
mysql取出每個分組中最新的記錄
1、建表、插入測試資料
CREATE TABLE `test` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL,
`category_id` tinyint(3) unsigned NOT NULL DEFAULT '0',
`date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8; 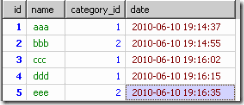
我現在需要取出每個分類中最新的內容
select * from test group by category_id order by date
結果如下
明顯。這不是我想要的資料,原因是msyql已經的執行順序是:
寫的順序:select … from… where…. group by… having… order by..
執行順序:from… where…group by… having…. select … order by…
所以在order by拿到的結果裡已經是分組的完的最後結果。
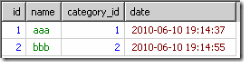
由from到where的結果如下的內容:
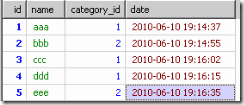
到group by時就得到了根據category_id分出來的多個小組
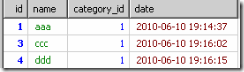

到了select的時候,只從上面的每個組裡取第一條資訊結果會如下
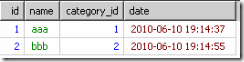
即使order by也只是從上面的結果裡進行排序。並不是每個分類的最新資訊。
2、方法
下面介紹兩種方法,一種是通過子查詢,一種是通過group_concat函式來實現。
2.1 子查詢解決方案
先將資料按照日期倒序排序(日期最新的在最前面),然後在group,這樣每個分類的第一條肯定是日期最新的。
select * from (select * from `test` order by `date` desc) `temp` group by category_id order by `date` desc2.2 通過group_concat函式
①group_concat函式
group_concat( [DISTINCT] 要連線的欄位 [Order BY 排序欄位 ASC/DESC] [Separator ‘分隔符’] )
作用:將要連線的欄位按照排序欄位的順序用分隔符連起來顯示,預設分隔符是”,”。
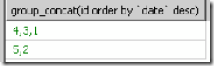
如:select group_concat(id order bydatedesc) fromtestgroup by category_id
按照時間排序將id連線起來,第一個一定是時間最新的。
②substring_index
substring_index(str,delim,count),str:要處理的字串、delim:分隔符、count:計數
例子:
SELECT SUBSTRING_INDEX('www.test.com','.',1);
結果是:www
SELECT SUBSTRING_INDEX('www.test.com','.',2)
結果是:www.test
SELECT SUBSTRING_INDEX('www.test.com','.',-2);
結果為:test.com
也就是說,如果count是正數,那麼就是從左往右數,第N個分隔符的左邊的全部內容,相反,如果是負數,那麼就是從右邊開始數,第N個分隔符右邊的所有內容。
③解析
GROUP_CONCAT將group by 後的id排序後連線起來,SUBSTRING_INDEX取得每行(每個分類)的第一個。
SELECT * FROM `test` WHERE id IN(SELECT SUBSTRING_INDEX(GROUP_CONCAT(id ORDER BY `date` DESC),',',1) FROM `test` GROUP BY category_id ) ORDER BY `date` DESC;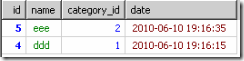
2、3 其他方法
一般id越大的時間越近,可以先選出各個分類最大的id,然後in。
SELECT MAX(id) AS id,category_id,MAX(DATE) FROM test GROUP BY category_id;
SELECT * FROM test WHERE id IN (SELECT MAX(id) FROM test GROUP BY category_id);連表,選擇出每個分類的id和最大時間作為一個臨時表,然後原表和臨時表連線,條件是分類id和時間相等。
SELECT * FROM test AS a,
(SELECT category_id, MAX(DATE) AS `date` FROM test AS b GROUP BY category_id)
AS b WHERE a.category_id=b.category_id AND a.date = b.date 相關推薦
mysql取出每個分組中最新的記錄
1、建表、插入測試資料 CREATE TABLE `test` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(10) NOT NULL, `categor
hive按照某個欄位分組,然後獲取每個分組中最新的n條資料
hive -e "use db; select t.advertId,t.exposureNum from (select advertId,exposureNum,ROW_NUMBER() OVER(PARTITION BY advertId ORDER BY addTime desc
linq中分組查詢而且獲取每個分組中的第一條記錄,數據用於分頁綁定
upd 但是 static groupby 麻煩 asc xxx each request LINQ分組取出第一條數據 Person1: Id=1, Name="Test1" Person2: Id=1, Name="Test1" Person3: Id=2, Na
在mysql中使用group by和order by取每個分組中日期最大一行資料
轉載自:https://blog.csdn.net/shiyong1949/article/details/78482737 自己實際使用的時候group by 單列欄位 兩種方式獲取資料一致,博主情況未知,有待驗證多group by 在mysql中使用group by進行分組後取某一列的最大
MYSQL中求每個分組中的最大值
求每個分組中的最大值 問題可參考https://segmentfault.com/q/1010000004138670 mysql> select * from test; +----+-------+-----+-------+ | id | name | age | c
簡單按日期查詢mysql某張表中的記錄數
unsigned 計劃 表結構 記錄 create sig 站點 signed using 測試表表結構:mysql> show create table dr_stats\G 1. row Table: dr_stats Create Table:
mysql刪除資料表中重複記錄保留一條
刪除資料庫中重複的記錄由兩種形式: 第一種是資料表中所有的欄位都重複,第二種是資料庫中部分欄位重複 這裡針對第二種情況重複: delete from app_user_verify where id not in (select a.id from (
mysql檢視各個表中的記錄數
information_schema 資料庫,在該庫中有一個 TABLES 表,這個表主要欄位分別是: TABLE_SCHEMA : 資料庫名TABLE_NAME:表名ENGINE:所使用的儲存引擎TABLES_ROWS:記錄數DATA_LENGTH:資料大小INDEX_LE
在mysql中查詢每個分組的前幾名
注意:!!!排序後分組出來的結果中非分組欄位是隨機的記錄中的資料,並不是按排序中的結果的第一條顯示的 綜合推薦的兩種方式(已經測試了結果是可行的方案): 1.分組取前n條記錄 SELECT b.id, b.wx_user_i
oracle查詢:分組查詢,取出每組中的第一條記錄
方法一: 方法二: 參考sql reference文件: Analytic functions compute an aggregate value based on a group of rows. They differ from a
MySQL中取出一列中含有最大值的記錄
在資料庫使用過程中,我們有時候需要取出在一個表中對於某個列來說具有最大值或最小值的記錄行,那麼該如何操作呢?下面講解幾種方法。 首先我們先定義一個表,如下所示: 這是一張簡單的表,下面我們通過這張表來得到含有最大price的記錄行。你想到該怎麼做了嗎? (1)採用子查詢
mysql 分組後,在每個組中排序
如下資料: 活動id 批次id 批次開始時間 期望序號 1 1 09:00 1 1 2 09:01 2 1
獲取分組後取某欄位最大一條記錄(求每個類別中最大的值的列表)
獲取分組後取某欄位最大一條記錄 方法一:(效率最高) select a.* from test a, (select type,max(typeindex) typeindex from test group by type) b where a.
mysql 分組取最新的一條記錄(整條記錄)
mysql取分組後最新的一條記錄,下面兩種方法.一種是先篩選 出最大和最新的時間,在連表查詢.一種是先排序,然後在次分組查詢(預設第一條),就是最新的一條資料了#select * from t_assistant_article as a, (select max(base
MYSQL操作數據表中的記錄
mysql操作數據表中的記錄1 把選中的列數名到最前面ALTER TABCE 表名 MODIFY 列數名以及列數名的類型 FIRST;2 修改列數名類型ALTERTABCE 表名 MODIFY 列數名新列數名;3 修改數據表名第一種 ALTERTABCE 原表名 RENAME 新表名;第二種 RENAME
mysql 數據表中查找重復記錄
語句 having sel table 數據表 col class select blog 以下sql語句可以實現查找出一個表中的所有重復的記錄 select user_name,count(*) as count from user_table group by use
MySQL--操作數據表中的記錄小結
log mage 分組 技術 rom ges sql alt image 最常用,最復雜的語句: 每一項的: 表的參照 From 條件 WHERE 進行記錄的分組 GROUP BY 分組的時候對分組的條件進行設定 HAVING 對結果進行排序 ORD
MySQL(四):操作資料表中的記錄
新增記錄 語句:INSERT [INTO(可省略)] 表名 [(可省略)列名1,列名2,..] {VALUES | VALUE} (列1的值,列2的值,列3...) 如果不寫列名則預設為所有列新增記錄 如果
從blast結果中取出每個query搜到的evalue最小的結果
在做多基因blast時,通常每個基因找到的匹配序列很多。這時習慣根據evalue來進行篩選,evalue較小的其相似性更高。下面提供兩種方法解決。 一 linux命令 第11列為evalue值,第一列為基因名,先根據evalue升序排列,然後根據基因名去重。預設
mysql變數使用(leetCode中一分組排序題)
select d.name as Department, e. Employee, e.Salary from ( select temp.name as Employee, temp.Salary, temp.