
關於使用者畫像產品構建和應用的幾點經驗
https://zhuanlan.zhihu.com/p/27329292
貝聊是一款提供給幼兒園使用的APP,兼具“工具屬性”、“社交屬性”和“資源屬性”,主要的使用者構成是家長和老師。APP裡面除了常見的工具屬性功能外,還有類似於微信朋友圈的動態釋出功能,也有類似於小米論壇的貝聊社群討論模組,更有類似於慕課網的孩子學習課程資源平臺,等等;所以貝聊的資料物件、資料主題、資料型別、資料維度和資料關係都十分豐富,面對資料應用業務場景也很多。這種背景下,如何串聯起來各種應用場景、如何找到資料應用中心環節、如何構建彈性的資料產品體系、如何滿足業務靈活多變的資料需求,等等問題立馬就凸顯出來,十分尖銳。以一系列的畫像產品為核心,構建育兒大資料生態體系,串聯各類資料應用場景,是貝聊大資料提出的解決方案之一!
同時,因為貝聊使用者高活躍度的特點,所以使用者行為資料的增長几乎呈指數化上升,目前每月的高價值使用者行為資料規模增長量已是TB級。這些資料的積累為畫像產品的構建打下了重要基礎,也是畫像產品可行性論證的重要指標(資料規模、資料顆粒度、資料頻率、資料價值、資料有效性……)。
在這裡,我們暫不分享具體的技術細節(留給後面幾期文章),只跟大家聊一聊畫像產品的構建思路、組成架構、應用方案和一些值得注意的事項,拋磚引玉!這些都是偏向於巨集觀的東西,但如果理不清這些東西,這個畫像產品是無法構建好的,畢竟業內尚未有公開的成體系的成熟、權威方案,各家各路都在探索。
畫像產品體系包括使用者畫像、內容畫像、訊息畫像等等各個子畫像,不同物件就有不同的畫像,此文主要以使用者畫像為案例展開介紹,部分地方也會涉及到一些其他畫像。
一、 追本溯源,應用為王
畫像產品的構建好不好、全不全、彈性夠不夠,很多時候不是技術問題;關鍵就在於一開始應用的場景有沒有想好、想全、想細,其次就是對自家資料的價值剖析對不對。不同的應用思路,就會有不同的畫像產品形態;不同的資料價值,就決定了畫像產品能實現到什麼程度。提前想好這些,就會有前瞻性,畫像產品體系後期的整合就更有利,開發過程的節奏就更合理。
就貝聊來說,畫像產品的應用,主要聚焦在以下幾方面:
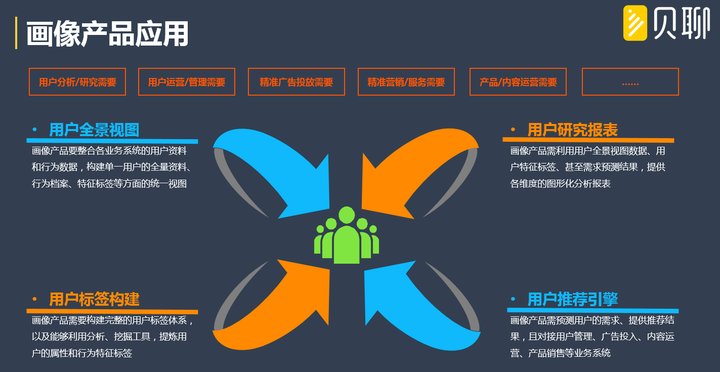
1、 使用者分析/研究需要:
畫像產品需要提供單一使用者全景檢視,滿足單一使用者的行為細緻分析、使用者調研、發燒友使用習慣研究、活動籌備等方面需要;同時,需要提供使用者行為分析、使用者特徵洞察、使用者規模分析等系列報表,方便業務及時監控使用者數量變化、使用者行為變化、使用者特徵表現等等。
2、 使用者運營和管理需要:
畫像產品需要提供使用者特徵標籤、使用者群體細分、使用者需求預測等方面結果,支撐使用者分層管理、使用者社群管理、使用者精細運營,甚至使用者個性化運營等各類使用者管理和運營業務需要。
3、 精準廣告投放需要:
畫像產品需要結合使用者全景檢視、使用者標籤結果、推薦結果等各方面資料,提供一套能快速查詢、精準篩選的DSP廣告投放工具,支援商業部門靈活、精準廣告投放需要。
4、 精準營銷/服務需要:
畫像產品的使用者全景檢視梳理是行為預警功能的基礎,方便服務型別的業務能根據使用者的行為變化,及時提供貼心周到的使用者關懷、挽留、激勵服務需要;同時使用者的標籤構建,需要覆蓋使用者的各類偏好、使用者的所屬地區等等,方能為公司的使用者獲取、營銷策劃提供支援。
5、 產品/內容運營需要:
畫像產品需要提供諸如課程推薦、商品推薦、帖子推薦等個性化預測結果,以清單方式,提供給產品、內容運營團隊直接應用。
從應用訴求出發,提煉畫像產品的主要功能更加到位和實用,總的來說至少要有:使用者全景檢視、使用者研究報表、使用者特徵標籤、使用者推薦引擎等等!
二、 產品功能,各自為政
畫像產品的主要組成模組比較多(如下圖),每一個模組都有很多的子功能,涉及的資料鏈路比較長,相互間依賴關係比較複雜。要保證畫像產品的穩定性,必須提前規劃好主要功能模組,做到各模組之間儘可能的各自為政,以免出現“一步錯、步步錯”或者“一著不慎、滿盤重構”的不利局面。
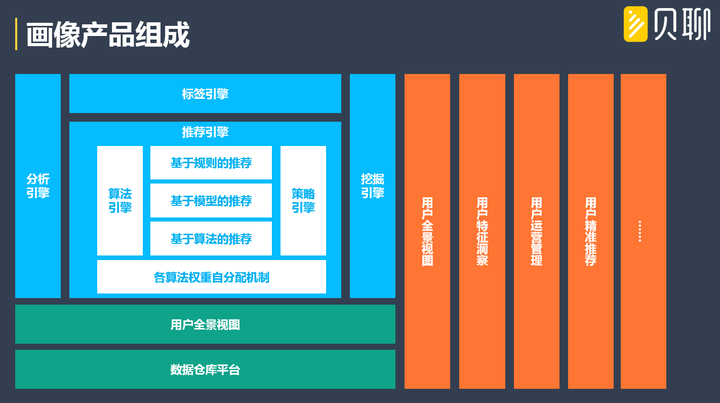
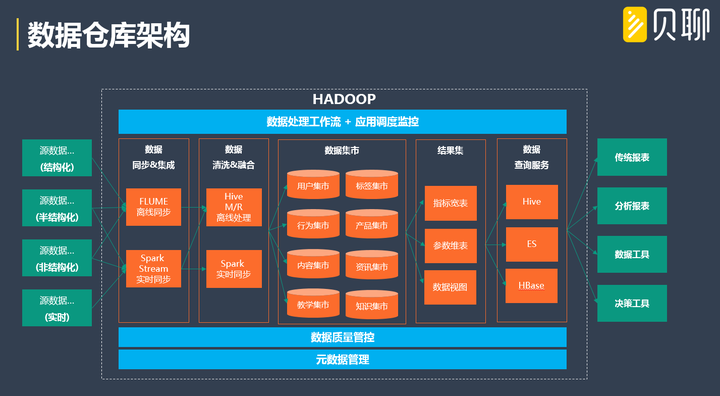
1、 資料倉庫:
畫像產品的資料覆蓋面非常廣,資料計算任務非常多,幾乎聚攏了業務系統的所有資料。做畫像產品前,必須構建統一的資料倉庫,對資料集市按物件、主題、型別進行切分,提高後續鏈條的資料查詢、資料計算、資料儲存等效率。
經驗來說,畫像產品構建初期,資料倉庫也會進行幾次的重構才能最終穩定下來,主要是因為業務的快速變化引發資料主題的變化造成的;所以其他模組要做到彈性相容,以免資料底層重構,所有模組都要重構。
2、 使用者全景檢視:
資料倉庫構建後的使用者全景檢視的構建,技術上來說幾乎沒有難度,需要注意的地方是使用者全景檢視的構建不單單是使用者的個人資訊、使用者的行為明細資料,還會包括使用者標籤的識別結果、使用者的推薦結果等等。同時,如果公司有明顯型別區分的使用者時候,使用者全景檢視是很難統一的,建議區別構建,會有意想不到的好處;例如貝聊就有家長、寶寶、老師、幼兒園等使用者物件,不同物件的行為和標籤等資料差異很大,全景檢視展示也無法統一;切開做後,再關聯,複雜度快速下降,實效很多。
另一個相對麻煩少許的地方就是使用者規模上去後、使用者行為資料沉澱量很大的情況下,允許的查詢方式和查詢條件又很多,資料查詢速度會比較慢。技術可選方案很多,各有利弊,這裡不做詳述!
3、 標籤引擎構建:
使用者標籤是使用者畫像產品的核心組成部分,應用最靈活、應用面最廣、應用頻率最高。構建標籤引擎前,標籤體系的構建必須要確定清楚,並且要儘可能的設計好,否則以後應用起來很麻煩,重構成本也非常大。
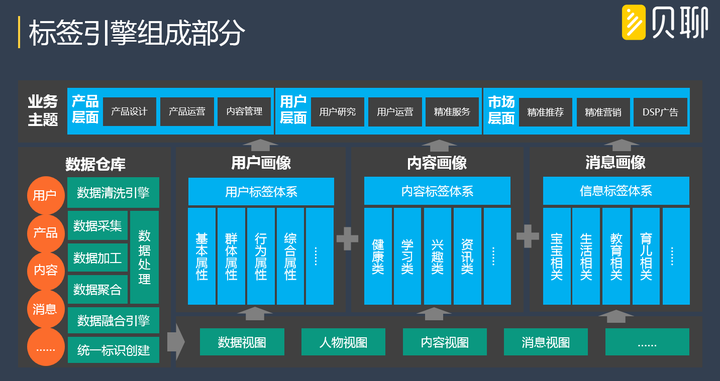
上圖是貝聊的標籤體系劃分,不同的物件有不同的標籤分類體系(裡面還會分子目錄),例如使用者畫像:基本屬性主要囊括使用者個人資訊方面的出來的標籤(如:地理、性別);群體屬性主要囊括使用者在群體細分方面出來的標籤(例如大V、話題製造者);行為屬性主要囊括使用者在行為表現和偏好方面的標籤(例如愛點贊、愛發圖);綜合屬性主要囊括使用者在多方綜合後得出的標籤(例如生命週期、使用者價值)。以貝聊的實踐經驗,群體細分時候,千萬不要僵化思考,作繭自縛,不同的細分方向就會有不同的群體型別標籤出來,所以會有很多群體型別標籤!
關於使用者標籤的具體識別,目前很多公司經常喜歡利用資料探勘模型進行識別(顯得高大上?),其實不然,有時費時費力效果還不好。使用者標籤的妙處就在於輕量化應用,像便籤一樣,隨手可用,生命週期不長、靈活度高、覆蓋面廣、容易理解、實用效率高才是重要的。僅僅依賴資料探勘模型構(如,聚類演算法)建出來的標籤很難滿足現實需要,目前貝聊構建的使用者標籤已有幾百個,還在持續增加,下面談談貝聊的標籤識別經驗:
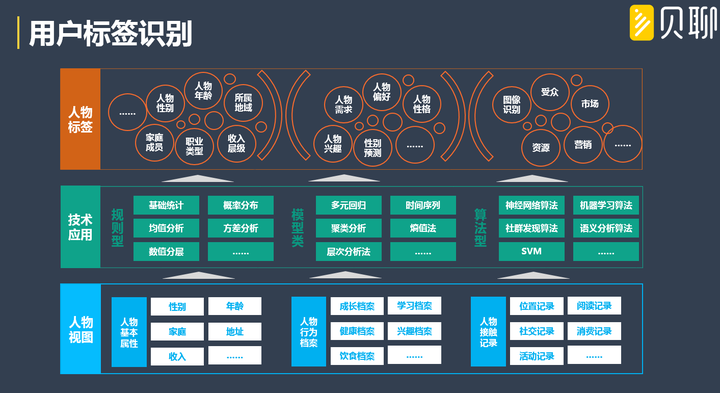
1) 基於規則型的人物特徵標籤識別技術
這類方法識別的標籤應該是最多的!主要應用於較為直觀或有清晰業務規則的人物標籤,例如地域所屬、家庭型別、年齡層等等。技術特點是直接有效靈活、計算複雜度低和可解釋度高,單個標籤涉及到的規則條件一般不超過3條,使用到的技術知識主要是數理統計類知識,例如基礎統計、數值分層、概率分佈、均值分析、方差分析等等。
2) 基於模型類的人物特徵標籤識別技術
主要應用於通過簡單的規則條件之間組合無法有效識別的人物標籤,但是識別出來的標籤價值非常大,一般作為基礎應用型別標籤,標籤的生命週期很長,例如行為偏好、性別預測、群體細分等等。
基於模型類的標籤技術特點是綜合程度高、複雜程度高;絕大部分標籤需要先有針對性地構建相應的挖掘指標體系,依託經典數學演算法或模型進行多指標間的綜合計算方能得到特徵標籤,常常需要多種演算法一起組合來建模。其中涉及到的經典演算法技術主要有熵值法、層次分析法(處理模型權重問題),聚類分析等(處理分類和歸集問題),迴歸分析、時間序列等(處理預測等問題),等等。
3) 基於演算法型的人物特徵標籤識別技術
主要應用於特定類場景或特定類資料的人物標籤識別。例如應用卷積神經網路和機器學習演算法技術對孩子在幼兒園的活動參與圖片進行識別,判斷圖片中幼兒周圍的同伴數量,以此推斷幼兒的社交活躍情況和性格(例如:活躍型、孤僻型等等)。
基於專類演算法的標籤技術特點是專業性強、針對性強、聚焦度高,部分場景下能批量輸出一系列的人物標籤。其中涉及到的專業技術主要有影象識別技術、音視訊分析技術、文字分析技術等等,演算法層主要有神經網路、機器學習、社群發現演算法、語義分析演算法等等。
4、 推薦引擎構建:
目前業內已經有很多的推薦演算法在應用,效果參差不齊,作者認為最大的問題在於很多人過度依賴演算法解決問題,試圖用一套演算法解決所有推薦問題,而不是把推薦當做一套引擎(或系統)來做。每一套演算法背後都有一套推薦思想和邏輯在驅動,例如協同過濾演算法背後的思想就是物以類聚或人以群分。但是每個演算法都有自己的適用領域,只能解決自己領域內的推薦問題,例如很多推薦演算法都存在冷啟動問題(新使用者沒有資料怎麼推薦?),這是沒法調和的,所以強行適用就造成了一種尷尬,推薦的還沒有猜的準。
要想推薦的準,我們必須放開思路,從多演算法組合的思路出發,各自演算法解決各自領域問題。以貝聊的實踐經驗來看,推薦的思想就是“演算法組合+策略組合”,這套思想非常靈活,原理上演算法和策略都可以無限載入和刪除。
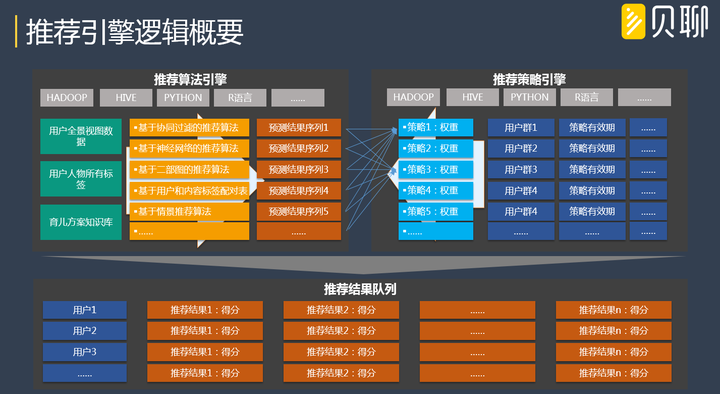
1) 推薦演算法引擎
主要容載各個推薦演算法,每個推薦演算法輸出自己的推薦結果以及得分;每個演算法聚焦自己推薦問題領域的結果準確性,有些是解決新使用者推薦問題的,有些是解決特殊場景推薦問題的,有些是解決業務依賴推薦問題的,不一一詳述,以作者的經驗,一般推薦組合中會有一套演算法是重磅的、作為演算法組合的母機!
推薦演算法組合,關鍵要點是要解決好各演算法推薦結果的得分量級一致性,意思是各演算法的推薦結果得分要有可對比性,這個不難,不做詳述。
2) 推薦策略引擎
主要容載各個推薦策略,需要區分不同的使用者群體,每個群體適用不同的演算法(通過權重分配),群體的劃分,可以通過使用者標籤來指定(可以通過開發一個工具,打通策略引擎和標籤引擎,進行快速配置推薦策略)。每條策略一定要有效期,否則無法進行策略的生命週期管理,有些策略生命週期很短的,例如節日期間的推薦策略,一般只適用這個節日前、中兩個階段,過了就要過期了。
3) 演算法權重自分配機制
對具體使用者來說,每條策略的各演算法組合的權重是不同的,可以在配置策略的時候根據經驗主觀敲定,這種方法不利的地方,是無法及時有效的跟隨使用者的行為和需求變化(人是善變的!),作者偏好採用權重自分配調節機制。
作者的實踐經驗是,可以根據推薦的效果進行權重的自調節,例如新聞推薦:如果使用者對演算法組合中的一個演算法的推薦結果不感冒(點選率低),則這個演算法分配的權重自動降低一點(分配到效果好的演算法上面去),經過一段時間後,該使用者的推薦策略的演算法權重分配就會穩定下來,並且可以自動化動態調整(跟隨使用者行為變化而變化),不用人為干預!
以上這些是貝聊構建畫像產品主要模組實踐過程中積累的一點小小的經驗,權當拋磚引玉,跟大家一起交流和討論!
相關推薦
關於使用者畫像產品構建和應用的幾點經驗
https://zhuanlan.zhihu.com/p/27329292 貝聊是一款提供給幼兒園使用的APP,兼具“工具屬性”、“社交屬性”和“資源屬性”,主要的使用者構成是家長和老師。APP裡面除了常見的工具屬性功能外,還有類似於微信朋友圈的動態釋出功能,也有類似於小米論壇的貝聊社群討論模組,更有類似於
fork()和printf()幾點註意細節
無緩沖 types 強制 pac for 定向 解答 來看 () 分兩點說吧:1.fork()函數會把它所在語句以後的語句復制到一個子進程裏,單獨執行。2.如果printf函數最後沒有"\n",則輸出緩沖區不會被立即清空,而fork函數會把輸出緩沖區裏的內容也都復制到子進程
想轉行做產品經理?這幾點你必須瞭解
近年來,隨著中國網際網路行業的深耕發展,產品經理在整體市場中的需求大坡度上升。然而,在大規模需求下,從業者的聚堆紮根也越發明顯。在各行業資訊化的大趨勢下,不管專業方向思維快慢,都想舔舐時代甜頭,最終,轉行做產品的越來越多,切入點也越發難找。 換工作的驅動力基本上來自
Trie樹的構建和應用
Trie樹又叫“字典樹”,是一種在字串計算中極為常見的資料結構。在介紹Trie樹的具體結構之前,我們首先要搞明白的就是Trie樹究竟是用來解決哪一類問題的,為什麼這類問題可以用Trie樹高效的解決。 我們為什麼用Trie樹 1. 節約字串的儲存空間
優化查詢速度的幾點經驗
根據個人工作經驗,歸納出幾點優化查詢資料的幾點簡單的思路,供大家參考,資料庫為mysql,開發框架為Spring+SpringMVC+hibernate。 一.合理使用索引 為經常作為查詢條件的欄位新增建立一個數據庫索引,建立資料庫索引的語句為:cr
關於C語言中用Keil軟體製作Lib庫檔案的幾點經驗(.lib庫檔案可以讓源函式封裝保密,仍可呼叫)
1.關於制止LIB庫檔案的幾點經驗 1. 一個工程如何生成lib檔案: 2. 一個生成lib檔案的工程可以呼叫這個工程中不存在的函式,只需要在.h檔案中宣告這些不存在函式的原型,然後在呼叫這個lib檔案的工程中實現這些函式即可。 3. 由上面一點
爬蟲入坑到資料分析 ,自學Python的幾點經驗分享
很多小夥伴入坑Python都是從爬蟲開始的,在簡單瞭解 HTTP 協議、網頁基礎知識和一些爬蟲庫之後,爬取一般的靜態網站根本不在話下。 寫幾十行程式碼便能實現表情包爬取 我也是從爬蟲開始,輕鬆爬取資料讓我感到快樂,但我逐漸意識到,爬取資料僅僅只是第一步,對資料進行分析才是重點。作為一名資料分析師,我的
爬蟲入坑到數據分析 ,自學Python的幾點經驗分享
ESS pytho png 最好的 開始學習 ado 人氣 簡單 交流 很多小夥伴入坑Python都是從爬蟲開始的,在簡單了解 HTTP 協議、網頁基礎知識和一些爬蟲庫之後,爬取一般的靜態網站根本不在話下。 寫幾十行代碼便能實現表情包爬取 我也是從爬蟲開始,輕松爬取數據讓
【自省】學習程式設計的幾點經驗教訓
1. 講究效率,切勿把筆記變手賬 可以記筆記,但只需記重點,莫要把筆記程式設計手掌。掌握學習內容後不會翻詳細美麗筆記的,搜尋引擎就夠了。筆記起到鞏固記憶的作用就行了。 2. 選擇合適的教程,感覺沒有收穫就及時換教程 不要相信大眾推薦的優質教程,發現不合適
Shell中的${}、##和%%幾點說明
shel %% ##假設我們定義了一個變量為:復制代碼 代碼如下:file=/dir1/dir2/dir3/my.file.txt可以用${ }分別替換得到不同的值:復制代碼 代碼如下: ${file#*/}:刪掉第一個 / 及其左邊的字符串:dir1/dir2/dir3/my.file.txt ${file
優化Webpack構建性能的幾點建議
webpackWebpack 作為目前最流行的前端構建工具之一,在 vue/react 等 Framework 的生態圈中都占據重要地位。在開發現代 Web 應用的過程中,Webpack 和我們的開發過程和發布過程都息息相關,如何改善 Webpack 構建打包的性能也關系到我們開發和發布部署的效率。以下是一些
ES6---擴展運算符和rest‘...’(三點運算符),在數組、函數、set/map等中的應用
數組集合 發揮 通過 一起 數量 ... XML 參數 運算符和 ES6新增的三點運算符,是由三個點表示,在數組中扮演著重要的角色,可以對數組進行合並與分解、可以對set等數據結構進行轉換、可以對函數參數進行簡化表示,接下來,我們一起揭開其神秘面紗… ●三點—r
堆和棧的主要區別由以下幾點:
C/C++1、管理方式不同;2、空間大小不同;3、能否產生碎片不同;4、生長方向不同;5、分配方式不同;6、分配效率不同;管理方式:對於棧來講,是由編譯器自動管理,無需我們手工控制;對於堆來說,釋放工作由程序員控制,容易產生memory leak(內存泄漏)。空間大小:一般來講在32位系統下,堆內存可以達到4
用ASP.NET Core MVC 和 EF Core 構建Web應用 (二)
work nal nta 多個 包括 catch web 應用 自動 選項卡 本節學習如何執行基本的 CRUD (創建、 讀取、 更新、 刪除) 操作。 自定義“詳細信息”頁 學生索引頁的基架代碼省略了 Enrollments 屬性,因為該屬性包含一個集合。 在“詳細信息”
用ASP.NET Core MVC 和 EF Core 構建Web應用 (九)
fix pro school time lap namespace 繼承映射 數據庫表 eas 在上一節中,已經處理了並發異常。 本節將演示如何在數據模型中實現繼承。 在面向對象的編程中,可以使用繼承以便於重用代碼。 在本教程中,將更改 Instructor和 Studen
用ASP.NET Core MVC 和 EF Core 構建Web應用 (十)
pan 信息 expr dispose writing AS das ech 任務欄 之前的學習中,已經以每個類一張表的方式實現了繼承。 本節將會介紹在掌握開發基礎 ASP.NET Core web 應用程序之後使用 Entity Framework Core 開發時需要註
泛型和列舉類幾點筆記
物件的儲存:1、陣列(基本資料型別&引用資料型別)2、集合(引用資料型別) 陣列儲存資料的弊端:長度一旦初始化,就不可變;真正給陣列元素賦值的個數沒有現成的方法可用 為什麼要有泛型 1.解決元素儲存的安全性問題。2.解決獲取資料元素時,需要型別強制的問題
【小家java】Java8新特性之---CompletableFuture的系統講解和例項演示(使用CompletableFuture構建非同步應用)
相關閱讀 【小家java】java5新特性(簡述十大新特性) 重要一躍 【小家java】java6新特性(簡述十大新特性) 雞肋升級 【小家java】java7新特性(簡述八大新特性) 不溫不火 【小家java】java8新特性(簡述十大新特性) 飽受讚譽 【小家java】java9
python 函式 和類都是物件,可以通過以下幾點證明
#函式 和類都是物件 ,可以通過以下幾點證明: #1.可以 賦值 給變數 def ask(): print("testing") a=ask() class Persion: def __init__(self): print("object")
oracle和mysql的幾點重要區別總結
最近,實際專案的開發中,將mysql遷移到了oracle,發現mysql與oracle在sql語句的處理上存在很大的差別,今天就兩大資料庫的差別做一下簡要的總結: 總括: 1.oracle是大型資料庫且價格昂貴;mysql是中小型資料庫且開源。 2.oracle支援高併發,高吞吐量,是O