
雙向長短時記憶迴圈神經網路詳解(Bi-directional LSTM RNN)
1. Recurrent Neural Network (RNN)
儘管從多層感知器(MLP)到迴圈神經網路(RNN)的擴充套件看起來微不足道,但是這對於序列的學習具有深遠的意義。迴圈神經網路(RNN)的使用是用來處理序列資料的。在傳統的神經網路中模型中,層與層之間是全連線的,每層之間的節點是無連線的。但是這種普通的神經網路對於很多問題是無能為力的。比如,預測句子的下一個單詞是什麼,一般需要用到前面的單詞,因為一個句子中前後單詞並不是獨立的。迴圈神經網路(RNN)指的是一個序列當前的輸出與之前的輸出也有關。具體的表現形式為網路會對前面的資訊進行記憶,儲存在網路的內部狀態中,並應用於當前輸出的計算中,即隱含層之間的節點不再無連線而是有連結的,並且隱含層的輸入不僅包含輸入層的輸出還包含上一時刻隱含層的輸出
下圖展示的是一個典型的迴圈神經網路(RNN)結構。
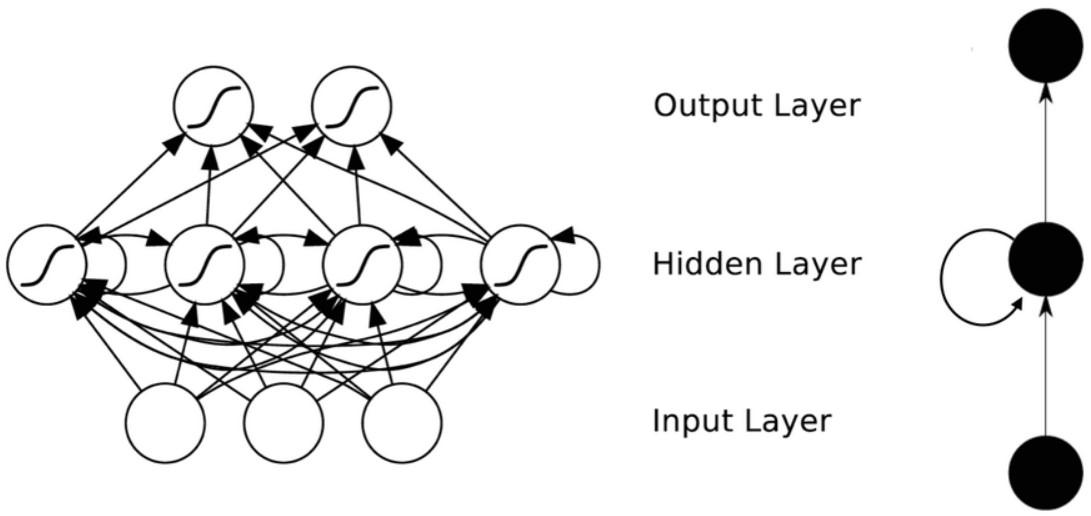
將迴圈神經網路(RNN)視覺化的一種有效方法是考慮將其在時間上進行展開,得到如圖2結構。
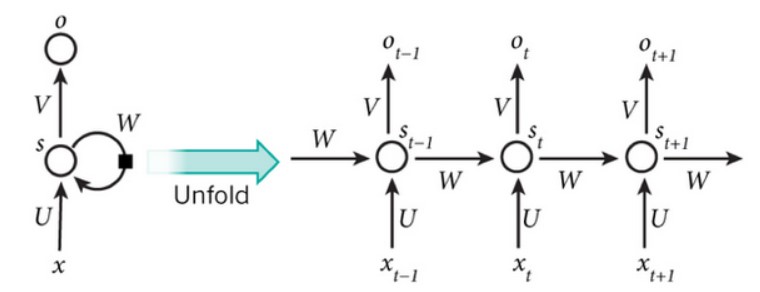
圖中展示的是一個在時間上展開的迴圈神經網路(RNN),其包含輸入單元(Input Units), 輸入集標記為{
在迴圈神經網路中(RNN),有一條單向流動的資訊流是從輸入單元到達隱含單元的,與此同時,另一條單向流動的資訊流從隱含單元到達輸出單元。在某些情況下,迴圈神經網路(RNN)會打破後者的限制,引導資訊從輸出單元返回隱含單元,這些被稱為“Back projections”,並且隱含層的輸入還包括上一層隱含層的輸出,即隱含層內的節點是可以自連也可以互連的。
對於圖2網路的計算過程如下:
1)
2)
3)
需要注意的是:
隱含層狀態
在傳統神經網路中,每一個網路層的引數是不共享的。而在迴圈神經網路(RNN)中,每輸入一步,每一層各自都共享引數U,V,W,其反映著迴圈神經網路(RNN)中的每一步都在做相同的事,只是輸入不同。因此,這大大降低了網路中需要學習的引數。具體的說是,將迴圈神經網路(RNN)進行展開,這樣變成了多層的網路,如果這是一個多層的傳統神經網路,那麼
圖中每一步都會有輸出,但是每一步都要有輸出並不是必須的。比如,我們需要預測一條語句所表達的情緒,我們僅僅需要關係最後一個單詞輸入後的輸出,而不需要知道每個單詞輸入後的輸出。同理,每步都需要輸入也不是必須的。迴圈神經網路(RNN)的關鍵之處在於隱含層,隱含層能夠捕捉序列的資訊。
最後,對於整個迴圈神經網路(RNN)的計算過程如下:
向前推算(Forward pass):
對於一個長度為T的輸入x,網路有I個輸入單元,H個隱含單元,K個輸出單元。定義
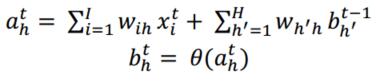
與此同時,對於網路的輸出單元也可以通過如下公式計算出:
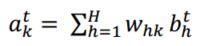
向後推算(Forward pass):
如同標準的反向傳播(Backpropagation),通過時間的反向傳播(BPTT)包含對鏈規則的重複應用。具體的說是,對於迴圈網路,目標函式依賴於隱含層的啟用函式(不僅通過其對輸出層的影響,以及其對下一個時步隱含層的影響),也就是:
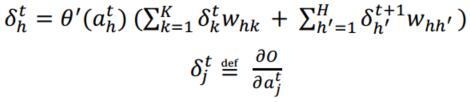
對於全部的序列
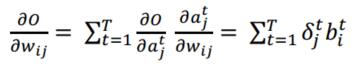
2. Bi-directional Recurrent Neural Network (BRNN)
如果能像訪問過去的上下文資訊一樣,訪問未來的上下文,這樣對於許多序列標註任務是非常有益的。例如,在最特殊字元分類的時候,如果能像知道這個字母之前的字母一樣,知道將要來的字母,這將非常有幫助。同樣,對於句子中的音素分類也是如此。
然而,由於標準的迴圈神經網路(RNN)在時序上處理序列,他們往往忽略了未來的上下文資訊。一種很顯而易見的解決辦法是在輸入和目標之間新增延遲,進而可以給網路一些時步來加入未來的上下文資訊,也就是加入M時間幀的未來資訊來一起預測輸出。理論上,M可以非常大來捕獲所有未來的可用資訊,但事實上發現如果M過大,預測結果將會變差。這是因為網路把精力都集中記憶大量的輸入資訊,而導致將不同輸入向量的預測知識聯合的建模能力下降。因此,M的大小需要手動來調節。
雙向迴圈神經網路(BRNN)的基本思想是提出每一個訓練序列向前和向後分別是兩個迴圈神經網路(RNN),而且這兩個都連線著一個輸出層。這個結構提供給輸出層輸入序列中每一個點的完整的過去和未來的上下文資訊。下圖展示的是一個沿著時間展開的雙向迴圈神經網路。六個獨特的權值在每一個時步被重複的利用,六個權值分別對應:輸入到向前和向後隱含層(w1, w3),隱含層到隱含層自己(w2, w5),向前和向後隱含層到輸出層(w4, w6)。值得注意的是:向前和向後隱含層之間沒有資訊流,這保證了展開圖是非迴圈的。
對於整個雙向迴圈神經網路(BRNN)的計算過程如下:
向前推算(Forward pass):
對於雙向迴圈神經網路(BRNN)的隱含層,向前推算跟單向的迴圈神經網路(RNN)一樣,除了輸入序列對於兩個隱含層是相反方向的,輸出層直到兩個隱含層處理完所有的全部輸入序列才更新:

向後推算(Backward pass):
雙向迴圈神經網路(BRNN)的向後推算與標準的迴圈神經網路(RNN)通過時間反向傳播相似,除了所有的輸出層

3. Long Short-Term Memory (LSTM)
迴圈神經網路(RNN)在工作時一個重要的優點在於,其能夠在輸入和輸出序列之間的對映過程中利用上下文相關資訊。然而不幸的是,標準的迴圈神經網路(RNN)能夠存取的上下文資訊範圍很有限。這個問題就使得隱含層的輸入對於網路輸出的影響隨著網路環路的不斷遞迴而衰退。因此,為了解決這個問題,長短時記憶(LSTM)結構誕生了。與其說長短時記憶是一種迴圈神經網路,倒不如說是一個加強版的元件被放在了迴圈神經網路中。具體地說,就是把迴圈神經網路中隱含層的小圓圈換成長短時記憶的模組。這個模組的樣子如下圖所示:
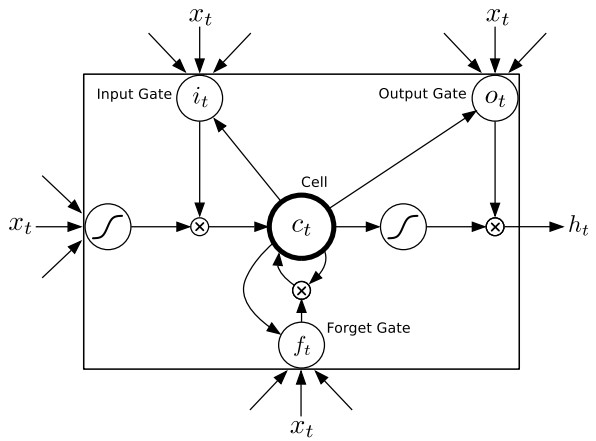
關於這個單元的計算過程如下所示:
向前推算(Forward pass):
Input Gate:
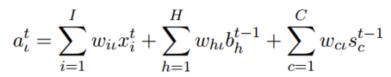
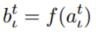
通過上圖可以觀察有哪些連線了 Input Gate: t 時刻外面的輸入, t-1 時刻隱含單元的輸出, 以及來自 t-1 時刻 Cell 的輸出。 累計求和之後進行啟用函式的計算就是上面兩行式子的含義了。
Forget Gate:
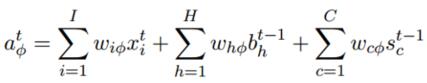
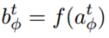
這兩行公式的計算意義跟上一個相同,Forget Gate的輸入來自於t時刻外面的輸入,t-1時刻隱含單元的輸出,以及來自t-1時刻Cell的輸出。
Cells:
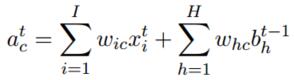
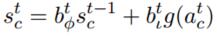
這部分有些複雜,Cell的輸入是:t時刻Forget Gate的輸出 * t-1時刻Cell的輸出 + t時刻Input Gate的輸出 * 啟用函式計算(t時刻外面的輸入 + t-1時刻隱含單元的輸出)
Output Gate:
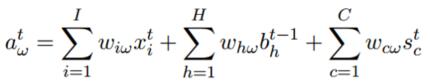
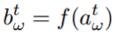
這部分就同樣好理解了:Output Gate的輸入是:t時刻外面的輸入,t-1時刻隱含單元的輸出以及t時刻Cell單元的輸出。
Cell Output:
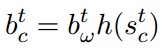
最後,模組的輸出是t時刻Output Gate的輸出 * t時刻Cell單元的輸出。
向後推算(Forward pass):
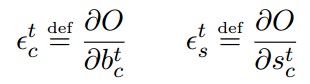
Cell Output:
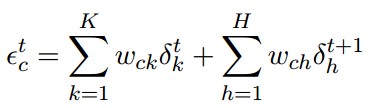
Output Gate:
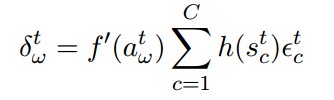
Cells:
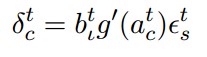
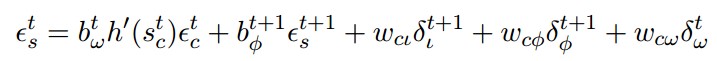
Forget Gate:
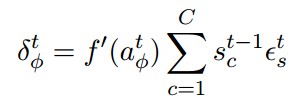
Input Gate:
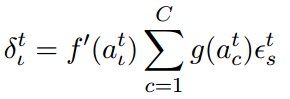
相關推薦
雙向長短時記憶迴圈神經網路詳解(Bi-directional LSTM RNN)
1. Recurrent Neural Network (RNN) 儘管從多層感知器(MLP)到迴圈神經網路(RNN)的擴充套件看起來微不足道,但是這對於序列的學習具有深遠的意義。迴圈神經網路(RNN)的使用是用來處理序列資料的。在傳統的神經網路中模型中,層與
深度學習 --- Hopfield神經網路詳解(吸引子的性質、網路的權值的設計、網路的資訊儲存容量)
上一節我們詳細的講解了Hopfield神經網路的工作過程,引出了吸引子的概念,簡單來說,吸引子就是Hopfield神經網路穩定時其中一個狀態,不懂的請看 Hopfield神經網路詳解,下面我們就開始看看吸引子有什麼性質: 1.吸引子的性質 &nb
深度學習 --- 隨機神經網路詳解(玻爾茲曼機學習演算法、執行演算法)
BM網路的學習演算法 (1) 學習過程 通過有導師學習,BM網路可以對訓練集中各模式的概率分佈進行模擬,從而實現聯想記憶.學習的目的是通過調整網路權值使訓練集中的模式在網路狀態中以相同的概率再現.學習過程可分為兩個階段;第一階段
深度學習 --- 深度卷積神經網路詳解(AlexNet 網路詳解)
本篇將解釋另外一個卷積神經網路,該網路是Hinton率領的谷歌團隊(Alex Krizhevsky,Ilya Sutskever,Geoffrey E. Hinton)在2010年的ImageNet大賽獲得冠軍的一個神經網路,因此本節主要參考的論文也是這次大賽的論文即“Imag
神經網路詳解(基本完成)
Fill you up with petrol 概述 人工神經網路(artificial neural network,ANN),簡稱神經網路(neural network,NN),是一種模仿生物神經網路的結構和功能的數學模型或計算模型。神經網路由大量的人工
學習記憶迴圈神經網路心得
如有繆誤歡迎指正 GRU結構向前傳播 心得(歡迎指正) 當遺忘門等於0的時候當前資訊拋棄 之前記憶前傳 當遺忘門等於1 的時候之前記憶拋棄 當前資訊前傳 當遺忘門的值為0和1之間的時候 調控前傳的記憶與資訊的比例 QAQ Q:LSTM與GRU 的
深度學習 --- Hopfield神經網路詳解
前面幾節我們詳細探討了BP神經網路,基本上很全面深入的探討了BP,BP屬於前饋式型別,但是和BP同一時期的另外一個神經網路也很重要,那就是Hopfield神經網路,他是反饋式型別。這個網路比BP出現的還早一點,他的學習規則是基於灌輸式學習,即
Keras入門教程06——CapsNet膠囊神經網路詳解及Keras實現
論文《Dynamic Routing Between Capsules》 參考了一篇部落格還有Keras官方的程式碼,結合程式碼給大家講解下膠囊神經網路。 1. 膠囊神經網路詳解 1.1 膠囊神經網路直觀理解 CNN存在的問題 影象分類中,一旦卷積核檢測到類
CNN(卷積神經網路)詳解
Why CNN 首先回答這樣一個問題,為什麼我們要學CNN,或者說CNN為什麼在很多領域收穫成功?還是先拿MNIST來當例子說。MNIST資料結構不清楚的話自行百度。。 我自己實驗用兩個hidden layer的DNN(全連線深度神經網路)在MNIST上也能
迴圈神經網路的訓練(2)
權重梯度的計算 現在,我們終於來到了BPTT演算法的最後一步:計算每個權重的梯度。 首先,我們計算誤差函式E對權重矩陣W的梯度∂E∂W。 上圖展示了我們到目前為止,在前兩步中已經計算得到的量,包括每個時刻t 迴圈層的輸出值st,以及誤差項δt。 回憶一下我們在文章
長文 | LSTM和迴圈神經網路基礎教程(PDF下載)
來自公眾號 機器學習演算法與Python學習目錄:前言前饋網路回顧迴圈網路時間反向傳播BPTT梯
神經網路詳解及技巧
[TOC](神經網路) # 前言 筆者一直在ipad上做手寫筆記,最近突然想把筆記搬到部落格上來,也就有了下面這些。因為本是給自己看的筆記,所以內容很簡陋,只是提了一些要點。隨緣更新。 # 正文 ## step1 建立一個神經網路模型 ###### 一個常見的神經網路——完全連線前饋神經網路 - 全連線:la
神經網路視覺化(Visualization of Neural Network )
神經網路視覺化和可解釋性(Visualization and Explanation of Neural Network ) 相對於傳統的ML模型,Deep NN由於其自身所特有的多層非線性的結構而導致難以對其工作原理進行透徹的理解。比如,我們很難理解網路將一個
Javascript設計模式與開發實踐詳解(二:策略模式) http://www.jianshu.com/p/ef53781f6ef2
的人 思想 ram gis pan pro msg have 改變 上一章我們介紹了單例模式及JavaScript惰性單例模式應用這一次我主要介紹策略模式策略模式是定義一系列的算法,把它們一個個封裝起來,並且讓他們可以互相替換。比方說在現實中很多時候也有很多途徑到達同一個
制作自己的Setup.exe-程序打包詳解(基於Visual Studio 2015)
忘記 圖片 安裝文件 for int .com create rtc gis 序言 第一次打包程序,新手,遂作筆記如下,以供自己忘記細節時翻看,也供同樣新手或有需要者以為參考。不敢班門弄斧,大神若是誤入還請莫要見笑。 以下所述基於Visual Studio 2015
Linux基本常用命令之ls詳解(含date,cal)
Linux基礎【1】顯示日期的指令:date示例:(1)#date +%Y/%m/%d結果:2018/02/27(2)#date +%H:%M結果:10:48【2】顯示日歷的指令:cal格式:cal [month] [year]示例:(1)#cal 2 2018(2)#cal 13 2018結果:cal:il
Android熱修復技術原理詳解(最新最全版本)
總結 核心 桌面圖標 實時 開源 穩定性 安卓 定義 check 本文框架 什麽是熱修復? 熱修復框架分類 技術原理及特點 Tinker框架解析 各框架對比圖 總結 ??通過閱讀本文,你會對熱修復技術有更深的認知,本文會列出各類框架的優缺點以及技術原理,文章末尾簡單描述
marquee標簽屬性詳解(跑馬燈文字效果)
del mouseover 鼠標 AR 百分數 lte 距離 BE 100% <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT
MapReduce編程模型詳解(基於Windows平臺Eclipse)
lib read 找到 lin @override ext logs 設置 otf 本文基於Windows平臺Eclipse,以使用MapReduce編程模型統計文本文件中相同單詞的個數來詳述了整個編程流程及需要註意的地方。不當之處還請留言指出。 前期準備 hadoop集群
xxx.launch檔案詳解(部落格學習筆記)
ROS筆記(一)xxx.launch檔案詳解 .launch檔案是ROS中用於同時啟動多個節點的重要檔案,在大型的ROS專案中使用頻繁,所以掌握其主要元素與屬性對ROS系統的應用至關重要: launch標籤(元素)說明 launch拓展說明 parameter說明