
Cassandra NoSQL資料模型設計指南
摘要:本文通過一個簡單的例項詳細介紹了Cassandra資料建模的五個步驟。以下是譯文。
我們最近在Instaclustr發表了一篇有關在Cassandra中經常出現的資料建模錯誤的文章。這篇文章非常受歡迎,並促使我思考如何設計出高質量的Cassandra資料模型,以避免在設計的過程中掉入陷阱。
然而,我們並沒有一個詳細的操作步驟來指導你對資料進行分析,並適配相應的規則和模式。但這份白皮書正嘗試著填補這方面的空白。
第一階段:瞭解資料
這個階段有兩個步驟,這兩個步驟都是為了更好地理解你正在建模的資料和所需的訪問模式。
定義資料域
第一步是深入理解資料域。作為一個非常熟悉關係資料建模的人,我傾向於通過繪製ER圖來理解這些實體、主鍵和互相之間的關係。但是,如果你熟悉另一種標記法,你也可以用一下試試。你需要在邏輯層面理解以下關鍵點:
- 資料模型中的實體(或物件)是什麼?
- 實體的主要關鍵屬性是什麼?
- 實體之間有哪些關係(即從一個到另一個的引用)?
- 關係的相對基數是多少(例如,假設存在一對多的關係,那麼平均是1對10,還是1對10000)?
定義所需的訪問模式
下一步,弄清楚你自己需要如何訪問資料:
- 列出需要訪問資料的路徑,例如:
- 以客戶ID為索引,在某個日期範圍內搜尋交易記錄,然後從搜尋結果中搜索特定交易的詳細資訊。按某個特定的伺服器和度量標準搜尋,檢索x度量值,按年齡升序排列。
- 按某個特定的伺服器和度量檢索,從特定時間點開始檢索x度量值。
- 對於給定的感測器,檢索給定日期的多個度量的所有讀數。
- 對於給定的感測器,檢索當前值。
- 請記住,對記錄的任何更新操作都是一個訪問路徑,都需要仔細考慮。
- 從效能的角度來確定哪些訪問最關鍵。是否有一些訪問需要儘可能快的速度,而其他一些訪問則需要花一定的時間進行多次讀取或在一定範圍內進行檢索?
- 請記住,在這個階段,你需要非常全面地瞭解如何訪問資料,在Cassandra的效能、可靠性和可伸縮性之間做出權衡。
第二階段:瞭解實體
這個階段有兩個具體的步驟,旨在瞭解與資料相關的主要和次要實體。
確定主要訪問實體
現在,我們開始從分析資料域和應用需求轉為開始設計資料模型了。在進入這個階段之前,你需要把上面兩個步驟的工作做得紮實一點。
這一階段主要的想法是根據你所使用的訪問模式將資料去規範化到儘可能少的表中。對於每一次按鍵進行的查詢,需要有一張表來滿足查詢需求。我創造了一個術語“主要訪問實體”來描述用於查詢的實體(例如,按客戶ID進行的查詢將使用客戶表作為主要訪問實體,按伺服器和度量名稱的查詢將使用伺服器-度量實體作為主要訪問實體)。
主要訪問實體定義了去規範化結果表的分割槽級別(即表會為每個主要訪問實體的例項提供一個分割槽)。
你可以選擇使用二級索引來滿足一些訪問模式,而不是使用不同的主要訪問實體來實現資料複製。請記住,包含在輔助索引中的列應比被索引的表的基數更低,並且你要對索引值的更新頻率瞭如指掌。
對於上面舉的訪問模式的例子,我們將定義以下主要訪問實體:
- 客戶和交易(從客戶實體獲取交易清單,然後從交易實體查詢交易詳情)
- 伺服器-度量
- 感測器
- 感測器
分配次要實體
下一步是尋找一個地方用來儲存那些沒有被選為主要訪問實體的實體資料(這些實體被稱為次要實體)。你可以這樣做:
- 通過從一對多關係的父級次要實體獲取資料並在主要訪問實體級別儲存它的多個副本(例如,將客戶的電話號碼儲存在客戶的訂單記錄中)。
- 通過從一對多關係的子次要實體獲取資料並通過使用聚集鍵或通過使用多值型別(列表和對映)將其儲存在主要訪問實體級別上(例如,將記錄項列表新增到交易表中)。
對於一些次要實體,只有一個相關的主要訪問實體,所以不需要選擇在哪個方向推入資料。對於其他實體,你需要選擇將資料推入哪些主要訪問實體。
為了獲得最佳的讀取效能,需要將資料副本推送到用作次要實體中資料訪問路徑的每個主要訪問實體中。
然而,維護多個副本資料會影響到資料插入和更新的效能,並會增加應用程式的複雜性。因此,需要根據應用程式指定的效能要求在讀取效能與資料維護成本之間做出權衡。
在這個階段要做出的另一個決定是要選擇使用聚集鍵還是多值型別來進行資料推升。一般來說:
- 在只有一個子次要實體向上推升的情況下使用聚集鍵,特別是在子次要實體本身有子節點上卷的情況下。
- 在有多個子實體推升到主要實體的時候使用多值型別
請注意,這些規則可能比較簡單,但它們可以引申出對這方面更深入的思考。
第三階段:稽核與調優
最後一個階段則是在必要的情況下對資料模型進行稽核、測試,以及調優。
稽核分割槽和聚集鍵
在這個階段中,你需要將所有需要儲存的資料分配到一個或多個表中,並且這些表需要支援所需的訪問模式。下一步是檢查生成的資料模型是否有效地使用了Cassandra,如果沒有,則進行調優。在這個階段,需要檢查和調整的內容包括:
分割槽鍵是否有足夠的基數?如果沒有,則可能需要將列從聚集鍵變為分割槽鍵(例如,將主鍵(client_id,timestamp)更改為主鍵((client_id,timestamp)))或引入將多個聚集鍵分組為分割槽的新列(例如,將主鍵(client_id,timestamp)更改為主鍵((client_id,day),timestamp))。
分割槽鍵中的值是否會經常更新?對主鍵的更新將導致記錄的刪除和重新插入。例如,在一個維護了所有客戶的狀態的表中,可能有主鍵(狀態,客戶ID)。但是,這將導致每當客戶狀態發生變化時都需要刪除並重新插入記錄。在這種情況下,最好選擇集合或列表資料型別,而不是將客戶ID作為聚集鍵。
每個分割槽中的記錄數是否有限制?特別大的分割槽和或者分佈非常不均勻的分割槽可能會出現問題。例如,假設有一張client_updates表,其主鍵為(client_id,update_timestamp),則客戶記錄的更新次數可能並沒有限制,因為可能有少量的客戶已經有10年未更新,而大多數客戶只有一兩天而已。
測試和調優
最後一步,也可能是最重要的,即對資料模型進行測試,並根據需要進行調優。請記住,像分割槽或記錄數增長過快的問題只有在實際負載下使用幾天(或更長時間)之後才能發現。因此,測試的時候需要儘可能地接近真實負載,並密切監視各種警告資訊(nodetool cfstats和cfhistograms命令對此非常有用)。
在這個階段,你也可以考慮調整一些影響資料物理儲存的設定。例如:
- 改變壓縮策略;
- 如果只使用TTL來刪除資料的話,則可以降低gc_grace_seconds,或者
- 設定快取選項。
一個完整的例子
為了說明這一點,下文將介紹一個示例,該示例構建了一個數據庫,用於儲存和檢索來自多個伺服器的日誌訊息。請注意,與大多數實際的案例相比,這個例子非常簡單。
步驟1:定義資料域
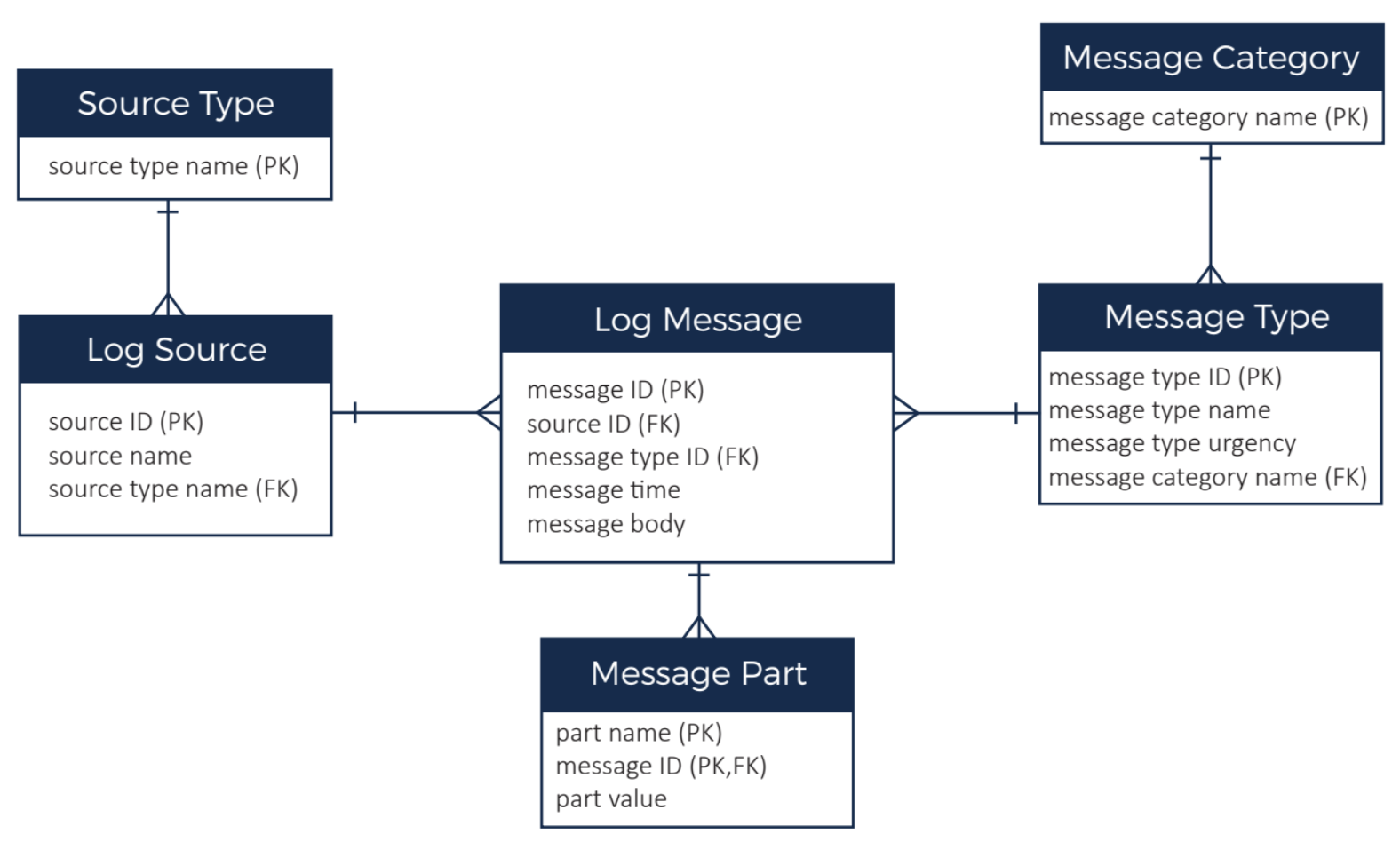
上面的ER圖描述了本示例的資料域,包括:
- 有很多(百萬數量級)的日誌訊息,有時間戳和主體。儘管訊息ID在ER圖中顯示為主鍵,但訊息時間加訊息型別是備用主鍵。
- 每個日誌訊息都有一個訊息型別,多個型別被進一步分組為一個訊息類別(例如,訊息型別可能是“記憶體不足錯誤”,類別可能是“錯誤”)。有幾百個訊息型別和大約20個類別。
- 每個日誌訊息來自一個訊息源。訊息源是生成訊息的伺服器。我們的系統中有1000臺伺服器。每個訊息源都有一個源型別對其進行分類(如紅帽伺服器、Ubuntu伺服器、Windows伺服器、路由器等)。有大約20個源型別。每個源每天有大約10000條訊息。
- 訊息體可以被解析並存儲為多個訊息體(一般來說是鍵值對)。每條訊息通常不超過20個訊息體。
步驟2:定義所需的訪問模式
我們需要能夠:
- 檢索給定源的最近10條訊息的所有可用資訊(並且能夠從中及時回溯)。
- 檢索給定源型別的最近10條訊息的所有可用資訊。
步驟3:確定主要訪問實體
這裡有兩個主要訪問實體:源和源型別。源型別的基數(約為20)使其非常適合成為二級索引,所以我們將使用源作為主要訪問實體,並新增源型別為二級索引。
步驟4:分配次要實體
在這個例子中,這個步驟相對簡單,因為所有資料都需要滾入到日誌源主要訪問實體中。所以我們需要:
- 下推源型別名稱
- 下推訊息類別和訊息型別以記錄訊息
- 上推日誌訊息,使其作為新實體的聚集鍵
- 作為map型別上推訊息體。
最終這將是一個帶有源ID分割槽鍵和(訊息時間,訊息型別)聚集鍵的單個表。
步驟5:稽核分割槽和聚集鍵
根據檢查清單檢查這些分割槽和聚集鍵:
- 分割槽鍵是否有足夠的基數?是的,有1000個源。
- 分割槽鍵中的值是否會經常更新?不,所有的資料都是一次寫入的。
- 每個分割槽中的記錄數是否有限制?不,訊息數可能會隨著時間的推移而無限地增長。
所以,我們需要解決無限分割槽大小的問題。在時間序列資料中,解決這個問題的典型模式是將一組時間段引入到聚集鍵中。在這種情況下,每天10000條訊息是一個比較合理的數字,可以包含在一個分割槽中,因此我們將使用“天”作為分割槽鍵的一部分。
最後,Cassandra結果表是這樣的:
CREATE TABLE example.log_messages (
message_id uuid,
source_name text,
source_type text,
message_type text,
message_urgency int,
message_category text,
message_time timestamp,
message_time_day text,
message_body text,
message_parts map<text, frozen>
PRIMARY KEY ((source_name, message_time_day,message_time, message_type)
) WITH CLUSTERING ORDER BY (message_time DESC);
CREATE INDEX log_messages_sourcetype_idx ON example.log_messages (source_type);相關推薦
Cassandra NoSQL資料模型設計指南
摘要:本文通過一個簡單的例項詳細介紹了Cassandra資料建模的五個步驟。以下是譯文。 我們最近在Instaclustr發表了一篇有關在Cassandra中經常出現的資料建模錯誤的文章。這篇文章非常受歡迎,並促使我思考如何設計出高質量的Cassandra
Cassandra資料模型設計最佳實踐(上)
本文是Cassandra資料模型設計第一篇(全兩篇),該系列文章包含了eBay使用Cassandra資料模型設計的一些實踐。其中一些最佳實踐我們是通過社群學到的,有些對我們來說也是新知識,還有一些仍然具有爭議性,可能在要通過進一步的實踐才能從中獲益。 本文中,我將會講解一些
Cassandra 資料模型設計總結
結合前段時間使用Cassandra使用過程,團隊簡單總結了Cassandra 資料模型設計,請大家斧正。 1、相關概念 Column:Cassandra中的最基本的儲存單元,用於儲存某一行的資訊;
Cassandra資料模型設計最佳實踐(上部)
本文是Cassandra資料模型設計第一篇(全兩篇),該系列文章包含了eBay使用Cassandra資料模型設計的一些實踐。其中一些最佳實踐我們是通過社群學到的,有些對我們來說也是新知識,還有一些仍然具有爭議性,可能在要通過進一步的實踐才能從中獲益。 本文中,我將會講解
SaaS系統中的資料模型設計思路
共享資料庫 單獨模式(Schema)第二種方式則是所有客戶使用同一資料庫,但各自擁有一套不同的資料表組合存在於其單獨的模式之內。 圖3. 獨立模式(Schema)在這種資料模型下,當客戶嘗試第一次使用該SaaS系統時,系統在建立使用者環境時會建立一整套預設的表結構,同時將其關聯到該客戶的獨立模式。此時一般
理論篇~第三章 資料模型設計
常見資料模型介紹 1 ER模型 資料倉庫之父Bill Inmon提出的建模方法,是從全企業的高度設計一個3NF模型,用實體關係(Entity Relationship,ER)模型描述企業業務。其具有以下幾個特點: 需要全面瞭解企業業務和資料 實施週期非
MongoDB 資料模型設計
一個高效的資料模型能夠很好的滿足你應用程式的需求。設計一個文件資料結構最關鍵的考量就是決定是否使用嵌入式還是引用。 1. 內嵌式資料模型 在MongoDB裡面,你可以把相關的資料包括在一個單個的結構或者文件下面。這樣的資料模式也叫做 “非規範化” 模式,它
MongoDB資料模型設計學習
近來需要設計使用MongoDB,想簡要學習一下。 MongoDB的資料模式是一種靈活模式,其集合並不限制文件結構。這種靈活性讓物件和資料庫文件之間的對映變得很容易,及時資料記錄之間有很大的變化,每個文件也可以很好的對映到各條不同的記錄。但在實際使用中,同一個集
淺談BI領域的資料模型設計(二)
/**********************************/目錄:第一部分:基礎概念第二部分:設計方式第三部分:銀行業資料模型基本概念介紹第四部分:銀行業資料模型分主題介紹第五部分:ODS和EDW/**********************************/第三部分:銀行業資料模型基本
cassandra的資料模型
ColumnFamily裡的每條記錄都是一個key-value對,value部分存放的是無限制的Columns。每個Column都有一個Column Name和value,因此Column實際也是一個key-value對。但Column的value部分已經是最基本的資料儲存單元,不能再向下嵌套
RGW 資料模型設計
ceph是一個開源的統一分散式儲存系統,RADOS是提供了底層基礎物件儲存服務,它由mon和osd組成。RADOS主要操作的物件有pool,object和object的xattr、omap。 rados gateway是基於RADOS的一個物件儲存服務,對外提
asp.net core高階EF Core2.0資料模型設計建立
在我當前開源的Zop框架中,網站的底層資料模型被設計為利用EF Core,並通過反射來進行批量建立模型資料上下文。 1、建立資料模型 /// <summary> /// 群組 /// </summary> publi
圖書 Framework 設計指南: 可重用 .NET 庫的約定、慣用法和模式 引出資料
-- tps frame focus doc 框架設計 uid 微軟 spa 文章:框架設計準則 --微軟 地址:https://docs.microsoft.com/zh-cn/dotnet/standard/design-guidelines/ind
MT6165使用手冊,MT6165晶片設計指南資料
MT6165與MT6169 使用 META 上的差異 RX – Path Loss : • 可以由meta config file來選擇以high LNA gain 來cal pathloss或分high/middle/low LNA gain來cal pathloss
TensorFlow 高效能資料輸入管道設計指南
作者:黑暗星球 原文地址:https://blog.csdn.net/u014061630/article/details/80776975 TensorFlow版本:1.12.0 本篇主要介紹怎麼使用
時序資料庫技術體系(一):時序資料儲存模型設計
時序資料庫技術體系中一個非常重要的技術點是時序資料模型設計,不同的時序系統有不同的設計模式,而不同的設計模式對時序資料的讀寫效能、資料壓縮效率等各個方面都有非常重要的影響。這篇文章筆者將會分別針對OpenTSDB、Druid、InfluxDB以及Beringei這四個時序系統中的時序資料模型設計進行
《資料密集型應用系統設計》第二章 資料模型與查詢語言
概述 本章從資料庫之初的資料模型開始介紹(20世紀60年代),從使用者使用的角度分析了每種資料模型的優缺點。就目前國內網際網路儲存來看實際用處並不大,對於網際網路分散式儲存開發工程師更多的意義是提供了一個全面(發展歷程)、籠統的瞭解資料庫的發展。 在資料模型部分介紹了,關係
三個例子,讓你看懂資料倉庫多維資料模型的設計
一、概述 多維資料模型是最流行的資料倉庫的資料模型,多維資料模型最典型的資料模式包括星型模式、雪花模式和事實星座模式,本文以例項方式展示三者的模式和區別。 二、星型模式(star schema) 星型模式的核心是一個大的中心表(事實表),一組小的附屬表(維表)。
PowerDesigner設計邏輯資料模型的做法
轉自:深藍居 http://www.cnblogs.com/studyzy/archive/2009/12/15/1624899.html 在PD中建立物理模型由以下幾種辦法: 直接新建物理模型。 設計好概念模型,然後由概念模型生成物理模型。 設
Asp.Net MVC4入門指南(8):給資料模型新增校驗器
在本節中將會給Movie模型新增驗證邏輯。並且確保這些驗證規則在使用者建立或編輯電影時被執行。 保持事情 DRY ASP.NET MVC 的核心設計信條之一是DRY: "不要重複自己(Don’t Repeat Yourself)"。ASP.NET MVC鼓勵您指定功能或者行為,只做一次,然後將它應用到應用