
編寫MapReduce程式示例——求平均成績
輸入檔案:
由於不識別中文,所以暫時使用姓名拼音
jiangxin 94
wangziwen 78
yangzi 83
wangkai 89
jiangxin 80
wangziwen 84
liutao 90
liutao 82
jiangxin 76
wangkai 77
wangkai 91
yangzi 86
jiangxin 88
每一行為一個學生姓名及一科成績,如果有多門學科,則該學生存在多行資料。

編寫程式碼:
package zmy.examples;
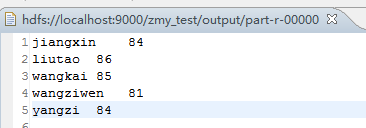
import java.io.IOException 執行結果:
相關推薦
編寫MapReduce程式示例——求平均成績
輸入檔案: 由於不識別中文,所以暫時使用姓名拼音 jiangxin 94 wangziwen 78 yangzi 83 wangkai 89 jiangxin 80 wangziwen 84 liutao 90 liutao 8
杭電2023 求平均成績(及一些易見的錯誤)
競賽 斷點 sco ani 今天 new 沒有 math 的人 鏈接:http://acm.split.hdu.edu.cn/showproblem.php?pid=2023 首先,想說下,這題對我來說可能是一個陰影。因為在自己學校的程序競賽中,這是第二題,當時自己
求平均成績使用二維數組(網上找的,僅自用,非原創)
student sys read his += class a oid new stat using System;class AverageofScore{ public static void Main() { int[,] student_score=new int
2023.求平均成績
printf ++ amp mil pan u+ strong scanf nbsp #include<stdio.h> #include<string.h> double student[55],subject[9],sore[55][9]; in
Hadoop學習3-Macbook環境在IDEA中編寫MapReduce程式
Hadoop學習3-Macbook環境在IDEA中編寫MapReduce程式 新建一個Maven專案 不用說了,普通的Maven專案就行。 加入Hadoop依賴 其中的${hadoop.version}對應自己使用的Hadoop版本 hadoop-client
python-輸入輸出練習題求平均成績
求平均成績(python3直譯器) 輸入學生姓名; 依次輸入學生的三門科目成績; 計算該學生的平均成績, 並列印; 平均成績保留一位小數點; 計算該學生語文成績佔總成績的百分之多少?並列印。eg: 78%; name = input('學生姓名:') chinese = float(
編寫MapReduce程式(簡單的電話被呼叫分析程式)
由於Hadoop 2.2.0目前還沒有好用的Eclipse外掛,目前使用Eclipse上編寫程式碼,而後放到Hadoop環境執行的形式。 準備工作: 1、搭建Hadoop環境,建立專案,專案的BuildPath中新增所有Hadoop中的jar包; 2、構造資料集:每一行資料兩個號碼組成,
編寫一個程式,求出滿足下列條件的四位數:該數是個完全平方數,且第一、三位數字之和為10,第二、四位數字之積為12
編寫一個程式,求出滿足下列條件的四位數:該數是個完全平方數,且第一、三位數字之和為10,第二、四位數字之積為12 程式碼: #include <stdio.h> #include <math.h> //編寫一個程式,求出滿足下列條件的四位數: //該數是個
hdu 求平均成績
Problem Description 假設一個班有n(n<=50)個學生,每人考m(m<=5)門課,求每個學生的平均成績和每門課的平均成績,並輸出各科成績均大於等於平均成績的學生數量。 Input 輸入資料有多個測試例項,每個測試例項的第一行包括兩
一個MapReduce 程式示例 細節決定成敗(一)
最近在看MapReduce,想起一直都是Copy 然後修改的方法來寫。突然想試試自己動手寫一個級其簡單的mr程式。 細節決定成敗啊,不試不知道,一試才能發現平時注意不到的細節。 下面是我用了很快時間寫好的一個程式,注意,這份是有問題的! package wordcount;
一個MapReduce 程式示例 細節決定成敗(二) :觀察日誌及 Counter
下面是一個計算輸入檔案中a~z每個單字元的數量的一個map reduce 程式。 package wordcount; import java.io.IOException; import org.apache.commons.lang.StringUtils; imp
hdu 2023 求平均成績(c語言)
hdu 2023 求平均成績 點選做題網站連結 題目描述 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Problem Description 假設一個班有
已確定學生人數,輸入成績求平均成績(JAVA)
1、已確定學生人數,輸入學生成績,求平均成績程式碼為:import java.util.Scanner; public class clock { private static Scanner sc; public static void main(String[]
Python練習題5(求水仙花數):編寫一個程式,求 100~999 之間的所有水仙花數 (如果一個 3 位數等於其各位數字的立方和,則稱這個數為水仙花數)
方法一:使用int和str,將int轉成字串拼接後再轉成int。 1 for i in range(1,10): 2 for j in range(0,10): 3 for k in range(0,10): 4 num = int(str(i) + s
一個MapReduce 程式示例 細節決定成敗(四) :In-Map Aggregation
為什麼使用in-map aggregation, 與combine 有什麼區別,什麼時候使用combiner ,什麼時候使用in-map 聚合? 先介紹用一張圖看看一下combiner 在一個mr job中的位置。 下面上乾貨: 資料檔案 由 InputFormat
HDU2023 求平均成績【入門】
求平均成績 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Submission(s): 135296 Accepted Submis
JavaScript編寫一個程式,求出200到300之間滿足如下條件的數:三個數字之積為42,三個數字之和為12
function num(){ for(i=200;i<301;i++){ var a=parseInt(i/100);//百位取整 var b=parseIn
求平均成績
對於每個測試例項,輸出3行資料,第一行包含n個數據,表示n個學生的平均成績,結果保留兩位小數;第二行包含m個數據,表示m門課的平均成績,結果保留兩位小數;第三行是一個整數,表示該班級中各科成績均大於等於平均成績的學生數量。 每個測試例項後面跟一個空行。 (adsbygoo
Linux_C練習:編寫一個程式,求出滿足下列條件的四位數:該數是個完全平方數,且第一、三位數字之和為10,第二、四位數字之積為12;
#include<stdio.h> #include<math.h> int main() { int num; int s1; int s2; for(num = 30; num < 100; ++num) { int r
hdu2023 求平均成績 (C語言)
Problem Description 假設一個班有n(n<=50)個學生,每人考m(m<=5)門課,求每個學生的平均成績和每門課的平均成績,並輸出各科成績均大於等於平均成績的學生數量。 Input 輸入資料有多個測試例項,每個測試例項的第一行包括兩個