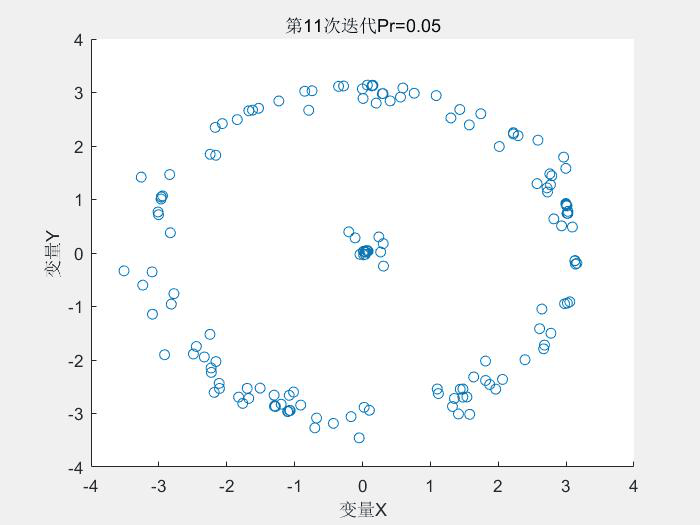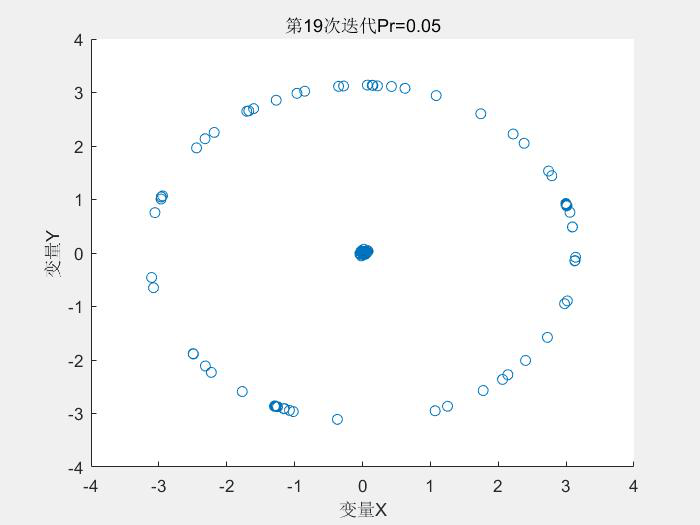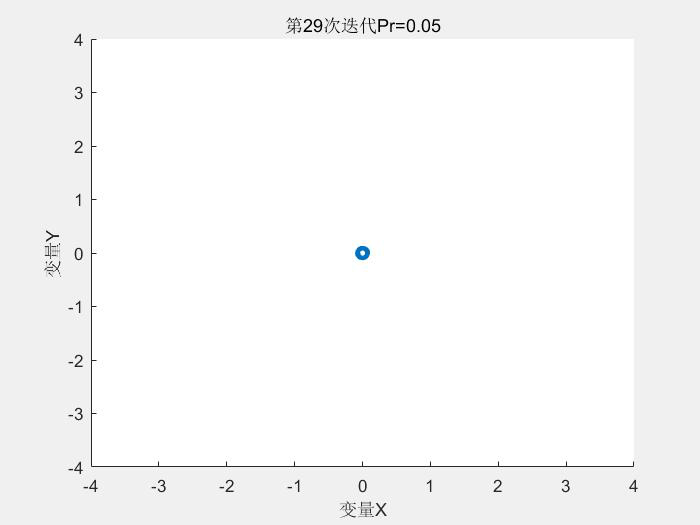

2.Rastrigin測試函式

種群分佈:


可以修改程式碼中的引數,NP的大小,Pr的大小,觀察演算法的收斂情況
-----------------------------------------------分割線--------------------------------------------------------