
伺服器TIME_WAIT和CLOSE_WAIT詳解和解決辦法
昨天解決了一個HttpClient呼叫錯誤導致的伺服器異常,具體過程如下:
裡頭的分析過程有提到,通過檢視伺服器網路狀態檢測到伺服器有大量的CLOSE_WAIT的狀態。
在伺服器的日常維護過程中,會經常用到下面的命令:
[plain] view plaincopyprint?- netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
它會顯示例如下面的資訊:
TIME_WAIT 814
CLOSE_WAIT 1
FIN_WAIT1 1
ESTABLISHED 634
SYN_RECV 2
LAST_ACK 1
常用的三個狀態是:ESTABLISHED 表示正在通訊,TIME_WAIT 表示主動關閉,CLOSE_WAIT 表示被動關閉。
具體每種狀態什麼意思,其實無需多說,看看下面這種圖就明白了,注意這裡提到的伺服器應該是業務請求接受處理的一方:
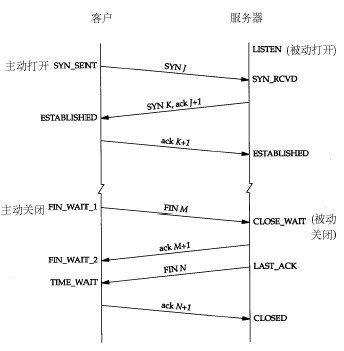
這麼多狀態不用都記住,只要瞭解到我上面提到的最常見的三種狀態的意義就可以了。一般不到萬不得已的情況也不會去檢視網路狀態,如果伺服器出了異常,百分之八九十都是下面兩種情況:
1.伺服器保持了大量TIME_WAIT狀態
2.伺服器保持了大量CLOSE_WAIT狀態
因為linux分配給一個使用者的檔案控制代碼是有限的(可以參考:http://blog.csdn.net/shootyou/article/details/6579139
下 面來討論下這兩種情況的處理方法,網上有很多資料把這兩種情況的處理方法混為一談,以為優化系統核心引數就可以解決問題,其實是不恰當的,優化系統核心參 數解決TIME_WAIT可能很容易,但是應對CLOSE_WAIT的情況還是需要從程式本身出發。現在來分別說說這兩種情況的處理方法:
1.伺服器保持了大量TIME_WAIT狀態
這種情況比較常見,一些爬蟲伺服器或者WEB伺服器(如果網管在安裝的時候沒有做核心引數優化的話)上經常會遇到這個問題,這個問題是怎麼產生的呢?
從 上面的示意圖可以看得出來,TIME_WAIT是主動關閉連線的一方保持的狀態,對於爬蟲伺服器來說他本身就是“客戶端”,在完成一個爬取任務之後,他就 會發起主動關閉連線,從而進入TIME_WAIT的狀態,然後在保持這個狀態2MSL(max segment lifetime)時間之後,徹底關閉回收資源。為什麼要這麼做?明明就已經主動關閉連線了為啥還要保持資源一段時間呢?這個是TCP/IP的設計者規定 的,主要出於以下兩個方面的考慮:
1.防止上一次連線中的包,迷路後重新出現,影響新連線(經過2MSL,上一次連線中所有的重複包都會消失)
2.
可靠的關閉TCP連線。在主動關閉方傳送的最後一個 ack(fin) ,有可能丟失,這時被動方會重新發fin, 如果這時主動方處於 CLOSED
狀態 ,就會響應 rst 而不是 ack。所以主動方要處於 TIME_WAIT 狀態,而不能是 CLOSED 。另外這麼設計TIME_WAIT
會定時的回收資源,並不會佔用很大資源的,除非短時間內接受大量請求或者受到攻擊。
關於MSL引用下面一段話:
[plain] view plaincopyprint?- MSL 為 一個 TCP Segment (某一塊 TCP 網路封包) 從來源送到目的之間可續存的時間 (也就是一個網路封包在網路上傳輸時能存活的時間),由 於 RFC 793 TCP 傳輸協定是在 1981 年定義的,當時的網路速度不像現在的網際網路那樣發達,你可以想像你從瀏覽器輸入網址等到第一 個 byte 出現要等 4 分鐘嗎?在現在的網路環境下幾乎不可能有這種事情發生,因此我們大可將 TIME_WAIT 狀態的續存時間大幅調低,好 讓 連線埠 (Ports) 能更快空出來給其他連線使用。
再引用網路資源的一段話:
[plain] view plaincopyprint?- 值 得一說的是,對於基於TCP的HTTP協議,關閉TCP連線的是Server端,這樣,Server端會進入TIME_WAIT狀態,可 想而知,對於訪 問量大的Web Server,會存在大量的TIME_WAIT狀態,假如server一秒鐘接收1000個請求,那麼就會積壓 240*1000=240,000個 TIME_WAIT的記錄,維護這些狀態給Server帶來負擔。當然現代作業系統都會用快速的查詢演算法來管理這些 TIME_WAIT,所以對於新的 TCP連線請求,判斷是否hit中一個TIME_WAIT不會太費時間,但是有這麼多狀態要維護總是不好。
- HTTP協議1.1版規定default行為是Keep-Alive,也就是會重用TCP連線傳輸多個 request/response,一個主要原因就是發現了這個問題。
也就是說HTTP的互動跟上面畫的那個圖是不一樣的,關閉連線的不是客戶端,而是伺服器,所以web伺服器也是會出現大量的TIME_WAIT的情況的。 現在來說如何來解決這個問題。 解決思路很簡單,就是讓伺服器能夠快速回收和重用那些TIME_WAIT的資源。 下面來看一下我們網管對/etc/sysctl.conf檔案的修改: [plain] view plaincopyprint?
- #對於一個新建連線,核心要傳送多少個 SYN 連線請求才決定放棄,不應該大於255,預設值是5,對應於180秒左右時間
- net.ipv4.tcp_syn_retries=2
- #net.ipv4.tcp_synack_retries=2
- #表示當keepalive起用的時候,TCP傳送keepalive訊息的頻度。預設是2小時,改為300秒
- net.ipv4.tcp_keepalive_time=1200
- net.ipv4.tcp_orphan_retries=3
- #表示如果套接字由本端要求關閉,這個引數決定了它保持在FIN-WAIT-2狀態的時間
- net.ipv4.tcp_fin_timeout=30
- #表示SYN佇列的長度,預設為1024,加大佇列長度為8192,可以容納更多等待連線的網路連線數。
- net.ipv4.tcp_max_syn_backlog = 4096
- #表示開啟SYN Cookies。當出現SYN等待佇列溢位時,啟用cookies來處理,可防範少量SYN攻擊,預設為0,表示關閉
- net.ipv4.tcp_syncookies = 1
- #表示開啟重用。允許將TIME-WAIT sockets重新用於新的TCP連線,預設為0,表示關閉
- net.ipv4.tcp_tw_reuse = 1
- #表示開啟TCP連線中TIME-WAIT sockets的快速回收,預設為0,表示關閉
- net.ipv4.tcp_tw_recycle = 1
- ##減少超時前的探測次數
- net.ipv4.tcp_keepalive_probes=5
- ##優化網路裝置接收佇列
- net.core.netdev_max_backlog=3000
net.ipv4.tcp_fin_timeout
net.ipv4.tcp_keepalive_*
這幾個引數。 net.ipv4.tcp_tw_reuse和net.ipv4.tcp_tw_recycle的開啟都是為了回收處於TIME_WAIT狀態的資源。
net.ipv4.tcp_fin_timeout這個時間可以減少在異常情況下伺服器從FIN-WAIT-2轉到TIME_WAIT的時間。
net.ipv4.tcp_keepalive_*一系列引數,是用來設定伺服器檢測連線存活的相關配置。
2.伺服器保持了大量CLOSE_WAIT狀態 休息一下,喘口氣,一開始只是打算說說TIME_WAIT和CLOSE_WAIT的區別,沒想到越挖越深,這也是寫部落格總結的好處,總可以有意外的收穫。 TIME_WAIT狀態可以通過優化伺服器引數得到解決,因為發生TIME_WAIT的情況是伺服器自己可控的,要麼就是對方連線的異常,要麼就是自己沒有迅速回收資源,總之不是由於自己程式錯誤導致的。 但 是CLOSE_WAIT就不一樣了,從上面的圖可以看出來,如果一直保持在CLOSE_WAIT狀態,那麼只有一種情況,就是在對方關閉連線之後伺服器程 序自己沒有進一步發出ack訊號。換句話說,就是在對方連線關閉之後,程式裡沒有檢測到,或者程式壓根就忘記了這個時候需要關閉連線,於是這個資源就一直 被程式佔著。個人覺得這種情況,通過伺服器核心引數也沒辦法解決,伺服器對於程式搶佔的資源沒有主動回收的權利,除非終止程式執行。 在那邊日誌裡頭我舉了個場景,來說明CLOSE_WAIT和TIME_WAIT的區別,這裡重新描述一下: 服 務器A是一臺爬蟲伺服器,它使用簡單的HttpClient去請求資源伺服器B上面的apache獲取檔案資源,正常情況下,如果請求成功,那麼在抓取完 資源後,伺服器A會主動發出關閉連線的請求,這個時候就是主動關閉連線,伺服器A的連線狀態我們可以看到是TIME_WAIT。如果一旦發生異常呢?假設 請求的資源伺服器B上並不存在,那麼這個時候就會由伺服器B發出關閉連線的請求,伺服器A就是被動的關閉了連線,如果伺服器A被動關閉連線之後程式設計師忘了 讓HttpClient釋放連線,那就會造成CLOSE_WAIT的狀態了。
所以如果將大量CLOSE_WAIT的解決辦法總結為一句話那就是:查程式碼。因為問題出在伺服器程式裡頭啊。 參考資料:
相關推薦
伺服器TIME_WAIT和CLOSE_WAIT詳解和解決辦法 伺服器TIME_WAIT和CLOSE_WAIT詳解和解決辦法
伺服器TIME_WAIT和CLOSE_WAIT詳解和解決辦法 來自:http://blog.csdn.net/shootyou/article/details/6622226 昨天解決了一個HttpClient呼叫錯誤導致的
伺服器TIME_WAIT和CLOSE_WAIT詳解和解決辦法
昨天解決了一個HttpClient呼叫錯誤導致的伺服器異常,具體過程如下: 裡頭的分析過程有提到,通過檢視伺服器網路狀態檢測到伺服器有大量的CLOSE_WAIT的狀態。 在伺服器的日常維護過程中,會經常用到下面的命令: [plain] view plaincopyprint?
服務器TIME_WAIT和CLOSE_WAIT詳解和解決辦法
src 並不會 blog 目的 core 沒有 解決辦法 ++ 重用 來自:http://blog.csdn.net/shootyou/article/details/6622226 昨天解決了一個HttpClient調用錯誤導致的服務器異常,具體過程如下:
HTTP報錯401和403詳解及解決辦法
一、401: 1. HTTP 401 錯誤 - 未授權: (Unauthorized) 您的Web伺服器認為,客戶端傳送的 HTTP 資料流是正確的,但進入網址 (URL) 資源 , 需要使用者身份驗證 , 而相關資訊 1 )尚未被提供, 或 2 )已提供但沒有通過授
大量TIME_WAIT的終極詳解和解決方案
上篇筆記主要介紹了與TIME_WAIT相關的基礎知識,本文則從實踐出發,說明如何解決文章標題提出的問題。 1. 檢視系統網路配置和當前TCP狀態在定位並處理應用程式出現的網路問題時,瞭解系統預設網路配置是非常必要的。以x86_64平臺Linux kernelversion
java的UDP和TCP詳解和北京-賽車平臺出租源碼分析
ati 消息 byte ide 一段 pack catch 打包 println 1、需求分析北京-賽車平臺出租Q1446595067 最近在和硬件做網口的傳輸協議,一開始告訴我說用TCP的socket進行傳輸,我說沒問題,就寫了個socket的發送和接收方法。but過了沒
Spark核心程式設計建立RDD及transformation和action詳解和案例
建立RDD 進行Spark核心程式設計時,首先要做的第一件事,就是建立一個初始的RDD。該RDD中,通常就代表和包含了Spark應用程式的輸入源資料。然後在建立了初始的RDD之後,才可以通過Spark Core提供的transformation運算元,對該RD
java中加密演算法Base64和RSA詳解和Android
手機的安全重要資訊容易被洩露的方式: 1.會從我們本地洩露 手機中毒等 2.會從伺服器洩露 伺服器人員將資訊賣出去等 3.半路上,網路傳輸的過程中 加密傳輸資料 手機連線WiFi,如果在WiFi上設定監聽資料,將關鍵的資訊攔截下來,就有可能盜取個人重要資訊
time_wait 詳解和解決方案
1. 產生原因 2. 導致問題 3. Nginx 3.1 長連線 4. 解決方案 5 .參考 產生原因 TCP 連線關閉時,會有 4 次通訊(四次揮手),來確認雙方都停止收發資料了。如上圖,主動關閉方,最後傳送 ACK 時,會進入 TIME_WAIT 狀態,要等 2MSL 時間後,這條連線才真正
Java程式設計師從笨鳥到菜鳥之(二十四)Xml基礎詳解和DTD驗證 Java程式設計師從笨鳥到菜鳥之(二十三)常見亂碼解決以及javaBean基礎知識
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
(轉)Linux的iptables做代理伺服器和防火牆詳解
https://blog.csdn.net/harryxlb/article/details/7339307 用Linux的iptables做代理伺服器和防火牆配置詳細介紹 代理/防火牆 1.iptables規則表 &n
iOS "Warning" No such file or directory詳解、解決方案和原理
最近用XCode做了一個靜態庫,在自己電腦上別的App project中編譯使用沒有任何問題,但是傳給別的同事使用在編譯的時候就會出現類似於下面警告。 warning: (i386) /UsersLibrary/Developer/Xcode/DerivedData/ProjectName-ebyadedaa
Xcode other link flag引數詳解和解決靜態庫衝突分析
1.Xcode設定Other Link Flag 先猜一下這個引數,Other Link Flag 其他連結標誌,從字面上的意思來看,肯定程式碼連結的時候有關和連結器有關。 一個程式從簡單易讀的程式碼到可執行檔案往往要經歷以下步驟: 原始碼 > 前處理器 &
快取DNS伺服器和主DNS伺服器的快速搭建詳解
一、設定配置內容 假設我們已經在網上註冊了wangej.com域名,得到的IP網路是172.16.12.0/24 ns伺服器是:172.16.12.1 www伺服器:172.16.12.1,另外一個地址:172.16.12.3 mail伺服器:172.16.12.2 ftp主機在www伺服器上,即ftp為ww
can’t find /mnt in /etc/fstab問題的解決和fstab詳解
can't find /mnt in /etc/fstab當我在執行mount -t 192.168.1.50:/tftpboot/arm /mnt -o nolock命令時。然後我換一個掛載點,錯誤也隨之成為掛載點cant find。先說解決問題的方法吧。在/etc/fst
java中呼叫本地動態連結庫(*.DLL)的兩種方式詳解和not found library、打包成jar,war包dll無法載入等等問題解決辦法
我們經常會遇到需要java呼叫c++的案例,這裡就java呼叫DLL本地動態連結庫兩種方式,和載入過程中遇到的問題進行詳細介紹 1、通過System.loadLibrary("dll名稱,不需要字尾名
R數據可視化----ggplot2之標度、坐標軸和圖例詳解
abs 調整 所有 不同的 size n) 默認 表達 idt 標度控制著數據到圖形屬性的映射,當有需要時,ggplot2會自動添加一個默認的標度。我們確實可以在不了解標度運行原理的情況下畫出許多圖形,但理解標度並學會如何操縱它們則將賦予我們對圖形更強的控制能力。 每一種圖
SVN trunk(主線) branch(分支) tag(標記) 用法詳解和詳細操作步驟
trac load mar span 必須 最可 objc copy 右鍵 原文地址:http://blog.csdn.net/vbirdbest/article/details/51122637 使用場景: 假如你的項目(這裏指的是手機客戶端項目)的某個版本(例如1.0
xargs 和 exec詳解
linux xargs exec cpxargs 和 exec詳解 exec主要和find一起配合使用,xargs比exec用的地方要多。xargs應用把管道符前面的輸出作為xargs後面的命令的輸入。好處在於可以簡化步驟。常常和find一起使用,#find . -mtime +10 |xargs rm
Storm容錯機制Acker詳解和實戰案例
storm acker 失敗重發 可靠性Storm中有個特殊的Executor叫acker,他們負責跟蹤spout發出的每一個Tuple的Tuple樹。當acker發現一個Tuple樹已經處理完成了,它會告訴框架回調Spout的ack(),否則回調Spout的fail()。Acker的跟蹤算法是Storm的主