
【軟體開發底層知識修煉】二十七 C/C++中的指標與陣列是不同的中
- 上幾篇文章學習了ABI-應用程式二進位制介面:【軟體開發底層知識修煉】二十六 ABI-應用程式二進位制介面 學習總結文章目錄
- 本篇文章就指標與陣列的聯絡與區別來學習學習
文章目錄
1 疑問
在具體用文字理論來說明指標與陣列的區別之前,先看一下下面的程式碼例子,這兩個程式輸出的結果是一樣的麼?不一樣的話,分別輸出什麼?
- main.c
#include <stdio.h> - define.c
#include <stdio.h>
char g_name[] = "D.T.Software";
void define_print()
{
printf("define_print() : %s\n", g_name);
}
將上述兩個程式放到同一資料夾下進行編譯執行:
- gcc -g main.c define.c -o test.out
- .test.out
執行結果如下:

- 但是如果我把main.c中的
extern char* g_name;換成extern char g_name[];的話,程式執行就可以通過,並且可以得到預期的結果。
對於這個結果,我想並不是很多人可以理解的。這個問題放到後面解釋。下面我們先來看看指標與陣列的一些基本概念。
2 指標與陣列是不相等的
- 指標
- 指標的本質就是一個變數,它儲存的目標值是一個記憶體地址。這個記憶體地址是另一個變數或者不管什麼東西的地址
- 指標運算與 * 操作符配合使用能夠模擬陣列的行為
- 陣列
- 陣列是一段連續的記憶體空間的別名
- 陣列名可看做指向陣列第一個元素的常量指標。
在C語言中指標與陣列在某些層面是具有等價關係的,注意這裡說的是某層面。比如下面的程式碼層面,指標與陣列的操作就是相等的:

那麼,既然我們已經學習了那麼多彙編的知識,上面的指標與陣列的操作在彙編層面(或者叫做二進位制層面)是否相等?我們以實際的例子來說明,編譯下面程式碼,並生成彙編程式碼,檢視test函式的彙編程式碼:
#include <stdio.h>
int test()
{
int a[3] = {0};
int* p = a;
p[0] = 1; // a[0] = 1
p[1] = 2; // a[1] = 2
a[2] = 3; // p[2] = 3
}
int main()
{
test();
return 0;
}
- gcc -g test.c -o test.out
- objdump -S test.out > test.s 生成test.s反彙編程式碼
檢視test.s中的test函式中的彙編程式碼,如下:
int test()
{
8048394: 55 push %ebp
8048395: 89 e5 mov %esp,%ebp
8048397: 83 ec 10 sub $0x10,%esp
int a[3] = {0};
804839a: c7 45 f0 00 00 00 00 movl $0x0,-0x10(%ebp) //a[0]的值
80483a1: c7 45 f4 00 00 00 00 movl $0x0,-0xc(%ebp)
80483a8: c7 45 f8 00 00 00 00 movl $0x0,-0x8(%ebp)
int* p = a; //指標p指向陣列a的第一個元素,4位元組
80483af: 8d 45 f0 lea -0x10(%ebp),%eax
80483b2: 89 45 fc mov %eax,-0x4(%ebp)
p[0] = 1; // a[0] = 1 由於是在第一個位置,沒必要使用add $0x0,%eax
80483b5: 8b 45 fc mov -0x4(%ebp),%eax
80483b8: c7 00 01 00 00 00 movl $0x1,(%eax)
p[1] = 2; // a[1] = 2 可以看出有兩次定址的過程
80483be: 8b 45 fc mov -0x4(%ebp),%eax //首先把指標p存的地址取出來傳給eax暫存器
80483c1: 83 c0 04 add $0x4,%eax //然後將eax+4
80483c4: c7 00 02 00 00 00 movl $0x2,(%eax) //最後將數值2傳給eax暫存器中存的地址所在的記憶體處,注意這句話的理解。
a[2] = 3; // p[2] = 3
80483ca: c7 45 f8 03 00 00 00 movl $0x3,-0x8(%ebp) //可以看出如果是陣列的話,直接將值賦值給對應記憶體處,而不用像指標那樣進行兩次地址的操作
}
80483d1: c9 leave
80483d2: c3 ret
對於上面的彙編程式碼,應該並不是很多人都可以理解。不理解也無所謂,能夠看出我們的問題所在即可。
- 首先看上面,對於
p[0]=1; p[1]=2;這兩段程式碼,它們所對應的彙編程式碼,由於p[0]比較特殊,所以看p[2]的。上線的註釋也是比較詳細了,由此我們知道如果將指標當做陣列來使用,首先需要取出指標所儲存的地址,然後將地址值+4,然後在加了4的地址處賦值,這很明顯是兩次定址操作。一次是從指標中取出地址,二是根據這個地址再找到相應的記憶體然後進行賦值。 - 但是對於
a[2] = 3;這段話,看上面的彙編程式碼,很明顯,就是直接進行一次記憶體操作。這顯而易見。
由此我們可以粗略的得出以下結論:
- 指標與陣列不管在真麼情況下,在二進位制層面是完全不同的。儘管在語言書寫的時候等效,但是效率是相差很大的
- 指標操作是先定址,然後再對記憶體單元進行操作
- 陣列是直接對記憶體單元進行操作
然後就是,在大多數情況下,編譯器做了很多的工作,它讓程式設計師可以更高效的寫程式碼,所以在很多情況中,指標和陣列在語言編寫層面,是一樣的,就像上線的示例程式碼一樣。
3 解決疑問
上一節內容我們學會了指標與陣列的一些區別,現在就來看看最開始的疑問,最開始main.c和define.c編譯執行後,為什麼會產生錯誤,並且為什麼是段錯誤呢?下面就一點點揭開迷霧。
- 首先我們要知道的前提知識點,C/C++編譯器的天生缺陷
- C/C++編譯器由4個子部件組成,分別是前處理器,編譯器,彙編器,連結器
- 每個子部件之間獨立工作,相互之間沒有通訊
- 對於語法的檢查與規範只在編譯器(是指第二個子部件的編譯器)編譯階段有效(如:型別約束和保護成員)
- 編譯器認為,每一個原始檔都是相互獨立的,對各個原始檔單獨進行編譯(當然最後是需要將各個單獨編譯後的檔案進行連結的)。這個是導致上面錯誤程式碼的直接原因。具體還看下面的分析。
那麼對於上面的幾條知識點,我們使用下面的圖解進行說明:

- 上面圖示中說了在兩個檔案中型別不一致導致執行時錯誤,當然這是表面原因,並且如果是其他的型別(不是指標的型別),有可能就不會出錯。所以我們還需要深挖這其中的錯誤。
- 針對我們的程式碼的話,就是在main.c中將g_name宣告為指標,那麼編譯器進行編譯的時候,就是單獨編譯main.c檔案,並且將g_name按照指標的方式進行編譯。那麼由第二節的內容知道,指標的操作是需要兩次定址的。 這裡我我們先記住,下面的分析會用上。
為了能夠更加清楚的說清楚問題,下面我們針對上述的main.c與define.c的編譯的過程簡單的用圖表示一下:

- 上面最後將define.c中的陣列g_name的首地址與main.c中代表的指標g_name連結起來,具體如何連結呢?請看以下圖示:
- 剛開始define.c中的g_name就是一個數組的首地址,如下圖所示:

- 當將main.c中的指標g_name與上面的define.c中的g_name進行連結後,由於g_name是指標,佔4位元組,所以連結後如下圖:
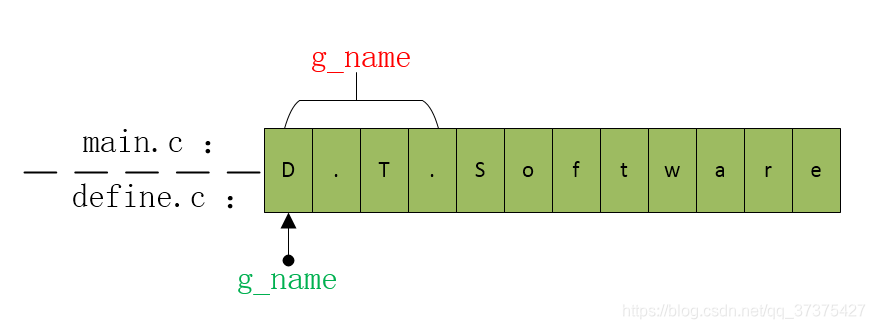
上面的圖示分析如果能看懂的話,就知道g_name 是一個佔有4位元組的指標,而g_name 是一個指向陣列首地址的值。如果我們注意到前面所說的指標作為陣列是需要兩次定址操作的話,我們就應該知道,如果使用g_name 的話,首先將它存的地址:“D.T.” 取出來,可以看到,它本身應該存的是地址,但是現在是一串字元。然後用這個“地址”來定址另一個記憶體地址處。到這裡,就明瞭了,上面的一串字元所代表的地址處是一個未定義的,是一個野地址!!!也就是說在執行的時候,此時g_name是一個野指標!!!這必然會產生段錯誤了!!!
- 這就是為什麼,產生的錯誤是段錯誤。真正的原因歸根結底是野指標的原因。
對於上面存在的問題,我們儘量使用以下的方法來解決:
- 儘可能不使用跨檔案的全域性變數,也就是非static的全域性變數
- 當必須使用時,在統一固定的標頭檔案中宣告global.h
- 其他原始檔包含上述global.h即可
4 總結
- 在進行總結前,這裡務必再次將宣告與定義的區別說明一下:
- 宣告只是告訴編譯器,目標存在,可使用
- 定義,是為目標分配記憶體(變數)或確定執行流(函式)
- 理論上,任何目標都需要先宣告,再使用
- C/C++允許宣告與定義的統一
下面是針對本文的指標與陣列的區別的總結
- C/C++語言中的指標與陣列在某些語言層面上的使用時等價的
- 指標與陣列在二進位制層面是完全不等的
- C/C++編譯器忽略了原始碼之間的依賴關係
- 如果一定要使用跨檔案之間的全域性變數的話,最好將全域性變數放到一個統一的標頭檔案global.h中
- 然後其他原始檔包含global.h即可
對於上面的分析,如果沒有懂,可以加左側群,進群進行交流。