
Hadoop4 利用VMware搭建自己的hadoop叢集
前言:
前段時間自己學習如何部署偽分散式模式的hadoop環境,之前由於工作比較忙,學習的進度停滯了一段時間,所以今天抽出時間把最近學習的成果和大家分享一下。
本文要介紹的是如何利用VMware搭建自己的hadoop的叢集。如果大家想了解偽分散式的大家以及eclipse中的hadoop程式設計,可以參考我之前的三篇文章。
===============================================================長長的分割線====================================================================
正文:
在之前的hadoop文章中,我主要是介紹了自己初次學習hadoop的過程中是如何將hadoop偽分散式模式部署到linux環境中的,如何自己編譯一個hadoop的eclipse外掛,以及如何在eclipse中搭建hadoop程式設計環境。如果大家有需要的話,可以點選我在前言中列出的前前三篇文章的連結。
閒話少說,言歸正傳,本次的目的是利用VMware搭建一個屬於自己的hadoop叢集。本次我們選擇的是VMware10,具體的安裝步驟大家可以到網上搜索,資源很多。
如果大家再安裝過程中,遇到了我沒有提到的錯誤,可以先參考文章底部列出的三個問題,看看解決方案是不是在其中,如果不在的話,再自行上網搜尋。
第一步,確定目標:
master 192.168.224.100 CentOS
slave1 192.168.224.201 CentOS
slave2 192.168.224.202 CentOS
其中master為nameNode和jobTracker節點,slave1和slave2為dataNode和taskTracker節點。
第二步,配置虛擬網路,在VMware工具欄中點選“編輯”,然後選擇“虛擬網路編輯器”,在彈出框中設定選項;然後點選“NAT設定”,也按照圖片設定,詳細參照如下圖:


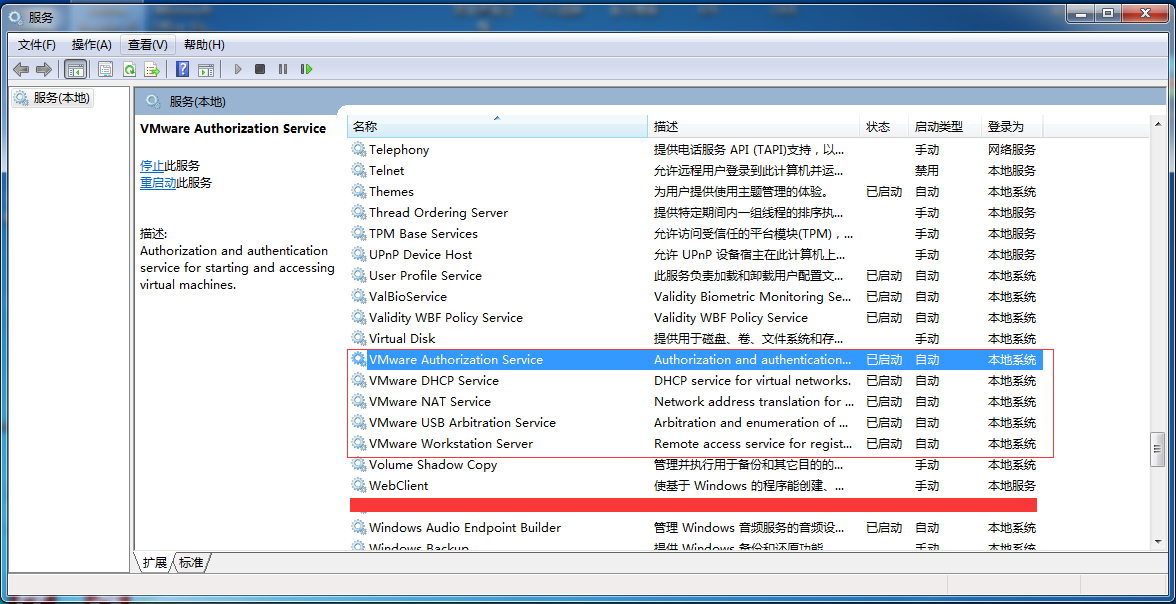
第三步,確認VMware服務都已經啟動,這個很重要,不然對你後邊的操作很有影響的,如下圖:
第五步,經過第四步我們的第一個master虛擬機器已經建立好了,下面針對這臺虛擬機器,進行網路、主機等配置,詳細步驟如下:
(1).關掉SELINUX:vi /etc/selinux/config ,設定SELINUX=disabled,儲存退出,如下圖:

(2).關閉防火牆:/sbin/service iptables stop;chkconfig --level 35 iptables off ;執行完畢後,呼叫 service iptables status,檢視防火牆的狀態,如下圖:

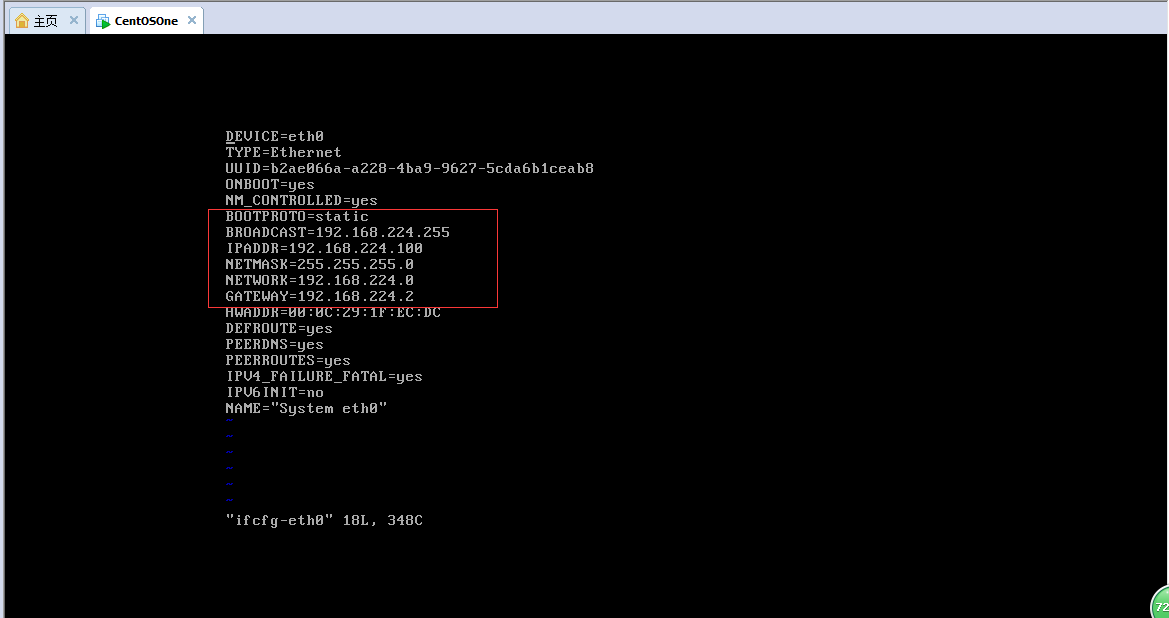
(3).修改IP地址為靜態地址:vi /etc/sysconfig/network-scripts/ifcfg-eth0,將其內容改為如下圖所示,注意HWADDR那一行,你所建立的虛擬機器的值很可能與之不同, 保持原值,不要修改它。
(4).修改主機名稱: vi /etc/sysconfig/network,如下圖:

(5).修改hosts對映:vi /etc/hosts,這裡我們也將slave1和slave2的主機ip對映關係新增上,方便後邊使用,如下圖:

(6).執行service network restart,重新啟動網路,這一步是必須的,請注意。
第七步,安裝putty工具,可以在百度上直接搜尋,下載解壓到自己的目錄即可,我們會用到目錄中的pscp.exe。
第八步,安裝JDK,詳細步驟如下:
(1).我從網上下載的是jdk-6u45-linux-i586.bin,放到了我的如下目錄是D:\SettingUp\ITSettingUp\Java\JDK\JDK1.6(linux32),注意此目錄大家可以根據自己的情 況自行選擇,這裡我把自己的目錄粘出來,是為了後邊方便說明pscp的上傳。
(2).開啟cmd,定位到putty的解壓目錄,呼叫如下命令,如果提示輸入密碼,就輸入虛擬機器中root帳戶的密碼。對於下邊的命令,我們使用的是pscp命令,兩個引數:第一個引數是本地的jdk路徑,後邊的引數是我們的虛擬機器路徑,這裡我提前在虛擬機器上建立了兩個父子資料夾:/myself_settings/jdk1.6
pscp D:\SettingUp\ITSettingUp\Java\JDK\JDK1.6(linux32)\jdk-6u45-linux-i586.bin [email protected]:/myself_settings/jdk1.6
(3).進入虛擬機器jdk的所在目錄/myself_settings/jdk1.6,執行命令: ./jdk-6u45-linux-i586.bin,等待安裝完成。
(4).修改環境變數:vi ~/.bash_profile,在最後新增,如下圖所示:

(5).輸入命令 source ~/.bash_profile 使配置生效,之後可以執行 java -version 判斷jdk是否已經配置成功
第九步,安裝hadoop,詳細步驟如下:
(1).下載hadoop,我從網上下載的是hadoop-1.0.1.tar.gz。放在了我的本機:D:\SettingUp\ITSettingUp\Hadoop\hadoop-1.0
(2).開啟cmd,定位到putty的解壓目錄,呼叫如下命令,如果提示輸入密碼,就輸入虛擬機器中root帳戶的密碼。
(3).進入虛擬機器hadoop所在的目錄/myself_settings/hadoop1.0,呼叫命令: tar -xzvf hadoop-1.0.1.tar.gz 將檔案解壓縮。
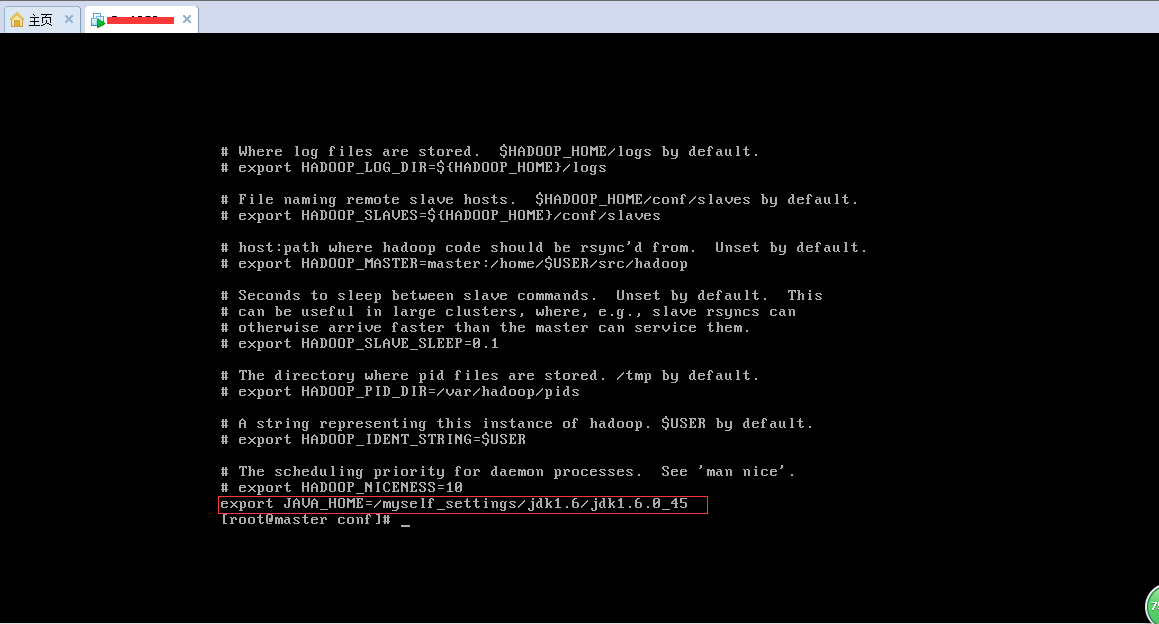
(4).進入(3)中解壓縮後的目錄後,進入到conf資料夾中進行配置,使用命令: vi hadoop-env.sh ,將JAVA_HOME一行的註釋去掉,並改為如下設定:
(5).新增環境變數 vi ~/.bash_profile ,如下圖:

(6).開啟conf檔案: vi core-site.xml, 進行編輯,如下圖:

(7).開啟conf檔案: vi hdfs-site.xml, 進行編輯,如下圖:

(8).開啟conf檔案: vi mapred-site.xml, 進行編輯,如下圖:

(9).開啟conf檔案: vi masters, 進行編輯,如下圖:

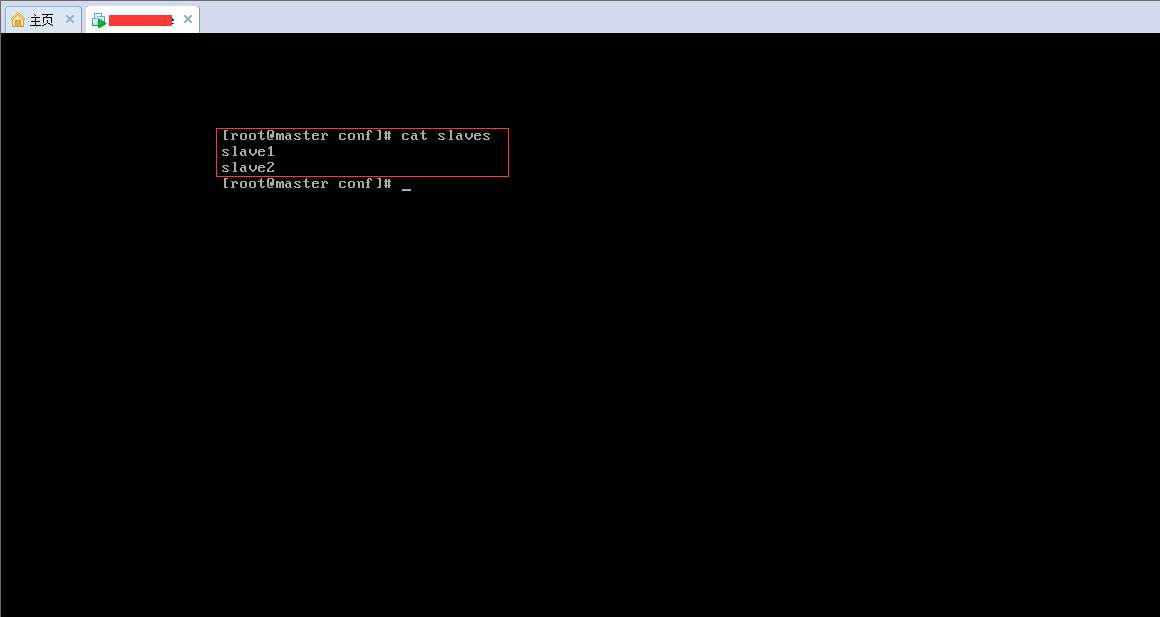
(10).開啟conf檔案: vi slaves, 進行編輯,如下圖:
第十步,經過上述步驟,第一個虛擬機器已經配置完畢了,下邊我們要克隆兩個虛擬機器出來,作為slave1和slave2,詳細步驟如下:
(1).在VMware左側的虛擬機器列表中選中第一個虛擬機器,右鍵選擇“管理”,在“管理”的面板中選擇“克隆”,依次選擇“下一步 ===》 虛擬機器中的當前狀態,下一步 ===》 建立完整克隆,下一步 ===》 設定虛擬機器名稱和安裝目錄 ===》 點選完成”,然後分別在這兩個虛擬機器繼續做如下操作。
(2).執行:rm -f /etc/udev/rules.d/70-persistent-net.rules
(3).執行 reboot 重啟虛擬機器
(4).執行 vi /etc/sysconfig/networking/devices/ifcfg-eth0 將其中的 HWADDR修改為新虛擬機器的網絡卡地址,具體檢視虛擬機器網絡卡地址的方式為: 選中虛擬機器,郵件選擇“設定”,在彈出的面板中按照下圖所示進行設定,如下圖:
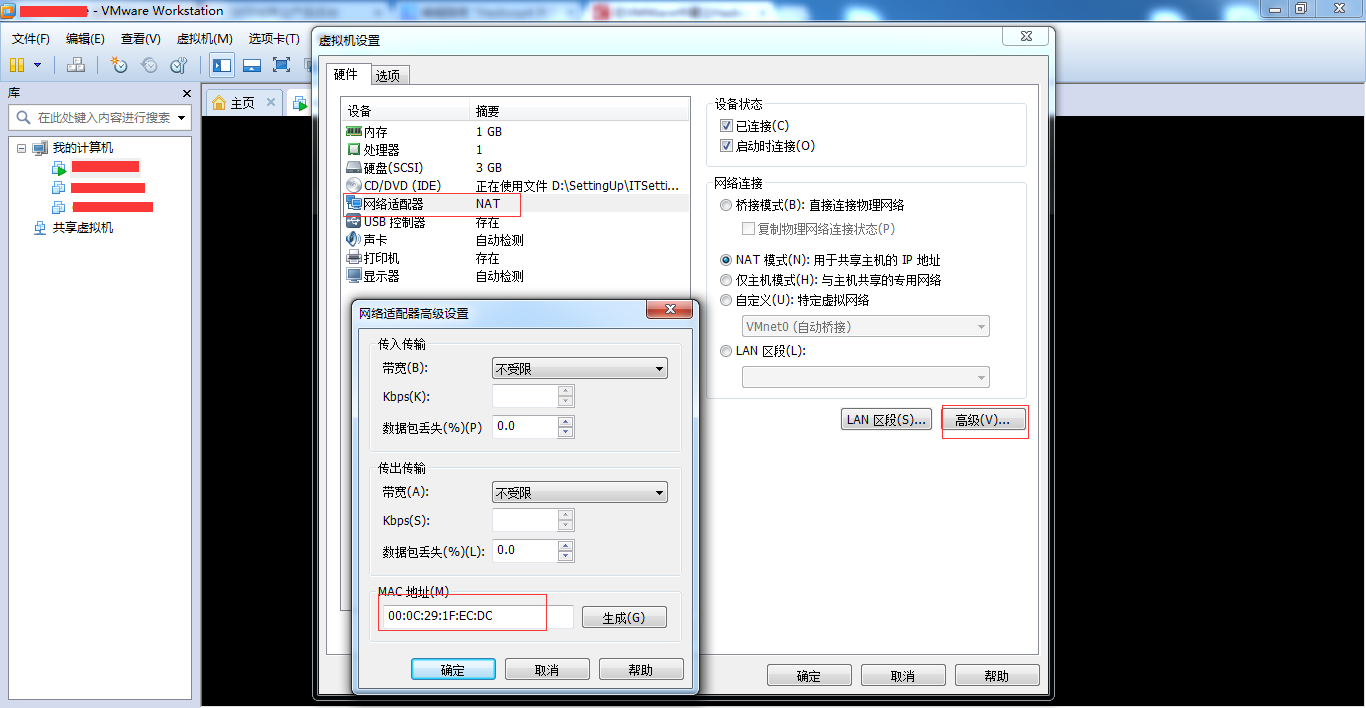
(5).同樣將(4)檔案中將IPADDR改為192.168.224.201(對於slave1)或192.168.224.202(對於slave2)。
(6).修改slave1和slave2的/etc/sysconfig/network檔案,將主機名改為slave1或者slave2
(7).兩臺虛擬機器執行 service network restart 重啟網路
第十一步,經過上述步驟,三臺虛擬機器已經基本配置完畢,但是還有一個重要的步驟,那就是ssh免登陸的配置,這塊我當時出了問題,所以這裡再詳細的說明一下:
備註:由於我第一次搭建的時候這裡出了問題,所以此處當時沒有來得及做記錄,現在為了演示,我重新搭建了兩個虛擬機器,分別是TestOne和TestTwo,我這裡要做的就是從TestOne免登陸到TestTwo。大家以此類推,與我們這個文章中要做的master免登陸 到slave1和slave2是一樣的。
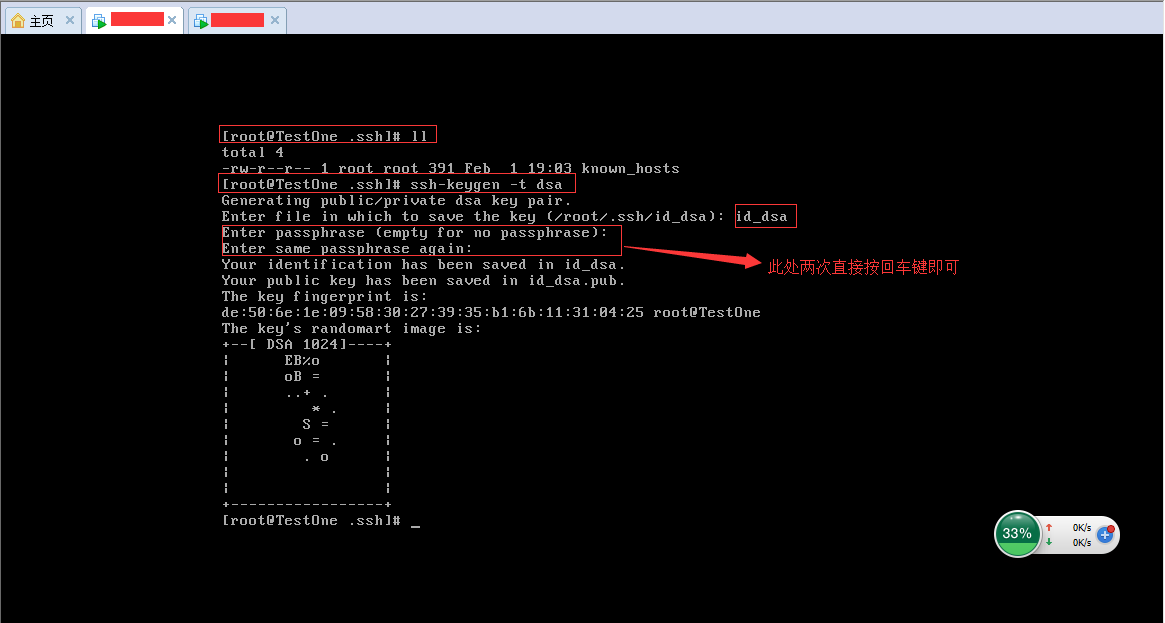
(1).首先在TestOne虛擬機器中,通過 cd ~/.ssh 進入~/.ssh目錄,會看到有一個known_hosts檔案,
(2).在~/.ssh資料夾中,輸入 ssh-keygen -t dsa ,然後會讓你輸入金鑰儲存檔案的名稱,我輸入的是id_dsa。前邊這兩部可以參考下邊的圖片,注意圖片中用紅色矩形框圈中的部分:
(3).在~/.ssh資料夾中輸入 cat id_dsa.pub >> authorized_keys,如下圖所示:

(4).在~/.ssh資料夾中,將剛才生成的金鑰拷貝到TestTwo機器上,輸入命令: scp authorized_keys TestTwo:~/.ssh ,過程中需要輸入TestTwo的密碼,詳細參考下圖,注意圖中用紅色矩形框圈中的部分:

(5).經過上述4步,輸入 ssh TestTwo,應該不需要再輸入TestTwo的登入密碼,就可以從TestOne直接登入到TestTwo了。
第十二步,至此,虛擬機器的配置全部完畢,我們依次執行hadoop namenode -format 、 hadoop datanode -format ,然後在hadoop的安裝目錄下,進入bin目錄,執行如下命令: ./start-all.sh . 然後可以在宿主機中開啟瀏覽器,檢視 192.168.224.100:50070 的內容,如果正常顯示,就說明啟動正常了。注意,這裡也可以分別在master和slaves輸入jps命令驗證是否啟動成功,如下圖:


經過上邊的十二步,我相信屬於你自己的hadoop叢集已經大家成功了,後邊你可以參考我文章開頭列出的文章,在eclipse中新增自己的DFS Location,指向我們的叢集。在上述這個過程中,你有可能遇到一些問題,可以參考下邊我列出的文章:
1.在eclipse中訪問hadoop叢集時出現 org.apache.hadoop.security.AccessControlException: Permission denied: user=DrWho, access=WRITE 這個錯誤,參考如下:
2.啟動hadoop時有這樣的提示 Warning: $HADOOP_HOME is deprecated. 這個不會影響使用,如果想解決的話,參考如下:
3. 如果在設定完網路,呼叫service network restart時,出現Device eth0 does not seem to be present這個問題,參考如下:
解決方案:重新開啟vi /etc/sysconfig/network-scripts/ifcfg-eth0,將其中的DEVICE的值改為eth1或者別的,然後重啟網路,應該就不會報錯了。
相關推薦
Hadoop4 利用VMware搭建自己的hadoop叢集
前言: 前段時間自己學習如何部署偽分散式模式的hadoop環境,之前由於工作比較忙,學習的進度停滯了一段時間,所以今天抽出時間把最近學習的成果和大家分享一下。 本文要介紹的是如何利用VMware搭建自己的hadoop的叢集。如果大家想了解偽分散式的大家以及eclipse中的hado
利用vultr搭建自己的服務器,附帶ss搭建哦!!!
設置 rtu 網絡數 瀏覽器 命令 運行 12個 信用 sof 眾所周知,我國因為某些原因查閱瀏覽不到一些國外的資料及內容,這給我們的學習工作帶來了很大的不便。所以怎樣才能跨越這個障礙呢?這就需要VPS(Virtual Private Server 虛擬專用服務器)的幫
模仿spring-aop的功能,利用註解搭建自己的框架。
屬性 def name rac java8 out fault 一個 lte 入JAVA坑7月有余,也嘗試自己手動搭建框架,最近對spring aop的這種切面很著迷,為此記錄下自己目前搭出來的小小的demo,後續有時間也會繼續改進自己的demo。望大神們不吝賜教。 主
利用Github搭建自己的博客
tps 利用 網頁 coder ebs targe them 教程 文件 教程鏈接:搭建個人博客 嘿嘿嘿!!一直想自己搭建博客的,一直沒機會,這次終於把博客搭了起來。雖然只是一個殼子。。套了別人的模板~不過還是很令人興奮喲!總的來說,就按照這個教程一直往下走,其中有一
利用bmob搭建自己的app升級服務
由於是個人非盈利app,沒有去開發獨立的升級後臺。最初用的umeng的升級服務,不能用以後,用過百度升級,騰訊升級,360升級,但是在上傳各個平臺時,都受到了限制,主要體現在檢測到集成了競爭對手的升級服務,就限制app的上架及版本更新。後來發現bmob有這一服務,就集成了進來。
用虛擬機器簡單搭建一個hadoop叢集(Linux)
一,前提 1. 安裝好一臺Linux的虛擬機器(我用的純粹的黑框框) 2. 修改好IP地址並安裝jdk (我這裡安裝的是1.8版本的) vi /etc/sysconfig/network-scripts/ifcfg-eth0 重啟網路生效 s
從零搭建生產Hadoop叢集(七)——關鍵伺服器雙網絡卡配置
一、概述 Hadoop叢集中,有許多伺服器部署著關鍵例項,如NameNode、ResourceManager、Zookeeper等,這些服務的穩定執行對叢集健康具有重要意義。雖然這些服務基本上都會做多例項高可用部署,但是若連線的是同個交換機,萬一交換機發生故障
從零搭建生產Hadoop叢集(八)——上線與下線資料節點流程
一、概述 Hadoop叢集中,經常需要在不重啟叢集的前提下,動態地上線與下線資料節點,而使用Cloudera Manager管理的叢集,可以很方便地做到這一點,本文將介紹其相關流程。 二、節點上線流程 1. 伺服器初始化 新節點的硬體配置最好能夠跟原叢集伺服器
利用docker搭建自己的gitlab
1.下載映象檔案(建議虛擬機器的記憶體在2g以上) docker pull beginor/gitlab-ce:11.0.1-ce.0 2.建立GitLab 的配置 (etc) 、 日誌 (log) 、資料 (data) 放到容器之外, 便於日後升級, 因此請先準備這三個目錄(使用者掛載配置
如何使用git將程式碼上傳至githup?以及如何利用github搭建自己的個人網站?
這裡是修真院前端小課堂,每篇分享文從 【背景介紹】【知識剖析】【常見問題】【解決方案】【編碼實戰】【擴充套件思考】【更多討論】【參考文獻】 八個方面深度解析前端知識/技能,本篇分享的是: 【 如何使用git將程式碼上傳至githup?以及如何利用github搭建自己的個人網站?】
從零搭建生產Hadoop叢集(三)——CDH叢集搭建
一、概述 繼本系列前兩篇文章講到的離線安裝YUM源搭建及規劃與環境準備,本文開始講述CDH叢集的搭建步驟及注意要點。本文基於CentOS7進行部署,Cloudera Manager版本選擇5.8.1,CDH版本5.8.0。 二、硬體檢查與系統配置 1.硬體檢查
利用Docker搭建MongoDB副本叢集
步驟如下(1master,2slave為例): 先拉取mongod映象 啟動三個mongo容器: sudo docker run –name mongo_server1 -p 21117:27017 -d 127.0.0.1:5000/mongod:la
利用Azure搭建自己的個人網站 ————ONE
筆者最近得到了微軟的Azure的每月1200港幣的免費信用額度,故想利用這個信用額度來做些什麼。 最先想到額是利用微軟開設在美國東部的雲伺服器搭建了一個科學上網的基於Linux的虛擬機器,通過遠端埠訪問來連線到國際網際網路。 在做完這個之後,還有近800的額
使用docker搭建彈性hadoop叢集
一.ubuntu環境(ubuntu server 16.04): 1.安裝docker: apt install docker-io 2.在docker容器中安裝ubuntu環境: 2.1 修改(不是必須的): vim /etc/default/docker 在最後新增以下
簡單瞭解一下K8S,並搭建自己的叢集
距離上次更新已經有一個月了,主要是最近工作上的變動有點頻繁,現在才暫時穩定下來。這篇部落格的本意是帶大家從零開始搭建K8S叢集的。但是我後面一想,如果是我看了這篇文章,會收穫什麼?就是跟著步驟一步一走嗎?是我的話我會選擇拒絕,所以我加了關於K8S的簡單介紹,每一步的步驟都添加了解釋。由於篇幅和時間原因,我只介
使用VMware搭建Hadoop叢集虛擬網路配置
使用NET模式,DNS地址就配置成閘道器的地址 NET虛擬網路配置 1、開啟VMware虛擬網路編輯器 編輯-->虛擬網路編輯器-->VMnet8-->更改設定 2、配置主機網路地址 &nb
VMware搭建Hadoop偽叢集
經過上一步,虛擬機器已經建立好了,接下來就是虛擬機器的配置和軟體的安裝了 1.修改虛擬閘道器地址 2.關掉SELINUX vi /etc/selinux/config ,設定SELINUX=disabled,儲存退出 3.關閉防火牆 sudo systemctl
利用虛擬機器搭建hadoop叢集
概述 在搭建hadoop叢集時,主要參考了網上的幾篇部落格,但也遇到一些問題。 點選原文 問題一:core-site.xml檔案中的錯誤 <property> <name>hadoop.tmp.dir</name>
VMware 下Hadoop叢集環境搭建之虛擬機器克隆,Hadoop環境配置
在上一篇我們完成了ContOS網路配置以及JDK的安裝,這一篇將在上一篇的基礎上繼續講解虛擬機器的克隆,hadoop環境搭建 虛擬機器克隆. 利用上一篇已經完成網路配置和jdk安裝的虛擬機器在克隆兩臺虛擬機器. 1. 將擬機hadoop01關機.
VMware虛擬機器中搭建Hadoop叢集
1、下載的軟體: VMware Workstation Ubuntu SUN-JDK Hadoop,可到官網下載 2、安裝 VMwareWorkstation 虛擬機器,並建立 Master 虛擬主機(記住,先是建立一個虛擬機器,然後在這個基礎上進行clone,