
SQL優化——SQL子句執行順序和Join的一點總結
1.笛卡爾積(Cartesian product)
顧名思義, 這個概念得名於笛卡兒. 在數學中,兩個集合 X 和 Y 的笛卡兒積(Cartesian product),又稱直積,表示為 X × Y,是其第一個物件是 X 的成員而第二個物件是 Y 的一個成員的所有可能的有序對.
假設集合A={a,b},集合B={0,1,2},則兩個集合的笛卡爾積為{(a,0),(a,1),(a,2),(b,0),(b,1), (b,2)}。可以擴充套件到多個集合的情況。類似的例子有,如果A表示某學校學生的集合,B表示該學校所有課程的集合,則A與B的笛卡爾積表示所有可能的選課情況。
2.Join型別
cross join 是笛卡兒乘積
inner join 只返回兩張表連線列的匹配項.
left join 第一張表的連線列在第二張表中沒有匹配是,第二張表中的值返回null.
right join 第二張表的連線列在第一張表中沒有匹配是,第一張表中的值返回null.
full join 返回兩張表中的行 left join+right join.
3.在對兩表進行各種型別的join (cross, left, right, full, inner)時, 都需要構造笛卡爾積.
有時想想不可思議, 若兩個特大表進行join, 難道sql就直接上笛卡爾積嗎? 難道不事前進行on的條件過濾嗎? 那資料量得多大?
4.查一下MSDN就清楚了整個SQL的執行順序.
Processing Order of the SELECT statement
The following steps show the processing order for a SELECT statement.
1.FROM
2.ON
3.JOIN
4.WHERE
5.GROUP BY
6.WITH CUBE or WITH ROLLUP
7.HAVING
8.SELECT
9.DISTINCT
10.ORDER BY
11.TOP
也就是說, 先進行on的過濾, 而後才進行join, 這樣就避免了兩個大表產生全部資料的笛卡爾積的龐大資料.
這些步驟執行時, 每個步驟都會產生一個虛擬表,該虛擬表被用作下一個步驟的輸入。這些虛擬表對呼叫者(客戶端應用程式或者外部查詢)不可用。只是最後一步生成的表才會返回 給呼叫者。
如果沒有在查詢中指定某一子句,將跳過相應的步驟。
下面是<<Inside Microsoft SQL Server 2008 T-SQL Querying>>一書中給的一幅SQL 執行順序的插圖.
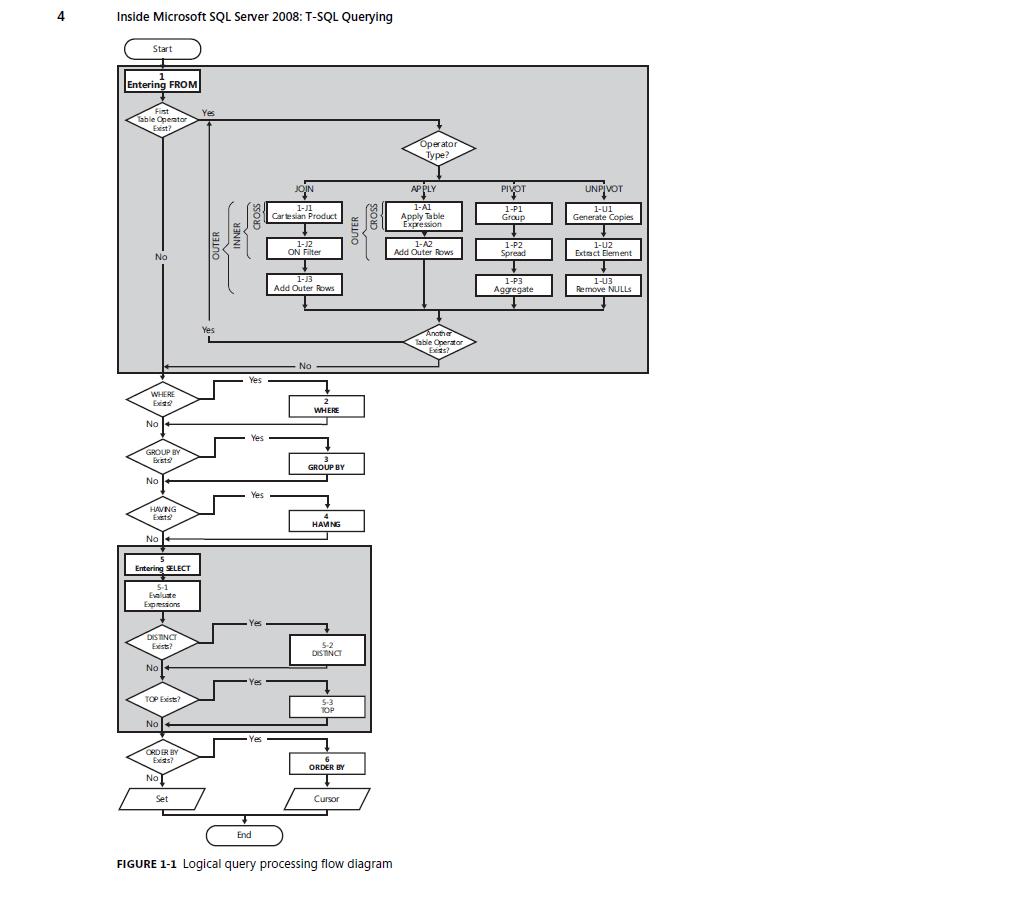
5.On的其餘過濾條件放Where裡效率更高還是更低?
select * from table1 as a
inner join table2 as b on a.id=b.id and a.status=1
select * from table1 as a
inner join table2 as b on a.id=b.id
where a.status=1
There can be predicates that involve only one of the joined tables in the ON clause. Such predicates also can be in the WHERE clause in the query. Although the placement of such predicates does not make a difference for INNER joins, they might cause a different result when OUTER joins are involved. This is because the predicates in the ON clause are applied to the table before the join, whereas the WHERE clause is semantically applied to the result of the join.
翻譯之後是, 如果是inner join, 放on和放where產生的結果一樣, 但沒說哪個效率速度更高? 如果有outer join (left or right), 就有區別了, 因為on生效在先, 已經提前過濾了一部分資料, 而where生效在後.
綜合一下, 感覺還是放在on裡更有效率, 因為它先於where執行.
聽說可以通過sql的查詢計劃來判別實際的結果, 明天再研究, 歡迎高手給與批評指正.
********************************************************************************************************
2011/11/21 最新體會
剛看到<<Microsoft SQL Server 2008技術內幕: T-SQL查詢>>一書中對於連線的描述和我先前理解的不太一樣;
Itzib在書上說先笛卡爾積, 然後再on過濾, 如果join是inner的, 就繼續往下走, 如果join 是left join, 就把on過濾掉的左主表中的資料再添加回來; 然後再執行where裡的過濾;
on中不是最終過濾, 因為後面left join還可能添加回來, 而where才是最終過濾.
只有當使用外連線(left, right)時, on 和 where 才有這個區別, 如果用inner join, 在哪裡制定都一樣, 因為on 之後就是where, 中間沒有其它步驟.
********************************************************************************************************
參考資料:
FROM (Transact-SQL)
相關推薦
SQL優化——SQL子句執行順序和Join的一點總結
1.笛卡爾積(Cartesian product) 顧名思義, 這個概念得名於笛卡兒. 在數學中,兩個集合 X 和 Y 的笛卡兒積(Cartesian product),又稱直積,表示為 X × Y,是其第一個物件是 X 的成員而第二個物件是 Y 的一個成員的所有可
SQL優化--使用 EXISTS 代替 IN 和 inner join來選擇正確的執行計劃
tool pos inner ner 使用 邏輯讀 rda jpg 分享 在使用Exists時,如果能正確使用,有時會提高查詢速度: 1,使用Exists代替inner join 2,使用Exists代替 in 1,
SQL語句的執行順序和效率
繼續 col 最好的 rom where 需要 完整 nbsp 解析 今天上午在開發的過程中,突然遇到一個問題,需要了解SQL語句的執行順序才能繼續,上網上查了一下相關的資料,現整理如下:一、sql語句的執行步驟: 1)語法分析,分析語句的語法是否符合規範,衡量語句中各表達
SQL SERVER 優化思路之 SQL查詢語句的執行順序
要優化SQL 首先我們得了解SQL的執行順序: 例子:查詢語句中select from where group by having order by的執行順序 查詢語句中select from where group by having order by的執行順序 1.
SQL查詢語句where,group by,having,order by的執行順序和編寫順序
當一個查詢語句同時出現了where,group by,having,order by的時候,執行順序和編寫順序。 一、使用count(列名)當某列出現null值的時候,count(*)仍然會計算,但是count(列名)不會。 二、資料分組(group by ): sel
45、SQL邏輯查詢語句執行順序
mysq 一定的 gif 行數據 查詢語句 客戶 prim 記錄 測試表 一 SELECT語句關鍵字的定義順序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> J
python 3 mysql sql邏輯查詢語句執行順序
shanghai 不能 結果 utf8 才會 right 完成 並且 分享 python 3 mysql sql邏輯查詢語句執行順序 一 、SELECT語句關鍵字的定義順序 SELECT DISTINCT <select_list> FROM <left
mysql五補充部分:SQL邏輯查詢語句執行順序
std data 根據 使用 cor 分析 執行過程 笛卡爾 不同的 閱讀目錄 一 SELECT語句關鍵字的定義順序 二 SELECT語句關鍵字的執行順序 三 準備表和數據 四 準備SQL邏輯查詢測試語句 五 執行順序分析 一 SELECT語句關鍵字的定義
Mysql補充部分:SQL邏輯查詢語句執行順序
num 支持 重復數 mysql 當我 每次 列表 sha mysq 一 SELECT語句關鍵字的定義順序 SELECT DISTINCT <select_list> FROM <left_table> <join_typ
mysql第四篇--SQL邏輯查詢語句執行順序
l數據庫 分組操作 一定的 內容 isp 新建 處理 hid 表示 mysql第四篇--SQL邏輯查詢語句執行順序 一.SQL語句定義順序 SELECT DISTINCT <select_list> FROM <left_table> <jo
SQL邏輯查詢語句執行順序 需要重新整理
lis highlight 虛擬表 發生 最終 數據處理 adding sql查詢 邏輯語句 一.SQL語句定義順序 1 2 3 4 5 6 7 8 9 10 SELECT DISTINCT <select_list> FROM <l
Mysql SQL優化系列之——執行計劃連線方式淺釋
關係庫SQL調優中,雖然思路都是一樣的,具體方法和步驟也是大同小異,但細節卻不容忽視,尤其是執行計劃的具體細節的解讀中,各關係庫確實有區別,特別是mysql資料庫,與其他關係庫的差別更大些,下面,我們僅就SQL執行計劃中最常見的連線方式,做以下簡要介紹和說明。 system : a syst
SQL邏輯查詢語句執行順序
number HERE 語句 order distinct type limit con lis SELECT語句語法順序 SELECT DISTINCT <select_list> FROM <left_table> <join_
sql 語句的先後執行順序
例:查詢語句中select from where group by having order by的執行順序 一般以為會按照邏輯思維執行,為: 查詢中用到的關鍵詞主要包含六個,並且他們的順序依次為 select--from--where--group by--having--ord
MySQL之新SQL優化(非同步執行)
背景 本次SQL優化是針對javaweb中的表格查詢做的。 部分網路架構圖 業務簡單說明 N個機臺將業務資料傳送至伺服器,伺服器程式將資料入庫至MySQL資料庫。伺服器中的javaweb程式將資料展示到網頁上供使用者檢視。 原資料庫設計 windows單機主從
sql查詢語句的執行順序
sql查詢語句的處理步驟如下: --查詢組合欄位 (5)select (5-2) distinct(5-3) top(<top_specification>)(5-1)<select_list> --連表 (1)from (1-J)
基層sql語句各部分執行順序
今天遇到一個問題,在使用mybatis來操作資料庫的時候。我要想通過一張中間表,來實現主表的查詢,並以前端easyui樣式中樹的形式展現出來,我利用兩個左連結left查詢資料庫的。不多說直接上查詢語句: resoure是我的主表、user_res是我的中間表 第一個查詢語句:s
sql關鍵字的解釋執行順序
有一次筆試考到了關於SQL關鍵字執行順序的知識點。 我們做軟體開發的,大部分人都離不開跟資料庫打交道,特別是erp開發的,跟資料庫打交道更是頻繁,儲存過程動不動就是上千行,如果資料量大,人員流動大,那麼我麼還能保證下一段時間系統還能流暢的執行嗎?我麼還能保證下一個人能看懂我
SQL查詢原理及執行順序
一、sql語句的執行步驟: 1)語法分析,分析語句的語法是否符合規範,衡量語句中各表示式的意義。 2) 語義分析,檢查語句中涉及的所有資料庫物件是否存在,且使用者有相應的許可權。 3)檢視轉換,將涉及檢視的查詢語句轉換為相應的對基表查詢語句。 4)表示式轉換, 將複雜的
MySQL的 SQL邏輯查詢語句執行順序
最後,這篇文章是我讀《MySQL技術內幕:SQL程式設計》而總結出來的,對於書中有的東西講的比較“粗”,可能是我的水平沒有達到人家作者要求的水平,導致閱讀起來,不是很舒服,所以,這篇博文,將會非常細緻的進行總結。只有你想不到,沒有你做不到。能看懂麼?先來一段虛擬碼,首先你能看