
打造高效能日誌系統
前言
說起日誌系統, 大家都不陌生, 每次線上出了問題, 大家通常都會第一時間抓log回來進行分析, 很多時候這些log是我們恢復現場的重要途徑也可能成為了唯一手段, 所以重要性不言而喻. 市面上的開源日誌系統有很多, 如log4cxx, log4cpp, glog等等, 最終目的都只有一個 -- 寫日誌. 於是如何優雅,高效,安全的寫日誌是大家的一致需求.
說起優雅, 這裡我指的是風格上的優雅, 也有指介面使用上的優雅, 這些庫都下了不少功夫也幾乎奠定了行業標準, 比如自定義format, log level, 靈活的config file.
說起安全, 這裡指執行緒安全, 不能一條log被打散分成了多節穿插在多條log中間, 這樣的日誌就完全沒有可讀性, 幾乎無用了.
說起高效, 大家各顯神通, 從系統介面上的選取, 設計模型上的斟酌, 再到程式碼級別的優化.
好了, 廢話不多說了, 介紹了一些大體情況後, 本篇將會講述使用Thread Caching模型來編寫高效的日誌系統. 文章將會分為幾個部分:
- 需求分析
- 設計模型
- 流程分析
- 測試結果
- 程式碼優化
- 總結
好了, 那我們開始吧 :D
需求分析首先我們要明確一些目的, 在保證優雅安全的前提下儘可能的快速, 這是前提, 否則一切都是空談. 那是不是越快越好那? 這個問題我們先留在後面進行分析.
明確前提的情況下, 我們先來看看傳統經典的模型是什麼樣的. 下圖是一個傳統非同步寫入的模型:
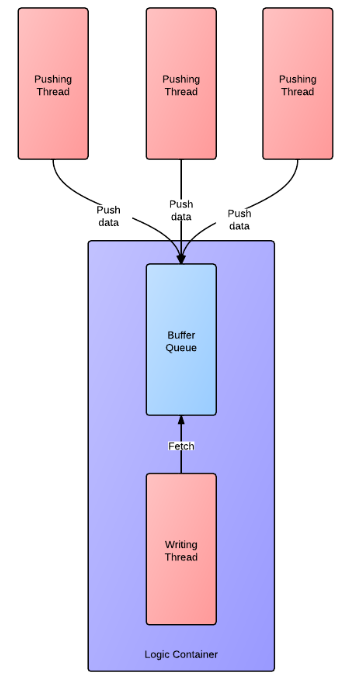
採用非同步介面主要為了避免磁碟IO阻塞導致邏輯執行緒阻塞, 阻塞現象在生產環境中是不可容忍的問題.
多執行緒方面, 通常使用加鎖保證寫入日誌安全性, 防止log被打散. 但這也造成了效能的損失, 效能損失會隨著每條log寫入時間的長短以及有多少個執行緒同時寫共同影響.
現在我們來整理一下需求, 接下來要做的日誌系統需要滿足以下幾點要求:
- 提供非同步介面.
- 執行緒安全.
- 完全無鎖化.
設計模型
為了滿足執行緒安全還要實現無鎖, 傳統的模型無法滿足, 我們仔細分析一下傳統模型的思路 -- 當多個執行緒同時寫日誌時, 資料被壓入一個buffer佇列中, 此時buffer跟後臺執行緒在邏輯上通常聯絡到一起, 認為是一個整體看待, 後臺執行緒的職責為被動接受資料並寫入磁碟, 此時的模型為多個生產者一個消費者, 必然導致加鎖. 換個思路, 化被動為主動, 如果為每個執行緒分配一塊自己的buffer, 而後臺執行緒主動的去每個thread buffer中取資料, 再寫入磁碟, 此時的模型以buffer為中心, 總是保持一個生產者跟一個消費者. 接觸過lockfree佇列的同學們應該都清楚, 在這種模型下, buffer的push和pop操作都可以做到無鎖(這裡的無鎖是真正的不使用鎖操作, 而不是CAS那種無鎖).

OK, 似乎勝利的曙光正在向我們靠近, 不過也別高興的太早, 我們還有一些技術關鍵點需要克服:
- 多個使用者執行緒push資料, 採用何種方式通知fetcher(這裡我暫且將後臺取資料的執行緒叫fetcher), 而且需要做到儘量公平的取走每個buffer中的資料, 而不造成對待不均的問題?
- 當用戶執行緒退出時, 此時thread buffer中還有資料, 何時優雅的釋放掉資源?
- 使用者執行緒的buffer queue size是定長還是變長? 如何應對使用者執行緒push log資料速度過快?
對於問題1: 在linux kernel2.6.22之後引入了一個叫做eventfd的feature, 可以使用這個feature為每個使用者thread建立一個event fd, 每次push log時對該event fd繫結的value加一即可, 在fethcer中使用epoll/select監控這些event fd, 發生變化時, fetcher即被啟用, 並讀取活動的event fd中的value, 此時這個value即為要取的message數量. 這樣我們是嚴格按照接到的通知從指定的buffer中讀取指定數目的log message, 不會一直讀下去(比如讀到空為止, 如果這個user thread一直活躍而且拼命的寫log, 我們的fetcher就變成他一個人的奴隸了), 這樣的方式即可保證更大限度的公平讀取.
對於問題2: 如果thread buffer中沒有資料, 我們直接釋放資源即可, 麻煩就出在如果還有資料的這種情況, 解決方案這裡給出2種:
- 增加一個標誌位, 如果user thread退出, 這個標誌位置true. 接下來我們需要在fetcher中增加一段檢測邏輯, 在每次fetch完這個佇列給定數目的message後去檢查一次這個標誌位是否為true並且此時buffer是否為空, 如果標誌位為true, buffer也為空, 則可以安全的釋放資源.
- 為每種log行為定義一個protocol id, 並放入log message頭部中. 比如 id=0 為push log message, id=1 為user thread退出行為, fetcher先取出log message header, 取出這個id就知道接下來要操作的data是何種行為了, 此時如果拿到了id=1的message, 直接釋放資源即可. 這種方案也是我選擇的方案, 方便定義和擴充套件其他行為.
流程分析
經過上面的分析, 我們已經知道了具體的模型, 下面還是來看下具體的流程圖, 乾巴巴的文字始終不如圖來的直觀.
1. 非同步寫流程:
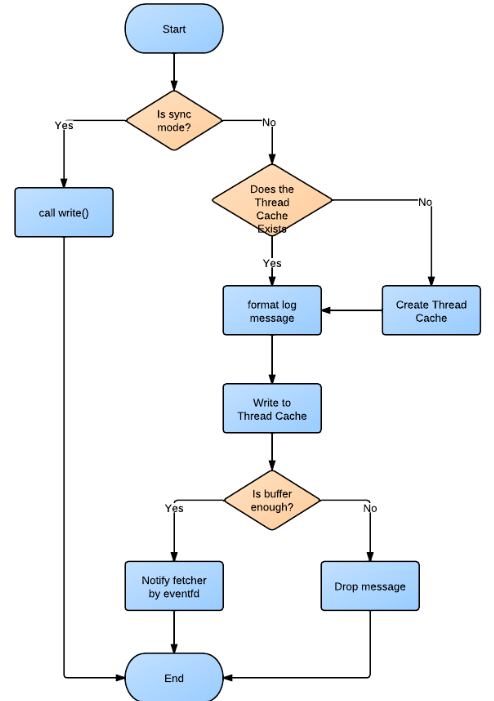
2. Fetcher流程:

這裡面一個重要的資料結構即log message. 如下圖:

- ID: 1 byte
- Log File Ptr: 4 bytes(in 32bit) / 8 bytes (in 64bit)
- Length: 2 bytes
- Log Message: Length of itself
這裡有意思的一個改變就是, 我們像做網路程式設計一樣編寫這個日誌庫, 概念上fetcher好像一個server, user thread作為client, 多個client與server互動通過構造好的protocol. :D
這裡或許大家會有疑問, ID只會是一個很小的資料集(當前只用了0和1), 而length又有一個max的limitation為4096 bytes, 所以說ID和Length可以合併在2bytes內, 不過目前這樣實現還是出於方便考慮.
測試結果
硬體測試環境:
CPU: Intel Xeon E5645 2.40Gz * 24
MEM: 24G
DISK: 100M+ w/s
程式設定:
Buffer per-thread: 200M, 避免由於buffer滿而drop message
Log Message Size: 500 bytes
Total Message : 1,000,000
測試目標: 單純測試介面呼叫效率, 如果說因為磁碟瓶頸導致fetcher速度跟不上user push速度, 這又是另外一方面了.
測試結果(圖的橫軸代表執行緒數目, 縱軸代表介面呼叫消耗時間, 越短越好, 單位micro-second):

另外2組資料:
sync writing max speed: 1,549,359 msg/s
sync writing min speed: 493,787 msg/s
async writing max speed: 4,866,937 msg/s
async writing min speed: 1,762,602 msg/s
總體來說, 效果還是很不錯的.
ps: 這個測試程式可以做到測試目標機器使用這套log system下的極限非同步寫入速度(根據fetcher的速度調整, 類似滑動視窗方式調節速率), 以及統計丟失率等.
程式碼優化
起初剛剛寫完的那版效果並不太理想, 經過一步步優化最終還算滿意, 簡單說說優化的經歷. 總體的過程分為2步:
1) 演算法/結構/設計上的優化
2) 程式碼級別的優化
完成第一步, 最重要的就是先找到熱點, 下面這張圖顯示了第一版時的熱點所在:
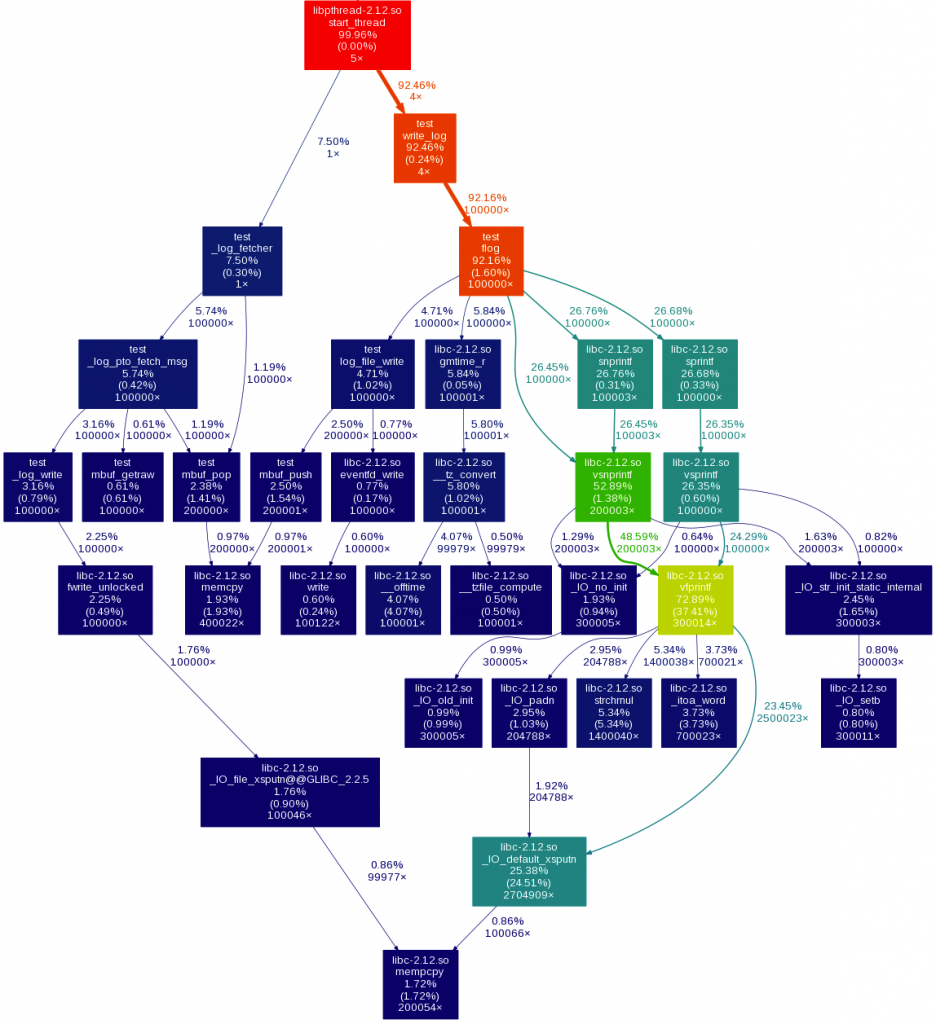
可以看到, 熱點在很多次的sprintf, snprintf呼叫佔用了大量時間, 呼叫這些函式主要做了一些format time和format log message的工作, 減少呼叫次數將是關鍵, 目標是合併為一次呼叫. 通過分析, time在每秒鐘內只需format一次, 其他時候直接copy即可. 這樣我們只需format一次log message.
經過這種優化再來看看熱點圖:

現在沒有什麼主要熱點了, 接下來我們開始從code level進行入手. 我們先來看一段引自valgrind document中的話:
On a modern machine, an L1 miss will typically cost around 10 cycles, an LL miss can cost as much as 200 cycles, and a mispredicted branch costs in the region of 10 to 30 cycles. Detailed cache and branch profiling can be very useful for understanding how your program interacts with the machine and thus how to make it faster.
CPU Cache與分支預測的效能損耗值得我們關注, 不過介於CPU Cache的有限, miss的情況必然會發生, 只不過我們根據區域性性原理最大限度的利用已經載入Cache的資料即可, 更多不可避免的miss通常也不太好去優化, 不過我這裡經驗也有限, 暫時也沒什麼更多可以多聊的, 比較遺憾了. 還是主要集中在分支預測方面給予優化. 所以首先我們需要知道一些事實:
1) 並不是所有的分支都需要動手優化, CPU有自己的預測機制, 通常也都很準確, 已經可以規避大部分miss, 只有小部分會讓CPU預測失效
2) 並不是所有靠近if的語句都一定會被編譯器安排到靠近if的地方.
3) 即使放在最靠近if地方的語句, 其準確率依然無法保證, 這取決於最終的跳轉方式.
基於以上3點, 我們所能做的就是測量哪些是預測失敗重災區, 然後通過優化減少miss. 通常我們有幾種solution:
1) 通過table mapping進行跳轉優化, 比如將要執行的分支函式都放進一個array中, 根據if的結果直接對映到函式進行跳轉. 不過這樣的做法會讓程式碼的可讀性急劇下降, 零散不堪, 我並不太喜歡這種做法.
2) 通過__builtin_expect提示編譯器哪條分支被執行的可能性更大, 編譯器會根據該提示將可能性大的分支放在前面, 防止不必要的跳轉造成branch miss. 這種手段在kernel中很常見, 我們經常看到的那個likely/unlikely macro就是幹這個的. 我比較喜歡這種做法, 可以在不破壞程式碼結構和邏輯正確性的前提下進行優化.
OK, 我們先起用cachegrind來分析一下cache miss率以及分支預測miss率. 系統呼叫我們先暫時不去管, 先集中精力看下自己寫的code中哪些地方有問題. 通過呼叫10萬次非同步寫操作觀測結果 ( 由於cachegrind生成的結果資料有些多, 我暫時整理出一些重要的 ) 如下所示:
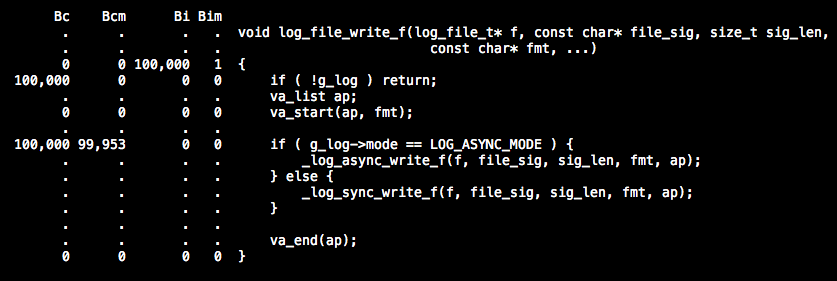
我們發現"if ( g_log->mode == LOG_ASYNC_MODE )" 這句話執行了10萬次就有9萬多次的branch miss, 但我明明是執行的非同步寫操作, 而且也將我們認為可能性大的非同步呼叫放在了前面, 可還是出現幾乎100%的branch miss, 不禁讓人感到奇怪. 原因在哪, 我們通過objdump分析assemble code來看看問題到底出在哪裡:

稍微解釋下, 第一行就是在判斷mode是否等於ASYNC_MODE, 如果是就跳轉到1750(_log_async_write_f)去執行_log_async_write_f, 邏輯上來說確實符合我們的希望, 但是結果上來看CPU在這段code上確實失誤不少, 並不能準確的判斷出跳轉到1750的概率更高. 從而導致幾乎每次都預測失敗並jump走, break了當前流水線.
所以, 我們可以像kernel一樣定義2個macros:( 注意在gcc 2.96後才支援)
[cpp] view plaincopyprint?- #define likely(x) __builtin_expect(!!(x), 1)
- #define unlikely(x) __builtin_expect(!!(x), 0)
[cpp] view plaincopyprint?
- if ( unlikely( g_log->mode == LOG_SYNC_MODE ) {
- _log_sync_write_f(...);
- } else {
- _log_async_write_f(...);
- }

稍微解釋下, 第一行測試一下mode是否為0(即SYNC_MODE的值), 如果成立, 則跳轉去執行_log_sync_write_f, 這樣會導致break流水線, 不過由於我們是執行非同步寫操作, 所以這一條不會成立, 進而是後面2條預讀的語句總是可以順利執行, 而後面這2條恰好就是_log_async_write_f函式開始的邏輯, 被編譯器直接優化放到這裡, 從而做到了減少branch miss. 哈哈, 是不是效果一下子就出來了. 通過cachegrind得到的最終結果, 光這一條改動就減少了0.5%的branch miss. 按照這個思路, 改動幾處影響比較惡劣的即可了.
總結
回顧這次coding過程, 不難發現, 單純比較sync/async介面效能是不一定能說明問題, 單純從效能來看, sync的介面效能也不一定差, 尤其是在單執行緒情況下更是不分伯仲, 有時候sync還要比async更快, 那麼是什麼讓我們一定要選擇async方式那? 問題就出在磁碟IO的不穩定性上, 尤其是機械硬碟物理上的尋道時間不均, 過熱,碎片過多寫入效率低下可能導致的卡住一段時間, 如果是sync方式, 這會導致"有可能"block住我們的worker thread, 而一旦出現這種情況, 在生產環境中幾乎是0容忍度. 這讓我想起了 blocking/non-blocking, sync/async, 我們經常提及的2組詞, 但是也經常被我們搞混, sync方式不代表性能一定會很差, 介面一定會是blocking的, 我們一樣可以使用non-blocking的方式去操作它, 更好的理解他們, 可能要將這2組詞彙分開來看:
blocking/non-blocking意味著介面是否有潛在被block的風險, blocking方式說明一定會存在風險, 但不意味著每次都會出現, 而non-blocking方式則明確表態不會.
而sync/async則代表著處理事務的一種思想, 比如通俗的講, 交給你一件事情, sync代表在你做這件事的時候我會放下手裡的工作, 一直等到你做完為止; 而async代表我告訴你該去做什麼後, 我先不去理會你, 該做啥做啥去, 你做完的時候是否通知我, 取決去我的需求.
所以說, 這兩種概念有聯絡, 但也不要簡單的混為一灘, 要分開理解對待, 屬於兩個範疇. 所以sync的方式不一定會慢, 這取決於是否會block, 如果不被block, 通常他會顯得更加高效, 而且實現起來也更加清晰, 簡單. async方式雖然消除了block帶來的影響, 但需要更多的邏輯保證正確性, 多了callback也必然會增加開銷, 也導致整體邏輯被拆散, 可讀性下降.
綜上, 如何取捨, 取決於實際產品, 實際需求, 不可一概而論.
對於這個日誌系統, 還是有些不足的, 比如多執行緒情況下雖然狀態穩定, 但卻比我的預期要差一點點, 當然, code方面的繼續優化還是可以提高表現的, 不過我一直懷疑"偽共享"這種情況在這裡到底能產生了多大的影響, 該如何有效測量它, 確是一個讓我很好奇的點. 在接下來的工作學習中, 或許可以找到更好的答案. :D
把握每次coding的機會, 點滴進取, 積少成多. :)
相關推薦
打造高效能日誌系統
前言 說起日誌系統, 大家都不陌生, 每次線上出了問題, 大家通常都會第一時間抓log回來進行分析, 很多時候這些log是我們恢復現場的重要途徑也可能成為了唯一手段, 所以重要性不言而喻. 市面上的開源日誌系統有很多, 如log4cxx, log4cpp, glog等
最新EasySwoole+ElasticSearch打造高效能小視訊服務系統
第1章 課程概述 本章介紹課程技術點、需要的環境準備以及easyswoole的簡介,讓大家輕鬆掌握課程的特色,明確學好本門課的技術儲備。 1-1 導學 1-2 easyswoole簡介 1-3 環境準備以及課程技術點介紹
EasySwoole+ElasticSearch打造高效能小視訊服務系統
第8章 利用EasySwoole和ElasticSearch打造高效能的小視訊搜尋服務 本章介紹高效能分散式 elasticsearch、技術選型、 jdk獲取和安裝、es單機安裝和分散式安裝 、easyswoole整合elasticearch等,帶大家實戰easyswoole層和elasticsea
Log4j2 + SLF4j打造日誌系統
目錄 一:前言 二:新增依賴 2.1:去除直接和間接依賴的log4j1和SLF4j 2.2:新增依賴 三:xml配置 3.1:log4j2.xml常用demo 3.2:demo的優點 3.3
基於Flume+kafka打造實時日誌收集分析系統
Kafka broker修改conf/server.properties檔案,修改內容如下: broker.id=1 host.name=172.16.137.196 port=10985 log.dirs=/data/kafka
高效能的PHP日誌系統 SeasLog
參考文件:http://neeke.github.io/SeasLog/ 什麼是SeasLog SeasLog是一個C語言編寫的PHP擴充套件,提供一組規範標準的功能函式,在PHP專案中方便、規範、高效地寫日誌,以及快速地讀取和查詢日誌。 一.什麼是日誌系統 1. 記
ceph儲存 打造高效能高可靠塊儲存系統
塊儲存系統 分散式儲存有出色的效能,可以扛很多故障,能夠輕鬆擴充套件,所以我們使用Ceph構建了高效能、高可靠的塊儲存系統,並使用它支撐公有云和託管雲的雲主機、雲硬碟服務。 由於使用分散式塊儲存系統,避免了複製映象的過程,所以雲主機的建立時間可以縮短到10秒以內,而且雲主機
Tomcat日誌系統詳解
mat core catalina res 最大的 tor dumps 異常 startup 綜合:Tomcat下相關的日誌文件 catalina引擎的日誌文件,文件名:catalina.日期.log Tomcat下內部代碼丟出的日誌,文件名localhost.日期.lo
Spring Boot入門第三天:配置日誌系統和Druid數據庫連接池。
禁用 css ret 輸入 ogg servlet log http gif 一、日誌管理 1.在application.properties文件中加入如下內容: logging.level.root=WARN logging.level.org.springfram
使用FineReport打造考試分析系統
報表 移動 技術分享 主任 目標 其它 ng- strong 教學 本系統的優點: 1、報表內容豐富:系統中包含總分分析、小分分析、作答錯因分析、試卷命題分析和各類用戶報告單五類報表。涵蓋學校須要的各項分析數據,並提供豐富的圖表,使分析數據更直觀表現。 2、操作
第二十三周微職位elk日誌系統
elk+nginx日誌系統利用ELK+redis搭建一套nginx日誌分析平臺。logstash,elasticsearch,kibana 怎麽進行nginx的日誌分析呢?首先,架構方面,nginx是有日誌文件的,它的每個請求的狀態等都有日誌文件進行記錄。其次,需要有個隊列,redis的list結構正好可以作
Javaweb日誌系統
部署 項目管理工具 管理 配置 att 項目 ica sym nbsp 1.SLF4J SLF4J,即簡單日誌門面(Simple Logging Facade for Java),不是具體的日誌解決方案,它只服務於各種各樣的日誌系統。按照官方的說法,SLF4J是一個用於日誌
部署 Graylog 日誌系統 - 每天5分鐘玩轉 Docker 容器技術(92)
docker 教程 容器 Graylog 是與 ELK 可以相提並論的一款集中式日誌管理方案,支持數據收集、檢索、可視化 Dashboard。本節將實踐用 Graylog 來管理 Docker 日誌。Graylog 架構Graylog 架構如下圖所示:Graylog 負責接收來自各種設備和應用的日
日誌系統
進行 5.5.0 worker stdout 時區 小時 存儲 match 基本用法 從ELK到EFK演進 背景 作為中國最大的在線教育站點,目前滬江日誌服務的用戶包含網校,交易,金融,CCTalk 等多個部門的多個產品的日誌搜索分析業務,每日產生的各類日誌有好十幾
.NET下使用 Seq結構化日誌系統
eof 檢索 fig 直連 自定義 兩個 img 性能 collect 前言 我們公司在日誌管理方面一直沒有統一,主要痛點有: 每個開發人員都是各用各的,存儲日誌的形式也是五花八門,如:本地文件,數據庫,Redis,MongoDB 由於公司訪問服務器要通過堡壘機
graylog 2.3.2 日誌系統安裝指南
graylog cnop Java (>= 8)MongoDB 3.2Elasticsearch 2.Xgraylog 2.3.2IP 192.168.0.210centos 7.xIP 192.168.0.210 (單機測試) 結構:mongodb + elasticsearch + gra
數據庫日誌系統分解
mysql 日誌標題索引日誌分類日誌操作日誌分解日誌分類 在數據庫系統中日誌主要分為6類,具體如下: 1、查詢日誌:主要記錄日常查詢的記錄; 2、慢查詢日誌:主要記錄查詢時長超過設置的數值時間的語句,方便DBA運維人員進行查詢; 3、錯誤日誌:主要用於記錄錯誤的事件,方便DBA運維人員
記錄日誌系統ELKB 5.6.4的搭建過程
logstash elk stack 集中式日誌系統 前言ELK是最近比較流行的免費的日誌系統解決方案,註意,ELK不是一個軟件名,而是一個結局方案的縮寫,即Elasticsearch+Logstash+Kibana(ELK Stack),其中Logstash負責日誌的采集和過濾,Elastics
centos7 部署 ELK 日誌系統
stash 修改配置 ali 分享 install .cn data entos 生產環境 =============================================== 2017/12/17_第1次修改 ccb
Slf4j與其他日誌系統兼容的使用
console 項目 load 循環 bridge 1.2 關於 重新 順序 java生產的各種框架(如spring等)裏各個框架會使用不同的日誌體系,多個不同日誌在一個jvm裏混搭會出現一定問題 ,這裏梳理一下java體系裏常見的日誌框架,以SFL4j為中心介紹下跟各個日