
linux記憶體管理--程序在記憶體中的分佈
一、程序與記憶體
所有程序(執行的程式)都必須佔用一定數量的記憶體,它或是用來存放從磁碟載入的程式程式碼,或是存放取自使用者輸入的資料等等。不過程序對這些記憶體的管理方式因記憶體用途不一而不盡相同,有些記憶體是事先靜態分配和統一回收的,而有些卻是按需要動態分配和回收的。對任何一個普通程序來講,它都會涉及到5種不同的資料段;
-
程式碼段:程式碼段是用來存放可執行檔案的操作指令,也就是說是它是可執行程式在記憶體中的映象。程式碼段需要防止在執行時被非法修改,所以只准許讀取操作,而不允許寫入(修改)操作——它是不可寫的。
-
資料段:資料段用來存放可執行檔案中已初始化全域性變數,換句話說就是存放程式靜態分配的變數和全域性變數。
-
BSS段:BSS段包含了程式中未初始化的全域性變數,在記憶體中 bss段全部置零。
-
堆(heap):堆是用於存放程序執行中被動態分配的記憶體段,它的大小並不固定,可動態擴張或縮減。當程序呼叫malloc等函式分配記憶體時,新分配的記憶體就被動態新增到堆上(堆被擴張);當利用free等函式釋放記憶體時,被釋放的記憶體從堆中被剔除(堆被縮減)
-
棧:棧是使用者存放程式臨時建立的區域性變數,也就是說我們函式括弧“{}”中定義的變數(但不包括static宣告的變數,static意味著在資料段中存放變數)。除此以外,在函式被呼叫時,其引數也會被壓入發起呼叫的程序棧中,並且待到呼叫結束後,函式的返回值也會被存放回棧中。由於棧的先進先出特點,所以棧特別方便用來儲存/恢復呼叫現場。從這個意義上講,我們可以把堆疊看成一個寄存、交換臨時資料的記憶體區。
上述幾種記憶體區域中資料段、BSS和堆通常是被連續儲存的——記憶體位置上是連續的,而程式碼段和棧往往會被獨立存放。有趣的是,堆和棧兩個區域關係很“曖昧”,他們一個向下“長”(i386體系結構中棧向下、堆向上),一個向上“長”,相對而生。但你不必擔心他們會碰頭,因為他們之間間隔很大(到底大到多少,你可以從下面的例子程式計算一下),絕少有機會能碰到一起。
- #include<stdio.h>
- #include<malloc.h>
- #include<unistd.h>
- int bss_var;
- int data_var0=1;
-
int main(int argc,char **argv)
- {
- printf("below are addresses of types of process's mem\n");
- printf("Text location:\n");
- printf("\tAddress of main(Code Segment):%p\n",main);
- printf("____________________________\n");
- int stack_var0=2;
- printf("Stack Location:\n");
- printf("\tInitial end of stack:%p\n",&stack_var0);
- int stack_var1=3;
- printf("\tnew end of stack:%p\n",&stack_var1);
- printf("____________________________\n");
- printf("Data Location:\n");
- printf("\tAddress of data_var(Data Segment):%p\n",&data_var0);
- staticint data_var1=4;
- printf("\tNew end of data_var(Data Segment):%p\n",&data_var1);
- printf("____________________________\n");
- printf("BSS Location:\n");
- printf("\tAddress of bss_var:%p\n",&bss_var);
- printf("____________________________\n");
- char *b = sbrk((ptrdiff_t)0);
- printf("Heap Location:\n");
- printf("\tInitial end of heap:%p\n",b);
- brk(b+4);
- b=sbrk((ptrdiff_t)0);
- printf("\tNew end of heap:%p\n",b);
- return 0;
- }
它的結果如下
below are addresses of types of process's mem
Text location:
Address of main(Code Segment):0x8048388
____________________________
Stack Location:
Initial end of stack:0xbffffab4
new end of stack:0xbffffab0
____________________________
Data Location:
Address of data_var(Data Segment):0x8049758
New end of data_var(Data Segment):0x804975c
____________________________
BSS Location:
Address of bss_var:0x8049864
____________________________
Heap Location:
Initial end of heap:0x8049868
New end of heap:0x804986c
利用size命令也可以看到程式的各段大小,比如執行size example會得到
text data bss dechex filename
1654 280 8 1942 796 example
但這些資料是程式編譯的靜態統計,而上面顯示的是程序執行時的動態值,但兩者是對應的。
從使用者向核心看,所使用的記憶體表象形式會依次經歷“邏輯地址”——“線性地址”——“實體地址”幾種形式(關於這三者的解釋)
邏輯地址經段機制轉化成線性地址;線性地址又經過頁機制轉化為實體地址。(但是我們要知道Linux系統雖然保留了段機制,但是將所有程式的段地址都定死為0-4G,所以雖然邏輯地址和線性地址是兩種不同的地址空間,但在linux中邏輯地址就等於線性地址,它們的值是一樣的)
二、虛擬記憶體空間
Linux作業系統採用虛擬記憶體管理技術,使得每個程序都有各自互不干涉的程序地址空間。該空間是塊大小為4G的線性虛擬空間,使用者所看到和接觸到的都是該虛擬地址,無法看到實際的實體記憶體地址。利用這種虛擬地址不但能起到保護作業系統的效果(使用者不能直接訪問實體記憶體),而且更重要的是,使用者程式可使用比實際實體記憶體更大的地址空間(具體的原因請看硬體基礎部分)。
在討論程序空間細節前,這裡先要澄清下面幾個問題:
- 第一、4G的程序地址空間被人為的分為兩個部分——使用者空間與核心空間。使用者空間從0到3G(0xC0000000),核心空間佔據3G到4G。使用者程序通常情況下只能訪問使用者空間的虛擬地址,不能訪問核心空間虛擬地址。只有使用者程序進行系統呼叫(代表使用者程序在核心態執行)等時刻可以訪問到核心空間。
- 第二、使用者空間對應程序,所以每當程序切換,使用者空間就會跟著變化;而核心空間是由核心負責對映,它並不會跟著程序改變,是固定的。核心空間地址有自己對應的頁表(init_mm.pgd),使用者程序各自有不同的頁表。
- 第三、每個程序的使用者空間都是完全獨立、互不相干的。不信的話,你可以把上面的程式同時執行10次(當然為了同時執行,讓它們在返回前一同睡眠100秒吧),你會看到10個程序佔用的線性地址一模一樣。
程序記憶體管理的物件是程序線性地址空間上的記憶體映象,這些記憶體映象其實就是程序使用的虛擬記憶體區域(memory region)。程序虛擬空間是個32或64位的“平坦”(獨立的連續區間)地址空間(空間的具體大小取決於體系結構)。要統一管理這麼大的平坦空間可絕非易事,為了方便管理,虛擬空間被劃分為許多大小可變的(但必須是4096的倍數)記憶體區域,這些區域在程序線性地址中像停車位一樣有序排列。這些區域的劃分原則是“將訪問屬性一致的地址空間存放在一起”,所謂訪問屬性在這裡無非指的是“可讀、可寫、可執行等”。
如果你要檢視某個程序佔用的記憶體區域,可以使用命令cat /proc/<pid>/maps獲得(pid是程序號,你可以執行上面我們給出的例子——./example &;pid便會列印到螢幕),你可以發現很多類似於下面的數字資訊。
由於程式example使用了動態庫,所以除了example本身使用的的記憶體區域外,還會包含那些動態庫使用的記憶體區域(區域順序是:程式碼段、資料段、bss段)。
我們下面只抽出和example有關的資訊,除了前兩行代表的程式碼段和資料段外,最後一行是程序使用的棧空間。
-------------------------------------------------------------------------------
08048000 - 08049000 r-xp 00000000 03:03 439029 /home/mm/src/example
08049000 - 0804a000 rw-p00000000 03:03 439029 /home/mm/src/example
……………
bfffe000 - c0000000 rwxpffff000 00:00 0
----------------------------------------------------------------------------------------------------------------------
每行資料格式如下:
(記憶體區域)開始-結束 訪問許可權 偏移 主裝置號:次裝置號 i節點 檔案。
注意,你一定會發現程序空間只包含三個記憶體區域,似乎沒有上面所提到的堆、bss等,其實並非如此,程式記憶體段和程序地址空間中的記憶體區域是種模糊對應,也就是說,堆、bss、資料段(初始化過的)都在程序空間中由資料段記憶體區域表示。
在Linux核心中對應程序記憶體區域的資料結構是: vm_area_struct, 核心將每個記憶體區域作為一個單獨的記憶體物件管理,相應的操作也都一致。採用面向物件方法使VMA結構體可以代表多種型別的記憶體區域--比如記憶體對映檔案或程序的使用者空間棧等,對這些區域的操作也都不盡相同。
vm_area_strcut結構比較複雜,關於它的詳細結構請參閱相關資料。我們這裡只對它的組織方法做一點補充說明。vm_area_struct是描述程序地址空間的基本管理單元,對於一個程序來說往往需要多個記憶體區域來描述它的虛擬空間,如何關聯這些不同的記憶體區域呢?大家可能都會想到使用連結串列,的確vm_area_struct結構確實是以連結串列形式連結,不過為了方便查詢,核心又以紅黑樹(以前的核心使用平衡樹)的形式組織記憶體區域,以便降低搜尋耗時。並存的兩種組織形式,並非冗餘:連結串列用於需要遍歷全部節點的時候用,而紅黑樹適用於在地址空間中定位特定記憶體區域的時候。核心為了記憶體區域上的各種不同操作都能獲得高效能,所以同時使用了這兩種資料結構。
下圖反映了程序地址空間的管理模型:

三、系統實體記憶體管理
1)實體記憶體管理
Linux核心管理實體記憶體是通過分頁機制實現的,它將整個記憶體劃分成無數個4k(在i386體系結構中)大小的頁,從而分配和回收記憶體的基本單位便是記憶體頁了。利用分頁管理有助於靈活分配記憶體地址,因為分配時不必要求必須有大塊的連續記憶體,系統可以東一頁、西一頁的湊出所需要的記憶體供程序使用。雖然如此,但是實際上系統使用記憶體時還是傾向於分配連續的記憶體塊,因為分配連續記憶體時,頁表不需要更改,因此能降低TLB的重新整理率(頻繁重新整理會在很大程度上降低訪問速度)。
鑑於上述需求,核心分配物理頁面時為了儘量減少不連續情況,採用了“夥伴”關係來管理空閒頁面。夥伴關係分配演算法大家應該不陌生——幾乎所有作業系統方面的書都會提到,我們不去詳細說它了,如果不明白可以參看有關資料。這裡只需要大家明白Linux中空閒頁面的組織和管理利用了夥伴關係,因此空閒頁面分配時也需要遵循夥伴關係,最小單位只能是2的冪倍頁面大小。核心中分配空閒頁面的基本函式是get_free_page/get_free_pages,它們或是分配單頁或是分配指定的頁面(2、4、8…512頁)。
注意:get_free_page是在核心中分配記憶體,不同於malloc在使用者空間中分配,malloc利用堆動態分配,實際上是呼叫brk()系統呼叫,該呼叫的作用是擴大或縮小程序堆空間(它會修改程序的brk域)。如果現有的記憶體區域不夠容納堆空間,則會以頁面大小的倍數為單位,擴張或收縮對應的記憶體區域,但brk值並非以頁面大小為倍數修改,而是按實際請求修改。因此Malloc在使用者空間分配記憶體可以以位元組為單位分配,但核心在內部仍然會是以頁為單位分配的。
另外,需要提及的是,物理頁在系統中由頁結構struct page描述,系統中所有的頁面都儲存在陣列mem_map[]中,可以通過該陣列找到系統中的每一頁(空閒或非空閒)。而其中的空閒頁面則可由上述提到的以夥伴關係組織的空閒頁連結串列(free_area[MAX_ORDER])來索引。
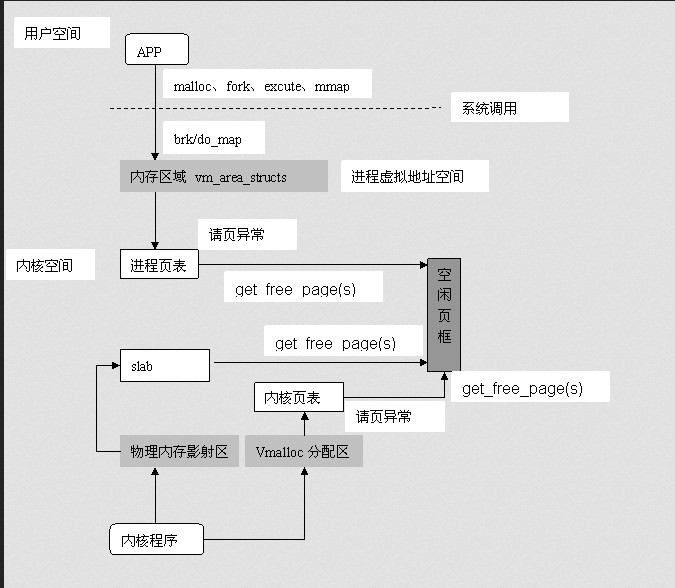
2)核心記憶體使用
- Slab
所謂尺有所長,寸有所短。以頁為最小單位分配記憶體對於核心管理系統中的實體記憶體來說的確比較方便,但核心自身最常使用的記憶體卻往往是很小(遠遠小於一頁)的記憶體塊——比如存放檔案描述符、程序描述符、虛擬記憶體區域描述符等行為所需的記憶體都不足一頁。這些用來存放描述符的記憶體相比頁面而言,就好比是麵包屑與麵包。一個整頁中可以聚集多個這些小塊記憶體;而且這些小塊記憶體塊也和麵包屑一樣頻繁地生成/銷燬。
為了滿足核心對這種小記憶體塊的需要,Linux系統採用了一種被稱為slab分配器的技術。Slab分配器的實現相當複雜,但原理不難,其核心思想就是“儲存池”的運用。記憶體片段(小塊記憶體)被看作物件,當被使用完後,並不直接釋放而是被快取到“儲存池”裡,留做下次使用,這無疑避免了頻繁建立與銷燬物件所帶來的額外負載。
Slab技術不但避免了記憶體內部分片(下文將解釋)帶來的不便(引入Slab分配器的主要目的是為了減少對夥伴系統分配演算法的呼叫次數——頻繁分配和回收必然會導致記憶體碎片——難以找到大塊連續的可用記憶體),而且可以很好地利用硬體快取提高訪問速度。
Slab並非是脫離夥伴關係而獨立存在的一種記憶體分配方式,slab仍然是建立在頁面基礎之上,換句話說,Slab將頁面(來自於夥伴關係管理的空閒頁面連結串列)撕碎成眾多小記憶體塊以供分配,slab中的物件分配和銷燬使用kmem_cache_alloc與kmem_cache_free。
- Kmalloc
Slab分配器不僅僅只用來存放核心專用的結構體,它還被用來處理核心對小塊記憶體的請求。當然鑑於Slab分配器的特點,一般來說核心程式中對小於一頁的小塊記憶體的請求才通過Slab分配器提供的介面Kmalloc來完成(雖然它可分配32 到131072位元組的記憶體)。從核心記憶體分配的角度來講,kmalloc可被看成是get_free_page(s)的一個有效補充,記憶體分配粒度更靈活了。
有興趣的話,可以到/proc/slabinfo中找到核心執行現場使用的各種slab資訊統計,其中你會看到系統中所有slab的使用資訊。從資訊中可以看到系統中除了專用結構體使用的slab外,還存在大量為Kmalloc而準備的Slab(其中有些為dma準備的)。
- 核心非連續記憶體分配(Vmalloc)
所以避免外部分片的最終思路還是落到了如何利用不連續的記憶體塊組合成“看起來很大的記憶體塊”——這裡的情況很類似於使用者空間分配虛擬記憶體,記憶體邏輯上連續,其實對映到並不一定連續的實體記憶體上。Linux核心借用了這個技術,允許核心程式在核心地址空間中分配虛擬地址,同樣也利用頁表(核心頁表)將虛擬地址對映到分散的記憶體頁上。以此完美地解決了核心記憶體使用中的外部分片問題。核心提供vmalloc函式分配核心虛擬記憶體,該函式不同於kmalloc,它可以分配較Kmalloc大得多的記憶體空間(可遠大於128K,但必須是頁大小的倍數),但相比Kmalloc來說,Vmalloc需要對核心虛擬地址進行重對映,必須更新核心頁表,因此分配效率上要低一些(用空間換時間)
與使用者程序相似,核心也有一個名為init_mm的mm_strcut結構來描述核心地址空間,其中頁表項pdg=swapper_pg_dir包含了系統核心空間(3G-4G)的對映關係。因此vmalloc分配核心虛擬地址必須更新核心頁表,而kmalloc或get_free_page由於分配的連續記憶體,所以不需要更新核心頁表。
vmalloc分配的核心虛擬記憶體與kmalloc/get_free_page分配的核心虛擬記憶體位於不同的區間,不會重疊。因為核心虛擬空間被分割槽管理,各司其職。程序空間地址分佈從0到3G(其實是到PAGE_OFFSET, 在0x86中它等於0xC0000000),從3G到vmalloc_start這段地址是實體記憶體對映區域(該區域中包含了核心映象、物理頁面表mem_map等等)比如我使用的系統記憶體是64M(可以用free看到),那麼(3G——3G+64M)這片記憶體就應該對映到實體記憶體,而vmalloc_start位置應在3G+64M附近(說"附近"因為是在實體記憶體對映區與vmalloc_start期間還會存在一個8M大小的gap來防止躍界),vmalloc_end的位置接近4G(說"接近"是因為最後位置系統會保留一片128k大小的區域用於專用頁面對映,還有可能會有高階記憶體對映區,這些都是細節,這裡我們不做糾纏)。

上圖是記憶體分佈的模糊輪廓
由get_free_page或Kmalloc函式所分配的連續記憶體都陷於物理對映區域,所以它們返回的核心虛擬地址和實際實體地址僅僅是相差一個偏移量(PAGE_OFFSET),你可以很方便的將其轉化為實體記憶體地址,同時核心也提供了virt_to_phys()函式將核心虛擬空間中的物理對映區地址轉化為實體地址。要知道,實體記憶體對映區中的地址與核心頁表是有序對應的,系統中的每個物理頁面都可以找到它對應的核心虛擬地址(在實體記憶體對映區中的)。
而vmalloc分配的地址則限於vmalloc_start與vmalloc_end之間。每一塊vmalloc分配的核心虛擬記憶體都對應一個vm_struct結構體(可別和vm_area_struct搞混,那可是程序虛擬記憶體區域的結構),不同的核心虛擬地址被4k大小的空閒區間隔,以防止越界——見下圖)。與程序虛擬地址的特性一樣,這些虛擬地址與實體記憶體沒有簡單的位移關係,必須通過核心頁表才可轉換為實體地址或物理頁。它們有可能尚未被對映,在發生缺頁時才真正分配物理頁面。

這裡給出一個小程式幫助大家認清上面幾種分配函式所對應的區域。
- #include<linux/module.h>
- #include<linux/slab.h>
- #include<linux/vmalloc.h>
- unsigned char*pagemem;
- unsigned char*kmallocmem;
- unsigned char*vmallocmem;
- int init_module(void)
- {
- pagemem = get_free_page(0);
- printk("<1>pagemem=%s",pagemem);
- kmallocmem = kmalloc(100,0);
- printk("<1>kmallocmem=%s",kmallocmem);
- vmallocmem = vmalloc(1000000);
- printk("<1>vmallocmem=%s",vmallocmem);
- }
- void cleanup_module(void)
- {
- free_page(pagemem);
- kfree(kmallocmem);
- vfree(vmallocmem);
- }
相關推薦
linux記憶體管理--程序在記憶體中的分佈
一、程序與記憶體 所有程序(執行的程式)都必須佔用一定數量的記憶體,它或是用來存放從磁碟載入的程式程式碼,或是存放取自使用者輸入的資料等等。不過程序對這些記憶體的管理方式因記憶體用途不一而不盡相同,有些記憶體是事先靜態分配和統一回收的,而有些卻是按需要動態分配和回
Linux記憶體管理 (26)記憶體相關工具
1. vmstat 參照《Linux CPU佔用率監控工具小結-vmstat》 2. memstat memstat可以通過sudo apt install memstat安裝,安裝包括兩個檔案memstat和memstat.conf。 其中memstat.conf是memstat配置
C++之記憶體管理——在堆中申請100個char型別的記憶體,拷貝Hello world字串到分配的堆中的記憶體中,列印字串,最後釋放記憶體。
首先先看一下簡單的案例 程式碼如下 #include<iostream> using namespace std; int main() { //整數1 int *x = new int; if(NULL==x) { return 0;
Nginx學習之路(七)NginX中的記憶體管理之---Nginx中的記憶體池
上一篇文章說到了Nginx中的記憶體對齊機制和記憶體分頁機制,今天就來說下Nginx中的記憶體池,記憶體池是一個使用非常廣泛的技術,在web伺服器的高併發情況下可能存在平凡的malloc()和free()過程,通過記憶體池的方式可以將這一過程的開銷極大程度的減少,Nginx的
Nginx學習之路(六)NginX中的記憶體管理之---Nginx中的記憶體對齊和記憶體分頁
Nginx由於極高的效能受到大家的追捧,而Nginx的高效能與它優秀的記憶體管理方式是分不開的,今天就來聊一聊Nginx中的記憶體對齊和記憶體分頁。先說下Nginx中的記憶體對齊,Nginx中的記憶體對齊機制是它高效能的關鍵因素之一,先說點基礎的東西,什麼是記憶體對齊呢? 記
linux下檢視程序記憶體使用情況
動態檢視一個程序的記憶體使用 1、top命令 top -d 1 -p pid [,pid ...] //設定為delay 1s,預設是delay 3s 如果想根據記憶體使用量進行排序,可以shift + m(Sort by memory usage) 靜態檢視一個程序的記憶
LINUX檢查一個程序記憶體增長的指令碼
記憶體洩露很難查。 1、記憶體有沒有洩露? 2、記憶體在哪裡洩露? 為了解決第一個問題,吾絞盡腦汁,寫了一個指令碼,檢查特定程式的記憶體增長。即只要增長就會輸出。分享出來供大家參考。 get_pid() { process_name=$1 text=`
linux 檢視各個程序記憶體使用情況 top 命令解釋
參考 :https://www.cnblogs.com/zhuiluoyu/p/6154898.html ps aux --sort -rss或者:https://www.cnblogs.com/sparkbj/p/6148817.htmllinux下獲取佔用CPU資源最多的
作業系統--記憶體學習筆記(2)程序記憶體管理--虛擬記憶體
虛擬記憶體(virtual memory) = CPU + MMU(Memory Management Unit), MMU是一個CPU上的元器件,它將實體地址對映為虛擬地址,這樣CPU可以之別虛擬地址,而不是實際實體地址了。使用MMU的好處有 1、同一個虛擬地址可以指向不
【原始碼】記憶體管理--得記憶體者得天下
程序和記憶體管理堪稱核心的任督二脈,是最重要的兩部分,這兩部弄清楚了,主體架構也就確立,其它都是支脈。而這兩者中,又數記憶體管理最難,所以,得記憶體者得天下。 (一) 1.buddy(夥伴)機制。 以頁為單位的大記憶體。 2.slab機制。 管
記憶體管理八 記憶體分配介面總結
一、簡介: 記憶體分配的介面有很多,不同的申請函式有不同的功能,下面會做詳細的介紹和對比。 kmalloc:基於slab分配器,用於分配小記憶體,物理空間連續的記憶體塊; vmalloc:用於分配大記憶體,虛擬地址連續的記憶體; malloc:為使用者空間分配程序地
記憶體管理四 記憶體洩漏檢測kmemleak
一、簡介: Kmemleak工作於核心態,Kmemleak 提供了一種可選的核心洩漏檢測,其方法類似於跟蹤記憶體收集器。當獨立的物件沒有被釋放時,其報告記錄在 /sys/kernel/debug/kmemleak中,Kmemcheck能夠幫助定位大
【軟體開發底層知識修煉】三 深入淺出處理器之三 記憶體管理與記憶體管理單元(MMU)
上一篇文章學習了中斷的概念與意義,以及中斷的應用-斷點除錯原理。點選連結複習上一篇文章:中斷的概念與意義 本片文章繼續學習處理器相關的知識-記憶體管理。包括:記憶體管理單元MMU的作用,虛擬記憶體與實體記憶體之間的對映方式,頁表的概念,快取記憶體(Cache)的作用,實體記憶體與快取
Java記憶體管理之記憶體洩露是什麼?什麼情況下會導致記憶體洩露?
文章目錄 1. 靜態類的使用 2. 資源連線的使用 3. 監聽器的使用 雖然Java擁有垃圾回收機制,但同樣會出現記憶體洩露問題,我們說一下比較主要的三種情況。 1. 靜態類的使用 諸如 HashMap、Vector 等集
深入淺出記憶體管理--實體記憶體框架
NUMA 首先需要介紹一個NUMA的概念,非一致性記憶體訪問模型,在這種系統中,CPU訪問不同記憶體單元的時間可能是不一樣的,實體記憶體被劃分為不同的Node節點來進行管理,對於單CPU的系統也可能使用NUMA,因為這些系統的實體記憶體有可能不一定是整塊的,而是中間包含有很大的洞,因
深入淺出記憶體管理--高階記憶體對映之pkmap(永久對映)
我們知道系統中的高階記憶體是不能作為直接對映區對映到核心空間的,那麼我們想要使用它怎麼辦呢?前面的文章我們已經有過相關的介紹,可以使用三種方法,分別是pkmap(永久對映)/fixmap(臨時固定對映)/vmlloc,本文主要介紹pkmap,也就是永久對映。 入口函式 首先我們來
深入淺出記憶體管理--快取記憶體(cache memory)和轉換後援緩衝(TLB)
快取記憶體(Cache memory) CPU的執行速度時非常快的,當今的CPU主頻都是GHZ級別的,而對於記憶體DDR來說,每次存取操作都會耗用很多的時鐘週期,這意味著,CPU需要等待很長時間來完成一次讀或者寫操作。 為了縮小CPU和DDR兩者之間速度上的不匹配造成的等待問題,硬體
C++面試常見題目4_記憶體管理,記憶體洩露
記憶體管理 定義:記憶體管理是指軟體執行時對計算機記憶體資源的分配和使用的技術。其最主要的目的是如何高效,快速的分配,並且在適當的時候釋放和回收記憶體資源。 在C++中記憶體分為5個區,分別是堆、棧、自由儲存區、全域性/靜態儲存區和常量儲存區。 堆:堆是
malloc記憶體管理器記憶體不釋放的解決方法
最近在對程式測試時發現,程式在執行某項操作後記憶體有一部分不會釋放,但是,在多次執行後又不會繼續增加,執行緒數越多,多次執行同樣的操作,記憶體佔用還會增大。檢查程式碼,並沒有程式碼上的記憶體洩漏,甚是苦惱。 網上搜索發現是malloc的原因:
JVM記憶體管理之記憶體結構
JVM在執行java程式時,將他們劃分成幾種不同格式的資料,分別儲存在不同的區域,這些資料統一稱為執行時資料。主要分為以下6種儲存結構。 1、PC暫存器資料; 2、Java棧; 3、堆; 4、方法區; 5、本地方法區; 6、執行時常量; 一:PC暫存器