
Flume NG 學習筆記(五)Sinks和Channel配置
一、HDFS Sink
Flume Sink是將事件寫入到Hadoop分散式檔案系統(HDFS)中。主要是Flume在Hadoop環境中的應用,即Flume採集資料輸出到HDFS,適用大資料日誌場景。
目前,它支援HDFS的文字和序列檔案格式,以及支援兩個檔案型別的壓縮。支援將所用的時間、資料大小、事件的數量為操作引數,對HDFS檔案進行關閉(關閉當前檔案,並建立一個新的)。它還可以對事源的機器名(hostname)及時間屬性分離資料,即通過時間戳將資料分佈到對應的檔案路徑。 HDFS目錄路徑可能包含格式轉義序列用於取代由HDFS Sink生成一個目錄/檔名儲存的事件。
注意:Hadoop的版本需要支援sync()方法呼叫,當然首先得按照Hadoop。
下面是HDFS Sinks轉義符的支援目錄:
|
Alias |
Description |
|
%{host} |
Substitute value of event header named “host”. Arbitrary header names are supported. |
|
%t |
Unix time in milliseconds |
|
%a |
locale’s short weekday name (Mon, Tue, ...) |
|
%A |
locale’s full weekday name (Monday, Tuesday, ...) |
|
%b |
locale’s short month name (Jan, Feb, ...) |
|
%B |
locale’s long month name (January, February, ...) |
|
%c |
locale’s date and time (Thu Mar 3 23:05:25 2005) |
|
%d |
day of month (01) 每月中的第幾天 |
|
%D |
date; same as %m/%d/%y |
|
%H |
hour (00..23) |
|
%I |
hour (01..12) |
|
%j |
day of year (001..366) 一年中的第幾天 |
|
%k |
hour ( 0..23) |
|
%m |
month (01..12) |
|
%M |
minute (00..59) |
|
%p |
locale’s equivalent of am or pm |
|
%s |
seconds since 1970-01-01 00:00:00 UTC |
|
%S |
second (00..59) |
|
%y |
last two digits of year (00..99) 年的後兩位 |
|
%Y |
year (2010) |
|
%z |
+hhmm numeric timezone (for example, -0400) |
下面是官網給出的HDFS Sinks的配置,加粗的引數是必選,可選項十分豐富,這裡就不一一列出來了
|
Name |
Default |
Description |
|
channel |
– |
|
|
type |
– |
The component type name, needs to be hdfs |
|
hdfs.path |
– |
HDFS directory path (eg hdfs://namenode/flume/webdata/) |
|
hdfs.filePrefix |
FlumeData |
Name prefixed to files created by Flume in hdfs directory 檔案字首 |
|
hdfs.fileType |
SequenceFile |
File format: currently SequenceFile, DataStream or CompressedStream |
|
hdfs.useLocalTimeStamp |
false |
Use the local time (instead of the timestamp from the event header) while replacing the escape sequences. |
|
hdfs.codeC |
– |
Compression codec. one of following : gzip, bzip2, lzo, lzop, snappy |
|
hdfs.round |
false |
Should the timestamp be rounded down (if true, affects all time based escape sequences except %t) 定時間用 |
|
hdfs.roundValue |
1 |
Rounded down to the highest multiple of this (in the unit configured using hdfs.roundUnit), less than current time.(需要hdfs.round為true) |
|
hdfs.roundUnit |
second |
The unit of the round down value - second, minute or hour.(同上) |
下面是官網的例子,他的三個round*配置是將向下舍入到最後10分鐘的時間戳記錄。
假設現在是上午10時56分20秒等等,2014年10月24日的Flume Sinks的資料到輸出到HDFS的路徑為/flume/events/2014-10-24/1050/00的。。
a1.channels=c1
a1.sinks=k1
a1.sinks.k1.type=hdfs
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.path=/flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix=events-
a1.sinks.k1.hdfs.round=true
a1.sinks.k1.hdfs.roundValue=10
a1.sinks.k1.hdfs.roundUnit=minute
下面是實際的例子:
#配置檔案:hdfs_case9.conf
#Name the components on this agent
a1.sources= r1
a1.sinks= k1
a1.channels= c1
#Describe/configure the source
a1.sources.r1.type= syslogtcp
a1.sources.r1.bind= 192.168.233.128
a1.sources.r1.port= 50000
a1.sources.r1.channels= c1
#Describe the sink
a1.sinks.k1.type= hdfs
a1.sinks.k1.channel= c1
a1.sinks.k1.hdfs.path= hdfs://carl:9000/flume/
a1.sinks.k1.hdfs.filePrefix= carl
a1.sinks.k1.hdfs.round= true
a1.sinks.k1.hdfs.roundValue= 1
a1.sinks.k1.hdfs.roundUnit= minute
a1.sinks.k1.hdfs.fileType=DataStream
# Usea channel which buffers events in memory
a1.channels.c1.type= memory
a1.channels.c1.capacity= 1000
a1.channels.c1.transactionCapacity= 100這裡我們偷懶拷了上節TCP的例子,然後加入sinks為HDFS中。我們設定資料是放入在HDFS的目錄為hdfs://carl:9000/flume/,檔案字首為carl,其中這裡有個設定要說明下:a1.sinks.k1.hdfs.fileType=DataStream,因為檔案格式預設是 SequenceFile,如果直接開啟是亂碼,這個不方便演示,因此我們設定成普通資料格式。
#敲命令
flume-ng agent -cconf -f conf/hdfs_case9.conf -n a1 -Dflume.root.logger=INFO,console
啟動成功後
開啟另一個終端輸入,往偵聽埠送資料
echo "hello looklook7hello hdfs" | nc 192.168.233.128 50000
#在啟動的終端檢視console輸出
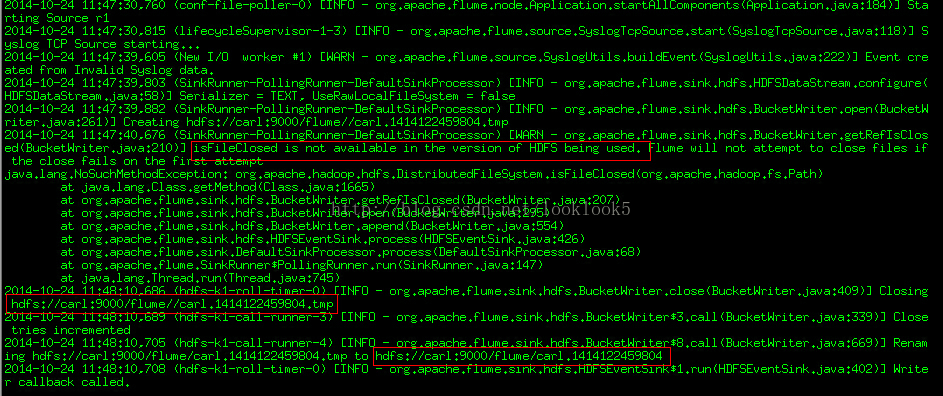
這裡可以看到他報了一個錯誤,說isfileclosed不可用。。。這個是這樣的,這邊的Hadoop是cdh3版本的,而flume ng 是說支援cdh4版本的,所以版本不匹配。不過這個無妨,下面看他們資料已經插入進去了,一開始生成一個hdfs://carl:9000/flume//carl.1414122459804.tmp,
然後資料進去了生成檔案hdfs://carl:9000/flume/carl.1414122459804
那我們看下資料檔案,hdfs://carl:9000/flume/carl.1414122459804
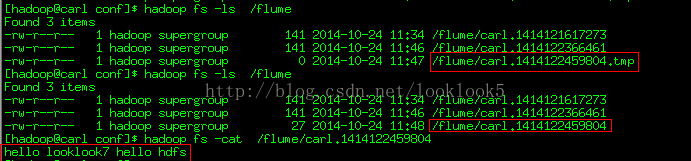
我們看到日誌檔案的生成過程,最後資料已經進去了。
然後我對配置檔案裡的這這個引數改下,參照官網的例子
a1.sinks.k1.hdfs.path= hdfs://carl:9000/flume/%y-%m-%d/%H%M/%S
然後加上這個引數
a1.sinks.k1.hdfs.useLocalTimeStamp=true
啟動
開啟另一個終端輸入,往偵聽埠送資料
echo "hello looklook7hello hdfs" | nc 192.168.233.128 50000
這裡如果不加上面的引數a1.sinks.k1.hdfs.useLocalTimeStamp=true,會需要向事件裡面明確header,否則會報錯,如下

資料成功傳送後,會生成資料檔案

資料目錄是/flume/14-10-24/1354/00
因為我們設的引數是1分鐘a1.sinks.k1.hdfs.roundValue= 1 這個與官網講的一致
二、Logger Sink
INFO級別的日誌事件。通常有用的測試/除錯目的。之前的測試裡有些,下面就不多贅述
下面是官網配置
|
Property Name |
Default |
Description |
|
channel |
– |
|
|
type |
– |
The component type name, needs to be logger |
三、Avro Sink
Avro Sink主要用於Flume分層結構。Flumeevent 傳送給這個sink的事件都會轉換成Avro事件,傳送到配置好的Avro主機和埠上。這些事件可以批量傳輸給通道。
下面是官網配置,加粗為必須,可選項太多就不一一列了
|
Property Name |
Default Description |
|
|
channel |
– |
|
|
type |
– |
The component type name, needs to be avro. |
|
hostname |
– |
The hostname or IP address to bind to. |
|
port |
– |
The port # to listen on. |
下面是官網例子
a1.channels=c1
a1.sinks=k1
a1.sinks.k1.type=avro
a1.sinks.k1.channel=c1
a1.sinks.k1.hostname=10.10.10.10
a1.sinks.k1.port=4545
因為Avro Sink主要用於Flume分層結構,那麼這邊都會想到我們學習心得(二)關於叢集配置的列子就是關於Avro Sink與Avro Source的一個例項,其中pull.cof是關於Avro Source的例子,而push.conf 是Avro Sink的例子,具體內容大家可以去第二節看,這裡不做贅述。
三、Avro Sink
Thrift也是用來支援Flume分層結構。Flumeevent 傳送給這個sink的事件都會轉換成Thrift事件,傳送到配置好的Thrift主機和埠上。這些事件可以批量傳輸給通道。和Avro Sink一模一樣。這邊也就略過了。
四、IRC Sink
IRC Sink 從通道中取得資訊到IRCServer,這個沒有IRC Server。。。無法測試,也略過吧。。。
五、File RollSink
儲存到本地儲存中。他有個滾動間隔的設定,設定多長時間去生成檔案(預設是30秒)。
下面是官網配置
|
Property Name |
Default |
Description |
|
channel |
– |
|
|
type |
– |
The component type name, needs to be file_roll. |
|
sink.directory |
– |
The directory where files will be stored |
|
sink.rollInterval |
30 |
Roll the file every 30 seconds. Specifying 0 will disable rolling and cause all events to be written to a single file. |
|
sink.serializer |
TEXT |
Other possible options include avro_event or the FQCN of an implementation of EventSerializer.Builder interface. |
|
batchSize |
100 |
接下去是官網例子
a1.channels=c1
a1.sinks=k1
a1.sinks.k1.type=file_roll
a1.sinks.k1.channel=c1
a1.sinks.k1.sink.directory=/var/log/flume
下面是測試例子:
#配置檔案:fileroll_case10.conf
#Name the components on this agent
a1.sources= r1
a1.sinks= k1
a1.channels= c1
#Describe/configure the source
a1.sources.r1.type= syslogtcp
a1.sources.r1.port= 50000
a1.sources.r1.host= 192.168.233.128
a1.sources.r1.channels= c1
#Describe the sink
a1.sinks.k1.type= file_roll
a1.sinks.k1.channel= c1
a1.sinks.k1.sink.directory= /tmp/logs
# Usea channel which buffers events in memory
a1.channels.c1.type= memory
a1.channels.c1.capacity= 1000
a1.channels.c1.transactionCapacity= 100#敲命令
flume-ng agent -cconf -f conf/fileroll_case10.conf -n a1 -Dflume.root.logger=INFO,console
啟動成功後
開啟另一個終端輸入,往偵聽埠送資料
echo "hello looklook5hello hdfs" | nc 192.168.233.128 50000
#在啟動的終端檢視console輸出
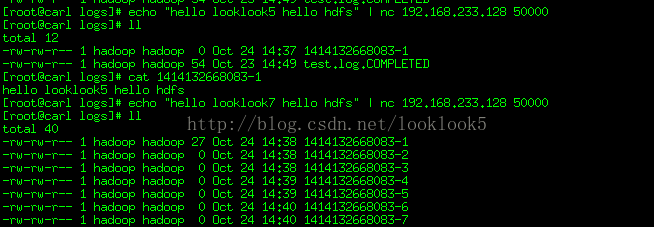
可以看到資料傳過來並生成檔案,然後無論是否有資料傳過來,都會每過30秒就會生成檔案。
六、Null Sink
丟棄從通道接收的所有事件。。。這邊就不測試了。。
下面是官網配置
|
Property Name |
Default |
Description |
|
channel |
– |
|
|
type |
– |
The component type name, needs to be null. |
|
batchSize |
100 |
下面是官網例子
a1.channels=c1
a1.sinks=k1
a1.sinks.k1.type=null
a1.sinks.k1.channel=c1
七、HBaseSinks與AsyncHBaseSink
HBaseSinks負責將資料寫入到Hbase中。Hbase的配置資訊從classpath路徑裡面遇到的第一個hbase-site.xml檔案中獲取。在配置檔案中指定的實現了HbaseEventSerializer 介面的類,用於將事件轉換成Hbase所表示的事件或者增量。然後將這些事件和增量寫入Hbase中。
Hbase Sink支援寫資料到安全的Hbase。為了將資料寫入安全的Hbase,使用者代理執行必須對配置的table表有寫許可權。主要用來驗證對KDC的金鑰表可以在配置中指定。在Flume Agent的classpath路徑下的Hbase-site.xml檔案必須設定到Kerberos認證。
注意有一定很重要,就是這個sinks 對格式的規範要求非常高。
至於 AsyncHBaseSink則是非同步的HBaseSinks。
這邊沒有HBase環境,因此也就不演示了。。
八、Custom Sink
一個自定義 Sinks其實是對Sinks介面的實現。當我們開始flume代理的時候必須將自定義Sinks和相依賴的jar包放到代理的classpath下面。自定義 Sinks的type就是我們實現Sinks介面對應的類全路徑。
這裡後面的內容裡會詳細介紹,這裡不做贅述。
九、MemoryChannel
Source通過通道新增事件,Sinks通過通道取事件。所以通道類似快取的存在。
Memory Channel是事件儲存在一個記憶體佇列中。速度快,吞吐量大。但會有代理出現故障後資料丟失的情況。
下面是官網配置
|
Property Name |
Default |
Description |
|
type |
– |
The component type name, needs to be memory |
|
capacity |
100 |
The maximum number of events stored in the channel |
|
transactionCapacity |
100 |
The maximum number of events the channel will take from a source or give to a sink per transaction |
|
keep-alive |
3 |
Timeout in seconds for adding or removing an event |
|
byteCapacityBufferPercentage |
20 |
Defines the percent of buffer between byteCapacity and the estimated total size of all events in the channel, to account for data in headers. See below. |
|
byteCapacity |
see description |
Maximum total bytes of memory allowed as a sum of all events in this channel. The implementation only counts the Event body, which is the reason for providing thebyteCapacityBufferPercentage configuration parameter as well. Defaults to a computed value equal to 80% of the maximum memory available to the JVM (i.e. 80% of the -Xmx value passed on the command line). Note that if you have multiple memory channels on a single JVM, and they happen to hold the same physical events (i.e. if you are using a replicating channel selector from a single source) then those event sizes may be double-counted for channel byteCapacity purposes. Setting this value to 0 will cause this value to fall back to a hard internal limit of about 200 GB. |
以及官網例子
a1.channels=c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=10000
a1.channels.c1.transactionCapacity=10000
a1.channels.c1.byteCapacityBufferPercentage=20
a1.channels.c1.byteCapacity=800000
之前的例子全部是Memory Channel。關於Channel的列子不好演示,後面就不會有例子了。
十、JDBCChannel
JDBC Channel是把事件儲存在資料庫。目前的JDBC Channel支援嵌入式Derby。主要是為了資料持久化,並且可恢復的特性。
|
Property Name |
Default |
Description |
|
type |
– |
The component type name, needs to be jdbc |
|
db.type |
DERBY |
Database vendor, needs to be DERBY. |
|
driver.class |
org.apache.derby.jdbc.EmbeddedDriver |
Class for vendor’s JDBC driver |
|
driver.url |
(constructed from other properties) |
JDBC connection URL |
|
db.username |
“sa” |
User id for db connection |
|
db.password |
– |
password for db connection |
下面是官網例子:
a1.channels=c1
a1.channels.c1.type=jdbc
十一、FileChannel
注意預設情況下,File Channel使用檢查點(checkpointDir)和在使用者目錄(dataDirs)上指定的資料目錄。所以在一個agent下面啟動多個File Channel例項,只會有一個File channel能鎖住檔案目錄,其他的都將初始化失敗。因此,有必要提供明確的路徑的所有已配置的通道,同時考慮最大吞吐率,檢查點與資料目錄最好是在不同的磁碟上。
|
Property Name Default |
Description |
|
|
type |
– |
The component type name, needs to be file. |
|
checkpointDir |
~/.flume/file-channel/checkpoint |
The directory where checkp |
|
dataDirs |
~/.flume/file-channel/data |
Comma separated list of directories for storing log files. Using multiple directories on separate disks can improve file channel peformance |
下面是官網例子
a1.channels=c1
a1.channels.c1.type=file
a1.channels.c1.checkpointDir=/mnt/flume/checkpoint
a1.channels.c1.dataDirs=/mnt/flume/data
File Channel 加密官網也給出了相應的配置
Generating a key with a password seperate from the key store password:
keytool -genseckey -alias key-0 -keypasskeyPassword -keyalg AES\
-keysize 128 -validity 9000 -keystore test.keystore\
-storetype jceks -storepass keyStorePassword
Generating a key with the password the same as the key store password:
keytool -genseckey -alias key-1 -keyalgAES -keysize 128 -validity 9000\
-keystore src/test/resources/test.keystore -storetype jceks\
-storepass keyStorePassword
a1.channels.c1.encryption.activeKey=key-0
a1.channels.c1.encryption.cipherProvider=AESCTRNOPADDING
a1.channels.c1.encryption.keyProvider=key-provider-0
a1.channels.c1.encryption.keyProvider=JCEKSFILE
a1.channels.c1.encryption.keyProvider.keyStoreFile=/path/to/my.keystore
a1.channels.c1.encryption.keyProvider.keyStorePasswordFile=/path/to/my.keystore.password
a1.channels.c1.encryption.keyProvider.keys=key-0
Let’s say you have aged key-0 out and new files should be encrypted withkey-1:
a1.channels.c1.encryption.activeKey=key-1
a1.channels.c1.encryption.cipherProvider=AESCTRNOPADDING
a1.channels.c1.encryption.keyProvider=JCEKSFILE
a1.channels.c1.encryption.keyProvider.keyStoreFile=/path/to/my.keystore
a1.channels.c1.encryption.keyProvider.keyStorePasswordFile=/path/to/my.keystore.password
a1.channels.c1.encryption.keyProvider.keys=key-0 key-1
The same scenerio as above, however key-0 has its own password:
a1.channels.c1.encryption.activeKey=key-1
a1.channels.c1.encryption.cipherProvider=AESCTRNOPADDING
a1.channels.c1.encryption.keyProvider=JCEKSFILE
a1.channels.c1.encryption.keyProvider.keyStoreFile=/path/to/my.keystore
a1.channels.c1.encryption.keyProvider.keyStorePasswordFile=/path/to/my.keystore.password
a1.channels.c1.encryption.keyProvider.keys=key-0 key-1
a1.channels.c1.encryption.keyProvider.keys.key-0.passwordFile=/path/to/key-0.password
十二、Spillable Memory Channel 與Pseudo Transaction Channel
前者還在試驗階段。。後者僅僅用來測試目的,不是在生產環境中使用,所以略過。
十三、CustomChannel
Custom Channel是對channel介面的實現。需要在classpath中引入實現類和相關的jar檔案。這Channel對應的type是該類的完整路徑
下面是官網配置
|
Property Name |
Default |
Description |
|
type |
– |
The component type name, needs to be a FQCN |
後面是官網例子
a1.channels=c1
a1.channels.c1.type=org.example.MyChannel
相關推薦
Flume NG 學習筆記(五)Sinks和Channel配置
一、HDFS Sink Flume Sink是將事件寫入到Hadoop分散式檔案系統(HDFS)中。主要是Flume在Hadoop環境中的應用,即Flume採集資料輸出到HDFS,適用大資料日誌場景。 目前,它支援HDFS的文字和序列檔案格式,以及支援兩個檔案型別的壓縮。支
Flume NG 學習筆記(八)Interceptors(攔截器)測試
攔截器主要是對事件的header資訊資訊操作,要麼直接忽略他,要麼修改他的資料 一、Event Serializers file_roll sink 和hdfs sink 都支援EventSerializer介面 1.1、Body Text Serializer Body
Flume NG 學習筆記(九)Flune Client 開發
由於在實際工作中,資料的生產方式極具多樣性,Flume 雖然包含了一些內建的機制來採集資料,但是更多的時候使用者更希望能將應用程式和flume直接相通。所以這邊執行使用者開發應用程式,通過IPC或者RPC連線flume並往flume傳送資料。 一、RPC client i
python學習筆記(五)——輸入和輸出
第六章 輸入和輸出 #第六章 輸入和輸出 #6.1 輸入和輸出概述 #實現互動功能的方式:a命令列引數 b標準輸入和輸出函式 c檔案輸入和輸出 d圖形化使用者介面 #6.2 命令列引數 #6.2.1 sys.argv與命令列引數 # import sys,random
ios學習筆記(五)陣列和字典
陣列類,可存放OC物件,不可存放int float 的基本資料型別和CGRect這兩種原始資料 陣列中物件的順序是以索引(index)標記的 陣列分為可變陣列和不可變陣列;可變陣列可進行增刪改得操作,不可變陣列不能進行增刪該 不可變陣列: NSArray *arra
數據結構學習筆記(五) 樹的創建和遍歷
一個 後序遍歷 for -1 堆棧 nor ext cnblogs 復制 創建(先序創建和根據先序和中序進行創建)和遍歷(先序遍歷、中序遍歷、後序遍歷、非遞歸堆棧遍歷、層次遍歷): package tree; public class XianCreateTree
最優化學習筆記(五)牛頓法及擬牛頓法
div size -a article fonts alt water src jsb 最優化學習筆記(五)牛頓法及擬牛頓法
javascript學習筆記(五):異常捕獲和事件處理
log 類型 按鈕 輸入 button lan yellow logs 代碼 異常捕獲 Try{ 發生異常的代碼塊 }catch(err){ 異常信息處理 } 1 <!DOCTYPE html> 2 <html> 3 <head
Spring 學習筆記(五)—— Bean之間的關系、作用域、自動裝配
mar byname pps etc 有時 sysman 對象實例 構造 encoding 繼承 Spring提供了配置信息的繼承機制,可以通過為<bean>元素指定parent值重用已有的<bean>元素的配置信息。 <?xml
Go語言學習筆記(五)文件操作
see 大小 unix rdo 筆記 不能 hid code lag 加 Golang學習 QQ群共同學習進步成家立業工作 ^-^ 群號:96933959 文件讀取 os.File 封裝了文件相關操作 type File File代表一個打開的文件對象。
Unity3D之Mecanim動畫系統學習筆記(五):Animator Controller
浮點 key 發現 菜單 融合 stat mon 好的 project 簡介 Animator Controller在Unity中是作為一種單獨的配置文件存在的文件類型,其後綴為controller,Animator Controller包含了以下幾種功能: 可以對
Python學習筆記(五)OOP
默認 tro acl 引入 支持 不同 post set 成像 模塊 使用模塊import 模塊名。有的僅僅導入了某個模塊的一個類或者函數,使用from 模塊名 import 函數或類名實現。為了避免模塊名沖突。Python引入了按文件夾來組織模塊的方
如鵬網學習筆記(五)MySql基礎
修改列 記錄 tex 令行 金額 升序 查詢 自動遞增 col MySQL基礎 一、數據庫概念 1,網友裝備信息、論壇帖子信息、QQ好友關系信息、學籍管理系統中的學生信息等都要“持久化”的保存到一個地方, 如果通過IO寫到文件中,那麽會非常麻煩,而且不利於多人共享數
docker學習筆記(五)——Docker常用命令總結
docker學習筆記 docker常用命令總結 1. 開啟/停止/重啟container(start/stop/restart)容器可以通過run新建一個來運行,也可以重新start已經停止的container,但start不能夠再指定容器啟動時運行的指令,因為docker只能有一個前臺進程。容器st
jQuery學習筆記(五)
加載 complete += ron 序列 border () ajaxstart 單選 jQuery與Ajax的應用 Ajax的優勢和不足 Ajax的優勢 a)不需要插件支持 b)優秀的用戶體驗 c)提高Web程序的性能 d)減輕服務器和寬帶的負擔 Ajax的不
流暢的python和cookbook學習筆記(五)
pytho col () 學習 util 學習筆記 取出 minute python 1.隨機選擇 python中生成隨機數使用random模塊。 1.從序列中隨機挑選元素,使用random.choice() >>> import random
Oracle 學習筆記(五)
采樣 flash 全表掃描 group space 表空間 manage 授權 個數 --表空間,auto: 自動管理, manual: 手動管理 create tablespace tsp1 datafile ‘D:\ORACLE\ORADATA\O10\tsp1.
Hibernate學習筆記(五) --- 創建基於中間關聯表的多對多映射關系
mys 兩個 override pac tid 一對多 main ber different 多對多映射是在實際數據庫表關系之間比較常見的一種,仍然以電影為例,一部電影可以有多個演員,一個演員也可以參演多部電影,電影表和演員表之間就是“多對多”的關系 針對多對多的映射關系,
Java8學習筆記(五)--Stream API詳解[轉]
有效 編程效率 實時處理 phaser 綜合 files -- bin 並發模式 為什麽要使用StreamStream 作為 Java 8 的一大亮點,它與 java.io 包裏的 InputStream 和 OutputStream 是完全不同的概念。它也不同於 StAX
python學習筆記(五)數值類型和類型轉換
學習 系統 oat cal 關於 trac hide sed lin Python中的數值類型有: 整型,如2,520 浮點型,如3.14159,1.5e10 布爾類型 True和False e記法: e記法即對應數學中的科學記數法 1 >>