
索引長度與區分度
1: 索引長度直接影響索引檔案的大小,影響增刪改的速度,並間接影響查詢速度(佔用記憶體多).
針對列中的值,從左往右擷取部分,來建索引
1: 截的越短, 重複度越高,區分度越小, 索引效果越不好
2: 截的越長, 重複度越低,區分度越高, 索引效果越好,但帶來的影響也越大--增刪改變慢,並間影響查詢速度.
所以, 要在 區分度 + 長度 兩者上,取得一個平衡.
慣用手法: 擷取不同長度,並測試其區分度,
<span style="font-size:18px;">select count(distinct left(word,6))/count(*) from dict; +---------------------------------------+ | count(distinct left(word,6))/count(*) | +---------------------------------------+ | 0.9992 | +---------------------------------------+</span>
擷取word欄位長度,從1開始擷取,計算字元字首沒有重複的字元佔全部資料的比例
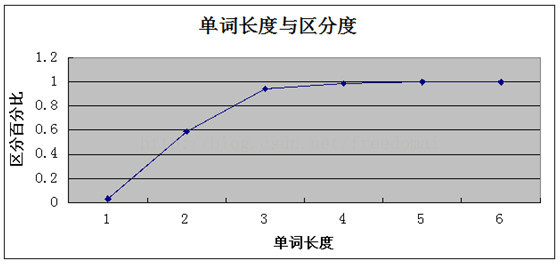
對於一般的系統應用: 區別度能達到0.1,索引的效能就可以接受.
3:多列索引
3.1 多列索引的考慮因素---
列的查詢頻率 , 列的區分度,
以ecshop商城為例, goods表中的cat_id,brand_id,做多列索引
從區分度看,Brand_id區分度更高,
select count(distinct cat_id) / count(*) from goods; +-----------------------------------+ | count(distinct cat_id) / count(*) | +-----------------------------------+ | 0.2903 | +-----------------------------------+ 1 row in set (0.00 sec) mysql> select count(distinct brand_id) / count(*) from goods; +-------------------------------------+ | count(distinct brand_id) / count(*) | +-------------------------------------+ | 0.3871 | +-------------------------------------+ 1 row in set (0.00 sec)
但從 商城的實際業務業務看, 顧客一般先選大分類->小分類->品牌,
最終選擇 index(cat_id,brand_id)來建立索引
有如下表(innodb引擎), sql語句在筆記中,
給定日照市,查詢子地區, 且查詢子地區的功能非常頻繁,
如何優化索引及語句?
+------+-----------+------+
| id | name | pid |
+------+-----------+------+
| .... | .... | .... |
| 1584 | 日照市 | 1476 |
| 1586 | 東港區 | 1584 |
| 1587 | 五蓮縣 | 1584 |
| 1588 | 莒縣 | 1584 |
+------+-----------+------+
1: 不加任何索引,自身連線查詢
explain select s.id,s.name from it_area as p inner join it_area as s on p.id=s.pid where p.name='日照市' \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: p
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 3263
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: s
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 3263
Extra: Using where; Using join buffer
2 rows in set (0.00 sec)2: 給name加索引
explain select s.id,s.name from it_area as p inner join it_area as s on p.id=s.pid where p.name='日照市' \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: p
type: ref
possible_keys: name
key: name
key_len: 93
ref: const
rows: 1
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: s
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 3243
Extra: Using where; Using join buffer
2 rows in set (0.00 sec)3: 在Pid上也加索引
explain select s.id,s.name from it_area as p inner join it_area as s on p.id=s.pid where p.name='日照市' \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: p
type: ref
possible_keys: name
key: name
key_len: 93
ref: const
rows: 1
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: s
type: ref
possible_keys: pid
key: pid
key_len: 5
ref: big_data.p.id
rows: 4
Extra: Using where
2 rows in set (0.00 sec)相關推薦
索引長度與區分度
1:查詢頻繁 2:區分度高 3:長度小 4: 儘量能覆蓋常用查詢欄位. 1: 索引長度直接影響索引檔案的大小,影響增刪改的速度,並間接影響查詢速度(佔用記憶體多). 針對列中的值,從左往右擷取部分,來建索引 1: 截的越短, 重複度越高,區分度越小, 索引效果越不好 2
mysql 索引長度和區分度
一點 分享 分析 blog 是不是 程序 觀察 name test 首先 索引長度和區分度是相互矛盾的, 索引長度太短,那麽區分度就很低,吧索引長度加長,區分度就高,但是索引也是要占內存的,所以我們需要找到一個平衡點; 那麽這個平衡點怎麽來定? 比如用戶表有個
(轉) SolrCloud之分布式索引及與Zookeeper的集成
閾值 leader選舉 較高的 配置 配置信息 tail ots 便是 recovery http://blog.csdn.net/ebay/article/details/46549481 作者:Wang, Josh 一、概述 Lucene是一個Java語言
java String長度與varchar長度匹配理解(字符和字節長度理解)
轉化 筆記 指定 是我 有一個 ati 法語 itl 情況 java String長度與varchar長度匹配理解(字符和字節長度理解) string中的length()長度,返回的是char的數量,每個char可以存儲世界上任何類型的文字和字符,一個char 而
【物聯網雲端對接-4】通過MQTT協議與百度雲進行雲端通信
src 發布 訂閱 操作 websocket 編寫 通用 頁面 開發 百度雲的天工物聯網服務目前包括:物接入、物解析、物管理、時序數據庫和規則引擎等5大部分,本篇文章僅介紹物接入。 天工物聯網的物接入,從開發者的角度來說相對有些復雜,需要多步操作才能實現一個雲設備的創建,
perl數組的長度與元素個數
元素 filter 等於 rar lte 數組下標 ++ print -1 perl數組的長度與元素個數 $#數組名 ---表示數組中最後一個元素的下標,它等於元素個數減1。 @數組名 ---表示數組中元素的個數。 $標量[email protected]數組名
mysql:索引原理與慢查詢優化
一個 mark index out 般的 test output 都是 records 一 介紹 二 索引的原理 三 索引的數據結構 三 MySQL索引管理 四 測試索引 五 正確使用索引 六 查詢優化神器-explain 七 慢查詢優化的基本步驟 八 慢日誌管理 九 參
A/B測試與灰度發布
目的 目標 交互 交付 場景 範圍 識別 需要 積累 1、A/B測試與灰度發布的理論 產品是多維度的,設計體驗、交互體驗、系統質量、運營支持等等, 測試的目的是為了系統最終的交付,一套各方面都足夠好的系統,而不是文檔上定義的系統,系統是需要不斷進化的。 測試的質疑貫穿產品的
Oracle JDBC:驅動版本區別與區分 [轉]
關閉數據庫 使用 windows bsp 需要 多個 批量 version truct classes12.jar,ojdbc14.jar,ojdbc5.jar和ojdbc6.jar的區別,之間的差異 在使用Oracle JDBC驅動時,有些問題你是不是通過替
二分索引樹與線段樹分析
比較 如果 -s 存儲 當我 帶來 執行 dex n-1 二分索引樹是一種樹狀數組,其全名為Binary Indexed Tree。二分索引樹可以用作統計作用,用於計某段連續區間中的總和,並且允許我們動態變更區間中存儲的值。二分索引樹和線段樹非常相似,二者都享有相同的O
Linux進程核心調度器之主調度器schedule--Linux進程的管理與調度(十九)【轉】
debug and spin block void 進程調度 2.6 standard 出錯 轉自:http://blog.csdn.net/gatieme/article/details/51872594 日期內核版本架構作者GitHubCSDN
MySQL數據庫學習【第九篇】索引原理與慢查詢優化
xxx 結構 復合 unix select查詢 全文搜索 等等 學習 獲取數據 一、介紹 1.什麽是索引? 一般的應用系統,讀寫比例在10:1左右,而且插入操作和一般的更新操作很少出現性能問題,在生產環境中,我們遇到最多的,也是最容易出問題的,還是一些復雜的查詢操作,因此對
MySQL 之 索引原理與慢查詢優化
英文 borde 發生 聚集 引擎 返回 位置 時間 pro 一 索引介紹 二 索引類型 三 索引分類 四 聚合索引和輔助索引 五 測試索引 六 正確使用索引 七 組合索引 八 註意事項 九 查詢計劃 十 慢日誌查詢 十一 大數據量分頁優化 1. 索引介紹
自己寫的加密網頁,與百度網盤私密很相似,需要密碼才能訪問(原創)
audio 查詢 數字 code 頁面 time AR 開發 其他 題記: 馬上就要招聘了,所以我打算放置簡歷在自己的網頁上,但是又不想給除了招聘的人,或者我指定的人外看,所以我需要對網頁頁面加密 我找了許多資料,查看了許多所謂的頁面加密,但是有60%左右都是網頁鎖,
mysql數據庫索引優化與實踐(一)
都是 分鐘 必備 範圍查詢 無法使用 RM strong span 實踐 前言 mysql數據庫是現在應用最廣泛的數據庫系統。與數據庫打交道是每個Java程序員日常工作之一,索引優化是必備的技能之一。 為什麽要了解索引 真實案例 案例一:大學有段時間學習爬蟲,爬取了知乎30
Linux進程優先級的處理--Linux進程的管理與調度(二十二)
idle 實時進程調度 height 2.7 borde 等於 calc convert free 日期 內核版本號 架構 作者 GitHu
第一次作業:Linux 2.6.32的進程模型與調度器分析
範圍 喚醒 最大 被調用 test ini writeback uid endif 1.前言 本文分析的是Linux 2.6.32版的進程模型以及調度器分析。在線查看 源碼下載 本文主要討論以下幾個問題: 什麽是進程?進程是如何產生的?進程都有那些? 在操作系統中,
mysql五:索引原理與慢查詢優化
mysql索引原理與慢查詢優化一、介紹1、為何要有索引? 一般的應用系統,讀寫比例在10:1左右,而且插入操作和一般的更新操作很少出現性能問題,在生產環境中,我們遇到最多的,也是最容易出問題的,還是一些復雜的查詢操作,因此對查詢語句的優化顯然是重中之重。說起加速查詢,就不得不提到索引了。2、什麽是索引?
線程池與並行度
資源 start 創建 sta tel span nds sys 不同的 本節將展示線程池如何工作於大量的異步操作,以及它與創建大量單獨的線程的方式有和不同。 代碼Demo: using System;using System.Threading;using System.
字符串經過base64編碼後的長度與原字符串的長度是什麽關系呀?
關系 是什麽 ase 字符 nbsp nco 編碼 base64編碼 字符串 beforeEncode為Encode之前的字符串 那麽Encode後的字符串長度為: 1、如果beforeEncode.length()是3的整數倍,那麽長度為 (beforeEncode.l