
Spark Streaming基於kafka的Direct詳解
本博文主要包括一下內容:
1,SparkStreaming on Kafka Direct工作原理機制
2,SparkStreaming on Kafka Direct 案例實戰
3,SparkStreaming on Kafka Direct原始碼解析
一:SparkStreaming on Kafka Direct工作原理機制:
1、Direct方式特點:
(1)Direct的方式是會直接操作kafka底層的元資料資訊,這樣如果計算失敗了,可以把資料重新讀一下,重新處理。即資料一定會被處理。拉資料,是RDD在執行的時候直接去拉資料。
(2)由於直接操作的是kafka,kafka就相當於你底層的檔案系統。這個時候能保證嚴格的事務一致性,即一定會被處理,而且只會被處理一次。而Receiver的方式則不能保證,因為Receiver和ZK中的資料可能不同步,spark Streaming可能會重複消費資料,這個調優可以解決,但顯然沒有Direct方便。而Direct api直接是操作kafka的,spark streaming自己負責追蹤消費這個資料的偏移量或者offset,並且自己儲存到checkpoint,所以它的資料一定是同步的,一定不會被重複。即使重啟也不會重複,因為checkpoint了,但是程序升級的時候,不能讀取原先的checkpoint,面對升級checkpoint無效這個問題,怎麼解決呢?升級的時候讀取我指定的備份就可以了,即手動的指定checkpoint也是可以的,這就再次完美的確保了事務性,有且僅有一次的事務機制。那麼怎麼手動checkpoint呢?構建SparkStreaming的時候,有getorCreate這個api,它就會獲取checkpoint的內容,具體指定下這個checkpoint在哪就好了。或者如下:
private static JavaStreamingContext createContext(
String checkpointDirectory, SparkConf conf) {
// TODO Auto-generated method stub
System.out.println("Creating new context");
SparkConf sparkConf = conf;
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf,Durations.seconds(5 而如果從checkpoint恢復後,如果資料累積太多處理不過來,怎麼辦?1)限速2)增強機器的處理能力3)放到資料緩衝池中。
(3)由於底層是直接讀資料,沒有所謂的Receiver,直接是週期性(Batch Intervel)的查詢kafka,處理資料的時候,我們會使用基於kafka原生的Consumer api來獲取kafka中特定範圍(offset範圍)中的資料。這個時候,Direct Api訪問kafka帶來的一個顯而易見的效能上的好處就是,如果你要讀取多個partition,Spark也會建立RDD的partition,這個時候RDD的partition和kafka的partition是一致的。而Receiver的方式,這2個partition是沒任何關係的。這個優勢是你的RDD,其實本質上講在底層讀取kafka的時候,kafka的partition就相當於原先hdfs上的一個block。這就符合了資料本地性。RDD和kafka資料都在這邊。所以讀資料的地方,處理資料的地方和驅動資料處理的程式都在同樣的機器上,這樣就可以極大的提高效能。不足之處是由於RDD和kafka的patition是一對一的,想提高並行度就會比較麻煩。提高並行度還是repartition,即重新分割槽,因為產生shuffle,很耗時。這個問題,以後也許新版本可以自由配置比例,不是一對一。因為提高並行度,可以更好的利用叢集的計算資源,這是很有意義的。
(4)不需要開啟wal機制,從資料零丟失的角度來看,極大的提升了效率,還至少能節省一倍的磁碟空間。從kafka獲取資料,比從hdfs獲取資料,因為zero copy的方式,速度肯定更快。
2、SparkStreaming on Kafka Direct與Receiver 的對比:
從高層次的角度看,之前的和Kafka整合方案(reciever方法)使用WAL工作方式如下:
1)執行在Spark workers/executors上的Kafka Receivers連續不斷地從Kafka中讀取資料,其中用到了Kafka中高層次的消費者API。
2)接收到的資料被儲存在Spark workers/executors中的記憶體,同時也被寫入到WAL中。只有接收到的資料被持久化到log中,Kafka Receivers才會去更新Zookeeper中Kafka的偏移量。
3)接收到的資料和WAL儲存位置資訊被可靠地儲存,如果期間出現故障,這些資訊被用來從錯誤中恢復,並繼續處理資料。
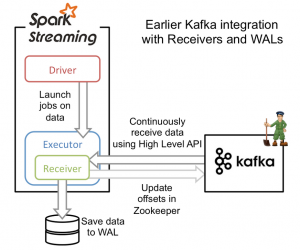
這個方法可以保證從Kafka接收的資料不被丟失。但是在失敗的情況下,有些資料很有可能會被處理不止一次!這種情況在一些接收到的資料被可靠地儲存到WAL中,但是還沒有來得及更新Zookeeper中Kafka偏移量,系統出現故障的情況下發生。這導致資料出現不一致性:Spark Streaming知道資料被接收,但是Kafka那邊認為資料還沒有被接收,這樣在系統恢復正常時,Kafka會再一次傳送這些資料。
這種不一致產生的原因是因為兩個系統無法對那些已經接收到的資料資訊儲存進行原子操作。為了解決這個問題,只需要一個系統來維護那些已經發送或接收的一致性檢視,而且,這個系統需要擁有從失敗中恢復的一切控制權利。基於這些考慮,社群決定將所有的消費偏移量資訊只儲存在Spark Streaming中,並且使用Kafka的低層次消費者API來從任意位置恢復資料。
為了構建這個系統,新引入的Direct API採用完全不同於Receivers和WALs的處理方式。它不是啟動一個Receivers來連續不斷地從Kafka中接收資料並寫入到WAL中,而且簡單地給出每個batch區間需要讀取的偏移量位置,最後,每個batch的Job被執行,那些對應偏移量的資料在Kafka中已經準備好了。這些偏移量資訊也被可靠地儲存(checkpoint),在從失敗中恢復可以直接讀取這些偏移量資訊。

需要注意的是,Spark Streaming可以在失敗以後重新從Kafka中讀取並處理那些資料段。然而,由於僅處理一次的語義,最後重新處理的結果和沒有失敗處理的結果是一致的。
因此,Direct API消除了需要使用WAL和Receivers的情況,而且確保每個Kafka記錄僅被接收一次並被高效地接收。這就使得我們可以將Spark Streaming和Kafka很好地整合在一起。總體來說,這些特性使得流處理管道擁有高容錯性,高效性,而且很容易地被使用。
二、SparkStreaming on Kafka Direct 案例實戰:
1、原始碼資訊如下:
package com.dt.spark.SparkApps.sparkstreaming;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaPairInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils;
import kafka.serializer.StringDecoder;
import scala.Tuple2;
public class SparkStreamingOnKafkaDirect {
public static void main(String[] args) {
/* 第一步:配置SparkConf:
1,至少兩條執行緒因為Spark Streaming應用程式在執行的時候至少有一條執行緒用於
不斷地迴圈接受程式,並且至少有一條執行緒用於處理接受的資料(否則的話有執行緒用於處理資料,隨著時間的推移記憶體和磁碟都會
不堪重負)
2,對於叢集而言,每個Executor一般肯定不止一個執行緒,那對於處理SparkStreaming
應用程式而言,每個Executor一般分配多少Core比較合適?根據我們過去的經驗,5個左右的Core是最佳的
(一個段子分配為奇數個Core表現最佳,例如3個,5個,7個Core等)
*/
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparStreamingOnKafkaReceiver");
/* SparkConf conf = new SparkConf().setMaster("spark://Master:7077").setAppName("SparStreamingOnKafkaReceiver");
第二步:建立SparkStreamingContext,
1,這個是SparkStreaming應用春香所有功能的起始點和程式排程的核心
SparkStreamingContext的構建可以基於SparkConf引數也可以基於持久化的SparkStreamingContext的內容
來恢復過來(典型的場景是Driver崩潰後重新啟動,由於SparkStreaming具有連續7*24
小時不間斷執行的特徵,所以需要Driver重新啟動後繼續上一次的狀態,此時的狀態恢復需要基於曾經的Checkpoint))
2,在一個Sparkstreaming 應用程式中可以建立若干個SparkStreaming物件,使用下一個SparkStreaming
之前需要把前面正在執行的SparkStreamingContext物件關閉掉,由此,我們獲取一個重大的啟發
我們獲得一個重大的啟發SparkStreaming也只是SparkCore上的一個應用程式而已,只不過SparkStreaming框架想執行的話需要
spark工程師寫業務邏輯
*/
@SuppressWarnings("resource")
JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(10));
/* 第三步:建立SparkStreaming輸入資料來源input Stream
1,資料輸入來源可以基於File,HDFS,Flume,Kafka-socket等
2,在這裡我們指定資料來源於網路Socket埠,SparkStreaming連線上該埠並在執行時候一直監聽
該埠的資料(當然該埠服務首先必須存在,並且在後續會根據業務需要不斷地資料產生當然對於SparkStreaming
應用程式的而言,有無資料其處理流程都是一樣的);
3,如果經常在每個5秒鐘沒有資料的話不斷地啟動空的Job其實會造成排程資源的浪費,因為並沒有資料發生計算
所以實際的企業級生成環境的程式碼在具體提交Job前會判斷是否有資料,如果沒有的話就不再提交資料
在本案例中具體引數含義:
第一個引數是StreamingContext例項,
第二個引數是zookeeper叢集資訊(接受Kafka資料的時候會從zookeeper中獲取Offset等元資料資訊)
第三個引數是Consumer Group
第四個引數是消費的Topic以及併發讀取Topic中Partition的執行緒數
*/
Map<String,String> kafkaParameters = new HashMap<String,String>();
kafkaParameters.put("meteadata.broker.list",
"Master:9092;Worker1:9092,Worker2:9092");
Set<String> topics =new HashSet<String>();
topics.add("SparkStreamingDirected");
JavaPairInputDStream<String,String> lines = KafkaUtils.createDirectStream(jsc,
String.class, String.class,
StringDecoder.class, StringDecoder.class,
kafkaParameters,
topics);
/*
* 第四步:接下來就像對於RDD程式設計一樣,基於DStream進行程式設計!!!原因是Dstream是RDD產生的模板(或者說類
* ),在SparkStreaming發生計算前,其實質是把每個Batch的Dstream的操作翻譯成RDD的操作
* 對初始的DTStream進行Transformation級別處理
* */
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<Tuple2<String, String>,String>(){ //如果是Scala,由於SAM裝換,可以寫成val words = lines.flatMap{line => line.split(" ")}
@Override
public Iterable<String> call(Tuple2<String,String> tuple) throws Exception {
return Arrays.asList(tuple._2.split(" "));//將其變成Iterable的子類
}
});
// 第四步:對初始DStream進行Transformation級別操作
//在單詞拆分的基礎上對每個單詞進行例項計數為1,也就是word => (word ,1 )
JavaPairDStream<String,Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word,1);
}
});
//對每個單詞事例技術為1的基礎上對每個單詞在檔案中出現的總次數
JavaPairDStream<String,Integer> wordsCount = pairs.reduceByKey(new Function2<Integer,Integer,Integer>(){
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
// TODO Auto-generated method stub
return v1 + v2;
}
});
/*
* 此處的print並不會直接出發Job的支援,因為現在一切都是在SparkStreaming的框架控制之下的
* 對於spark而言具體是否觸發真正的JOb執行是基於設定的Duration時間間隔的
* 諸位一定要注意的是Spark Streaming應用程式要想執行具體的Job,對DStream就必須有output Stream操作
* output Stream有很多型別的函式觸發,類print,savaAsTextFile,scaAsHadoopFiles等
* 其實最為重要的一個方法是foreachRDD,因為SparkStreaming處理的結果一般都會放在Redis,DB
* DashBoard等上面,foreach主要就是用來完成這些功能的,而且可以自定義具體的資料放在哪裡!!!
* */
wordsCount.print();
// SparkStreaming 執行引擎也就是Driver開始執行,Driver啟動的時候位於一條新執行緒中的,當然
// 其內部有訊息接受應用程式本身或者Executor中的訊息
jsc.start();
jsc.close();
}
}
接下來的步驟為:
(1)首先在安裝了zookeeper機器上的bin目錄下啟動zookeeper服務:
(2)接下來在各個機器上啟動Kafka服務,在Kafkabin目錄下:
1) nohup ./kafka-server-start.sh ../config/server.properties &
2) ./kafka-topic.sh –create –zookeeper Master:2181,Worker1:2181,Worker2:2181 –replication-factor 3 –pertitions 1 –topic SaprkStreamingDirected
3)./kafka -console -producer.sh –broker-list Master:9092,Worker1:9092,Worker2:9092 –topic SparkStreamingDirected
(3)在控制檯上輸入資料
(4)此時你就可以在eclipse控制檯上觀察到值
三、SparkStreaming on Kafka Direct原始碼解析
1、首先我們在KafkaUtils中看到createDirectStream的原始碼註釋寫的非常的纖細,主要包括你可以訪問offset,怎樣訪問offset,通過foreach暴露我們需要的RDD等等
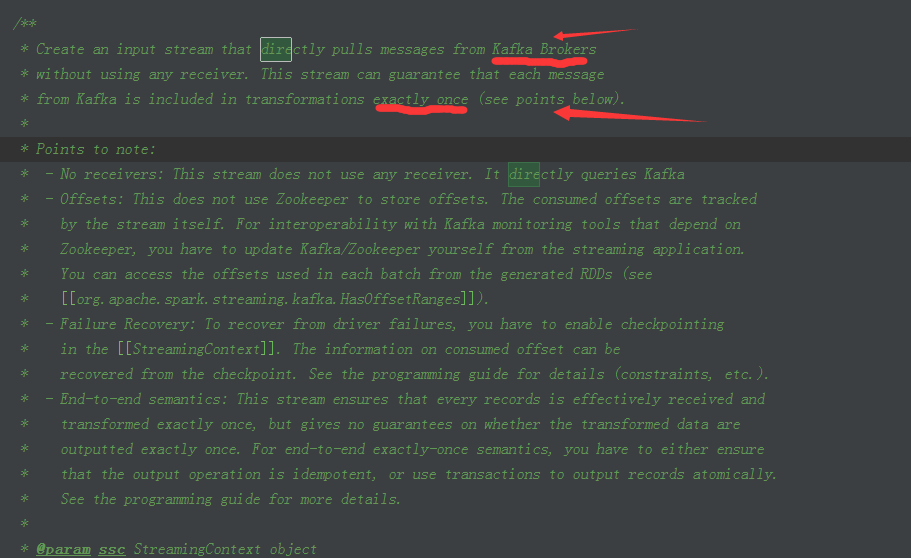
2、在這裡我們可以看到各個引數資訊說明的非常詳細:

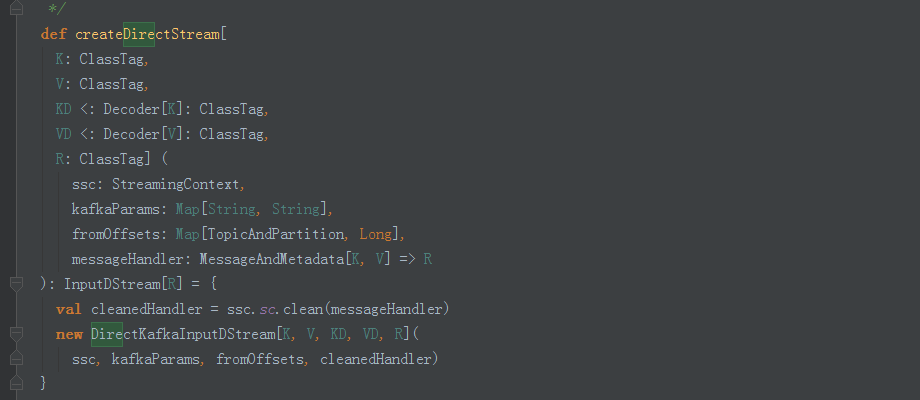
3、我們看到建立了DirectKafkaInputStream
4、在DirectKafakaInputStream中我們可以看到它建立了DirectKafkaInputDStreamcheckpointData:
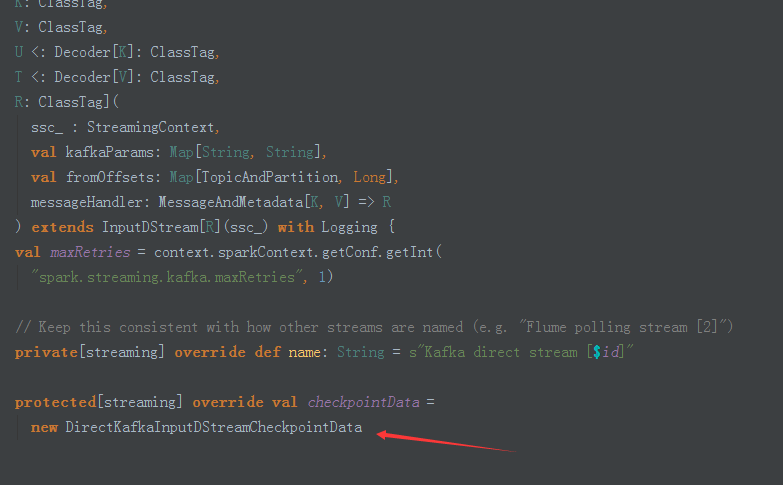
5、通過DirectKafkaInputDStreamcheckpointData,這裡我們可以看到,我們可以自定義checkpoint:

更多原始碼希望大家自己去看。
補充說明:
使用Spark Streaming可以處理各種資料來源型別,如:資料庫、HDFS,伺服器log日誌、網路流,其強大超越了你想象不到的場景,只是很多時候大家不會用,其真正原因是對Spark、spark streaming本身不瞭解。
相關推薦
Spark Streaming基於案例詳解
本篇博文將從如下幾點組織文章: 一:案例演示 二:原始碼分析 一:案例演示 這裡只是貼出原始碼,後續會對改程式碼的實戰和實驗演示都會詳細的補充。 package com.dt.spark.sparkstreaming import org.apac
Spark Streaming基於kafka的Direct詳解
本博文主要包括一下內容: 1,SparkStreaming on Kafka Direct工作原理機制 2,SparkStreaming on Kafka Direct 案例實戰 3,SparkStreaming on Kafka Direct原始碼解析
Apache Spark 內存管理詳解
append 緩存 hashmap slave 完整 developer transform borde 區別 Apache Spark 內存管理詳解 Spark 作為一個基於內存的分布式計算引擎,其內存管理模塊在整個系統中扮演著非常重要的角色。理解 Spark 內存
MapReduce和spark的shuffle過程詳解
存在 位置 方式 傳遞 第一個 2個 過濾 之前 第三方 面試常見問題,必備答案。 參考:https://blog.csdn.net/u010697988/article/details/70173104 mapReducehe和Spark之間的最大區別是前者較偏向於離
Spark的啟動程序詳解
Master和Worker是執行任務之前存在的程序 (類似於公司) Driver和Excutor是任務執行之後存在的程序(類似於公司接到專案後才成立的專案小組) 啟動步驟: 啟動Master資源管理程序和Work程序 有任務來執行時會啟動Driver程序,然後向Master資源管理程序進行註冊
大資料學習之路107-spark streaming基於mysql歷史state統計
package com.test.sparkStreaming import java.sql.{DriverManager, PreparedStatement} import com.typesafe.config.{Config, ConfigFactory} im
spark 引數調優詳解(持續更新中)
spark引數調優需要對各個引數充分理解,沒有一套可以借鑑的引數,因為每個叢集規模都不一樣,只有理解了引數的用途,調試出符合自己業務場景叢集環境,並且能在擴大叢集、業務的情況下,能夠跟著修改引數。這樣才算是正確的引數調優。 1、背景 使用spark-thriftser
Spark運算元執行流程詳解之六
coalesce顧名思義為合併,就是把多個分割槽的RDD合併成少量分割槽的RDD,這樣可以減少任務排程的時間,但是請記住:合併之後不能保證結果RDD中的每個分割槽的記錄數量是均衡的,因為合併的時候並沒有考慮合併前每個分割槽的記錄數,合併只會減少RDD的分割槽個數,因此並不能利用它來解決資料傾斜的問題。 d
spark log4j.properties配置詳解與例項
################################################################################ #①配置根Logger,其語法為: # #log4j.rootLogger = [level],appen
Hadoop Hbase Spark 配置文件詳解
hadoop 1.core-site.xml 1.fs.defaultFS hdfs預設埠 2.hadoop.tmp.dir Hadoop.tmp.dir是hadoop檔
《深入理解Spark》之運算元詳解
XML Code 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
Hadoop+Spark叢集安裝步驟詳解
一、環境:作業系統版本:SUSE Linux Enterprise Server 11 (x86_64) SP3主機名:192.168.0.10 node1192.168.0.11 node2192.168.0.12 node3192.168.0.13
Spark運算元執行流程詳解之八
針對rdd的每個元素利用f進行處理 /** * Applies a function f to all elements of this RDD. */ def foreach(f: T => Unit): Unit = withScope { val cleanF = sc.clean
Spark運算元執行流程詳解之四
針對RDD的每個分割槽進行處理,返回一個新的RDD /** * Return a new RDD by applying a function to each partition of this RDD. * * `preservesPartitioning` indicates whether t
spark 自定義排序詳解
目的: 排序輸出資料是資料處理的常見操作,本篇部落格示例解決元組、字串按照key、value進行單值、多值 自定義排序問題。 程式碼 package LoadTest import org.apache.log4j.{Logger, Level} impo
Spark運算元篇 --Spark運算元之aggregateByKey詳解
一。基本介紹 rdd.aggregateByKey(3, seqFunc, combFunc) 其中第一個函式是初始值 3代表每次分完組之後的每個組的初始值。 seqFunc代表combine
Spark Streaming StreamingContext詳解
一、StreamingContext的建立方式 (1)使用configuration建立 val conf = new SparkConf().setAppName(appName).setMaster
Spark Streaming 輸入DStream和Receiver詳解
輸入DStream和Receiver詳解 輸入DStream代表了來自資料來源的輸入資料流。在之前的wordcount例子中,lines就是一個輸入DStream(JavaReceiverInputDStream),代表了從netcat(nc)服務接收到的資
Linux下基於Hadoop的大資料環境搭建步驟詳解(Hadoop,Hive,Zookeeper,Kafka,Flume,Hbase,Spark等安裝與配置)
Linux下基於Hadoop的大資料環境搭建步驟詳解(Hadoop,Hive,Zookeeper,Kafka,Flume,Hbase,Spark等安裝與配置) 系統說明 搭建步驟詳述 一、節點基礎配置 二、H