
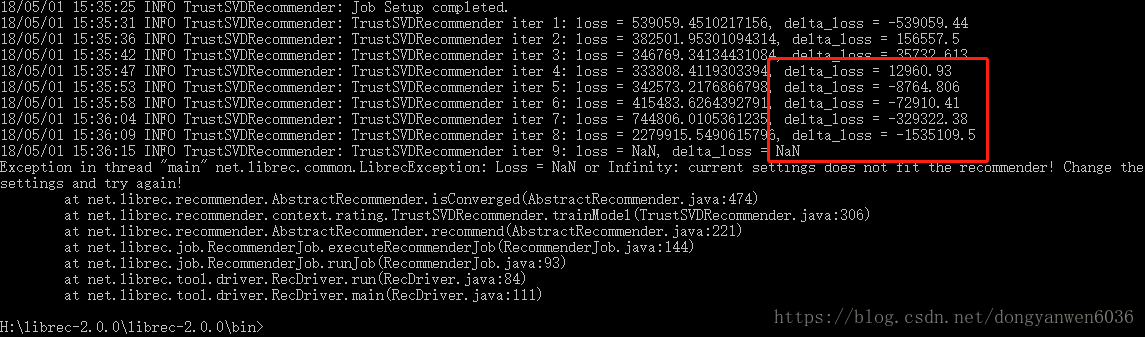
LibRec使用重現trustsvd和`Exception in thread"main"net.librec.common.LibrecException:Loss=NaN or Infinity
1.首先 下載
2.下載後解壓。
3.在windows下演示,linux同理。
4.直接先進入cmd,切換到解壓的目錄bin下如圖:

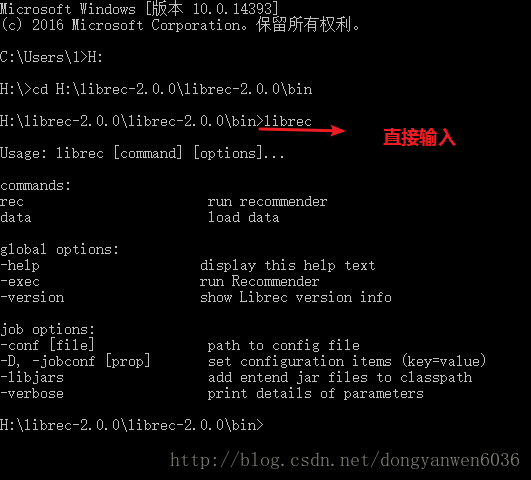
5.測試執行一個簡單的推薦演算法:Global Average
librec rec -exec -D rec.recommender.class=globalaverage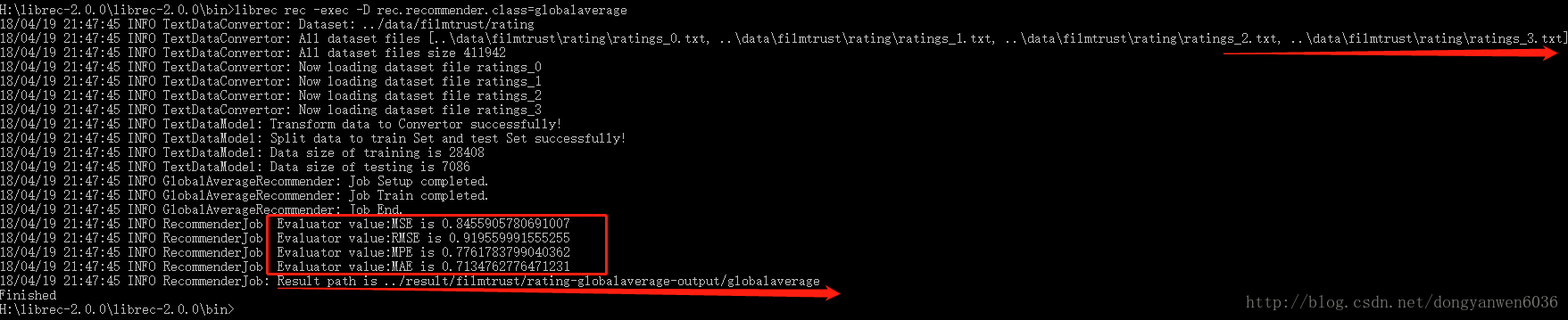
從圖上可知,LibRec自動(從類路徑classpath中)載入了 librec.properties配置檔案來指定程式執行的必要配置,包括資料集位置,資料分割的方式,評估器等內容。執行完成後,把評估的結果儲存到指定位置。
貼了6的結果圖
6.最近看來Trustsvd論文:好奇它的結果如何
librec rec -exec -conf ../core\src\main\resources\rec\context\rating/trustsvd-test.properties結果:
8/04/19 21:26:10 INFO RecommenderJob: Evaluator value:MPE is 0.9901213660739486
18/04/19 21:26:10 INFO RecommenderJob: Evaluator value:MSE is 0.6271031037849762
18/04/19 21:26:10 INFO RecommenderJob: Evaluator value 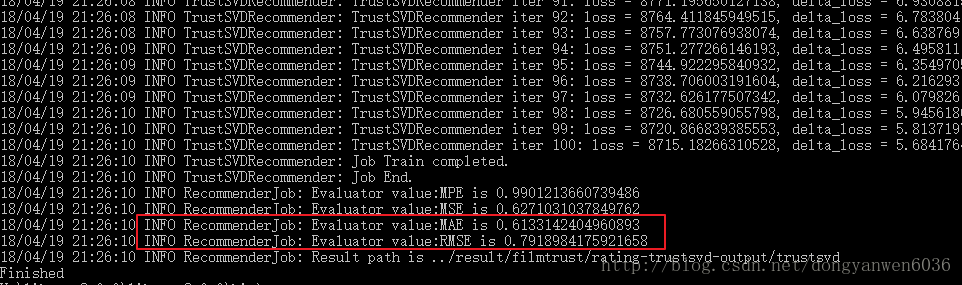
預設的都是filmtrust資料集,看到達不到論文裡的水平,配置檔案裡的引數可能不一樣。看一下論文裡的水平。
7.配置選項–追求論文水平
core\src\main\resources\rec\context\rating\trustsvd-test.properties下的配置和論文裡一樣
data.appender.class=social
data.appender.path=test/test-append-dir
rec.recommender.class=trustsvd
rec.iterator.learnrate=0.005
rec.iterator.learnrate.maximum=-1
rec.iterator.maximum=100
rec.user.regularization=1.2
rec.item.regularization=1.2
rec.social.regularization=0.9
rec.bias.regularization=1.2
rec.factor.number=10
rec.learnrate.bolddriver=false
rec.learnrate.decay=1.0
rec.recommender.earlystop=false
rec.recommender.verbose=true
#新增兩條
data.model.splitter=kcv
data.splitter.cv.number=57.1.1.這樣把放置在 conf / librec.properties檔案中設定覆蓋瞭如下設定:下面的設定比例0.8有一個特點就是
就是產生的結果是不變的,不像論文的5折交叉驗證結果每次都不一樣。最後貼張很接近論文的值了(論文中應該用的是交叉驗證中較低的值非平均值)。
data.model.splitter=ratio
# this value should in (0,1)
data.splitter.trainset.ratio=0.87.1.2.或者把前者去掉,只在在 conf / librec.properties檔案中設定
data.model.splitter=kcv
data.splitter.cv.number=57.2.配置後還是執行6中的命令

Librec.properties 是優先匯入的,其配置項可以被具體演算法的配置檔案重置。例如,我們可以在 svdpp-test.properties 覆蓋並指定新的資料分割方式。
更新
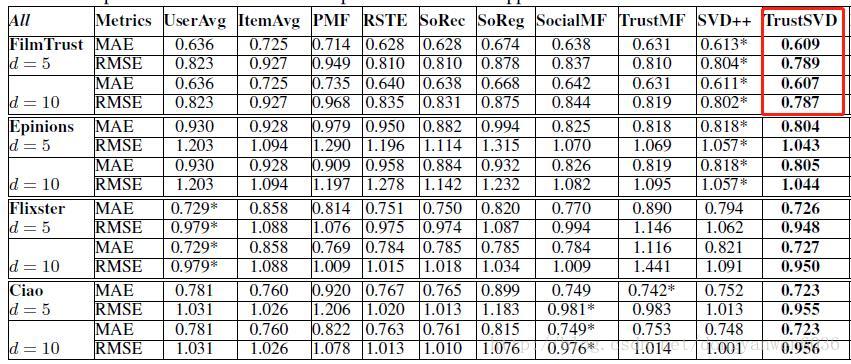
官網測試結果彙總
官方資料推薦
我的目的是重現trustsvd論文裡的結果,注意資料集的大小
paper中:
Epinions(665K)
Filmtrust(35K)
Flixster(410K)
Ciao(280K)
前兩個已經弄到,後兩個還找不到同樣大小的,微信群裡問作者要,還被嘲諷了一下 哈哈
測試新資料Epinions(665K)
更改檔案測試在 在conf / librec.properties 檔案中設定:
# convertor
# load data and splitting data
# into two (or three) set
# setting dataset name
data.input.path=Epinions/rating
data.input.path=filmtrust/trust1.在執行SocialMF,預設引數就可以!先看一下Epinions在SocialMF的效果

2.在執行trustsvd注意配置引數不然會崩見圖,但是這樣就不能保證最優,儘管我用的是論文的引數還是崩。不是trustsvd最優但必須比其他要優,不然真是垃圾。
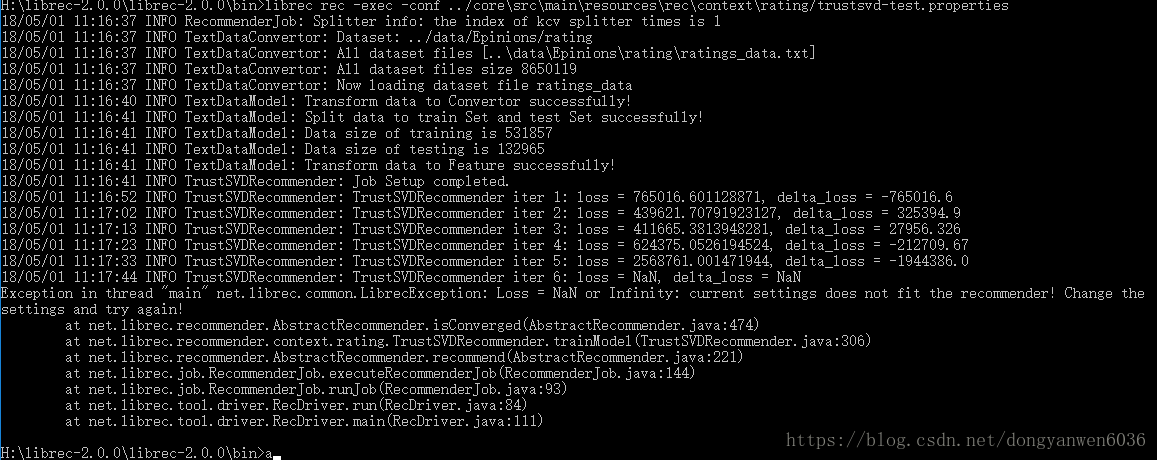
當前的配置:
data.appender.class=social
data.appender.path=test/test-append-dir
rec.recommender.class=trustsvd
rec.iterator.learnrate=0.005
rec.iterator.learnrate.maximum=-1
rec.iterator.maximum=100
rec.user.regularization=1.2
rec.item.regularization=1.2
rec.social.regularization=0.9
rec.bias.regularization=1.2
rec.factor.number=10
rec.learnrate.bolddriver=false
rec.learnrate.decay=1.0
rec.recommender.earlystop=false
rec.recommender.verbose=trueException in thread "main" net.librec.common.LibrecException: Loss = NaN or Infinity: current settings does not fit the recommender! Change the settings and try again!
2.修改後配置可以出正常結果
data.appender.class=social
data.appender.path=test/test-append-dir
rec.recommender.class=trustsvd
rec.iterator.learnrate=0.005
rec.iterator.learnrate.maximum=1
rec.iterator.maximum=10
rec.user.regularization=0.0001
rec.item.regularization=0.0001
rec.social.regularization=0.0001
rec.bias.regularization=0.0001
rec.factor.number=10
rec.learnrate.bolddriver=false
rec.learnrate.decay=0.0001
rec.recommender.earlystop=false
rec.recommender.verbose=true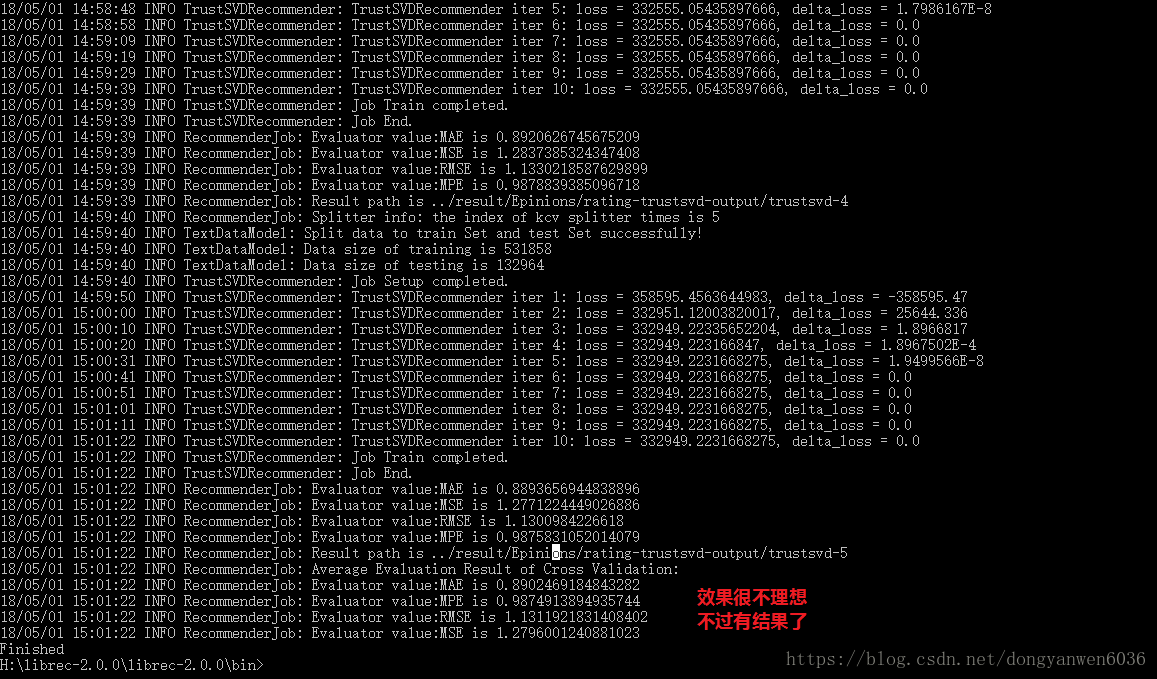
現在我才知道出錯原來是學習率的問題,之前雖然跑通了但是也說了與論文中的結果0.805相差太多。之前正則係數太差了,更新一下:
調學習率的過程中如果再出現delta_loss負值(除了第一次迭代)肯定會崩
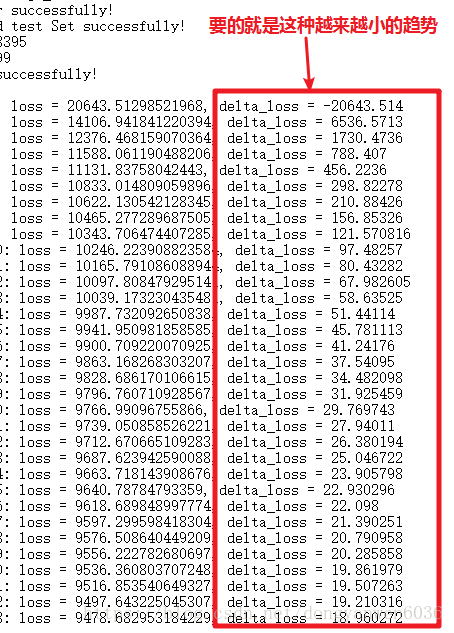
Epinions的最接近理想值配置:
data.appender.class=social
data.appender.path=test/test-append-dir
rec.recommender.class=trustsvd
rec.iterator.learnrate=0.005
rec.iterator.learnrate.maximum=0.003
rec.iterator.maximum=100
rec.user.regularization=0.9
rec.item.regularization=0.9
rec.social.regularization=0.5
rec.bias.regularization=0.9
rec.factor.number=5
rec.learnrate.bolddriver=false
rec.learnrate.decay=-1
rec.recommender.earlystop=false
rec.recommender.verbose=true
data.splitter.cv.number=5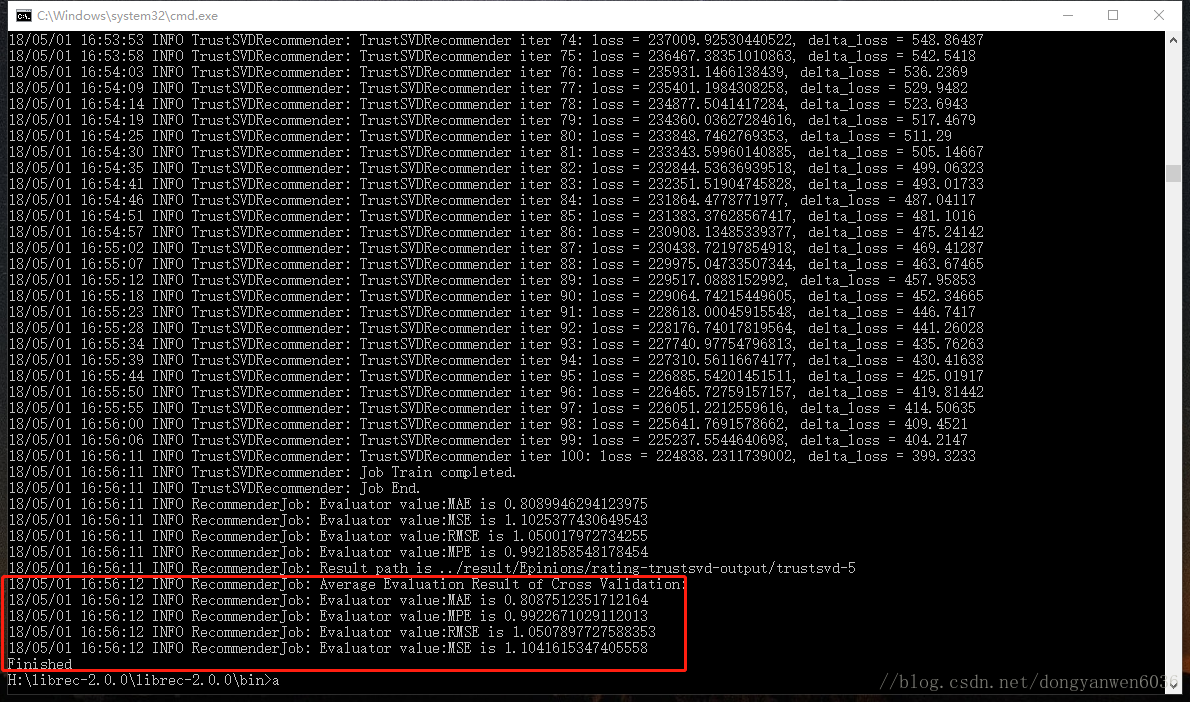
結果是0.809,d=5,trustsvd.
相關推薦
LibRec使用重現trustsvd和`Exception in thread"main"net.librec.common.LibrecException:Loss=NaN or Infinity
1.首先 下載 2.下載後解壓。 3.在windows下演示,linux同理。 4.直接先進入cmd,切換到解壓的目錄bin下如圖: 5.測試執行一個簡單的推薦演算法:Global Average librec rec -exec -
idea運行的時候出現的問題Exception in thread “main” java.lang
ideaidea運行的時候出現的問題Exception in thread “main” java.lang.NoSuchMethodError: scala.collection.immutable.HashSet$這類錯誤主要是環境中運行scala與idea中scala的版本不一致導致的。將他們更換為相同
Exception in thread “main” java.sql.SQLException: The server time zone value ‘?й???????’ is unrecognized or represents more than one time zone.
odin 異常 參數 執行 cif must ant -h base Exception in thread “main” java.sql.SQLException: The server time zone value ‘?й???????’ is unrecogniz
Exception in thread “main” java.sql.SQLException: No suitable driver
問題背景:通過Spark SQL的jdbc去讀取Oracle資料做測試,在本地的idea中沒有報任務錯誤。但是打包到叢集的時候報: Exception in thread “main” java.sql.SQLException: No suitable driver 測試程式碼:
idea 啟動專案報錯:Exception in thread "main" io.sited.StandardException: Timed out after 30000 ms ....
Exception in thread "main" io.sited.StandardException: Timed out after 30000 ms while waiting for a server that matches ReadPreferenceServerSelector{readPr
Exception in thread “main” java.lang.NoSuchMethodError: scala.Predef..conforms()Lscala/Predef$$less$
執行Scala程式,出現如下問題: Exception in thread “main” java.lang.NoSuchMethodError: scala.Predef..conforms()Lscala/Predef$$less$colon$less; at org.apach
java使用類陣列 報錯Exception in thread "main" java.lang.NullPointerException
原始碼如下: Point[] points=new Point[n];//Point是一個類 for(int i=0;i<n;i++) { System.out.print("請輸入x:"); points[i].setX(in.next
連線資料庫連線池 Exception in thread "main" java.lang.NullPointerException
今天測試資料庫連線池發現一直是空指標錯誤。一般都是配置檔案出了問題。找了半天才發現,在沒有密碼的情況下不要加入password=null,估計是沒有加入關鍵字解析的。直接省去不寫就好了 driverClassName=com.mysql.jdbc.Driver
【解決】自己編寫Wordcount程式碼上傳叢集上執行時報錯:Exception in thread "main" java.lang.ClassNotFoundException: WordCount
報錯資訊:ClassNotFoundException: WordCount [[email protected] fs_testdir]# hadoop jar /fs_testdir/my
Exception in thread "main" org.springframework.beans.factory.BeanCreationException:
媽的蛋,出現這個bug,搞了我一下午,建議各位,在學習一個新技術之前可以先去了解,這個技術是幹嘛的,它的作用,它的原理,以及後期的原始碼分析, 所以回到正題,出現bug,很明顯,它的問題出現在,建立bean失敗的情況下,這個時候你可以試著跟著程式的提示走,你就會發現,程式不
personRDD.toDF Exception in thread "main" java.lang.NoSuchMethodError
scala 版本: 2.10.2 sparkSQL :maven依賴版本 <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark
elasticsearch 編寫java程式報錯Exception in thread "main" java.lang.NoClassDefFoundError: org/elasticsearch
java程式啟動報錯: Exception in thread "main" java.lang.NoClassDefFoundError: org/elasticsearch/plugins/NetworkPlugin ERROR StatusLogger Log4j2
Exception in thread "main" java.lang.ClassNotFoundException: WordCount
出現這個問題主要是呼叫的問題,沒有加入包./bin/hadoop jar FirstJar/WordCount.jar WordCount input output改成如下的樣子就可以了./bin/hadoop jar FirstJar/WordCount.jar cn.edu.ruc.cloud
hive錯誤:Exception in thread "main" java.lang.RuntimeException: java.io.IOException: Permission denied
用不同使用者去登入hive 可能會報如下錯誤: Exception in thread "main" java.lang.RuntimeException: java.io.IOException: Permission denied at org.apa
Exception in thread "main" java.lang.ClassNotFoundException: com.mysql.jdbc.driver at java.base/jdk
Eclipse下javal連資料庫一直報這個錯。由於我用的是新版的MySQL,所以經常遇見些奇奇怪怪的錯…… 坑在這裡: 錯誤程式碼:Class.forName("com.mysql.jdbc.driver"); Driver要大寫!!! 正確的程式碼: pack
[o.e.b.ElasticsearchUncaughtExceptionHandler] [unknown] uncaught exception in thread [main] org.elasticsearch.bootstrap.StartupException: java.lang.Ru
這是因為不知從哪個版本後,elasticsearch為了安全性,是不能用root使用者啟動的。 解決的辦法:當然是建立一個使用者,用建立的使用者啟動啦,注意許可權的問題,目錄也應該改為建立的使用者許可權! 我是用elk的使用者啟動,exec引數指定命令,這樣就可以了su - elk -c "
spark submit提交任務報錯Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/stream
1.問題描述 提交spark任務: bin/spark-submit --master local[2] \ --class _0924MoocProject.ImoocStatStreamingApp_product \ /opt/datas/project/scala
hibernate出現Exception in thread "main " java.lang.ExceptionInInitializerError錯誤解決辦法
最近複習了下hibernate的內容,用於準備面試。另外看了下尚學堂的視訊,按照步驟去做了幾個實驗, 但是在這過程中遇到了以下錯誤問題: SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found bi
Exception in thread "main" java.lang.NoClassDefFoundError: javax/servlet/ServletContext
最近習慣做筆記,如果那裡有不對的地方,還望大神們指點,親噴也可以。 用了兩天碼了個dubbo服務,本地執行可以,結果放到伺服器傻逼了(心裡一萬隻草泥馬在奔騰。。。),為什麼? 結果在執行消費端zookeeper的時候,出現:Exception
“Exception in thread "main" java.lang.OutOfMemoryError: Java heap space ”
背景: 我在Eclipse+tomcat下使用http協議的post方法向伺服器上傳大檔案的時候出錯。 Error: Exception in thread "main" java.lang.Out