
Ubuntu安裝Ganglia並監控Hadoop叢集
關於 Ganglia 軟體,Ganglia是一個跨平臺可擴充套件的,高效能運算系統下的分散式監控系統,如叢集和網格。它是基於分層設計,它使用廣泛的技術,如XML資料代表,便攜資料傳輸,RRDtool用於資料儲存和視覺化。它利用精心設計的資料結構和演算法實現每節點間併發非常低的。它已移植到廣泛的作業系統和處理器架構上,目前在世界各地成千上萬的叢集正在使用。它已 被用來連結大學校園和世界各地,可以處理2000節點的規模。gmond 帶來的系統負載非常少,這使得它成為在叢集中各臺計算機上執行的一段程式碼,而不會影響使用者效能。
本文采用的是ubuntu14.04 LTS-32bit的系統,安裝自帶Ganglia
1.首先,需要確保在 Ubuntu14.04 上安裝了 LAMP 服務。
Ganglia 由兩個所謂主要守護程序 gmond(Ganglia 監測守護程序)和 gmetad(Ganglia 元守護程序),一個基於 PHP 的 Web 前端和其他一些小的實用程式。
1.1Ganglia元件
Ganglia 監控套件包括三個主要部分:gmond,gmetad,和網頁介面,通常被稱為ganglia-web。
Gmond :是一個守護程序,他執行在每一個需要監測的節點上,收集監測統計,傳送和接受在同一個組播或單播通道上的統計資訊 如果他是一個傳送者(mute=no)他會收集基本指標,比如系統負載(load_one),CPU利用率。他同時也會發送使用者通過新增C/Python模組來自定義的指標。 如果他是一個接收者(deaf=no)他會聚合所有從別的主機上發來的指標,並把它們都儲存在記憶體緩衝區中。
Gmetad:也是一個守護程序,他定期檢查gmonds,從那裡拉取資料,並將他們的指標儲存在RRD儲存引擎中。他可以查詢多個叢集並聚合指標。他也被用於生成使用者介面的web前端。
Ganglia-web :顧名思義,他應該安裝在有gmetad執行的機器上,以便讀取RRD檔案。 叢集是主機和度量資料的邏輯分組,比如資料庫伺服器,網頁伺服器,生產,測試,QA等,他們都是完全分開的,你需要為每個叢集執行單獨的gmond例項。
一般來說每個叢集需要一個接收的gmond,每個網站需要一個gmetad。
Ganglia工作流如圖所示:
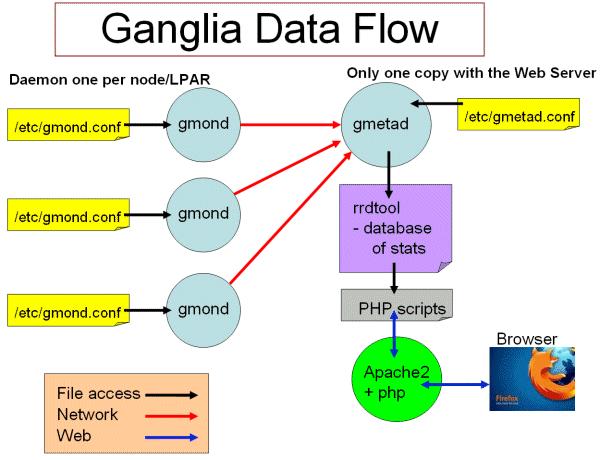
左邊是執行在各個節點上的gmond程序,這個程序的配置只由節點上/etc/gmond.conf的檔案決定。所以,在各個監視節點上都需要安裝和配置該檔案。
右上角是更加負責的中心機(通常是這個叢集中的一臺,也可以不是)。在這個臺機器上執行這著gmetad程序,收集來自各個節點上的資訊並存儲在RRDtool上,該程序的配置只由/etc/gmetad.conf決定。
右下角顯示了關於網頁方面的一些資訊。我們的瀏覽網站時呼叫php指令碼,從RRDTool資料庫中抓取資訊,動態的生成各類圖表。
1.2 Ganglia執行模式(單播與多播)
Ganglia的收集資料工作可以工作在單播(unicast)或多播(multicast)模式下,預設為多播模式。
單播:傳送自己收集到的監控資料到特定的一臺或幾臺機器上,可以跨網段。
多播:傳送自己收集到的監控資料到同一網段內所有的機器上,同時收集同一網段內的所有機器傳送過來的監控資料。因為是以廣播包的形式傳送,因此需要同一網段內。但同一網段內,又可以定義不同的傳送通道。
2.在 Ubuntu14.04 上安裝 Ganglia
本文采用的是apt-get方式進行安裝,也可以去ganglia官網下載最新版本進行搭建安裝
master節點:
sudo apt-get install ganglia-monitor rrdtool gmetad ganglia-webfrontend
在安裝過程中,你應該會看到類似下面的安裝後與apache2伺服器重啟選擇,直接 Yes,然後按Enter鍵。
將ganglia的檔案連結到apache的預設目錄下
sudo ln -s /usr/share/ganglia-webfrontend /var/www/ganglia
當然也可以直接拷貝。
slave節點:
sudo apt-get install ganglia-monitor
在主節點上安裝ganglia-webfrontend和ganglia-monitor。在其他監視節點上,只需要安裝ganglia-monitor即可
3.Ganglia 主節點配置
複製 Ganglia webfrontend Apache 配置,使用下面的命令來正確的位置:
sudo cp /etc/ganglia-webfrontend/apache.conf /etc/apache2/sites-enabled/ganglia.conf(很關鍵的一步)
現在,您需要使用以下命令來編輯 Ganglia 元守護程式的配置檔案:
sudo vi /etc/ganglia/gmetad.conf
更改如下:
data_source "hadoop-cluster" 10.15.43.214(master主機地址)
修改為:
data_source "hadoop-cluster" 3 10.15.43.***:8649 10.15.43.***:8649 10.15.43.***:8649
setuid_username "nobody"
rrd_rootdir "/var/lib/ganglia/rrds"
gridname "hadoop-cluster"
data_source中hadoop-cluster與gmond.conf中name一致
列出機器服務的資料來源,叢集數量,IP:埠或伺服器名稱:埠,一臺master,2臺slave,中間為空格。如果未指定埠號8649(預設gmond埠)。
需要使用下面的命令編輯主節點的配置檔案:
sudo vi /etc/ganglia/gmond.conf
做下面的變化:
/* If a cluster attribute is specified, then all gmond hosts are wrapped inside
* of a tag. If you do not specify a cluster tag, then all will
* NOT be wrapped inside of a tag. */
cluster {
name = "unspecified"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
修改為:
cluster {
name = "hadoop-cluster"/需要和data_source的源名稱一致/
owner = "unspecified"/即為需要使用ganglia的使用者名稱/
latlong = "unspecified"
url = "unspecified"
}
/* Feel free to specify as many udp_send_channels as you like. Gmond
used to only support having a single channel */
udp_send_channel {
mcast_join = 239.2.11.71
port = 8649
ttl = 1
}
修改為:
/* Feel free to specify as many udp_send_channels as you like. Gmond
used to only support having a single channel */
udp_send_channel {
# mcast_join = 239.2.11.71
host = 10.15.43.214/為那臺可以檢視監控資訊的主機地址,安裝gmetad的主機/
port = 8649
ttl = 1
}
/* You can specify as many udp_recv_channels as you like as well. */
udp_recv_channel {
mcast_join = 239.2.11.71
port = 8649
bind = 239.2.11.71
}
修改為:
/* You can specify as many udp_recv_channels as you like as well. */
udp_recv_channel {
# mcast_join = 239.2.11.71
port = 8649
#bind = 239.2.11.71
}
儲存並關閉檔案。
4.Ganglia 叢集slave節點配置將master修改好的/etc/ganglia/gmond.conf 複製到slave個節點,替換原有檔案。 5.hadoop配置
在所有hadoop所在的節點,均需要配置hadoop-metrics2.properties,配置如下:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# syntax: [prefix].[source|sink].[instance].[options]
# See javadoc of package-info.java for org.apache.hadoop.metrics2 for details
#註釋掉以前原有配置
#*.sink.file.class=org.apache.hadoop.metrics2.sink.FileSink
# default sampling period, in seconds
#*.period=10
# The namenode-metrics.out will contain metrics from all context
#namenode.sink.file.filename=namenode-metrics.out
# Specifying a special sampling period for namenode:
#namenode.sink.*.period=8
#datanode.sink.file.filename=datanode-metrics.out
# the following example split metrics of different
# context to different sinks (in this case files)
#jobtracker.sink.file_jvm.context=jvm
#jobtracker.sink.file_jvm.filename=jobtracker-jvm-metrics.out
#jobtracker.sink.file_mapred.context=mapred
#jobtracker.sink.file_mapred.filename=jobtracker-mapred-metrics.out
#tasktracker.sink.file.filename=tasktracker-metrics.out
#maptask.sink.file.filename=maptask-metrics.out
#reducetask.sink.file.filename=reducetask-metrics.out
*.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
*.sink.ganglia.period=10
*.sink.ganglia.slope=jvm.metrics.gcCount=zero,jvm.metrics.memHeapUsedM=both
*.sink.ganglia.dmax=jvm.metrics.threadsBlocked=70,jvm.metrics.memHeapUsedM=40
namenode.sink.ganglia.servers=<span style="font-family: Arial, Helvetica, sans-serif;">10.15.43.214</span>:8649
resourcemanager.sink.ganglia.servers=<span style="font-family: Arial, Helvetica, sans-serif;">10.15.43.214</span>:8649
datanode.sink.ganglia.servers=<span style="font-family: Arial, Helvetica, sans-serif;">10.15.43.214</span>:8649
nodemanager.sink.ganglia.servers=<span style="font-family: Arial, Helvetica, sans-serif;">10.15.43.214</span>:8649
maptask.sink.ganglia.servers=<span style="font-family: Arial, Helvetica, sans-serif;">10.15.43.214</span><span style="font-family: Arial, Helvetica, sans-serif;">:8649 </span>
reducetask.sink.ganglia.servers=<span style="font-family: Arial, Helvetica, sans-serif;">10.15.43.214</span>:86496.Hbase配置
在所有的hbase節點中均配置hadoop-metrics2-hbase.properties,配置如下:
# syntax: [prefix].[source|sink].[instance].[options]
# See javadoc of package-info.java for org.apache.hadoop.metrics2 for details
#*.sink.file*.class=org.apache.hadoop.metrics2.sink.FileSink
# default sampling period
#*.period=10
# Below are some examples of sinks that could be used
# to monitor different hbase daemons.
# hbase.sink.file-all.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file-all.filename=all.metrics
# hbase.sink.file0.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file0.context=hmaster
# hbase.sink.file0.filename=master.metrics
# hbase.sink.file1.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file1.context=thrift-one
# hbase.sink.file1.filename=thrift-one.metrics
# hbase.sink.file2.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file2.context=thrift-two
# hbase.sink.file2.filename=thrift-one.metrics
# hbase.sink.file3.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file3.context=rest
# hbase.sink.file3.filename=rest.metrics
*.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
*.sink.ganglia.period=10
hbase.sink.ganglia.period=10
hbase.sink.ganglia.servers=10.15.43.214:8649start-dfs.sh
start-yarn.sh
start-hbase.sh
8.啟動Ganglia
先需要重啟hadoop和hbase 。在各個節點上啟動gmond服務,主節點還需要啟動gmetad服務,同時重啟apache2。
使用apt-get方式安裝的Ganglia,可以直接用service方式啟動。
sudo service ganglia-monitor start(每臺機器都需要啟動)
sudo service gmetad start(在安裝了ganglia-webfrontend的機器上啟動
sudo /etc/init.d/apache2 restart(在主機上重啟apache2)
或者:
sudo /etc/init.d/ganglia-monitor start
sudo /etc/init.d/gmetad start
sudo /etc/init.d/apache2 restart
9.最終檢驗
登入瀏覽器檢視:http://10.15.43.214/ganglia,如果Hosts up為9即表示安裝成功。
如下圖所示:

若安裝不成功,有幾個很有用的除錯命令:
以除錯模式啟動gmetad:gmetad -d 9
檢視gmetad收集到的XML檔案:telnet master 8649
gmetad收集到的資訊被放到/var/lib/ganglia/rrds/
可以通過以下命令檢查是否有資料在傳輸 tcpdump port 8649
10.參考網站博文(非常受益):
http://www.linuxidc.com/Linux/2014-08/105838.htm
http://www.aboutyun.com/thread-8129-1-1.html
http://www.cr173.com/html/18899_1.html
http://www.linuxidc.com/Linux/2015-03/114631.htm
相關推薦
Ubuntu安裝Ganglia並監控Hadoop叢集
關於 Ganglia 軟體,Ganglia是一個跨平臺可擴充套件的,高效能運算系統下的分散式監控系統,如叢集和網格。它是基於分層設計,它使用廣泛的技術,如XML資料代表,便攜資料傳輸,RRDtool用於資料儲存和視覺化。它利用精心設計的資料結構和演算法實現每節點間併發非常低
以容器部署Ganglia並監控Hadoop叢集
網上有很多Ganglia部署的教程,每一個我都覺得繁瑣,我的目的只是用來監控Hadoop測試叢集,能即刻使用才是王道,於是我想到通過Rancher部署Ganglia應用服務(類似於我在上一篇文章中部署Jmeter容器叢集的方式),以容器的方式一鍵部署,省去了中間繁瑣的安裝過程。 第一步:安裝
Ganglia監控Hadoop叢集的安裝部署
一、 安裝環境 Ubuntu server 12.04 安裝gmetad的機器:192.168.52.105安裝gmond的機器:192.168.52.31,192.168.52.32,192.168.52.33,192.168.52.34,192.168.52.35,
ganglia監控hadoop叢集配置
本篇文章是參考網上別人的部落格,加自己實踐後記錄下來的,免得自己又忘了,感謝網際網路的分享精神,感謝大牛們的分享。 ganglia簡介 Metrics- 監控電腦的執行資料 Node - 一臺電腦,或許擁有多個CPU,中文稱之為節點。 Clu
Ubuntu - 安裝 jdk 並配置環境變量
blog 完成 9.png 配置環境 java png 目錄 jdk tools 先利用的 Xshell 或者 Xftp 把本地下載好的 Linux 版本的 jdk 復制到 Ubuntu 虛擬機下的 /home/zhouk/user/DevTools 目錄下 解壓:tar
Ubuntu安裝vsftpd並通過xftp連接
listen mct bsp ipv 防火墻 allow 用戶名 systemctl 監聽 1.在ubuntu中安裝xftp: sudo apt-get update sudo apt-get install vsftpd sudo service vsftpd
Ubuntu安裝mysql並開通mysql root 使用者遠端訪問許可權
1. sudo apt-get install mysql-server (注意中間提示填寫的賬號密碼) 2. apt-get install mysql-client 3. sudo apt-get install l
阿里雲ECS伺服器Ubuntu安裝MySQL並遠端訪問
root賬戶登入伺服器Ubuntu16.04 apt-get update apt-get install mysql-server mysql-client; 安裝時會讓你設定root密碼,輸入2次。 本地連線mysql測試: mysql -uroot -p****(****是安裝時你設定的roo
Ubuntu安裝Redis並設定為開機自啟動服務
在Ubuntu系統上安裝Redis。本例Ubuntu為Ubuntu Server 14.04版,Redis為3.2.6版。準備工作1:下載Redis準備工作2:下載GCC下載GCC的目的是稍後要編譯redis原始碼用。執行:$sudo apt-get build-dep gcc
安裝redis-live監控redis叢集
監控redis叢集服務的軟體還不少,但是視覺化的不多,瞭解到的就是redis-live和radish。 但是radish國內貌似登陸不了,要翻牆,而且是收費軟體,沒用上。 這裡主要就是描述一下redis-live的安裝和使用。 目前所知的監控軟體基本都是根據redis的命
Linux安裝mitmproxy並監控android資料包
首先列出相關參考資料,本文也是基本上這幾個連結的文章融合總結來的: 廢話不多說,直接上步驟: (一)安裝配置python環境並安裝mitmproxy: ubuntu12.04預設的配置好
Ubuntu安裝nginx並配置應用
安裝gcc g++的依賴庫 1 2 apt-get install build-essential apt-get install libtool centeros平臺可以使用如下命令。 1 2 3 4
Ubuntu安裝lua並基本使用
最近因為要深入應用premake,所以得學點lua.Ubuntu13.04下安裝命令:apt-get install lua5.2 lua5.2-doc版本是5.2.1, 不算最新,不過也很新了。官方參考在這裡:http://www.lua.org/manual/5.2/這是
ubuntu安裝sublime3並配置python3環境
最近有一些煩,虛擬機器跑程式碼,跑著跑著儲存不夠,我就去擴大磁碟,結果虛擬機器崩了,試了一上午的修復辦法,仍然無法修復,於是只能重灌虛擬機器,配置各種環境,這裡總結一下Ubuntu中配置sublime3,並且配置Python3編譯環境。 (一)安裝su
ubuntu 虛擬機器 完全分散式 hadoop叢集搭建 hive搭建 ha搭建
針對分散式hadoop叢集搭建,已經在四臺虛擬機器上,完全搭建好,這裡針對整個搭建過程以及遇到的問題做個總結,按照下面的做法應該能夠比較順暢的搭建一套高可用的分散式hadoop叢集。 這一系列分散式元件的安裝過程中,大體可以分為以下幾步: 第一步.配置機器互信 機器互
使用ganglia 實現監控 hadoop 和 hbase(詳細過程總結)
一,環境準備 hadoop 2.8.2 分散式環境(三個節點 安裝請參考 hadoop分散式環境安裝) hbase 1.2.6 分散式環境(三個節點 ,安裝參考hbase分散式環境安裝 ) 主節點採用 ubuntu 16.04 桌面版 ,從
Ubuntu安裝工具並設定軟連線
我們此處以按照交叉編譯工具鏈為例。有兩種方法,一種方法是下載工具的按裝程式並且在ubuntu中開啟。還有一種是apt-get命令,本文詳細介紹第一種,因為第二種很簡單,一鍵安裝,相信不需要在詳細敘述了 如果你的虛擬機器沒有聯網,可以通過虛擬機器與主機的共享檔案
Ubuntu安裝openjdk並設定環境變數
先安裝openjdk: sudo apt-get install openjdk-7-jre sudo apt-get install openjdk-7-jdk 安裝完成後,用gedit文字編
hadoop安裝,並配置單節點hadoop叢集
前言:本文以申威伺服器raise系統為例,安裝部署hadoop-2.7.3 一、安裝Java 在安裝 hadoop 之前,請確保你的系統上安裝了 Java。使用java -version命令檢查已安裝 Java 的版本。 申威raise系統中預設安裝Java1.7版本,安裝路徑
ubutun16.04下安裝Ganglia監控hadoop與hbase
1.採用的是apt-get方式進行安裝:(測試叢集2臺機器)bigdata-cnki節點(主節點)進行下面命令安裝:(ganglia-monitor +gmetad +ganglia-webfrontend+apache2)sudo apt-get install gangl