
Convolution Neural Network (CNN) 原理與實現
1. Convolution(卷積)
類似於高斯卷積,對imagebatch中的所有image進行卷積。對於一張圖,其所有feature map用一個filter捲成一張feature map。 如下面的程式碼,對一個imagebatch(含兩張圖)進行操作,每個圖初始有3張feature map(R,G,B), 用兩個9*9的filter進行卷積,結果是,每張圖得到兩個feature map。
卷積操作由theano的conv.conv2d實現,這裡我們用隨機引數W,b。結果有點像edge detector是不是?
Code: (詳見註釋)
# -*- coding: utf-8 -*- """ Created on Sat May 10 18:55:26 2014 @author: rachel Function: convolution option of two pictures with same size (width,height) input: 3 feature maps (3 channels <RGB> of a picture) convolution: two 9*9 convolutional filters """ from theano.tensor.nnet import conv import theano.tensor as T import numpy, theano rng = numpy.random.RandomState(23455) # symbol variable input = T.tensor4(name = 'input') # initial weights w_shape = (2,3,9,9) #2 convolutional filters, 3 channels, filter shape: 9*9 w_bound = numpy.sqrt(3*9*9) W = theano.shared(numpy.asarray(rng.uniform(low = -1.0/w_bound, high = 1.0/w_bound,size = w_shape), dtype = input.dtype),name = 'W') b_shape = (2,) b = theano.shared(numpy.asarray(rng.uniform(low = -.5, high = .5, size = b_shape), dtype = input.dtype),name = 'b') conv_out = conv.conv2d(input,W) #T.TensorVariable.dimshuffle() can reshape or broadcast (add dimension) #dimshuffle(self,*pattern) # >>>b1 = b.dimshuffle('x',0,'x','x') # >>>b1.shape.eval() # array([1,2,1,1]) output = T.nnet.sigmoid(conv_out + b.dimshuffle('x',0,'x','x')) f = theano.function([input],output) # demo import pylab from PIL import Image #minibatch_img = T.tensor4(name = 'minibatch_img') #-------------img1--------------- img1 = Image.open(open('//home//rachel//Documents//ZJU_Projects//DL//Dataset//rachel.jpg')) width1,height1 = img1.size img1 = numpy.asarray(img1, dtype = 'float32')/256. # (height, width, 3) # put image in 4D tensor of shape (1,3,height,width) img1_rgb = img1.swapaxes(0,2).swapaxes(1,2).reshape(1,3,height1,width1) #(3,height,width) #-------------img2--------------- img2 = Image.open(open('//home//rachel//Documents//ZJU_Projects//DL//Dataset//rachel1.jpg')) width2,height2 = img2.size img2 = numpy.asarray(img2,dtype = 'float32')/256. img2_rgb = img2.swapaxes(0,2).swapaxes(1,2).reshape(1,3,height2,width2) #(3,height,width) #minibatch_img = T.join(0,img1_rgb,img2_rgb) minibatch_img = numpy.concatenate((img1_rgb,img2_rgb),axis = 0) filtered_img = f(minibatch_img) # plot original image and two convoluted results pylab.subplot(2,3,1);pylab.axis('off'); pylab.imshow(img1) pylab.subplot(2,3,4);pylab.axis('off'); pylab.imshow(img2) pylab.gray() pylab.subplot(2,3,2); pylab.axis("off") pylab.imshow(filtered_img[0,0,:,:]) #0:minibatch_index; 0:1-st filter pylab.subplot(2,3,3); pylab.axis("off") pylab.imshow(filtered_img[0,1,:,:]) #0:minibatch_index; 1:1-st filter pylab.subplot(2,3,5); pylab.axis("off") pylab.imshow(filtered_img[1,0,:,:]) #0:minibatch_index; 0:1-st filter pylab.subplot(2,3,6); pylab.axis("off") pylab.imshow(filtered_img[1,1,:,:]) #0:minibatch_index; 1:1-st filter pylab.show()

2. Pooling(降取樣過程)
最常用的Maxpooling. 解決了兩個問題:
1. 減少計算量
2. 旋轉不變性 (原因自己悟)
PS:對於旋轉不變性,回憶下SIFT,LBP:採用主方向;HOG:選擇不同方向的模版
Maxpooling的降取樣過程會將feature map的長寬各減半。(下面結果圖中沒有體現出來,python自動給拉到一樣大了,但實際上畫素數是減半的)
Code: (詳見註釋)
# -*- coding: utf-8 -*- """ Created on Sat May 10 18:55:26 2014 @author: rachel Function: convolution option input: 3 feature maps (3 channels <RGB> of a picture) convolution: two 9*9 convolutional filters """ from theano.tensor.nnet import conv import theano.tensor as T import numpy, theano rng = numpy.random.RandomState(23455) # symbol variable input = T.tensor4(name = 'input') # initial weights w_shape = (2,3,9,9) #2 convolutional filters, 3 channels, filter shape: 9*9 w_bound = numpy.sqrt(3*9*9) W = theano.shared(numpy.asarray(rng.uniform(low = -1.0/w_bound, high = 1.0/w_bound,size = w_shape), dtype = input.dtype),name = 'W') b_shape = (2,) b = theano.shared(numpy.asarray(rng.uniform(low = -.5, high = .5, size = b_shape), dtype = input.dtype),name = 'b') conv_out = conv.conv2d(input,W) #T.TensorVariable.dimshuffle() can reshape or broadcast (add dimension) #dimshuffle(self,*pattern) # >>>b1 = b.dimshuffle('x',0,'x','x') # >>>b1.shape.eval() # array([1,2,1,1]) output = T.nnet.sigmoid(conv_out + b.dimshuffle('x',0,'x','x')) f = theano.function([input],output) # demo import pylab from PIL import Image from matplotlib.pyplot import * #open random image img = Image.open(open('//home//rachel//Documents//ZJU_Projects//DL//Dataset//rachel.jpg')) width,height = img.size img = numpy.asarray(img, dtype = 'float32')/256. # (height, width, 3) # put image in 4D tensor of shape (1,3,height,width) img_rgb = img.swapaxes(0,2).swapaxes(1,2) #(3,height,width) minibatch_img = img_rgb.reshape(1,3,height,width) filtered_img = f(minibatch_img) # plot original image and two convoluted results pylab.figure(1) pylab.subplot(1,3,1);pylab.axis('off'); pylab.imshow(img) title('origin image') pylab.gray() pylab.subplot(2,3,2); pylab.axis("off") pylab.imshow(filtered_img[0,0,:,:]) #0:minibatch_index; 0:1-st filter title('convolution 1') pylab.subplot(2,3,3); pylab.axis("off") pylab.imshow(filtered_img[0,1,:,:]) #0:minibatch_index; 1:1-st filter title('convolution 2') #pylab.show() # maxpooling from theano.tensor.signal import downsample input = T.tensor4('input') maxpool_shape = (2,2) pooled_img = downsample.max_pool_2d(input,maxpool_shape,ignore_border = False) maxpool = theano.function(inputs = [input], outputs = [pooled_img]) pooled_res = numpy.squeeze(maxpool(filtered_img)) #pylab.figure(2) pylab.subplot(235);pylab.axis('off'); pylab.imshow(pooled_res[0,:,:]) title('down sampled 1') pylab.subplot(236);pylab.axis('off'); pylab.imshow(pooled_res[1,:,:]) title('down sampled 2') pylab.show()

3. CNN結構
想必大家隨便google下CNN的圖都濫大街了,這裡拖出來那時候學CNN的時候一張圖,自認為陪上講解的話畫得還易懂(<!--囧-->)
廢話不多說了,直接上Lenet結構圖:(從下往上順著箭頭看,最下面為底層original input)
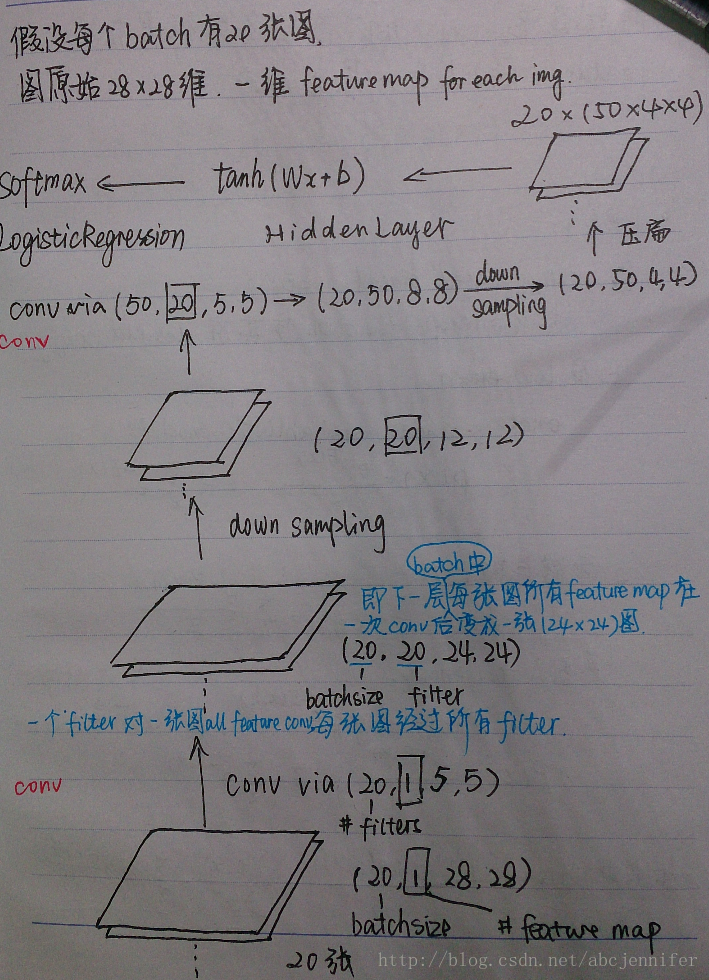
4. CNN程式碼
相關推薦
Convolution Neural Network (CNN) 原理與實現
1. Convolution(卷積)類似於高斯卷積,對imagebatch中的所有image進行卷積。對於一張圖,其所有feature map用一個filter捲成一張feature map。 如下面的程式碼,對一個imagebatch(含兩張圖)進行操作,每個圖初始有3張feature map(R,G,B)
Java 線程池的原理與實現
控制 try 所在 使用 urn str waiting media .info 這幾天主要是狂看源程序,在彌補了一些曾經知識空白的同一時候,也學會了不少新的知識(比方 NIO)。或者稱為新技術吧。 線程池就是當中之中的一個,一提到線程。我們會想到曾經《操作系統》的
防盜鏈的基本原理與實現
rec eal limit ole 站點 new exceptio stub text 1. 我的實現防盜鏈的做法,也是參考該位前輩的文章。基本原理就是就是一句話:通過判斷request請求頭的refer是否來源於本站。(當然請求頭是來自於客戶端的,是可偽造的,暫不在本文
最小二乘法多項式曲線擬合原理與實現 zz
博客 del p s 並且 多項式 聯網 python mar 程序 概念 最小二乘法多項式曲線擬合,根據給定的m個點,並不要求這條曲線精確地經過這些點,而是曲線y=f(x)的近似曲線y= φ(x)。 原理 [原理部分由個人根據互聯網上的資料進行總結,希望對大
無限極分類原理與實現(轉)
轉換 完成 外灘 獲得 意思 容易 set 導航 另一個 前言 無限極分類是我很久前學到知識,今天在做一個項目時,發現對其概念有點模糊,所以今天就來說說無限極分類。 首先來說說什麽是無限極分類。按照我的理解,就是對數據完成多次分類,如同一棵樹一樣,從根開始,
java監聽器的原理與實現
來看 class copyto 圖片 http size stat 順序 方法 監聽器模型涉及以下三個對象,模型圖如下: (1)事件:用戶對組件的一個操作,稱之為一個事件 (2)事件源:發生事件的組件就是事件源 (3)事件監聽器(處理器):監聽並負責處理事件的方法 執行順序
Redis實現分布式鎖原理與實現分析
數據表 防止 中一 csdn 訂單 not 產生 www 整體 一、關於分布式鎖 關於分布式鎖,可能絕大部分人都會或多或少涉及到。 我舉二個例子: 場景一:從前端界面發起一筆支付請求,如果前端沒有做防重處理,那麽可能在某一個時刻會有二筆一樣的單子同時到達系統後臺。 場
優先隊列原理與實現
() 通過 size 大堆 默認 深入理解 -s 示例 完整 轉自:https://www.cnblogs.com/luoxn28/p/5616101.html 優先隊列是一種用來維護一組元素構成的結合S的數據結構,其中每個元素都有一個關鍵字key,元素之間的比較都是通過k
LVM原理與實現過程
LVM原理與實現過程一、什麽是LVM 不管是使用傳統的MBR分區方式或者是GPT的分區方式,在最後數據量逐漸變大的過程中都會出現空間不足的情況,但是若是使用將此分區的數據全部遷移至一個更大空間的磁盤上的遷移時間也是不可想象的,為了解決這個問題,LVM就誕生了。LVM(Logical volume Manag
MapReduce原理與實現
讀取 提交 hdf 撲克 datanode 分配 去掉 是否 跟著 課程鏈接:Hadoop大數據平臺架構與實踐--基礎篇 1.MapReduce原理 分而治之,一個大任務分成多個小的子任務(map),並行執行後,合並結果(reduce) 問題1:1000副撲克牌少哪一張牌(
單點登錄原理與實現
授權 速度 restful contain ppi 靠譜 遠的 except 令牌 單點登錄原理與實現 關於單點登錄,在項目中用到的是對於cookie中設置的domain 為二級域名,這樣二級域名下的cookie都可以共享,將sessionId存儲在cookie中
數據加密--詳解 RSA加密算法 原理與實現
pri mir 對稱加密 模運算 速度 探討 進制 成績 分析 RSA算法簡介 RSA是最流行的非對稱加密算法之一。也被稱為公鑰加密。它是由羅納德·李維斯特(Ron Rivest)、阿迪·薩莫爾(Adi Shamir)和倫納德·阿德曼(Leonard Adleman)在19
線上防雪崩利器——熔斷器設計原理與實現
data 沒有 保障系統 狀態模式 熔斷器 data- 雪崩 form cimage 前言 這是一篇根據工作中遇到的問題總結出的最佳實踐。 上周六,我負責的業務在淩晨00-04點的支付全部失敗了。 結果一查,MD,晚上銀行維護,下遊支付系統沒有掛維護公告,在此期間一直請求維
分頁技術原理與實現之分頁的意義及方法(一)
轉載自https://www.jb51.net/article/86326.htm。 什麼是分頁技術 分頁,是一種將所有資料分段展示給使用者的技術.使用者每次看到的不是全部資料,而是其中的一部分,如果在其中沒有找到自習自己想要的內容,使用者可以通過制定頁碼或是翻頁的方式轉換可見內容,
Android系統硬體抽象層原理與實現之WIFI
http://m.blog.csdn.net/linux_zkf/article/details/7492720 整個WIFIHAL實現都很簡單,都是對wpa_supplicant的操作和使用,如果需要自己實現 WIFI HAL可以參考wifi.c來實現wifi.h中所定義的
推薦系統-協同過濾原理與實現
一、基本介紹 1. 推薦系統任務 推薦系統的任務就是聯絡使用者和資訊一方面幫助使用者發現對自己有價值的資訊,而另一方面讓資訊能夠展現在對它感興趣的使用者面前從而實現資訊消費者和資訊生產者的雙贏。 2. 與搜尋引擎比較 相同點:幫助使用者快速發現有用資訊的工具 不同點:和搜尋引擎不同的是推薦系統不
離散傅立葉變換(DFT)和快速傅立葉變換(FFT)原理與實現
目錄 1、影象變換 2、離散傅立葉變換(Discrete Fourier Transform) 3、DFT性質 4、DFT與數字影象處理 5、FFT-快速傅立葉變換 6、DFT與FFT的演算法實現 1. 影象變換 — —數學領域中有很多種變換,如傅立葉變換、拉普拉斯變
論文閱讀——LANE-Label Informed Attributed Network Embedding原理即實現
帶標籤資料的sku嵌入方法 方法名:Label Informed Attributed Network Embedding 簡稱:LANE sku嵌入向量中應包括:user對sku的行為,sku屬性,sku標籤 演算法基本流程 從使用者對sku的pv序列構造網路
DeepLearning(深度學習)原理與實現
經過三年的狂刷理論,覺得是時候停下來做些有用的東西了,因此決定開博把他們寫下來,一是為了整理學過的理論,二是監督自己並和大家分享。先從DeepLearning談起吧,因為這個有一定的實用性(大家口頭傳的“和錢靠的很近”大笑),國內各個大牛也都談了不少,我儘量從其他方面解釋一下。
【翻譯】TensorFlow卷積神經網路識別CIFAR 10Convolutional Neural Network (CNN)| CIFAR 10 TensorFlow
原網址:https://data-flair.training/blogs/cnn-tensorflow-cifar-10/ by DataFlair Team · Published May 21, 2018 · Updated September 15, 2018 1、目標-TensorFlow C