
003-Ambari一鍵自動化部署指令碼
微信搜尋公眾號:BearData,關注更多內容。
根據前兩篇 “Ambari大資料平臺搭建利器(一)&(二)”, 我們已經完成大資料平臺的搭建,但是我們發現安裝Ambari的步驟比較繁瑣。我們發現手動部署存在以下的劣勢:
- 每個節點都要執行重複的命令,我們前兩篇測試的節點只有三個,如果生產環境有上百個節點,這也是工作量比較大的一件事。
- 如果是基於專案的平臺,如果有幾十甚至上百個客戶,安裝平臺就是一件比較麻煩的事。
- 如果我們修改了原始碼,在測試環境中,很有可能要來回解除安裝,安裝。
- 人工操作會有一定的風險。
基於上述,我們打算寫一套指令碼,主要是安裝Ambari server和agent,以及前期的環境檢查,準備,修復,解除安裝。
注:如果只是個人測試學習,或者基於雲端部署一套大資料平臺,可以手動操作,這種場景是一次性的操作,並且之後很少再重新部署。
本篇主要是基於前兩篇的基礎上做的,因此需要對前兩篇內容需要了解一下。
整體流程
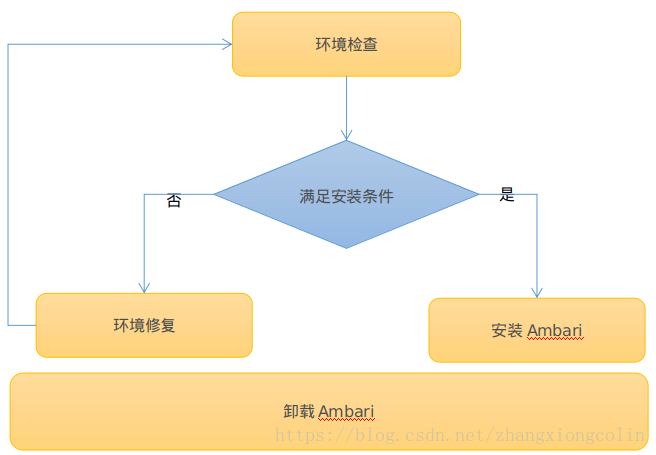
環境檢查:檢查服務安裝的每個節點是否滿足安裝Ambari的條件,如JDK,OpenSSL,Ambari Server需要檢查PostgreSQL等等。
環境修復:如果某些節點或者所有節點不滿足安裝條件,則需要通過修復來滿足安裝條件,如JDK沒有安裝,則需要安裝JDK,並且設定環境變數。
安裝Ambari:如果條件滿足,則在指定的節點安裝Ambari Server以及在每個節點安裝Ambari agent。
解除安裝Ambari:解除安裝Ambari Server及Ambari agent。
技術選型
- 程式語言:Python
- 由於要在每個節點執行相同的命令(Server和Agent有區別),所以要選一種封裝了SSH的庫,我們選擇Python中的Fabric。
- 指令碼是執行在安裝Ambari Server的節點上的,為了不影響原系統中的Python,我們需要在指令碼中搭建Python虛擬環境。
技術實現
- 配置檔案
配置檔案主要配置了程式中需要讀取的靜態屬性。
[node_host]: 配置安裝agent的節點IP和主機名
節點IP=主機名,如 192.168.163.130 = bigdata001
[domain_name]: 域名配置字尾
suffix = 域名字尾,如 suffix = bdp.com
[host_certification]: 操作使用者名稱密碼
host_user = 使用者名稱
host_password = 密碼
[server_host]: Ambari Server 安裝主機IP
server_ip = 主機IP
[language]: 配置安裝時的語言
language = zh_CN
#language = en_US
[ntp]: 配置ntp時間同步server,如果沒有配置該項,並且在外網連通的情況下會讀取網路時間
#ntp_server = 192.168.163.130
[resource_path]:源相關配置
main_version = 2.6.2.0 #Ambar大i版本號
min_version = 155 #Ambari小版本號
yum_host_ip = 192.168.70.52 #yum源地址
HDP = ambari,HDP,HDP-UTILS #Ambari源的資料夾
[java_home]: JDK 安裝路徑
java_home = /opt/jdk1.8.0_111
[python_virtual_path]:Python虛擬環境路徑
py_path = ~/py_virtual
[software_package]:環境修復,虛擬環境所依賴的軟體包
jdk = jdk-8u102-linux-x64.tar.gz
openssl = openssl-1.1.0a.tar.gz
postgresql = postgresql-9.2.15.tar.gz
httpd = httpd-2.2.31.tar.gz
python = Python-2.7.5.tgz
ruby = ruby-2.0.0.tar.gz
ntp = ntp-service-centos7.tar.gz
setuptools = setuptools-36.0.0.tar.gz
ecdsa = ecdsa-0.13.tar.gz
pycrypto = pycrypto-2.6.1.tar.gz
paramiko = paramiko-1.17.2.tar.gz
[remove]:解除安裝時所刪除的包,目錄,使用者等資訊
#############解除安裝安裝包(RPM包)###############
remove_package = hadoop_2*,hdp-select*,ranger*,zookeeper*,bigtop*,atlas-metadata*,ambari-agent,postgresql*,spark*,smartsense-hst,ambari-metrics*,ambari-infra*,ambari-logsearch*,opentsdb*,redis*,hbase*,tez*,hive*,pig*,sqoop*,storm*,flume*,kafka*,zeppelin*,mahout*,slider*,cassandra*,phoenix*,extjs*,knox*,oozie*,accumulo*,elasticsearch_*,mysql_*,mycat_*,keepalived_*,haproxy_*,logstash_*,kibana_*,solr_*,rstudio-server_*,ceph*,kylin_*,greenplum_*
#################刪除使用者##########################
remove_user = ambari-qa,ams,falcon,flume,hbase,hcat,hdfs,hive,kafka,livy,mahout,mapred,oozie,opentsdb,redis,spark,sqoop,tez,yarn,zeppelin,zookeeper,cassandra,infra- solr,storm,livy,logsearch,knox,atlas,kms,ranger,accumulo,elasticsearch,mysqldb,mycat,keepalived,haproxy,logstash,kibana,solr,rstudio-server,ceph,kylin,gpadmin
####################刪除目錄###############################
remove_dir = /etc/,/var/lib/,/tmp/,/usr/lib/,/var/log/,/var/run/,/var/tmp/,/usr/bin/,/tmp/,/var/,/opt/,/data/
########################刪除檔案##################################
remove_file=ambari*,ams*,falcon*,flume*,hadoop*,hbase*,hive*,kafka*,oozie*,opentsdb*,postgresql,spark*,sqoop*,zeppelin,zookeeper*,storm*,smartsense,hadoop*,phoenix*,redis,slider,tez*,pig*,pgsql,cassandra,webhcat,mahout,hcat,accumulo*,hdfs*,mapred*,ranger*,slider*,atlas*,yarn*,worker-lanucher,beeline,logsearch*,knox*,ranger*,elasticsearch,mysqldb,mycat,keepalived,haproxy,logstash,kibana,solr,service_solr,rstudio-server,ceph,kylin,greenplum
########################刪除特殊目錄#########################################
spec_dir = /usr/hdp,/hadoop,/kafka*,/usr/share/HDP-oozie,/var/local/osd*,/etc/systemd/system/multi-user.target.wants/[email protected]*.service
以上就是配置檔案內容及說明。
- Python虛擬環境
思路很簡單,期實現就是將系統中的Python重新拷貝一份到指定目錄下,然後將Fabric及依賴包進行安裝,每次執行時都會去檢查配置的虛擬環境路徑是否存在,如果存在則直接使用,不存在則建立虛擬環境。
- 環境檢查
我們在該指令碼中環境檢查項主要包括:JDK,Python,OpenSSL,Httpd,最大檔案數,NTP,防火牆,SELinux,SSH,主機名,HOSTS檔案,PGSQL,PackageKit。每項檢查失敗都有對應的修復。
我們以檢查防火牆是否關閉為例,來說明環境檢查的過程。
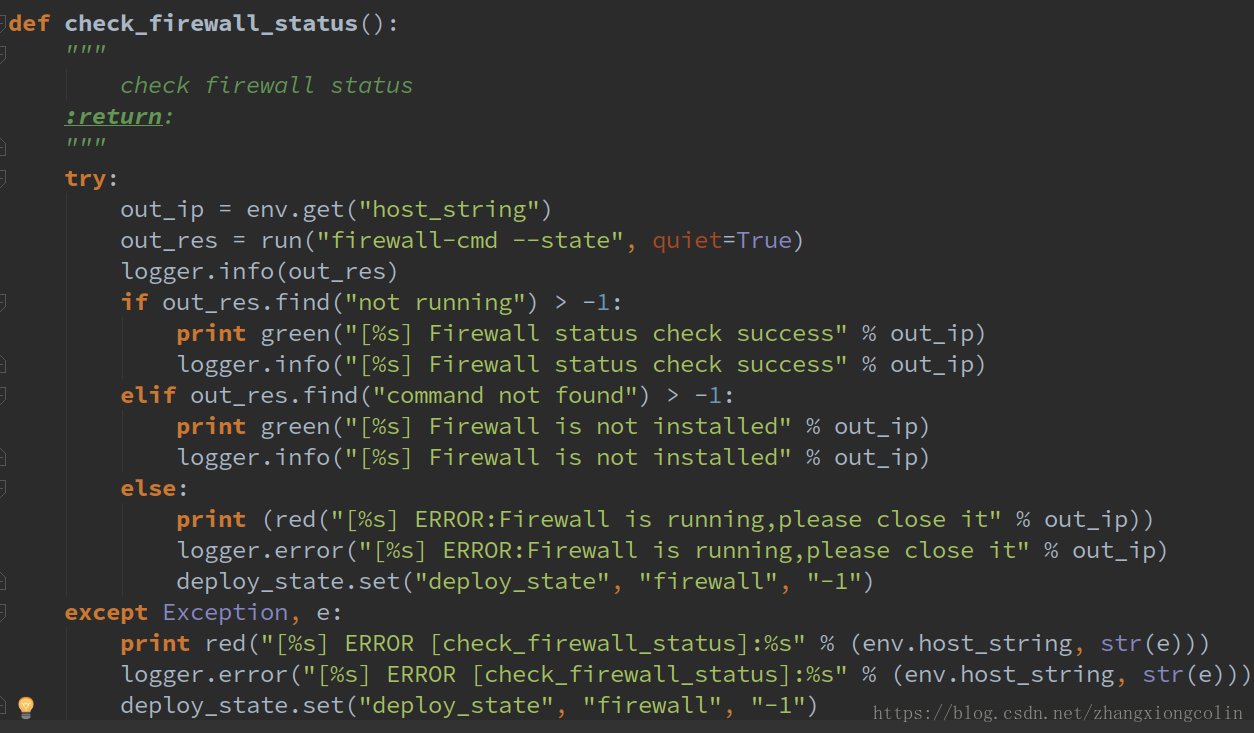
check_firewall_status()方法是整個檢查的核心部分。
1. 在每個節點執行檢查防火牆狀態的命令:firewall-cmd status (不同的作業系統,檢查的命令略微有區別)
2. 判斷返回的內容,如果是 "not runnind" 則表示防火牆已處於關閉的狀態。如果返回值為 “command not found” 則表示未安裝防火牆指令(一般這種情況比較少,因為系統預設會有安裝)。
3. 如果2中的條件都沒有滿足,則防火牆就處於 running 狀態,將改資訊寫入到臨時檔案中,在後續修復環境時需要讀取改檔案。
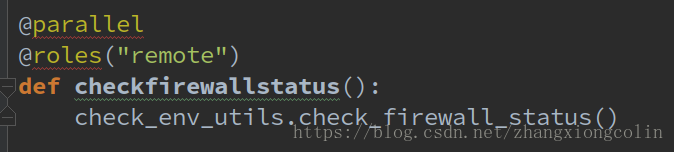
checkfirewallstatus()方法是利用Fabric的特性,在指定節點執行該方法。
@parallel :表示並行執行
@Roles("remote") : 表示在指定的角色上執行蓋方法,其中remote我們配置的所有機器的IP。
上述方法就表示在remote角色中配置的節點上並行執行該方法。
- 環境修復
我們還是接上面的關閉防火牆來說明環境修復的過程

首先判斷firewall是否在臨時檔案中,如果在則執行修復方法。
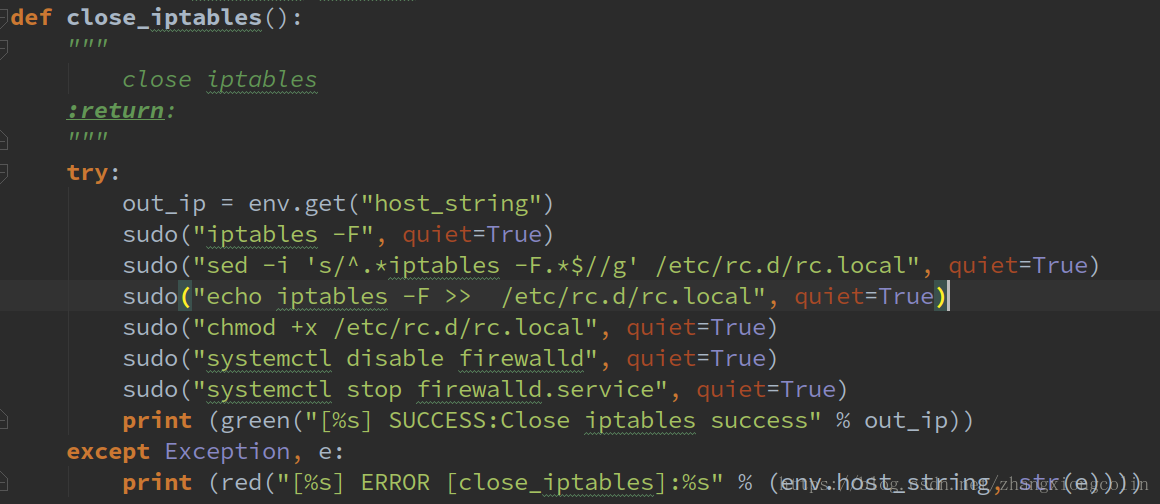
修復的過程也就是執行關閉防火牆的過程。
- 刪除Ambari 及安裝元件
刪除的場景
1. 徹底刪除Ambari及全部元件
2. 安裝失敗,某些節點安裝失敗,這時候需要刪除安裝失敗的,保留安裝成功的,我們在這稱為回滾(roll-back)
刪除Ambari Server

回滾刪除,只刪除server,已安裝成功的節點不進行刪除
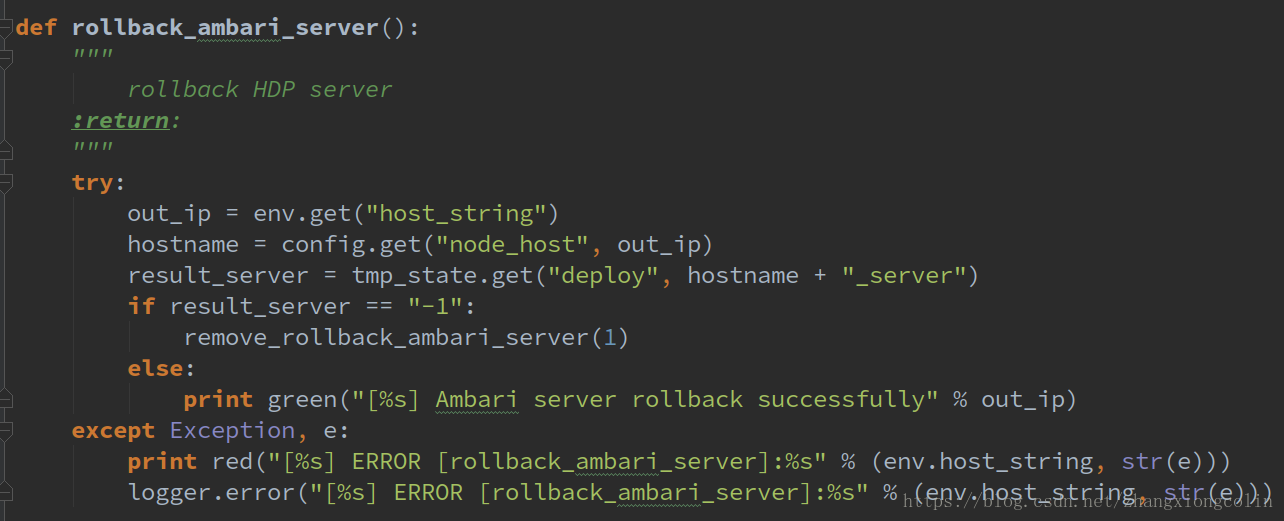
刪除元件及使用者資訊

整體執行演示截圖:

1. 環境檢查,發現防火牆未關閉
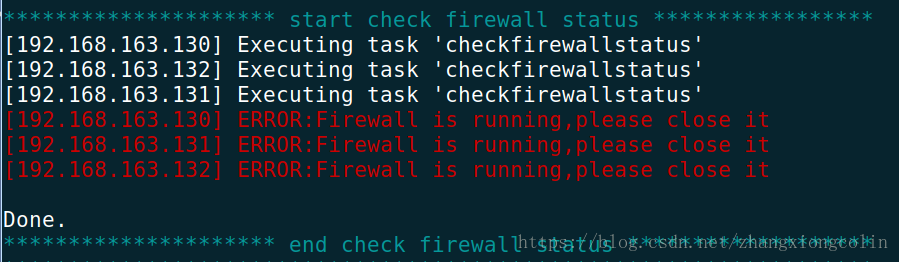
2. 修復環境

3.重新檢查
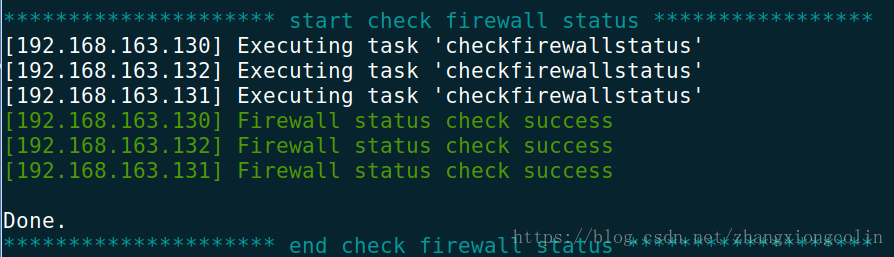
4.安裝Ambari
5. 安裝過程
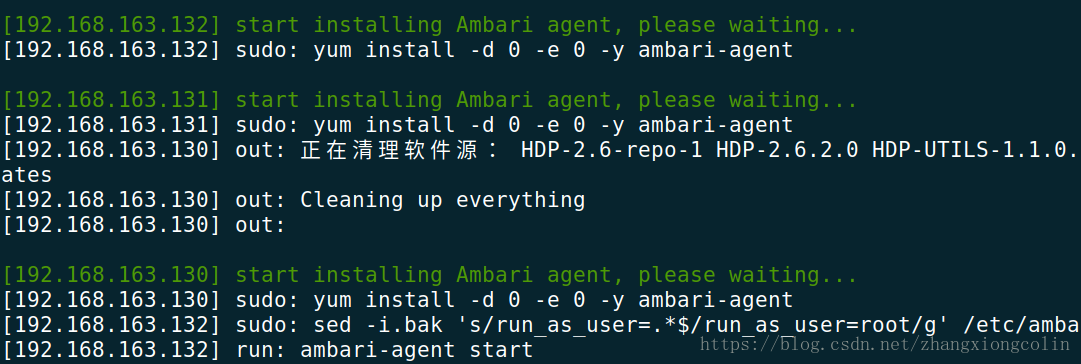
6. 安裝完成
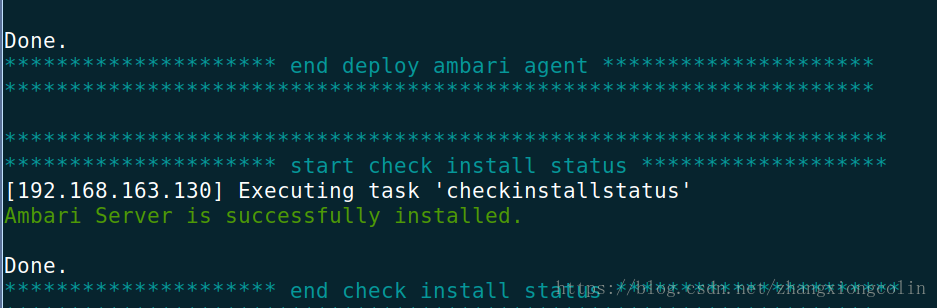
7. 訪問http://bigdata001:8080 進行驗證,安裝元件
8. 解除安裝Ambari Server和Agent
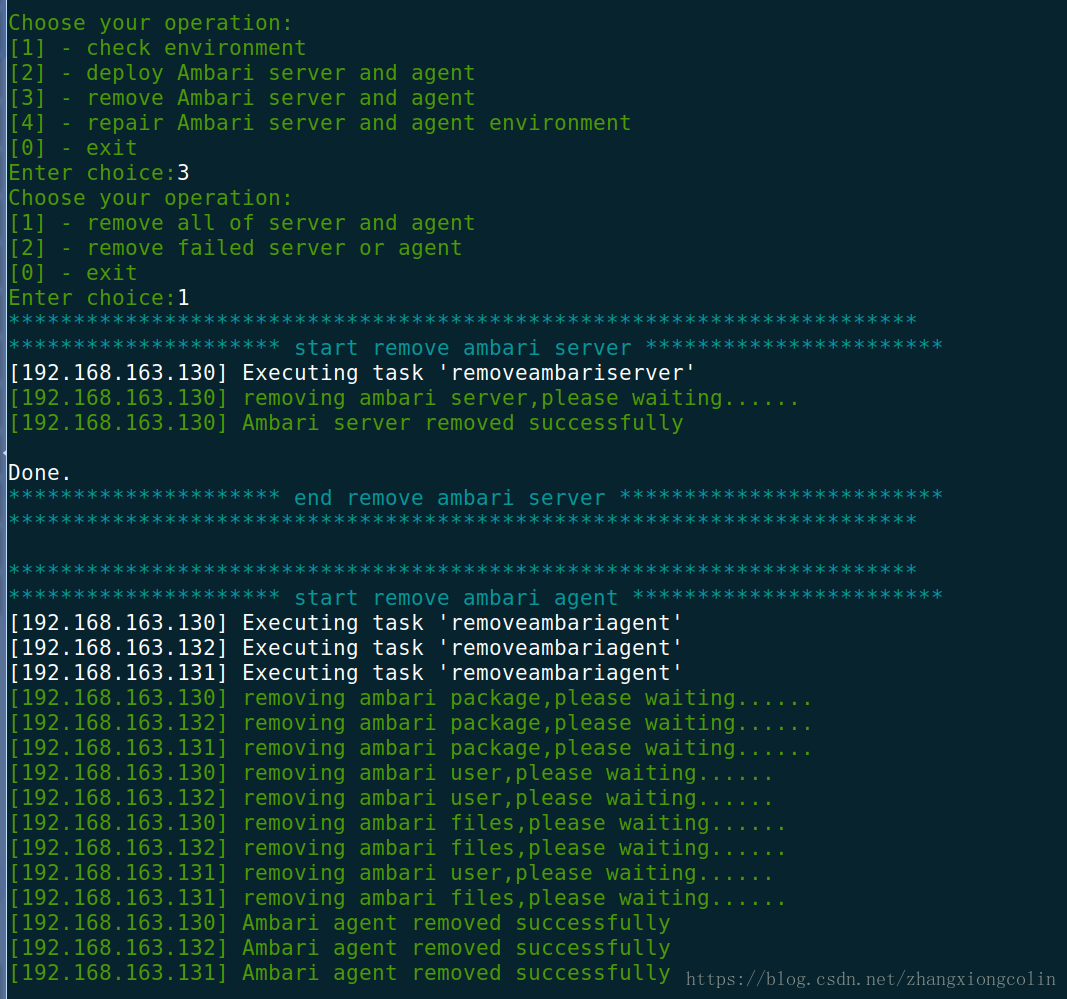
以上就是Ambari一鍵自動化部署指令碼的思路和演示,下一篇我們將對Ambari的原始碼結構進行說明。
掃描二維碼,關注BearData

相關推薦
003-Ambari一鍵自動化部署指令碼
微信搜尋公眾號:BearData,關注更多內容。 根據前兩篇 “Ambari大資料平臺搭建利器(一)&(二)”, 我們已經完成大資料平臺的搭建,但是我們發現安裝Ambari的步驟比較繁瑣。我們發現手動部署存在以下的劣勢: 每個節點都要執行重複的命令,我們前
一鍵自動化部署web架構
一鍵自動化 lnmp lamp 自動化安裝 逗哥自動化 一鍵自動化部署web架構 (LNMP LAMP 等github見底部) 一、前言 要實現自動化,首先要是文檔化---標準化--流程化--自動化,環境的統一是最低標準,所以我們平臺系統環境全部來源於1個腳本,這樣就可以自動化管理,減少企
SpringBoot + maven + Jenkins + docker 實現docker叢集一鍵自動化部署
整體可分為以下幾個步驟:1,建立springboot專案2,搭建docker私服庫3,build映象並上傳到私服庫4,搭建docker swarm叢集5,搭建jenkins並構建部署演示系統使用centos7,jdk1.81,建立Springboot專案:在eclipse上新
SaltStack一鍵自動化部署高可用負載均衡叢集
本節內容涉及的saltstack配置以及各服務的安裝包和配置檔案均打包上傳到了百度雲,可自由下載使用 實驗環境(rhel6.5 x86_64bit virtual machine) 172.25.5.91 salt-master rhel65-lockey1
Varnish的部署與使用例項(內附一鍵安裝部署指令碼github連結)
Varnish的部署與使用 指令碼及原始碼安裝包連結 概述 Varnish是一款高效能且開源的反向代理伺服器和http加速器 與傳統的Squid相比,Varnish具有效能更高,速度更快,管理更方便等諸多優點。 編譯安裝 這裡展
jenkins+svn+rsync+php_一鍵自動化部署可持續化整合伺服器叢集專案_支援回滾
此文的方案支援回滾,支援回滾,支援回滾,重要的事情說三遍!前言:此文的解決方案,只能解決釋放運維一半的工作量,為何一半?因為需要部署程式碼的伺服器叢集,都事先安裝配置好專案執行所需的環境,例如java專案需要tomcat,php專案需要nginx+php-fpm等。如果問有沒
Linux:自動化部署指令碼,給每一臺主機裝上JDK,且配好環境變數
centos6.7 當我們有很多臺主機,想在每臺機器上都安裝一樣的某些軟體,當然,一臺機器一臺機器安裝也是可以的,但是如果有一鍵安裝所有機器上的軟體那是不是很激動人心呢! 首先我們需要製作一臺伺服器,並把軟體包放在我們的伺服器上 首先進入 /var/www/html資料夾
用Ambari一鍵部署大資料平臺
安裝前準備先明確幾個概念: 1. Ambari只能安裝Hortonworks Data Platform,即Hortonworks的開源Hadoop,不支援Apach的Hadoop平臺; 2. 對於已經安裝了Apach Hadoop或者其他Hadoop平臺的,不能使用Amba
如何一鍵自動化期中50臺規模集群網站搭建
linux本文出自 “sandshell” 博客,請務必保留此出處http://sandshell.blog.51cto.com/9055959/1956938如何一鍵自動化期中50臺規模集群網站搭建
ansible一鍵批量部署nfs服務
nfs 一鍵安裝 批量一鍵安裝nfs服務#install nfs_server - hosts: 172.16.1.31 服務端 tasks: -name: installnfs-utils rpcbind yum: name=nfs-utils,rpcbind
rsync軟件服務利用ansible實現一鍵化部署
一鍵化部署首先創建一個腳本文件 /server/tools/peizhi.shcat /server/tools/peizhi.shcat >>/etc/rsyncd.conf<<EOF#luo##paichu.sh##uid = rsyncgid = rsyncuse chroot
rnfs軟件服務利用ansible實現一鍵化部署
一鍵化部署創建配置文件[[email protected] tools]# cat nfspeizhi.shcat >>/etc/exports<<EOF /data 172.16.1.0/24(rw,sync)EOF劇本:[[email pro
利用ansible實現一鍵化部署 rsync服務
linux創建腳本cat /server/scripts/rsyncd.conf.sh修改rsync配置文件cat >>/etc/rsyncd.conf<<EOFuid = rsyncgid = rsyncuse chroot = nomax connections = 200tim
利用ansible一鍵化部署nfs&rsync並實時同步
linux管理端 :[root@m01 tools]# cat quanwang.sh#!/bin/bashsh /server/scripts/piliangceshimiyao.shansible-playbook /server/tools/rsyncpiliang.ymlansible-playboo
centos7 OpenStack 一鍵自動部署
var one tar img tmp ima dmi kconfig ntp 1、[root@localhost ~]# systemctl stop NetworkManager [root@localhost ~]# systemctl enable Netw
Linux環境一鍵自動化安裝oracle軟件的構想(附shell腳本)
don 服務器 ons redhat7 cif tex entos sdi class 一、自動化批量安裝ORACLE軟件的構想1、1構想從哪裏來?熟悉PXE+KICKSTART一鍵批量安裝Liunx操作系統的童鞋都知道,該方式可實現快速定制,規範化,自動化的無人值守安裝。
一鍵化部署rsync和nfs服務,掛載web服務器到nfs,實現共享目錄和備份
sts backup 批量 1.7 ict util local install user 使用ansible服務,實現批量管理第一步,先分發公鑰,實現ansible無密碼進行控制#!/bin/bash #mk key 2rm -f /root/.ssh/id*ssh-ke
一鍵配置ssr指令碼備用地址
///Server yum -y install wget wget -N --no-check-certificate https://raw.githubusercontent.com/ToyoDAdoubi/doubi/master/ssr.sh && chmod ?
MYSQL一鍵安裝的指令碼
系統環境:CENTOS7 MYSQL:mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz MYSQL的安裝包的路徑:/shared/app/mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz [[email p
kafka一鍵啟動/停止指令碼
kafka 版本 kafka_2.11-0.10.2.1 因為kafka沒有批量啟動指令碼,每次都需要在各個broker節點上啟動kafka服務。比較麻煩。 這裡自定義一個kafka啟動的指令碼: #!/bin/bash BROKERS=