
爬蟲案例之藥品通用名和商品名資料庫下載
阿新 • • 發佈:2019-01-14
如圖:我想把圖中的表格給下載下來。
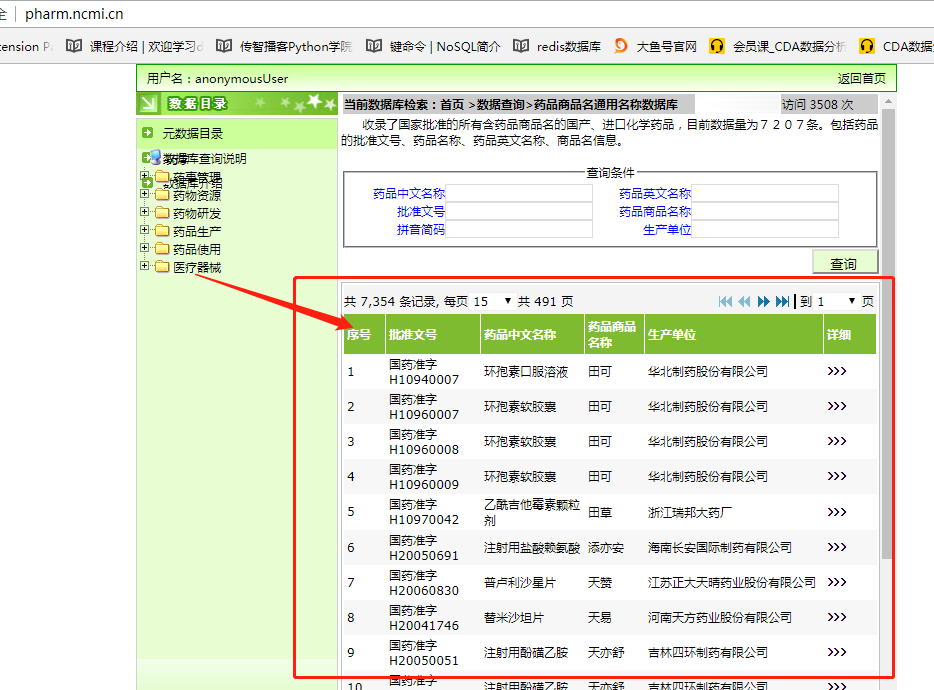
分析頁面請求,發現是ajax請求,不需要cookie,post請求需要帶一些引數,總之發現實現流程很簡單。但關鍵是從頁面提取表格,這裡主要用到了pandas的read_html,使用這個函式可以使我們很方便的提取也頁面的表格資訊。
程式碼
# -*- coding: utf-8 -*-
"""
@Datetime: 2018/11/11
@Author: Zhang Yafei
"""
from multiprocessing import Pool
import pandas
import requests
import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
HTML_DIR = os.path.join(BASE_DIR,'藥品商品名通用名稱資料庫')
if not os.path.exists(HTML_DIR):
os.mkdir(HTML_DIR)
name_list = []
if os.path.exists('drug_name.csv'):
data = pandas.read_csv('drug_name.csv',encoding='utf-8')
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Content-Length': '248',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'JSESSIONID=0000ixyj6Mwe6Be4heuHcvtSW4C:-1; Hm_lvt_3849dadba32c9735c8c87ef59de6783c=1541937281; Hm_lpvt_3849dadba32c9735c8c87ef59de6783c=1541940406',
'Upgrade-Insecure-Requests': '1',
'Origin': 'http://pharm.ncmi.cn',
'Referer': 'http://pharm.ncmi.cn/dataContent/dataSearch.do?did=27',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
def spider(page):
adverse_url = 'http://pharm.ncmi.cn/dataContent/dataSearch.do?did=27'
form_data = {
'method': 'list',
'did': 27,
'ec_i': 'ec',
'ec_crd': 15,
'ec_p': page,
'ec_rd': 15,
'ec_pd': page,
}
response = requests.post(url=adverse_url,headers=header,data=form_data)
filename = '{}.html'.format(page)
with open(filename,'w',encoding='utf-8') as f:
f.write(response.text)
print(filename,'下載完成')
def get_response(page):
file = os.path.join(HTML_DIR,'{}.html')
with open(file.format(page),'r',encoding='utf-8') as f:
response = f.read()
return response
def parse(page):
response = get_response(page)
result = pandas.read_html(response,attrs={'id':'ec_table'})[0]
data = result.iloc[:,:5]
data.columns = ['序號','批准文號','藥品中文名稱','藥品商品名稱','生產單位']
if page==1:
data.to_csv('drug_name.csv',mode='w',encoding='utf_8_sig',index=False)
else:
data.to_csv('drug_name.csv',mode='a',encoding='utf_8_sig',header=False,index=False)
print('第{}頁資料存取完畢'.format(page))
def get_unparse_data():
if os.path.exists('drug_name.csv'):
pages = data['序號']
pages = list(set(range(1,492))-set(pages.values))
else:
pages = list(range(1,492))
return pages
def download():
pool = Pool()
pool.map(spider,list(range(1,492)))
pool.close()
pool.join()
def write_to_csv():
pages = get_unparse_data()
print(pages)
list(map(parse,pages))
def new_data(chinese_name):
trade_name = '/'.join(set(data[data.藥品中文名稱==chinese_name].藥品商品名稱))
name_list.append(trade_name)
def read_from_csv():
name = data['藥品中文名稱'].values
print(len(name))
chinese_name = list(set(data['藥品中文名稱'].values))
list(map(new_data,chinese_name))
df_data = {'藥品中文名稱':chinese_name,'藥品商品名稱':name_list}
new_dataframe = pandas.DataFrame(df_data)
new_dataframe.to_csv('unique_chinese_name.csv',mode='w',encoding='utf_8_sig',index=False)
return new_dataframe
def main():
download()
write_to_csv()
return read_from_csv()
if __name__ == '__main__':
drugname_dataframe = main()
知識點總結:1.ajax的post請求,不需要登入
2.多程序下載
3.解析資料用read_html快速提取表格