
一個純C#寫的分散式訊息佇列介紹2
一年前,當我第一次開發完EQueue後,寫過一篇文章介紹了其整體架構,做這個框架的背景,以及架構中的所有基本概念。通過那篇文章,大家可以對EQueue有一個基本的瞭解。經過了1年多的完善,EQueue無論是功能上還是成熟性上都完善了不少。所以,希望再寫一篇文章,介紹一下EQueue的整體架構和關鍵特性。
EQueue架構
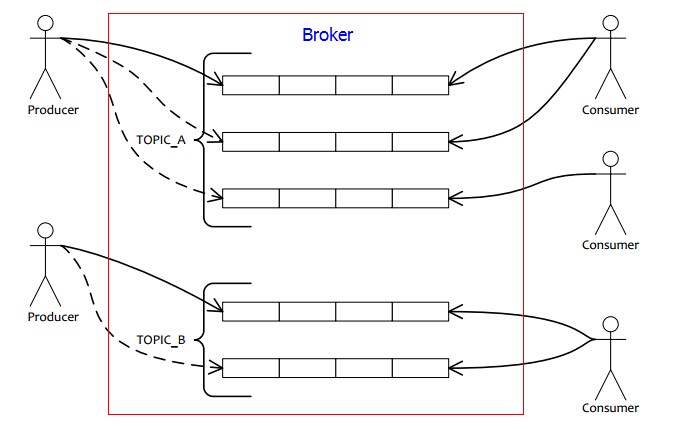
EQueue是一個分散式的、輕量級、高效能、具有一定可靠性,純C#編寫的訊息佇列,支援消費者叢集消費模式。
主要包括三個部分:producer, broker, consumer。producer就是訊息傳送者;broker就是訊息佇列伺服器,負責接收producer傳送過來的訊息,以及持久化訊息;consumer就是訊息消費者,consumer從broker採用拉模式到broker拉取訊息進行消費,具體採用的是long polling(長輪訓)的方式。這種方式的最大好處是可以讓broker非常簡單,不需要主動去推訊息給consumer,而是隻要負責持久化訊息即可,這樣就減輕了broker server的負擔。同時,consumer由於是自己主動去拉取訊息,所以消費速度可以自己控制,不會出現broker給consumer訊息推的太快導致consumer來不及消費而掛掉的情況。在訊息實時性方面,由於是長輪訓的方式,所以訊息消費的實時性也可以保證,實時性和推模型基本相當。
EQueue是面向topic的架構,和傳統的MSMQ這種面向queue的方式不同。使用EQueue,我們不需要關心queue。producer傳送訊息時,指定的是訊息的topic,而不需要指定具體傳送到哪個queue。同樣,consumer傳送訊息也是一樣,訂閱的是topic,不需要關心自己想從哪個queue接收訊息。然後,producer客戶端框架內部,會根據當前的topic獲取所有可用的queue,然後通過某種queue select strategy選擇一個queue,然後把訊息傳送到該queue;同樣,consumer端,也會根據當前訂閱的topic,獲取其下面的所有的queue,以及當前所有訂閱這個topic的consumer,按照平均的方式計算出當前consumer應該分配到哪些queue。這個分配的過程就是消費者負載均衡。
Broker的主要職責是:
傳送訊息時:負責接收producer的訊息,然後持久化訊息,然後建立訊息索引資訊(把訊息的全域性offset和其在queue中的offset簡歷對映關係),然後返回結果給producer;
消費訊息時:負責根據consumer的pull message request,查詢一批訊息(預設是一次pull request拉取最多32個訊息),然後返回給consumer;
各位看官如果對EQueue中的一些基本概念還不太清楚,可以看一下我去年寫的介紹1,寫的很詳細。下面,我想介紹一下EQueue的一些有特色的地方。
EQueue關鍵特性
高效能與可靠性設計
網路通訊模型,採用.NET自帶的SocketAsyncEventArgs,內部基於Windows IOCP網路模型。傳送訊息支援async, sync, oneway三種模式,無論是哪種模式,內部都是非同步模式。當同步傳送訊息時,就是框架幫我們在非同步傳送訊息後,同步等待訊息傳送結果,等到結果返回後,才返回給訊息傳送者;如果一定時間還不返回,則報超時異常。在非同步傳送訊息時,採用從EventStore開源專案中學習到的優秀的socket訊息傳送設計,目前測試下來,效能高效、穩定。通過幾個案例執行很長時間,沒有出現通訊層方面的問題。
broker訊息持久化的設計。採用WAL(Write-Ahead Log)技術,以及非同步批量持久化到SQL Server的方式確保訊息高效持久化且不會丟。訊息到達broker後,先寫入本地日誌檔案,這種設計在db, nosql等資料庫中很常見,都是為了確保訊息或請求不丟失。然後,再非同步批量持久化訊息到SQL Server,採用.NET自帶的SqlBulkCopy技術。這種方式,我們可以確保訊息持久化的實時性和很高的吞吐量,因為一條訊息只要寫入本地日誌檔案,然後放入記憶體的一個dict即可。
當broker意外宕機,可能會有一些訊息還沒持久化到SQL Server;所以,我們在重啟broker時,我們除了先從SQL Server恢復所有未消費的訊息到記憶體外,同時記錄當前SQL Server中的最後一條訊息的offset,然後我們從本地日誌檔案掃描offset+1開始的所有訊息,全部恢復到SQL Server以及記憶體。
需要簡單提一下的是,我們在把訊息寫入到本地日誌檔案時,不可能全部寫入到一個檔案,所以要拆檔案。目前是根據log4net來寫訊息日誌,每100MB一個日誌檔案。為什麼是100MB?是因為,我們的這個訊息日誌檔案的用途主要是用來在Broker重啟時,恢復SQL Server中最後還沒來得及持久化的那些訊息的。正常情況下,這些訊息量應該不會很多。所以,我們希望,當掃描本地日誌檔案時,儘量能快速的掃描檔案。通常100MB的訊息日誌檔案,已經可以儲存不少的訊息量,而SQL Server中未持久化的訊息通常不會超過這個量,除非當機前,出現長時間訊息無法持久化的情況,這種情況,應該會被我們監控到並及時發現,並採取措施。當然,每個訊息日誌檔案的大小,可以支援配置。另外一點,就是從日誌檔案恢復的時候,還是需要有一個演算法的,因為未被持久化的訊息,有可能不只在最近的一個訊息日誌檔案裡,有可能在多個日誌檔案裡,因為就像前面所說,會出現大量訊息沒有持久化到SQL Server的情況。
但總之,在保證高效能的前提下,訊息不丟(可靠性)是完全可以保證的。
消費訊息方面,採用批量拉取訊息進行消費的方式。預設consumer一個pull message request會最多拉取32個訊息(只要存在這麼多未消費訊息的話);然後consumer會並行消費這些消費,除了並行消費外,也可以配置為單執行緒線性消費。broker在查詢訊息時,一般情況未消費訊息總是在記憶體的,只有有一種情況不在記憶體,這個下面詳細分析。所以,查詢訊息應該說非常快。
不過上面提到的訊息可靠性,只能儘量保證單機不丟訊息。由於訊息是放在DB,以及本地日誌。所以,如果DB伺服器硬碟壞了,或者broker的硬碟壞了,那就會有丟訊息的可能性。要解決這個問題,就需要做replication了。EQueue下一步會支援broker的叢集和故障轉移(failover)。目前,我開發了一個守護程序服務,會監控broker程序是否掛掉,如果掛掉,則自動重啟,一定程度上也會提高broker的可用性。
我覺得,做事情,越簡單越好,不要一開始就搞的太複雜。複雜的東西,往往難以維護和駕馭,雖然理論很美好,但總是會出現各種問題,呵呵。就像去中心化的架構雖然理論好像很美好,但實際使用中,發現還是中心化的架構更好,更具備實戰性。
支援消費者負載均衡
消費者負載均衡是指某個topic的所有消費者,可以平均消費這個topic下的所有queue。我們使用訊息佇列,我認為這個特性非常重要。設想,某一天,我們的網站搞了一個活動,然後producer產生的訊息猛增。此時,如果我們的consumer伺服器如果還是隻有原來的數量,那很可能會來不及處理這麼多的訊息,導致broker上的訊息大量堆積。最終會影響使用者請求的響應時間,因為很多訊息無法及時被處理。
所以,遇到這種情況,我們希望分散式訊息佇列可以方便的允許我們動態新增消費者機器,提高消費能力。EQueue支援這樣的動態擴充套件能力。假如某個topic,預設有4個queue,然後每個queue對應一臺consumer機器進行消費。然後,我們希望增加一倍的consumer時,只要在EQueue Web控制檯上,為這個topic增加4個queue,然後我們再新增4臺consumer機器即可。這樣EQueue客戶端會支援自動負載均衡,幾秒鐘後,8個consumer就可以各自消費對應的queue了。然後,當活動過後,訊息量又會回退到正常水平,那麼我們就可以再減少queue,並下線多餘的consumer機器。
另外,EQueue還充分考慮到了下線queue時的平滑性,可以支援先凍結某個queue,這樣可以確保不會有新的訊息傳送到該queue。然後我們等到這個queue的訊息都消費完後,就可以下線consumer機器和刪除該queue了。這點,應該說,阿里的rocketmq也沒有做到,呵呵。
broker支援大量訊息堆積
這個特性,我之前專門寫過一篇文章,詳細介紹設計思路,這裡也簡單介紹一下。MQ的一個很重要的作用就是削峰,就是在遇到一瞬間大量訊息產生而消費者來不及一下子消費時,訊息佇列可以起到一個緩衝的作用,從而可以確保訊息消費者伺服器不會垮掉,這個就是削峰。如果使用RPC的方式,那最後所有的請求,都會壓倒DB,DB就會承受不了這麼多的請求而掛掉。
所以,我們希望MQ支援訊息堆積的能力,不能因為為了快,而只能支援把訊息放入伺服器記憶體。因為伺服器記憶體的大小是有限的,假設我們的訊息伺服器記憶體大小是128G,每個訊息大小為1KB,那差不多最多隻能堆積1.3億個訊息。不過一般來說1.3億也夠了,呵呵。但這個畢竟要求大記憶體作為前提的。但有時我們可能沒有那麼大的伺服器記憶體,但也需要堆積這麼多的訊息的能力。那就需要我們的MQ在設計上也提供支援。EQueue可以允許我們在啟動時配置broker伺服器上允許在記憶體裡存放的訊息數以及訊息佇列裡訊息的全域性offset和queueOffset的對映關係(我稱之為訊息索引資訊)的數量。我們可以根據我們的伺服器記憶體的大小進行配置。然後,broker上會有定時的掃描執行緒,定時掃描是否有多出來的訊息和訊息索引,如果有,則移除多出來的部分。通過這個設計,可以確保伺服器記憶體一定不會用完。但是否要移除也有一個前提,就是必須要求這個訊息已經持久化到SQL Server了。否則就不能移除。這個應該通常可以保證,因為一般不會出現1億個訊息都還沒持久化到DB,如果出現這個情況,說明DB一定出了什麼嚴重的問題,或者broker無法與db建立連線了。這種情況下,我們應該早就已經發現了,EQueue Web監控控制檯上隨時可以檢視訊息的最大全域性offset,已經持久化的最大全域性offset。
上面這個設計帶來的一個問題是,假如現在consumer要拉取的訊息不在記憶體了怎麼辦?一種辦法是從DB把這個訊息拉取到記憶體,但一條條拉,肯定太慢了。所以,我們可以做一個優化,就是發現當前訊息不在記憶體時,因為很可能下一條訊息也不在記憶體,所以我們可以一次性從Sql Server DB拉取10000個訊息(可配置),這樣後續的10000個訊息就一定在記憶體了,我們需要再訪問DB。這個設計其實是在記憶體使用和拉取訊息效能之間的一個權衡後的設計。Linux的pagecache的目的也是這個。
另外一點,就是我們broker重啟時,不能全部把所有訊息都恢復到記憶體,而是要判斷是否已經到達記憶體可以承受的最大訊息數了。如果已經到達,那就不能再放入記憶體了;同理,訊息索引資訊的恢復也是一樣。否則,在訊息堆積過多的時候,就會導致broker重啟時,記憶體爆掉了。
訊息消費進度更新的設計
EQueue的訊息消費進度的設計,和kafka, rocketmq是一個思路。就是定時儲存每個queue的消費進度(queue consumed offset),一個long值。這樣設計的好處是,我們不用每次消費完一個訊息後,就立即傳送一個ack回覆訊息到broker。如果是這樣,對broker的壓力是很大的。而如果只是定時傳送一個消費進度,那對broker的壓力很小。那這個消費進度怎麼來?就是採用滑動門技術。就是consumer端,在拉取到一批訊息後,先放入本地記憶體的一個SortedDictionary裡。然後繼續去拉下一批訊息。然後會啟動task去並行消費這些剛剛拉取到的訊息。所以,這個本地的SortedDictionary就是存放了所有已經拉取到本地但還沒有被消費掉的訊息。然後當某個task thread消費掉一個訊息後,會把它從SortedDictionary中移除。然後,我上面所說的滑動門技術,就是指,在每次移除一個訊息後,獲取當前SortedDictionary裡key最小的那個訊息的queue offset。隨著訊息的不斷消費,這個queue offset也會不斷增大,從巨集觀的角度看來,就像是一扇門在不停的往前移動。
但這個設計有個問題,就是假如這個Dict裡,有一個offset=100的訊息一直沒被消費掉,那就算後面的訊息都被消費了,最後這個滑動門還是不會前進。因為這個dict裡的最後的那個queue offset總是100。這個應該好理解的吧。所以這種情況下,當consumer重啟後,下次消費的位置還是會從100開始,後面的也會重新消費一遍。所以,我們的消費者內部,需要都支援冪等處理訊息。
支援訊息回溯
因為broker上的訊息,不是訊息消費掉了就立即刪除,而是定時刪除,比如每2天刪除一次(可以配置)。所以,當我們哪天希望重新消費1天前的訊息的時候,EQueue也是完全支援的。只要在consumer啟動前,修改消費進度到以前的某個特定的值即可。
Web管理控制檯
EQueue有一個完善的Web管理控制檯,我們可以通過該控制檯管理topic,管理queue,檢視訊息,檢視訊息消費進度,檢視訊息堆積情況等資訊。但是目前還不支援報警,以後會慢慢增加報警功能。
通過這個控制檯,我們使用EQueue就會方便很多,可以實時瞭解訊息佇列伺服器的健康狀況。貼一個管理控制檯的UI介面,讓大家有個印象:

EQueue未來的計劃
- broker支援叢集,master-slave模式,使其具備更高的可用性和擴充套件性;
- Web管理控制檯支援報警;
- 出一份效能測試報告,目前我主要是沒有實際伺服器,沒辦法實際測試;
- 考慮支援非DBC持久化的支援,比如本地key/value儲存支援,或者完全的本地檔案持久化訊息(難度很大);
- 其他小功能完善和程式碼區域性調整;
我相信:沒有做不好,只有沒耐心。
相關推薦
一個純C#寫的分散式訊息佇列介紹2
一年前,當我第一次開發完EQueue後,寫過一篇文章介紹了其整體架構,做這個框架的背景,以及架構中的所有基本概念。通過那篇文章,大家可以對EQueue有一個基本的瞭解。經過了1年多的完善,EQueue無論是功能上還是成熟性上都完善了不少。所以,希望再寫一篇文章,介紹一下EQueue的整體架構和關鍵特性。 E
C#的分散式訊息佇列介紹
EQueue架構 EQueue是一個分散式的、輕量級、高效能、具有一定可靠性,純C#編寫的訊息佇列,支援消費者叢集消費模式。 主要包括三個部分:producer, broker, consumer。producer就是訊息傳送者;broker就是訊息佇列伺服器,負責接收producer傳送過來的訊息
C#分散式訊息佇列 EQueue 2.0 釋出啦
前言 最近花了我幾個月的業餘時間,對EQueue做了一個重大的改造,訊息持久化採用本地寫檔案的方式。到現在為止,總算完成了,所以第一時間寫文章分享給大家這段時間我所積累的一些成果。 昨天,我寫過一篇關於EQueue 2.0效能測試結果的文章,有興趣的可以看看。 為什麼要改為檔案儲存? SQL
Kafka訊息佇列介紹、環境搭建及應用:C#實現消費者-生產者訂閱
一:kafka介紹 kafka(官網地址:http://kafka.apache.org)是一種高吞吐量的分散式釋出訂閱的訊息佇列系統,具有高效能和高吞吐率。 1.1 術語介紹 Broker Kafka叢集包含一個或多個伺服器,這種伺服器被稱為broker
分散式訊息佇列RocketMQ&Kafka -- 訊息的“順序消費”-- 一個看似簡單的複雜問題
在說到訊息中介軟體的時候,我們通常都會談到一個特性:訊息的順序消費問題。這個問題看起來很簡單:Producer傳送訊息1, 2, 3。。。 Consumer按1, 2, 3。。。順序消費。 但實際情況卻是:無論RocketMQ,還是Kafka,預設都不保證訊息
kafka分散式訊息佇列 — 基本概念介紹
轉載源:https://www.cnblogs.com/lsx1993/p/4627465.html這個應該算是之前比較火熱的詞了,一直沒時間抽出來看看。一個新東西出來,肯定是為了解決某些問題,不然不會有它的市場。先簡單看下。官方介紹:分散式、分割槽、支援複製的日誌提交系統適
分散式訊息佇列kafka系列介紹 — 基本概念
這個應該算是之前比較火熱的詞了,一直沒時間抽出來看看。一個新東西出來,肯定是為了解決某些問題,不然不會有它的市場。先簡單看下。 官方介紹:分散式、分割槽、支援複製的日誌提交系統 適用場景:顧名思義,特別適合用於系統日誌的非同步記錄,對於資料穩定性、一致性、可靠性要求不高的
大型網站架構系列:分散式訊息佇列(一)(轉)
以下是訊息佇列以下的大綱,本文主要介紹訊息佇列概述,訊息佇列應用場景和訊息中介軟體示例(電商,日誌系統)。 本次分享大綱 訊息佇列概述 訊息佇列應用場景 訊息中介軟體示例 JMS訊息服務(見第二篇:大型網站架構系列:分散式訊息佇列(二)) 常用訊息佇列(見第二篇:大型網站架構系列:分
C++封裝Linux訊息佇列
訊息佇列是Linux程序間通訊方式之一,在面向物件程式設計中,需要對其封裝。 一、訊息佇列的特點 1、非同步通訊,訊息佇列會儲存程序傳送的訊息,其他程序不一定要及時取走訊息。 2、可以傳送不同型別的訊息,訊息的頭部用long型別的欄位標記。 3、取訊息時,不一定按先進
Kafka分散式訊息佇列
基本架構 Kafka分散式訊息佇列的作用: 解耦:將訊息生產階段和處理階段拆分開,兩個階段互相獨立各自實現自己的處理邏輯,通過Kafka提供的訊息寫入和消費介面實現對訊息的連線處理。降低開發複雜度,提高系統穩定性。 高吞吐率:kafka通過順序讀寫磁碟提供可以和記憶體隨機讀寫相匹敵的讀寫速度,靈活的客戶
基於Docker搭建分散式訊息佇列Kafka
本文基於Docker搭建一套單節點的Kafka訊息佇列,Kafka依賴Zookeeper為其管理叢集資訊,雖然本例不涉及叢集,但是該有的元件都還是會有,典型的kafka分散式架構如下圖所示。本例搭建的示例包含Zookeeper + Kafka + Kafka-manger mark &
springboot2.x簡單詳細教程--訊息佇列介紹及整合ActiveMQ (第十三章)
一、JMS介紹和使用場景及基礎程式設計模型 簡介:講解什麼是小寫佇列,JMS的基礎知識和使用場景 1、什麼是JMS: Java訊息服務(Java Message Service),Java平臺中關於面向訊息中介
RabbitMQ系列之七 分散式訊息佇列應用場景之非同步處理、應用解耦、流量削鋒和訊息通訊理解分析
摘要:訊息佇列中介軟體是分散式系統中重要的元件,主要解決應用耦合,非同步訊息,流量削鋒等問題。實現高效能,高可用,可伸縮和最終一致性架構。是大型分散式系統不可缺少的中介軟體。 目前在生產環境,使用較多的訊息佇列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,
Spark Streaming實時流處理筆記(4)—— 分散式訊息佇列Kafka
1 Kafka概述 和訊息系統類似 1.1 訊息中介軟體 生產者和消費者 1.2 Kafka 架構和概念 producer:生產者(生產饅頭) consumer:消費者(吃饅頭) broker:籃子 topic : 主題,給饅頭帶一個標籤,(
Netty實戰開發(7):Netty結合kafka實現分散式訊息佇列
在分散式遊戲伺服器系統中,訊息處理佇列主要解決問題就是解耦系統中的業務,使得每個系統看起來功能比較單一,而且解決一些全服資料共享等問題。 通常我們知道kafka是作為訊息佇列比較火的一種方式,其實還有(Active MQ,Rabbit MQ,Zero MQ)個人
kafka(01)——分散式訊息佇列kafka概述
kafka是什麼? Apache Kafka是一個開源訊息系統,由Scala寫成。是由Apache軟體基金會開發的一個開源訊息系統專案。 Kafka最初是由LinkedIn開發,並於2011年初開源。 該專案的目標是為處理實時資料提供一個統一、高通量、低等待的
Kafka 和 ZooKeeper 的分散式訊息佇列
文章出處:https://blog.csdn.net/valada/article/details/80892612 訊息佇列中介軟體是分散式系統中重要的元件,主要解決應用耦合,非同步訊息,流量削鋒等問題。實現高效能,高可用,可伸縮和最終一致性架構,是大型分散式系統不可缺少的中介
訊息佇列及常見訊息佇列介紹
一、訊息佇列(MQ)概述 訊息佇列(Message Queue),是分散式系統中重要的元件,其通用的使用場景可以簡單地描述為: 當不需要立即獲得結果,但是併發量又需要進行控制的時候,差不多就是需要使用訊息佇列的時候。 訊息佇列主要解決了應用耦合、
XXL-MQ v1.2.2 釋出,分散式訊息佇列
Release Notes 1、訪問令牌(accessToken):為提升系統安全性,訊息中心和客戶端進行安全性校驗,雙方AccessToken匹配才允許通訊; 2、支援批量註冊、摘除,提升註冊發現效能;升級 xxl-rpc 至 v1.3.1; 3、升級 pom
訊息佇列介紹及選型
1.mq使用場景非同步通訊有些業務不想也不需要立即處理訊息。訊息佇列提供了非同步處理機制,允許使用者把訊息放入佇列,但並不立即處理它。想在佇列中放入多少訊息就放多少,然後在需要的時候再去處理他。解耦降低工程間的強依賴程度,針對異構系統進行適配。在專案啟動之初來預測將來專案會碰