
Spark1.6之後為何使用Netty通訊框架替代Akka
解決方案:
一直以來,基於Akka實現的RPC通訊框架是Spark引以為豪的主要特性,也是與Hadoop等分散式計算框架對比過程中一大亮點。
但是時代和技術都在演化,從Spark1.3.1版本開始,為了解決大塊資料(如Shuffle)的傳輸問題,Spark引入了Netty通訊框架,到了1.6.0版本,Netty居然完成取代了Akka,承擔Spark內部所有的RPC通訊以及資料流傳輸。
網路IO掃盲貼
在Linux作業系統層面,網路操作即為IO操作,總共有:阻塞式,非阻塞式,複用模型,訊號驅動和非同步五種IO模型。其中
- 阻塞式IO操作請求發起以後,從網絡卡等待/讀取資料,核心/到使用者態的拷貝,整個IO過程中,使用者的執行緒都是處於阻塞狀態。
- 非阻塞與阻塞的區別在於應用層不會等待網絡卡接收資料,即在核心資料未準備好之前,IO將返回EWOULDBLOCK,使用者端通過主動輪詢,直到核心態資料準備好,然後再主動發起核心態資料到使用者態的拷貝讀操作(阻塞)。
- 在非阻塞IO中,每個IO的應用層程式碼都需要主動地去核心態輪詢直到資料OK,在IO複用模型中,將“輪詢/事件驅動”的工作交給一個單獨的select/epoll的IO控制代碼去做,即所謂的IO複用。
- 訊號驅動IO是向核心註冊訊號回撥函式,在資料OK的時候自動觸發回撥函式,進而可以在回撥函式中啟用資料的讀取,即由核心告訴我們何時可以開始IO操作。
- 非同步IO是將IO資料讀取到使用者態記憶體的函式註冊到系統中,在核心資料OK的時候,自動完成核心態到使用者態的拷貝,並通知應用態資料已經讀取完成,即由核心告訴我們何時IO操作已經完成;
JAVA IO也經歷來上面幾次演化,從最早的BIO(阻塞式/非阻塞IO),到1.4版本的NIO(IO複用),到1.7版本的NIO2.0/AIO(非同步IO);
基於早期BIO來實現高併發網路伺服器都是依賴多執行緒來實現,但是執行緒開銷較大,BIO的瓶頸明顯,NIO的出現解決了這一大難題,基於IO複用解決了IO高併發;但是NIO有也有幾個缺點:
- API可用性較低(拿ByteBuffer來說,共用一個curent指標,讀寫切換需要進行flip和rewind,相當麻煩);
- 僅僅是API,如果想在NIO上實現一個網路模型,還需要自己寫很多比如執行緒池,解碼,半包/粘包,限流等邏輯;
- 最後就是著名的NIO-Epoll死迴圈的BUG 因為這幾個原因,促使了很多JAVA-IO通訊框架的出現,Netty就是其中一員,它也因為高度的穩定性,功能性,效能等特性,成為Javaer們的首選。
那麼Netty和JDK-NIO之間到底是什麼關係?是JDK-NIO的封裝還是重寫?
首先是NIO的上層封裝,Netty提供了NioEventLoopGroup/NioSocketChannel/NioServerSocketChannel的組合來完成實際IO操作,繼而在此之上實現資料流Pipeline以及EventLoop執行緒池等功能。
另外它又重寫了NIO,JDK-NIO底層是基於Epoll的LT模式來實現,而Netty是基於Epoll的ET模式實現的一組IO操作EpollEventLoopGroup/EpollSocketChannel/EpollServerSocketChannel;
Netty對兩種實現進行完美的封裝,可以根據業務的需求來選擇不同的實現(Epoll的ET和LT模式真的有很大的效能差別嗎?單從Epoll的角度來看,ET肯定是比LT要效能好那麼一點。
但是如果為了編碼簡潔性,LT還是首選,ET如果使用者層邏輯實現不夠優美,相比ET還會帶來更大大效能開銷;不過Netty這麼大的開源團隊,相信ET模式應該實現的不錯吧!!純屬猜測!!)。
那麼Akka又是什麼東西?
從Akka出現背景來說,它是基於Actor的RPC通訊系統,它的核心概念也是Message,它是基於協程的,效能不容置疑;基於scala的偏函式,易用性也沒有話說。
但是它畢竟只是RPC通訊,無法適用大的package/stream的資料傳輸,這也是Spark早期引入Netty的原因。
注:
Akka is a concurrency framework built around the notion of actors and composable futures, Akka was inspired by Erlang which was built from the ground up around the Actor paradigm. It would usually be used to replace blocking locks such as synchronized, read write locks and the like with higher level asynchronous abstractions.
Akka是一個建立在Actors概念和可組合Futures之上的併發框架,,Akka設計靈感來源於Erlang,Erlang是基於Actor模型構建的。它通常被用來取代阻塞鎖如同步、讀寫鎖及類似的更高級別的非同步抽象。
Netty is an asynchronous network library used to make Java NIO easier to use.
Netty是一個非同步網路庫,使JAVA NIO的功能更好用。
Notice that they both embrace asynchronous approaches, and that one could use the two together, or entirely separately.
注意:它們兩個都提供了非同步方法,你可以使用其中一個,或兩個都用
Where there is an overlap is that Akka has an IO abstraction too, and Akka can be used to create computing clusters that pass messages between actors on different machines. From this point of view, Akka is a higher level abstraction that could (and does) make use of Netty under the hood
Akka針對IO操作有一個抽象,這和netty是一樣的。使用Akka可以用來建立計算叢集,Actor在不同的機器之間傳遞訊息。從這個角度來看,Akka相對於Netty來說,是一個更高層次的抽象
那麼Netty為什麼可以取代Akka?首先不容置疑的是Akka可以做到的,Netty也可以做到,但是Netty可以做到,Akka卻無法做到,原因是啥?
在軟體棧中,Akka相比Netty要Higher一點,它專門針對RPC做了很多事情,而Netty相比更加基礎一點,可以為不同的應用層通訊協議(RPC,FTP,HTTP等)提供支援。
在早期的Akka版本,底層的NIO通訊就是用的Netty;其次一個優雅的工程師是不會允許一個系統中容納兩套通訊框架,噁心!
最後,雖然Netty沒有Akka協程級的效能優勢,但是Netty內部高效的Reactor執行緒模型,無鎖化的序列設計,高效的序列化,零拷貝,記憶體池等特性也保證了Netty不會存在效能問題。
那麼Spark是怎麼用Netty來取代Akka呢?一句話,利用偏函式的特性,基於Netty“仿造”出一個簡約版本的Actor模型!!
Spark Network Common的實現
Byte的表示
對於Network通訊,不管傳輸的是序列化後的物件還是檔案,在網路上表現的都是位元組流。在傳統IO中,位元組流表示為Stream;在NIO中,位元組流表示為ByteBuffer;在Netty中位元組流表示為ByteBuff或FileRegion;在Spark中,針對Byte也做了一層包裝,支援對Byte和檔案流進行處理,即ManagedBuffer;
ManagedBuffer包含了三個函式createInputStream(),nioByteBuffer(),convertToNetty()來對Buffer進行“型別轉換”,分別獲取stream,ByteBuffer,ByteBuff或FileRegion;NioManagedBuffer/NettyManagedBuffer/FileSegmentManagedBuffer也是針對這ByteBuffer,ByteBuff或FileRegion提供了具體的實現。
更好的理解ManagedBuffer:比如Shuffle BlockManager模組需要在記憶體中維護本地executor生成的shuffle-map輸出的檔案引用,從而可以提供給shuffleFetch進行遠端讀取,此時檔案表示為FileSegmentManagedBuffer,shuffleFetch遠端呼叫FileSegmentManagedBuffer.nioByteBuffer/createInputStream函式從檔案中讀取為Bytes,並進行後面的網路傳輸。如果已經在記憶體中bytes就更好理解了,比如將一個字元陣列表示為NettyManagedBuffer。
Protocol的表示
協議是應用層通訊的基礎,它提供了應用層通訊的資料表示,以及編碼和解碼的能力。在Spark Network Common中,繼承AKKA中的定義,將協議命名為Message,它繼承Encodable,提供了encode的能力。
<ignore_js_op>
Message根據請求響應可以劃分為RequestMessage和ResponseMessage兩種;對於Response,根據處理結果,可以劃分為Failure和Success兩種型別;根據功能的不同,z主要劃分為Stream,ChunkFetch,Rpc。
Stream訊息就是上面提到的ManagedBuffer中的Stream流,在Spark內部,比如SparkContext.addFile操作會在Driver中針對每一個add進來的file/jar會分配唯一的StreamID(file/[]filename],jars/[filename]);worker通過該StreamID向Driver發起一個StreamRequest的請求,Driver將檔案轉換為FileSegmentManagedBuffer返回給Worker,這就是StreamMessage的用途之一;
ChunkFetch也有一個類似Stream的概念,ChunkFetch的物件是“一個記憶體中的Iterator[ManagedBuffer]”,即一組Buffer,每一個Buffer對應一個chunkIndex,整個Iterator[ManagedBuffer]由一個StreamID標識。Client每次的ChunkFetch請求是由(streamId,chunkIndex)組成的唯一的StreamChunkId,Server端根據StreamChunkId獲取為一個Buffer並返回給Client; 不管是Stream還是ChunkFetch,在Server的記憶體中都需要管理一組由StreamID與資源之間對映,即StreamManager類,它提供了getChunk和openStream兩個介面來分別響應ChunkFetch與Stream兩種操作,並且針對Server的ChunkFetch提供一個registerStream介面來註冊一組Buffer,比如可以將BlockManager中一組BlockID對應的Iterator[ManagedBuffer]註冊到StreamManager,從而支援遠端Block Fetch操作。
Case:對於ExternalShuffleService(一種單獨shuffle服務程序,對其他計算節點提供本節點上面的所有shuffle map輸出),它為遠端Executor提供了一種OpenBlocks的RPC介面,即根據請求的appid,executorid,blockid(appid+executor對應本地一組目錄,blockid拆封出)從本地磁碟中載入一組FileSegmentManagedBuffer到記憶體,並返回載入後的streamId返回給客戶端,從而支援後續的ChunkFetch的操作。
RPC是第三種核心的Message,和Stream/ChunkFetch的Message不同,每次通訊的Body是型別是確定的,在rpcHandler可以根據每種Body的型別進行相應的處理。 在Spark1.6.*版本中,也正式使用基於Netty的RPC框架來替代Akka。
Server的結構
Server構建在Netty之上,它提供兩種模型NIO和Epoll,可以通過引數(spark.[module].io.mode)進行配置,最基礎的module就是shuffle,不同的IOMode選型,對應了Netty底層不同的實現,Server的Init過程中,最重要的步驟就是根據不同的IOModel完成EventLoop和Pipeline的構造,如下所示:
//根據IO模型的不同,構造不同的EventLoop/ClientChannel/ServerChannel
EventLoopGroup createEventLoop(IOMode mode, int numThreads, String threadPrefix) { switch (mode) { case NIO: return new NioEventLoopGroup(numThreads, threadFactory); case EPOLL: return new EpollEventLoopGroup(numThreads, threadFactory); } } Class<? extends Channel> getClientChannelClass(IOMode mode) { switch (mode) { case NIO: return NioSocketChannel.class; case EPOLL: return EpollSocketChannel.class; } } Class<? extends ServerChannel> getServerChannelClass(IOMode mode) { switch (mode) { case NIO: return NioServerSocketChannel.class; case EPOLL: return EpollServerSocketChannel.class; } } //構造pipelet responseHandler = new TransportResponseHandler(channel); TransportClient client = new TransportClient(channel, responseHandler); requestHandler = new TransportRequestHandler(channel, client,rpcHandler); channelHandler = new TransportChannelHandler(client, responseHandler, requestHandler, conf.connectionTimeoutMs(), closeIdleConnections); channel.pipeline() .addLast("encoder", encoder) .addLast(TransportFrameDecoder.HANDLER_NAME, NettyUtils.createFrameDecoder()) .addLast("decoder", decoder) .addLast("idleStateHandler", new IdleStateHandler()) .addLast("handler", channelHandler);
其中,MessageEncoder/Decoder針對網路包到Message的編碼和解碼,而最為核心就TransportRequestHandler,它封裝了對所有請求/響應的處理;TransportChannelHandler內部實現也很簡單,它封裝了responseHandler和requestHandler,當從Netty中讀取一條Message以後,根據判斷路由給相應的responseHandler和requestHandler。
public void channelRead0(ChannelHandlerContext ctx, Message request) throws Exception { if (request instanceof RequestMessage) { requestHandler.handle((RequestMessage) request); } else { responseHandler.handle((ResponseMessage) request); } }
Sever提供的RPC,ChunkFecth,Stream的功能都是依賴TransportRequestHandler來實現的;從原理上來說,RPC與ChunkFecth/Stream還是有很大不同的,其中RPC對於TransportRequestHandler來說是功能依賴,而ChunkFecth/Stream對於TransportRequestHandler來說只是資料依賴。
怎麼理解?即TransportRequestHandler已經提供了ChunkFecth/Stream的實現,只需要在構造的時候,向TransportRequestHandler提供一個streamManager,告訴RequestHandler從哪裡可以讀取到Chunk或者Stream。
而RPC需要向TransportRequestHandler註冊一個rpcHandler,針對每個RPC介面進行功能實現,同時RPC與ChunkFecth/Stream都會有同一個streamManager的依賴,因此注入到TransportRequestHandler中的streamManager也是依賴rpcHandler來實現,即rpcHandler中提供了RPC功能實現和streamManager的資料依賴。
//參考TransportRequestHandler的建構函式 public TransportRequestHandler(RpcHandler rpcHandler) { this.rpcHandler = rpcHandler;//****注入功能**** this.streamManager = rpcHandler.getStreamManager();//****注入streamManager**** } //實現ChunkFecth的功能 private void processFetchRequest(final ChunkFetchRequest req) { buf = streamManager.getChunk(req.streamId, req.chunkIndex); respond(new ChunkFetchSuccess(req.streamChunkId, buf)); } //實現Stream的功能 private void processStreamRequest(final StreamRequest req) { buf = streamManager.openStream(req.streamId); respond(new StreamResponse(req.streamId, buf.size(), buf)); } //實現RPC的功能 private void processRpcRequest(final RpcRequest req) { rpcHandler.receive(reverseClient, req.body().nioByteBuffer(), new RpcResponseCallback() { public void onSuccess(ByteBuffer response) { respond(new RpcResponse(req.requestId, new NioManagedBuffer(response))); } }); }
Client的結構
Server是通過監聽一個埠,注入rpcHandler和streamManager從而對外提供RPC,ChunkFecth,Stream的服務,而Client即為一個客戶端類,通過該類,可以將一個streamId/chunkIndex對應的ChunkFetch請求,streamId對應的Stream請求,以及一個RPC資料包對應的RPC請求傳送到服務端,並監聽和處理來自服務端的響應;其中最重要的兩個類即為TransportClient和TransportResponseHandler分別為上述的“客戶端類”和“監聽和處理來自服務端的響應"。
那麼TransportClient和TransportResponseHandler是怎麼配合一起完成Client的工作呢?
<ignore_js_op>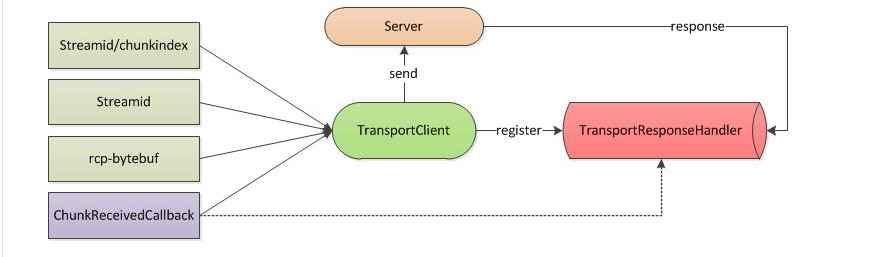
如上所示,由TransportClient將使用者的RPC,ChunkFecth,Stream的請求進行打包併發送到Server端,同時將使用者提供的回撥函式註冊到TransportResponseHandler,在上面一節中說過,TransportResponseHandler是TransportChannelHandler的一部分,在TransportChannelHandler接收到資料包,並判斷為響應包以後,將包資料路由到TransportResponseHandler中,在TransportResponseHandler中通過註冊的回撥函式,將響應包的資料返回給客戶端
//以TransportResponseHandler中處理ChunkFetchSuccess響應包的處理邏輯 public void handle(ResponseMessage message) throws Exception { String remoteAddress = NettyUtils.getRemoteAddress(channel); if (message instanceof ChunkFetchSuccess) { resp = (ChunkFetchSuccess) message; listener = outstandingFetches.get(resp.streamChunkId); if (listener == null) { //沒有監聽的回撥函式 } else { outstandingFetches.remove(resp.streamChunkId); //回撥函式,並把resp.body()對應的chunk資料返回給listener listener.onSuccess(resp.streamChunkId.chunkIndex, resp.body()); resp.body().release(); } } } //ChunkFetchFailure/RpcResponse/RpcFailure/StreamResponse/StreamFailure處理的方法是一致的
Spark Network的功能應用--BlockTransfer&&Shuffle
無論是BlockTransfer還是ShuffleFetch都需要跨executor的資料傳輸,在每一個executor裡面都需要執行一個Server執行緒(後面也會分析到,對於Shuffle也可能是一個獨立的ShuffleServer程序存在)來提供對Block資料的遠端讀寫服務。
在每個Executor裡面,都有一個BlockManager模組,它提供了對當前Executor所有的Block的“本地管理”,並對程序內其他模組暴露getBlockData(blockId: BlockId): ManagedBuffer的Block讀取介面,但是這裡GetBlockData僅僅是提供本地的管理功能,對於跨遠端的Block傳輸,則由NettyBlockTransferService提供服務。
NettyBlockTransferService本身即是Server,為其他其他遠端Executor提供Block的讀取功能,同時它即為Client,為本地其他模組暴露fetchBlocks的介面,支援通過host/port拉取任何Executor上的一組的Blocks。
NettyBlockTransferService作為一個Server
NettyBlockTransferService作為一個Server,與Executor或Driver裡面其他的服務一樣,在程序啟動時,由SparkEnv初始化構造並啟動服務,在整個執行時的一部分。
val blockTransferService =
new NettyBlockTransferService(conf, securityManager, hostname, numUsableCores)
val envInstance = new SparkEnv(executorId,rpcEnv,serializer, closureSerializer,
blockTransferService,//為SparkEnv的一個組成
....,conf)
在上文,我們談到,一個Server的構造依賴RpcHandler提供RPC的功能注入以及提供streamManager的資料注入。對於NettyBlockTransferService,該RpcHandler即為NettyBlockRpcServer,在構造的過程中,需要與本地的BlockManager進行管理,從而支援對外提供本地BlockMananger中管理的資料
"RpcHandler提供RPC的功能注入"在這裡還是屬於比較“簡陋的”,畢竟他是屬於資料傳輸模組,Server中提供的chunkFetch和stream已經足夠滿足他的功能需要,那現在問題就是怎麼從streamManager中讀取資料來提供給chunkFetch和stream進行使用呢?
就是NettyBlockRpcServer作為RpcHandler提供的一個Rpc介面之一:OpenBlocks,它接受由Client提供一個Blockids列表,Server根據該BlockIds從BlockManager獲取到相應的資料並註冊到streamManager中,同時返回一個StreamID,後續Client即可以使用該StreamID發起ChunkFetch的操作。
//case openBlocks: OpenBlocks => val blocks: Seq[ManagedBuffer] = openBlocks.blockIds.map(BlockId.apply).map(blockManager.getBlockData) val streamId = streamManager.registerStream(appId, blocks.iterator.asJava) responseContext.onSuccess(new StreamHandle(streamId, blocks.size).toByteBuffer)
NettyBlockTransferService作為一個Client
從NettyBlockTransferService作為一個Server,我們基本可以推測NettyBlockTransferService作為一個Client支援fetchBlocks的功能的基本方法:
- Client將一組Blockid表示為一個openMessage請求,傳送到服務端,服務針對該組Blockid返回一個唯一的streamId
- Client針對該streamId發起size(blockids)個fetchChunk操作。
核心程式碼如下:
//發出openMessage請求 client.sendRpc(openMessage.toByteBuffer(), new RpcResponseCallback() { @Override public void onSuccess(ByteBuffer response) { streamHandle = (StreamHandle)response;//獲取streamId //針對streamid發出一組fetchChunk for (int i = 0; i < streamHandle.numChunks; i++) { client.fetchChunk(streamHandle.streamId, i, chunkCallback); } } });
同時,為了提高服務端穩定性,針對fetchBlocks操作NettyBlockTransferService提供了非重試版本和重試版本的BlockFetcher,分別為OneForOneBlockFetcher和RetryingBlockFetcher,通過引數(spark.[module].io.maxRetries)進行配置,預設是重試3次,除非你蛋疼,你不重試!!!
在Spark,Block有各種型別,可以是ShuffleBlock,也可以是BroadcastBlock等等,對於ShuffleBlock的Fetch,除了由Executor內部的NettyBlockTransferService提供服務以外,也可以由外部的ShuffleService來充當Server的功能,並由專門的ExternalShuffleClient來與其進行互動,從而獲取到相應Block資料。功能的原理和實現,基本一致,但是問題來了?為什麼需要一個專門的ShuffleService服務呢?主要原因還是為了做到任務隔離,即減輕因為fetch帶來對Executor的壓力,讓其專心的進行資料的計算。
其實外部的ShuffleService最終是來自Hadoop的AuxiliaryService概念,AuxiliaryService為計算節點NodeManager常駐的服務執行緒,早期的MapReduce是程序級別的排程,ShuffleMap完成shuffle檔案的輸出以後,即立即退出,在ShuffleReduce過程中由誰來提供檔案的讀取服務呢?即AuxiliaryService,每一個ShuffleMap都會將自己在本地的輸出,註冊到AuxiliaryService,由AuxiliaryService提供本地資料的清理以及外部讀取的功能。
在目前Spark中,也提供了這樣的一個AuxiliaryService:YarnShuffleService,但是對於Spark不是必須的,如果你考慮到需要“通過減輕因為fetch帶來對Executor的壓力”,那麼就可以嘗試嘗試。
同時,如果啟用了外部的ShuffleService,對於shuffleClient也不是使用上面的NettyBlockTransferService,而是專門的ExternalShuffleClient,功能邏輯基本一致!
Spark Network的功能應用--新的RPC框架
Akka的通訊模型是基於Actor,一個Actor可以理解為一個Service服務物件,它可以針對相應的RPC請求進行處理,如下所示,定義了一個最為基本的Actor:
class HelloActor extends Actor { def receive = { case "hello" => println("world") case _ => println("huh?") } } // Receive = PartialFunction[Any, Unit]
Actor內部只有唯一一個變數(當然也可以理解為函數了),即Receive,它為一個偏函式,通過case語句可以針對Any資訊可以進行相應的處理,這裡Any訊息在實際專案中就是訊息包。
另外一個很重要的概念就是ActorSystem,它是一個Actor的容器,多個Actor可以通過name->Actor的註冊到Actor中,在ActorSystem中可以根據請求不同將請求路由給相應的Actor。ActorSystem和一組Actor構成一個完整的Server端,此時客戶端通過host:port與ActorSystem建立連線,通過指定name就可以相應的Actor進行通訊,這裡客戶端就是ActorRef。所有Akka整個RPC通訊系列是由Actor,ActorRef,ActorSystem組成。
Spark基於這個思想在上述的Network的基礎上實現一套自己的RPC Actor模型,從而取代Akka。其中RpcEndpoint對於Actor,RpcEndpointRef對應ActorRef,RpcEnv即對應了ActorSystem。
下面我們具體進行分析它的實現原理。
private[spark] trait RpcEndpoint { def receive: PartialFunction[Any, Unit] = { case _ => throw new SparkException() } def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = { case _ => context.sendFailure(new SparkException()) } //onStart(),onStop() }
RpcEndpoint與Actor一樣,不同RPC Server可以根據業務需要指定相應receive/receiveAndReply的實現,在Spark內部現在有N多個這樣的Actor,比如Executor就是一個Actor,它處理來自Driver的LaunchTask/KillTask等訊息。
RpcEnv相對於ActorSystem:
- 首先它作為一個Server,它通過NettyRpcHandler來提供了Server的服務能力,
- 其次它作為RpcEndpoint的容器,它提供了setupEndpoint(name,endpoint)介面,從而實現將一個RpcEndpoint以一個Name對應關係註冊到容器中,從而通過Server對外提供Service
- 最後它作為Client的介面卡,它提供了setupEndpointRef/setupEndpointRefByURI介面,通過指定Server端的Host和PORT,並指定RpcEndpointName,從而獲取一個與指定Endpoint通訊的引用。
RpcEndpointRef即為與相應Endpoint通訊的引用,它對外暴露了send/ask等介面,實現將一個Message傳送到Endpoint中。
這就是新版本的RPC框架的基本功能,它的實現基本上與Akka無縫對接,業務的遷移的功能很小,目前基本上都全部遷移完了。
RpcEnv內部實現原理
RpcEnv不僅從外部介面與Akka基本一致,在內部的實現上,也基本差不多,都是按照MailBox的設計思路來實現的;
<ignore_js_op>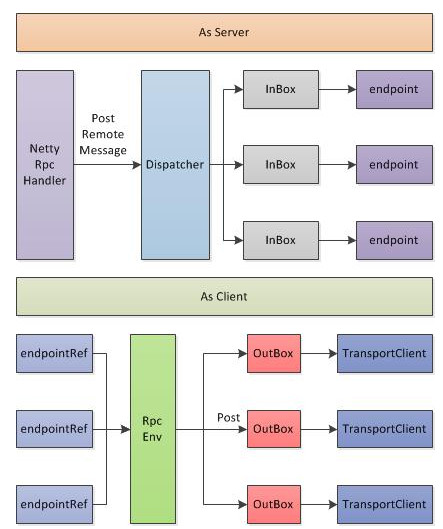
與上圖所示,RpcEnv即充當著Server,同時也為Client內部實現。 當As Server,RpcEnv會初始化一個Server,並註冊NettyRpcHandler,在前面描述過,RpcHandler的receive介面負責對每一個請求進行處理,一般情況下,簡單業務可以在RpcHandler直接完成請求的處理,但是考慮一個RpcEnv的Server上會掛載了很多個RpcEndpoint,每個RpcEndpoint的RPC請求頻率不可控,因此需要對一定的分發機制和佇列來維護這些請求,其中Dispatcher為分發器,InBox即為請求佇列;
在將RpcEndpoint註冊到RpcEnv過程中,也間接的將RpcEnv註冊到Dispatcher分發器中,Dispatcher針對每個RpcEndpoint維護一個InBox,在Dispatcher維持一個執行緒池(執行緒池大小預設為系統可用的核數,當然也可以通過spark.rpc.netty.dispatcher.numThreads進行配置),執行緒針對每個InBox裡面的請求進行處理。當然實際的處理過程是由RpcEndpoint來完成。
這就是RpcEnv As Server的基本過程!
其次RpcEnv也完成Client的功能實現,RpcEndpointRef是以RpcEndpoint為單位,即如果一個程序需要和遠端機器上N個RpcEndpoint服務進行通訊,就對應N個RpcEndpointRef(後端的實際的網路連線是公用,這個是TransportClient內部提供了連線池來實現的),當呼叫一個RpcEndpointRef的ask/send等介面時候,會將把“訊息內容+RpcEndpointRef+本地地址”一起打包為一個RequestMessage,交由RpcEnv進行傳送。注意這裡打包的訊息裡面包括RpcEndpointRef本身是很重要的,從而可以由Server端識別出這個訊息對應的是哪一個RpcEndpoint。
和傳送端一樣,在RpcEnv中,針對每個remote端的host:port維護一個佇列,即OutBox,RpcEnv的傳送僅僅是把訊息放入到相應的佇列中,但是和傳送端不一樣的是:在OutBox中沒有維護一個所謂的執行緒池來定時清理OutBox,而是通過一堆synchronized來實現的,這點值得商討。
相關推薦
Spark1.6之後為何使用Netty通訊框架替代Akka
解決方案:一直以來,基於Akka實現的RPC通訊框架是Spark引以為豪的主要特性,也是與Hadoop等分散式計算框架對比過程中一大亮點。 但是時代和技術都在演化,從Spark1.3.1版本開始,為了解決大塊資料(如Shuffle)的傳輸問題,Spark引入了Netty通訊框架,到了1.6.0版本,Netty
Spark為何使用Netty通訊框架替代Akka
轉自:http://www.aboutyun.com/thread-21115-1-1.html 問題導讀: 1. spark 如何在1.6.0之後使用Netty替代了Akka? 2. Spark Network Common怎麼實現? 3. BlockTra
Spark1.6之後為何使用Netty通信框架替代Akka
chan try 線程池大小 -- 核心概念 事情 ike 新的 inux 解決方案:一直以來,基於Akka實現的RPC通信框架是Spark引以為豪的主要特性,也是與Hadoop等分布式計算框架對比過程中一大亮點。 但是時代和技術都在演化,從Spark1.3.1版本開始,為
為什麼spark 1.6之後使用Netty來替代Akka通訊庫?
Akka的底層是使用Netty,儘管Akka能簡化訊息通訊的使用,但使用Akka要求message傳送端和接收端有相同的版本(例如spark streaming的receiver接收上游訊息要求上游的actor有相同的Akka版本) 由於spark對Akka的
Netty通訊框架Java實現小記
1、Netty介紹 Netty通俗地說就是一套Socket通訊框架,提供非同步的、事件驅動的網路應用程式框架和工具,可快速開發高效能、高可靠性的網路伺服器和客戶端程式 2、Netty的特性 1)設計 統一的API,適用於不同的協議(阻塞和非阻塞)
IO與Netty瞭解一下!網路通訊框架是這樣構成的!
隨著網際網路應用對高併發、高可用的要求越來越高,傳統的垂直架構由於其自身的侷限性逐漸被分散式、彈性伸縮的微服務架構替代。 微服務將單體應用拆分為多個獨立的微服務應用,每個應用獨立執行,每個服務間通過遠端呼叫(RPC)進行通訊,此時高效能的通訊方式就顯得尤為重要,實現RPC通訊的底層框架Netty
為什麼選擇Netty作為基礎通訊框架
在開始之前,我先講一個親身經歷的故事:曾經有兩個專案組同時用到了NIO程式設計技術,一個專案組選擇自己開發NIO服務端,直接使用JDK原生的API,結果兩個多月過去了,他們的NIO服務端始終無法穩定,問題頻出。由於NIO通訊是它們的核心元件之一,因此專案的進度受到了嚴重的影響。
高效能網路通訊框架Netty-Netty客戶端底層與Java NIO對應關係
5.1 Netty客戶端底層與Java NIO對應關係 在講解Netty客戶端程式時候我們提到指定NioSocketChannel用於建立客戶端NIO套接字通道的例項,下面我們來看NioSocketChannel是如何建立一個Java NIO裡面的SocketChannel的。 首先我們來看
高效能網路通訊框架Netty-基礎概念篇
一、前言 Netty是一種可以輕鬆快速的開發協議伺服器和客戶端網路應用程式的NIO框架,它大大簡化了TCP或者UDP伺服器的網路程式設計,但是你仍然可以訪問和使用底層的API,Netty只是對其進行了高層的抽象。 Netty的簡易和快速開發並不意味著由它開發的程式將失去可維護性或者存在效能問題
Netty學習:搭建一個簡單的Netty服務(JAVA NIO 類庫的非同步通訊框架)
http://wosyingjun.iteye.com/blog/2303296 Netty學習:搭建一個簡單的Netty服務 Netty 是一個基於 JAVA NIO 類庫的非同步通訊框架,它的架構特點是:非同步非阻塞、基於事件驅動、高效能、高可靠性和高可定製性。換句
java遊戲伺服器開發之四--通訊框架netty
前言, 說明 引入netty的pom <!-- netty --> <dependency> <groupId>io.netty</groupId> <artifactId>nett
通訊框架Netty的詳細介紹及應用
對於Netty的十一個疑問 【說明】本文原載於碼農 IO(manong.io)官方微信 developerWorks,轉載、引用請註明出處及作者。 1.Netty 是什麼? Netty 是一個基於 JAVA NIO 類庫的非同步通訊框架,它的架構特點是:非同步非
Netty通訊小框架-測試伺服器支援使用者數量
由於任務需要,寫了一個基於Netty的通訊框架,用於測試Netty可以支援多少客戶端的登入。簡單的先將原始碼上傳到自己的資源,以後再做詳細介紹。另外,Netty的通訊效率果然很高效,基於事件的通訊模型改變了以往每個連結需要一個執行緒控制的傳統模型,這種傳統
Spark通訊機制:1)Spark1.3 vs Spark1.6原始碼分析
前一段時間看了Spark1.3的原始碼,其RPC通訊機制是基於Akka的,但是在Spark1.6中,提供了2種實現方式:Netty(預設)、Akka 下面對比Spark1.3的Akka通訊機制,看下Spark1.6中Master是如何與Worker進行通訊。首先看下Spar
通訊框架 T-io 學習——給初學者的Demo:ShowCase設計分析
char bst row 重復 框架 enc 簡單介紹 packet 處理器 前言 最近閑暇時間研究Springboot,正好需要用到即時通訊部分了,雖然springboot 有websocket,但是我還是看中了 t-io框架。看了部分源代碼和示例,先把hell
通訊框架 t-io 學習——websocket 部分源碼解析
update remove leg return hashmap ext 菜鳥 未來 offset 前言 前端時間看了看t-io的websocket部分源碼,於是抽時間看了看websocket的握手和他的通訊機制。本篇只是簡單記錄一下websocket握手部分。 Web
高效能跨平臺通訊框架 HP-Socket v5.4.2
專案主頁 : http://www.oschina.net/p/hp-socket 開發文件 : http://www.docin.com/p-2137713732.html 下載地址 : https://github.com/ldcsaa/HP-
分散式通訊框架 - rmi
知識點: 1)什麼是rmi 2)簡單的實現rmi 3)rmi原理 4)手寫rmi框架 首先談下什麼RPC? Remote procedure call protocal 遠端過程呼叫協議 不用知道具體細節,呼叫遠端系統中類的方法,就跟呼叫本地方法一樣。 RPC協議其實是一種規範。 包括Dubbo,Thr
centos 重新安裝python3.6之後 yum 無法使用報錯
存在 使用 3.6 兼容 一是 報錯 oar python升級 沒有 問題: $ yum File "/usr/bin/yum", line 30 except KeyboardInterrupt, e:
Netty之框架原理分析(一)
https://blog.csdn.net/qq_18603599/article/details/80768390 netty是典型基於reatctor模型的程式設計,主要用於完成網路底層通訊的,java本身也是提供各種io的操作,但是使用起來api會很繁瑣,同時效能有很難有保證,經常會出現莫