
OpenCV人臉識別知識
目前的人臉檢測方法主要有兩大類:基於知識和基於統計。
Ø 基於知識的方法:主要利用先驗知識將人臉看作器官特徵的組合,根據眼睛、眉毛、嘴巴、鼻子等器官的特徵以及相互之間的幾何位置關係來檢測人臉。
Ø 基於統計的方法:將人臉看作一個整體的模式——二維畫素矩陣,從統計的觀點通過大量人臉影象樣本構造人臉模式空間,根據相似度量來判斷人臉是否存在。
基於知識的人臉檢測方法:
模板匹配、人臉特徵、形狀與邊緣、紋理特性、顏色特徵
基於統計的人臉檢測方法:
主成分分析與特徵臉、神經網路方法、支援向量機、隱馬爾可夫模型、Adaboost演算法
聚類和分類的區別是什麼?
Ø 分類:一般對已知物體類別總數的識別方式我們稱之為分類,並且訓練的資料是有標籤的,比如已經明確指定了是人臉還是非人臉,這是一種有監督學習。
Ø 聚類:也存在可以處理類別總數不確定的方法或者訓練的資料是沒有標籤的,這就是聚類,不需要學習階段中關於物體類別的資訊,是一種無監督學習。
其中包括Mahalanobis距離、K均值、樸素貝葉斯分類器、決策樹、Boosting、隨機森林、Haar分類器、期望最大化、K近鄰、神經網路、支援向量機。
我們要探討的Haar分類器實際上是Boosting演算法的一個應用,Haar分類器用到了Boosting演算法中的AdaBoost演算法,只是把AdaBoost演算法訓練出的強分類器進行了級聯,並且在底層的特徵提取中採用了高效率的矩形特徵和積分圖方法,這裡涉及到的幾個名詞接下來會具體討論。
Haar分類器 = Haar-like
Haar分類器演算法的要點如下:
① 使用Haar-like特徵做檢測。
② 使用積分圖(Integral Image)對Haar-like特徵求值進行加速。
③ 使用AdaBoost演算法訓練區分人臉和非人臉的強分類器。
④ 使用篩選式級聯把強分類器級聯到一起,提高準確率。
/* * CART classifier */ typedef struct CvCARTHaarClassifier { CV_INT_HAAR_CLASSIFIER_FIELDS() int count; int* compidx; CvTHaarFeature* feature; CvFastHaarFeature* fastfeature; float* threshold; int* left; int* right; float* val; } CvCARTHaarClassifier;
CART這個詞,它是一種二叉決策樹 ,“分類和迴歸樹(CART)”。
什麼是決策樹?
“機器學習中,決策樹是一個預測模型;他代表的是物件屬性與物件值之間的一種對映關係。樹中每個節點表示某個物件,而每個分叉路徑則代表的某個可能的屬性值,而每個葉結點則對應從根節點到該葉節點所經歷的路徑所表示的物件的值。決策樹僅有單一輸出,若欲有複數輸出,可以建立獨立的決策樹以處理不同輸出。從資料產生決策樹的機器學習技術叫做決策樹學習, 通俗說就是決策樹。”
決策樹包含:分類樹,迴歸樹,分類和迴歸樹(CART),CHAID 。
分類和迴歸的區別是,分類是當預計結果可能為兩種型別(例如男女,輸贏等)使用的概念。
迴歸是當局域結果可能為實數(例如房價,患者住院時間等)使用的概念。
決策樹用途很廣可以分析因素對事件結果的影響,同時也是很常用的分類方法,我舉個最簡單的決策樹例子,假設我們使用三個Haar-like特徵f1,f2,f3來判斷輸入資料是否為人臉,可以建立如下決策樹:
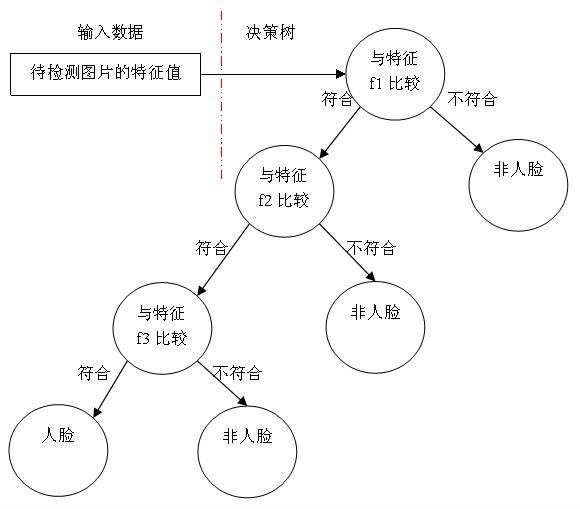
可以看出,在分類的應用中,每個非葉子節點都表示一種判斷,每個路徑代表一種判斷的輸出,每個葉子節點代表一種類別,並作為最終判斷的結果。
一個弱分類器就是一個基本和上圖類似的決策樹,最基本的弱分類器只包含一個Haar-like特徵,也就是它的決策樹只有一層,被稱為樹樁(stump)。
具體操作過程如下:
1)對於每個特徵 f,計算所有訓練樣本的特徵值,並將其排序。
掃描一遍排好序的特徵值,對排好序的表中的每個元素,計算下面四個值:
全部人臉樣本的權重的和t1;
全部非人臉樣本的權重的和t0;
在此元素之前的人臉樣本的權重的和s1;
在此元素之前的非人臉樣本的權重的和s0;
2)最終求得每個元素的分類誤差![]()
在表中尋找r值最小的元素,則該元素作為最優閾值。有了該閾值,我們的第一個最優弱分類器就誕生了。
在這漫長的煎熬中,我們見證了一個弱分類器孵化成長的過程,並回答瞭如何得到弱分類器以及二叉決策樹是什麼。最後的問題是強分類器是如何得到的。
首先看一下強分類器的程式碼結構:
/* internal stage classifier */
typedef struct CvStageHaarClassifier
{
CV_INT_HAAR_CLASSIFIER_FIELDS()
int count;
float threshold;
CvIntHaarClassifier** classifier;
}CvStageHaarClassifier;/* internal weak classifier*/
typedef struct CvIntHaarClassifier
{
CV_INT_HAAR_CLASSIFIER_FIELDS()
} CvIntHaarClassifier;這裡要提到的是CvIntHaarClassifier結構:它就相當於一個介面類,當然是用C語言模擬的面向物件思想,利用CV_INT_HAAR_CLASSIFIER_FIELDS()這個巨集讓弱分類CvCARTHaarClassifier和強分類器CvStageHaarClassifier繼承於CvIntHaarClassifier。
強分類器的誕生需要T輪的迭代,具體操作如下:
1. 給定訓練樣本集S,共N個樣本,其中X和Y分別對應於正樣本和負樣本; T為訓練的最大迴圈次數;
2. 初始化樣本權重為1/N ,即為訓練樣本的初始概率分佈;
3. 第一次迭代訓練N個樣本,得到第一個最優弱分類器,步驟見上
4. 提高上一輪中被誤判的樣本的權重;
5. 將新的樣本和上次本分錯的樣本放在一起進行新一輪的訓練。
6. 迴圈執行4-5步驟,T輪後得到T個最優弱分類器。
7.組合T個最優弱分類器得到強分類器
相當於讓所有弱分類器投票,再對投票結果按照弱分類器的錯誤率加權求和,將投票加權求和的結果與平均投票結果比較得出最終的結果
至今為止我們好像一直在講分類器的訓練,實際上Haar分類器是有兩個體系的,訓練的體系,和檢測的體系。訓練的部分大致都提到了,還剩下最後一部分就是對篩選式級聯分類器的訓練。我們看到了通過AdaBoost演算法辛苦的訓練出了強分類器,然而在現實的人臉檢測中,只靠一個強分類器還是難以保證檢測的正確率,這個時候,需要一個豪華的陣容,訓練出多個強分類器將它們強強聯手,最終形成正確率很高的級聯分類器這就是我們最終的目標Haar分類器。
那麼訓練級聯分類器的目的就是為了檢測的時候,更加準確,這涉及到Haar分類器的另一個體系,檢測體系,檢測體系是以現實中的一幅大圖片作為輸入,然後對圖片中進行多區域,多尺度的檢測,所謂多區域,是要對圖片劃分多塊,對每個塊進行檢測,由於訓練的時候用的照片一般都是20*20左右的小圖片,所以對於大的人臉,還需要進行多尺度的檢測,多尺度檢測機制一般有兩種策略,一種是不改變搜尋視窗的大小,而不斷縮放圖片,這種方法顯然需要對每個縮放後的圖片進行區域特徵值的運算,效率不高,而另一種方法,是不斷初始化搜尋視窗size為訓練時的圖片大小,不斷擴大搜索視窗,進行搜尋,解決了第一種方法的弱勢。在區域放大的過程中會出現同一個人臉被多次檢測,這需要進行區域的合併,這裡不作探討。
無論哪一種搜尋方法,都會為輸入圖片輸出大量的子視窗影象,這些子視窗影象經過篩選式級聯分類器會不斷地被每一個節點篩選,拋棄或通過。
/* internal tree cascade classifier node */
typedef struct CvTreeCascadeNode
{
CvStageHaarClassifier* stage;
struct CvTreeCascadeNode* next;
struct CvTreeCascadeNode* child;
struct CvTreeCascadeNode* parent;
struct CvTreeCascadeNode* next_same_level;
struct CvTreeCascadeNode* child_eval;
int idx;
int leaf;
} CvTreeCascadeNode;
/* internal tree cascade classifier */
typedef struct CvTreeCascadeClassifier
{
CV_INT_HAAR_CLASSIFIER_FIELDS()
CvTreeCascadeNode* root; /* root of the tree */
CvTreeCascadeNode* root_eval; /* root node for the filtering */
int next_idx;
} CvTreeCascadeClassifier;我們熟悉了Haar-like分類器的訓練和檢測過程,你會看到無論是訓練還是檢測,每遇到一個圖片樣本,每遇到一個子視窗影象,我們都面臨著如何計算當前子影象特徵值的問題,一個Haar-like特徵在一個視窗中怎樣排列能夠更好的體現人臉的特徵,這是未知的,所以才要訓練,而訓練之前我們只能通過排列組合窮舉所有這樣的特徵,僅以Viola牛提出的最基本四個特徵為例,在一個24×24size的視窗中任意排列至少可以產生數以10萬計的特徵,對這些特徵求值的計算量是非常大的。
而積分圖就是隻遍歷一次影象就可以求出影象中所有區域畫素和的快速演算法,大大的提高了影象特徵值計算的效率。
我們來看看它是怎麼做到的。
積分圖是一種能夠描述全域性資訊的矩陣表示方法。積分圖的構造方式是位置(i,j)處的值ii(i,j)是原影象(i,j)左上角方向所有畫素的和:
![]()
積分圖構建演算法:
1)用s(i,j)表示行方向的累加和,初始化s(i,-1)=0;
2)用ii(i,j)表示一個積分影象,初始化ii(-1,i)=0;
3)逐行掃描影象,遞迴計算每個畫素(i,j)行方向的累加和s(i,j)和積分影象ii(i,j)的值
s(i,j)=s(i,j-1)+f(i,j)
ii(i,j)=ii(i-1,j)+s(i,j)
4)掃描影象一遍,當到達影象右下角畫素時,積分影象ii就構造好了。
積分圖構造好之後,影象中任何矩陣區域的畫素累加和都可以通過簡單運算得到如圖所示。
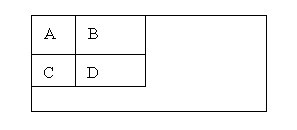
設D的四個頂點分別為α、β、γ、δ,則D的畫素和可以表示為
Dsum = ii( α )+ii( β)-(ii( γ)+ii( δ ));
而Haar-like特徵值無非就是兩個矩陣畫素和的差,同樣可以在常數時間內完成。
搜尋視窗的搜尋區域是提高效率的關鍵
OpenCV的人臉檢測主要是呼叫訓練好的cascade(Haar分類器)來進行模式匹配。
cvHaarDetectObjects,先將影象灰度化,根據傳入引數判斷是否進行canny邊緣處理(預設不使用),再進行匹配。匹配後收集找出的匹配塊,過濾噪聲,計算相鄰個數如果超過了規定值(傳入的min_neighbors)就當成輸出結果,否則刪去。
匹配迴圈:將匹配分類器放大scale(傳入值)倍,同時原圖縮小scale倍,進行匹配,直到匹配分類器的大小大於原圖,則返回匹配結果。匹配的時候呼叫cvRunHaarClassifierCascade來進行匹配,將所有結果存入CvSeq* Seq (可動態增長元素序列),將結果傳給cvHaarDetectObjects。
cvRunHaarClassifierCascade函式整體是根據傳入的影象和cascade來進行匹配。並且可以根據傳入的cascade型別不同(樹型、stump(不完整的樹)或其他的),進行不同的匹配方式。
函式 cvRunHaarClassifierCascade 用於對單幅圖片的檢測。在函式呼叫前首先利用 cvSetImagesForHaarClassifierCascade設定積分圖和合適的比例係數 (=> 視窗尺寸)。當分析的矩形框全部通過級聯分類器每一層的時返回正值(這是一個候選目標),否則返回0或負值。
在給定位置的影象中執行 cascade of boosted classifier
int cvRunHaarClassifierCascade( CvHaarClassifierCascade* cascade,
CvPoint pt, int start_stage=0 );cascade Haar 級聯分類器
pt 待檢測區域的左上角座標。待檢測區域大小為原始視窗尺寸乘以當前設定的比例係數。當前視窗尺寸可以通過cvGetHaarClassifierCascadeWindowSize重新得到。
start_stage 級聯層的初始下標值(從0開始計數)。函式假定前面所有每層的分類器都已通過。這個特徵通過函式cvHaarDetectObjects內部呼叫,用於更好的處理器高速緩衝儲存器。
correction_ratio = weight_scale * (!feature->tilted ? 1 : 0.5);
其中:
weight_scale = 1./(equRect.width*equRect.height);
cascade->inv_window_area = weight_scale;
weight_scale就是面積分之一。我個人理解correction_ratio就是看你的haar-like特徵旋轉沒,
若旋轉過則:要乘以1/2。若沒有就是原面積。
然後去乘以矩形內的畫素和就應該是該haar—like的特徵值了。
該演算法的主要貢獻有三:
1.提出積分影象(integral image),從而可以快速計算Haar-like特徵。
2.利用Adaboost學習演算法進行特徵選擇和分類器訓練,把弱分類器組合成強分類器。
3.採用分類器級聯提高效率。
DSP 演算法優化~
線性彙編
當C語言級的優化仍不能滿足要求時,應採用彙編級優化。測試中發現,一些程式很短,但在板子上上執行相當耗時,這類程式考慮用線性彙編優化。如:浮點數的四則運算。
迴圈優化
在程式2中,使用這種方法優化:
1)迴圈變數儘量不參加運算,直接給出迴圈變數的值;
2)迴圈巢狀時,儘可能開啟最裡面的小迴圈,才能形成軟體流水。
線性彙編
當C語言級的優化仍不能滿足要求時,應採用彙編級優化。測試中發現,一些程式很短,但在DM642上執行相當耗時,這類程式考慮用線性彙編優化。如:浮點數的四則運算。
DM6447是定點DSP,浮點數運算佔用大量的執行時間,可採用下面的方法優化:
1)在程式中,要儘量把浮點運算轉化為定點運算,比如採用定標的方式;
2)編寫浮點運算對應的線性彙編程式。
二級快取L2的使用
增大Cache,可以明顯提高效能,但是DM642中二級Cache共享片內RAM,因此增大Cache,就減小了實際的片內可用空間,在優化設計時必須綜合考慮。在本文系統中,經常
用到兩個資料(檢測分類器和識別轉換矩陣)和兩個程式(檢測和識別程式碼) ,為了提高系統速度,程式設計時,把這四部分儘可能多地放到L2中,如程式3所示
資料的EDMA搬移
由於DM642有限的片內RAM,當L2中無法儲存資料和程式時,經常把資料儲存在片外, EDMA技術把到的資料搬入片內,大大提高了程式的執行速度。
相關推薦
OpenCV人臉識別知識
目前的人臉檢測方法主要有兩大類:基於知識和基於統計。Ø 基於知識的方法:主要利用先驗知識將人臉看作器官特徵的組合,根據眼睛、眉毛、嘴巴、鼻子等器官的特徵以及相互之間的幾何位置關係來檢測人臉。Ø 基於統計的方法:將人臉看作一個整體的模式——二維畫素矩陣,從統計的觀點通過大量人臉
OpenCV人臉識別
com show wait window alt imp bsp src import import cv2 filename = ‘pic.jpg‘ def detect(filename): face_cascade = cv2.Cascade
基於Qt的OpenCV人臉識別(一)
OpenCV對影象處理非常專業,具有很多模組。但是其GUI模組(即highgui),互動性非常差,就連按鈕也得用滑動條來實現。而Qt這個強大的c++圖形庫很好的避免了這個缺點,因此筆者基於Qt平臺,呼叫OpenCV庫,來進行OpenCV的人
基於Qt的OpenCV人臉識別(二)
經過上篇的qt環境配置,現在可以進行開發了。首先進行總體的介面設計,介面的控制元件選擇及介面如下: 單擊開啟攝像頭按鈕右鍵,轉到槽,OpenCV開啟攝像頭操作槽函式程式碼如下: //開啟攝像頭 void Widget::on_btn_open_clicked() { //開
基於python opencv人臉識別的員工考勤系統
WorkAttendanceSystem 一個基於opencv人臉識別的員工考勤系統,作者某雙一流A類大學裡的一流學生,寫於2018/09/,python課設期間。
java實現opencv人臉識別(二)
Java下使用opencv進行人臉檢測 工作需要,研究下人臉識別,發現opencv比較常用,儘管能檢測人臉,但識別率不高,多數是用來獲取攝像頭的視訊流的,提取裡面的視訊幀,實現人臉識別時通常會和其他框架搭配使用,比如face_recognition、SeetaFace En
opencv 人臉識別 二 訓練和識別
上一篇中我們對訓練資料做了一些預處理,檢測出人臉並儲存在\pic\color\x資料夾下(x=1,2,3,...類別號),本文做訓練和識別。為了識別,首先將人臉訓練資料 轉為灰度、對齊、歸一化,再放入分類器(EigenFaceRecognizer),最後用訓練出的model進行
【2018.12.24】python3.7+OpenCV 人臉識別(圖片+攝像頭)
一、識別影象中的人臉個數。註釋寫的很好(\(^o^)/恩) #!/practice/Study_Test python # -*- coding: utf-8 -*- # @Time : 2018/12/23 21:19 # @Author : yb.w # @File : ima
opencv 人臉識別 (一)訓練樣本的處理
本文實現基於eigenface的人臉檢測與識別。給定一個影象資料庫,進行以下步驟:進行人臉檢測,將檢測出的人臉存入資料庫2對資料庫2進行人臉建模在測試集上進行recognition本篇實現第一步:進行人臉檢測,將檢測出的人臉存入資料庫2環境:vs2010+opencv 2.4
基於Qt的OpenCV人臉識別(四)
上篇進行了人臉的檢測,現在進行人臉的識別,採用OpenCV的face320模組裡的EigenFace演算法。在進行檢測之間,得製作被檢測人的人臉資料,這是捕獲按鈕就起到了作用,進行人臉資料的拍攝, //拍攝人臉 void Widget::on_btn_cap_clicked() {
基於Qt的OpenCV人臉識別(三)
上篇完成了Qt呼叫OpenCV的攝像頭,接下來要做的是基於拍攝到的圖片進行人臉檢測。使用OpenCV的級聯檢測器HAAR人臉檢測,首先在Qt的初始化函式中載入人臉模型: //初始化 void Widget::Init() { //載入人臉檢測模型 if(!faceDetect
openCV人臉識別,yuv420sp格式轉BGR傳入Mat矩陣
繼續安卓人臉識別,為了達到更好的效果,程式碼需要不斷優化。 前兩篇分別實現了jpg格式和bitmap格式的圖片資料傳入Mat
opencv人臉識別,jni中Bitmap轉BGR格式
續上篇,繼續人臉識別。 上篇雖然成功把Bitmap轉為了BGRA的格式傳到Mat矩陣中,但是在做人臉識別的過程中,需要的影象
OpenCV人臉識別實驗(一)——特徵臉(Eigenfaces)及其重構的原始碼詳解
1、介紹Introduction 從OpenCV2.4開始,加入了新的類FaceRecognizer,我們可以使用它便捷地進行人臉識別實驗。 本實驗採用的程式設計環境為:opencv3.0+VS2013。人臉識別的實驗已經轉移到face模組中, face模組在我這裡的路徑為
python-opencv-人臉識別實現 從圖片中扣人臉
最近專案需要,從百度,bing 爬取圖片,並對圖片中人臉進行扣取,然後扣取的人臉作為機器學習的樣本資料進行人工標註,圖片爬取了人工篩選比較耗時,於是查詢資料發現opencv庫中人臉識別可以實現該需求,識別率還可以。 #-*-coding:utf8-*- import os
OpenCV——人臉識別模型訓練(2)
在之前的部落格OpenCV——人臉識別資料處理(1)之中,已經下載了ORL人臉資料庫,並且為了識別自己的人臉寫了一個拍照程式自拍。之後對拍的照片進行人臉識別和提取,最後我們得到了一個包含自己的人臉照片的資料夾s41。在部落格的最後我們提到了一個非常重要的檔案——
openCV人臉識別三種演算法實現(官網翻譯)
怎樣使用OpenCV進行人臉識別 友情提示,要看懂程式碼前,你得先知道OpenCV的安裝和配置,會用C++,用過一些OpenCV函式。基本的影象處理和矩陣知識也是需要的。[gm:我是簫鳴的註釋]由於我僅僅是翻譯,對於六級才過的我,肯定有一些翻譯錯的或
【OpenCV人臉識別入門教程之四】LBP人臉識別
本文使用OpenCV實現攝像頭實時LBP人臉識別,這裡不講解LBP人臉識別的原理,小路孩會另外專門寫特徵提取的系列部落格,到時會詳細講解LBP特徵,敬請關注。才疏學淺,有錯誤在所難免,歡迎指正。 系統:Windows7;OpenCV版本:2.4.10. 一、準備工作 1
【OpenCV人臉識別入門教程之二】人臉檢測
本篇文章主要介紹瞭如何使用OpenCV實現人臉檢測。本文不具體講解人臉檢測的原理,直接使用OpenCV實現。 OpenCV版本:2.4.10;VS開發版本:VS2012。 一、OpenCV人臉檢測 要實現人臉識別功能,首先要進行人臉檢測,判斷出圖片中人臉的位置,才能進行
OpenCV人臉識別的原理 完整版程式碼
http://blog.csdn.net/yanming901012/article/details/8606183 本程式首先利用從攝像頭檢測到的人臉圖片,先進行直方圖均衡化 並縮放到92*112的圖片大小,然後根據train.txt的採