
Oracle架構實現原理、含五大程序解析(圖文詳解)
目錄
前言
Oracle架構,講述了Oracle RDBMS的底層實現原理,是Oracle DBA**調優和排錯的基礎理論。深入理解Oracle架構,能夠讓我們在Oracle的路上走的更遠。本文主要是在對RDBMS的底層元件功能和實現原理有一定的瞭解的情況下,結合自身的工作經驗提出了對Oracle調優和排錯的思路。**當然,對Oracle體系結構的理解是一個深遠的過程,需要不斷的更新修改,如有不對,還望指正。:)
Oracle RDBMS架構圖
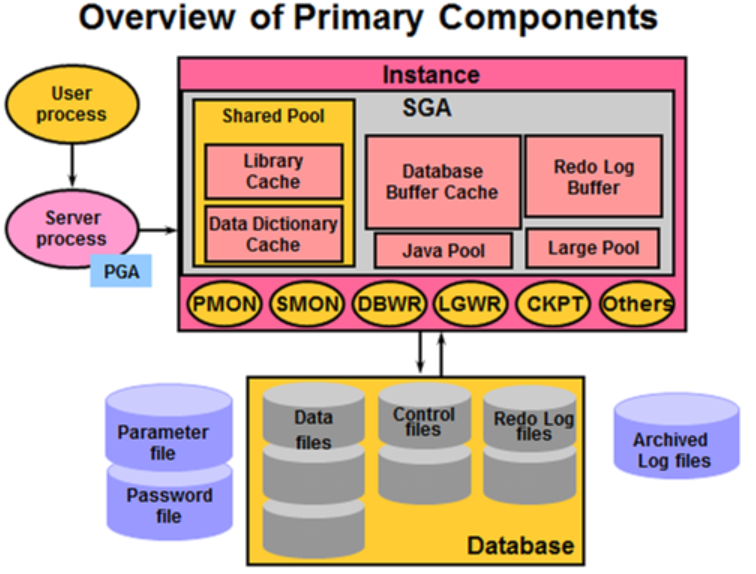
一般我們所說的Oracle指的是Oracle RDBMS(Relational databases Management system),一套Oracle資料庫管理系統,也稱之為Oracle Server。而Oracle Server主要有兩大部分:
Oracle Server = 例項 + 資料庫 (Instance和Database是相互獨立的)
- 資料庫 = 資料檔案 + 控制檔案 +日誌檔案
- 例項 = 記憶體池 + 後臺程序
所以可以細分為: Oracle Server = 記憶體池 + 後臺程序 + 資料檔案 + 控制檔案 + 日誌檔案
一臺Oracle Server支援建立多個Database,而且每個Datacase是互相隔離而獨立的。不同的Database擁有屬於自己的全套相關檔案,例如:有各自的密碼檔案,引數檔案,資料檔案,控制檔案和日誌檔案。
Database由一些物理檔案(如:存放在儲存裝置中的二維表文件)組成。二維表儲存在Database中,但Database的內容不能被使用者直接讀取,使用者必須通過Oracle instance才能夠訪問Database,一個Instance只能連線一個Database,但是一個Database可以被多個Instance連線。
將上面的Oracle RDBMS架構圖進行抽象分類,可以將Oracle架構抽象為:Oracle體系 = 記憶體結構 + 程序結構 + 儲存結構
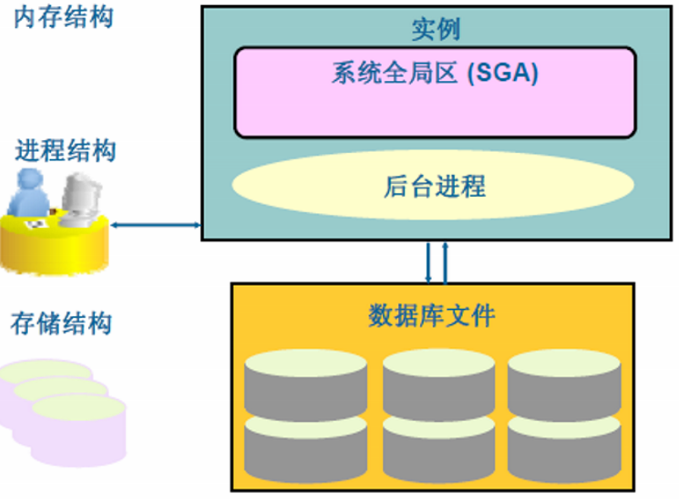
記憶體結構
Oracle Instance是Oracle RDBMS的核心之一,負責RDBMS的管理功能。Oracle Instance主要由記憶體池SGA和後臺程序組成。
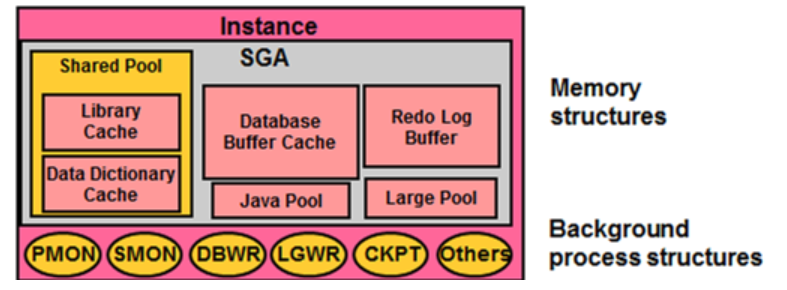
系統全域性區SGA
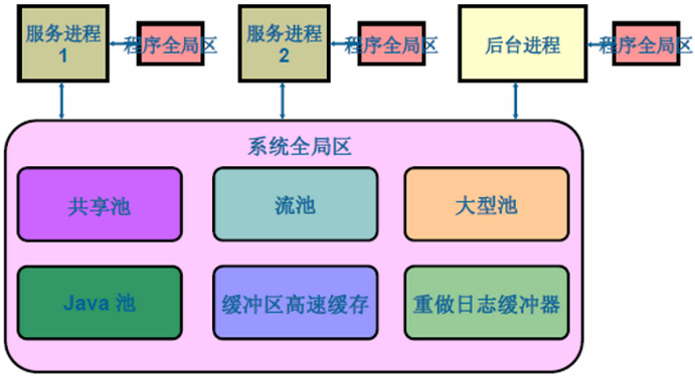
記憶體池SGA的預設Size,會在安裝Oracle的時候會根據LinuxOS的sysctl.conf引數檔案來決定:
kernel.shmall = 2097152
kernel.shmmax = 2147483648
kernel.shmmni 檢視SGA的Size:
SQL> conn /as sysdba
Connected.
SQL> show user;
USER is "SYS"
SQL> select * from v$sga;
NAME VALUE
-------------------- ----------
Fixed Size 2022144
Variable Size 503317760
Database Buffers 1627389952
Redo Buffers 14753792
SQL> show sga
Total System Global Area 2147483648 bytes #對應kernel.shmmax = 2147483648
Fixed Size 2022144 bytes
Variable Size 503317760 bytes
Database Buffers 1627389952 bytes
Redo Buffers 14753792 bytesSGA(System Global Area)是與Oracle效能關係最大的核心部分,也是對Oracle進行調優的主要考量。SGA記憶體池會在Instance啟動時被分配,在Instance關閉時被釋放。在一定範圍內,SGA可以在Instance執行時通過自動方式響應DBA的指令。如果想對SGA進行調優還必須理解SGA所包含如下幾種資料結構:
快取記憶體緩衝區(資料庫緩衝區)
資料庫緩衝區是oracle執行SQL語句的區域。
例如在更新資料時,使用者執行的SQL語句不會直接對磁碟上的資料檔案進行更改操作,而是首先將資料檔案複製到資料庫緩衝區快取(就是說資料庫緩衝區裡會存放著SQL相關資料檔案副本),再更改應用於資料庫緩衝區快取中這些資料塊的副本。而且資料塊副本將在快取中保留一段時間,直至其佔用的緩衝區被另一個數據庫覆蓋為止(緩衝區Size有限)。
在查詢資料時,為了提高執行效率,查詢的資料也要經過快取。建立的Session會計算出那些資料塊包含關鍵的行,並將它們複製到資料庫緩衝區中進行快取。此後,相關關鍵行會傳輸到Session的PGA作進一步處理。這些資料塊也會在資料庫快取區快取中保留一段時間。
一般情況下,被頻繁訪問的資料塊會存在於資料庫緩衝區快取中,從而最大程度地減少對磁碟I/O的需要。
那什麼時候會將被更新的資料塊副本寫入到磁碟中的資料檔案呢?
答案就是:如果在緩衝區快取中儲存的資料塊與磁碟上的資料塊不同時,那麼這樣的緩衝區常稱為”髒緩衝區”,髒緩衝區中的資料塊副本就必須寫回到磁碟的資料檔案中。
調優:資料庫緩衝區快取的大小會對效能產生至關重要的影響,具體需要多大的Size才能成為最佳配比還要結合實際的生產環境而言。總體而言可以依據以下兩點基本要求來判斷:
1. 快取應足夠大,以便能快取所有被頻繁訪問的資料塊。如果快取過小,那麼將導致磁碟I/0活動過多,因為頻繁訪問的資料塊持續從磁碟讀取,並由其他資料塊使用和重寫,然後再從磁碟讀取。
2. 但也不能太大,以至於它會將極少被訪問的塊也一併加入到快取中,這樣會增長在快取中搜索的時間。
資料庫緩衝區快取在Instance啟動時被分配。從資料庫9i開始,可以隨時將其調大或調小。可以採用手動方式重調,也可以根據工作負荷自動重調大小(事務)。
修改緩衝區DB_CACHE_SIZE地方法:
#Step1. 檢視SGA的大小:因為DB_CACHE_SIZE的size受SGA的影響
SQL> show parameter sga_max_size;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
sga_max_size big integer 2G
#Step2. 檢視show parameter shared_pool_size的大小
SQL> show parameter shared_pool_size; NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
shared_pool_size big integer 0
#Step3. 計算DB_CACHE_SIZE的大小:shared_pool_size + db_cache_size = SGA_MAX_SIZE * 70%
#Step4. 修改DB_CACHE_SIZE的大小
SQL> alter system set db_cache_size=1433M scope=spfile sid='demo';
System altered.
SQL> conn sys /as sysdba
Enter password: ********
Connected.
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup
ORACLE instance started.
Total System Global Area 2147483648 bytes
Fixed Size 2022144 bytes
Variable Size 503317760 bytes
Database Buffers 1627389952 bytes
Redo Buffers 14753792 bytes
Database mounted.
Database opened.
SQL> show parameter db_cache_size日誌緩衝區
日誌緩衝區是小型的、用於短期儲存將寫入到磁碟上的重做日誌的變更向量的臨時區域。主要作用是提供更加快的日誌處理效率。
共享池
共享池的大小也對效能產生重要影響
1. 它應該足夠大,以便快取所有頻繁執行的程式碼和頻繁訪問的物件定義。如果共享池過小,則效能下降,因為伺服器會話將反覆搶奪其中的空間來分析語句,此後,這些語句會被其他語句重寫,在重新執行時,將不得不再次分析。如果共享池小於最優容量,則效能將下降。但有一個最小容量,如果低於此限度,則語句將失敗。
2. 但也不能過大,以至於連僅執行一次的語句也要快取。過大的共享池也會對效能產生不良影響,因為搜尋需要的時間過長。
確定最優容量是一個性能調整問題,大多數資料庫都需要一個數百MB的共享池。有些應用程式需要1GB以上的共享池,但很少有應用程式能夠在共享池小於100MB時充分執行。共享池內有下列三種資料結構:
- 庫緩衝:儲存最近執行的程式碼
- 資料字典快取:儲存最近使用的物件定義
- PL/SQL緩衝區:儲存的PL/SQL物件是過程、函式、打包的過程、打包的函式、物件型別定義和觸發器。
手動的調整共享池的大小:
select COMPONENT,CURRENT_SIZE,MIN_SIZE,MAX_SIZE from v$sga_dynamic_components; //顯示可以動態重設大小的SGA元件的當前最大和最小容量
ALTER SYSTEM SET SHARED_POOL_SIZE = 110M;其他結構
這裡暫時不做詳細介紹。
大型池
主要用途是供共享的伺服器程序使用。
JAVA池
只有當應用程式需要在資料庫中執行java儲存程式時,才需要java池。
程序結構
程序結構主要有後臺程序和使用者連線程序兩大類。
使用者連線程序
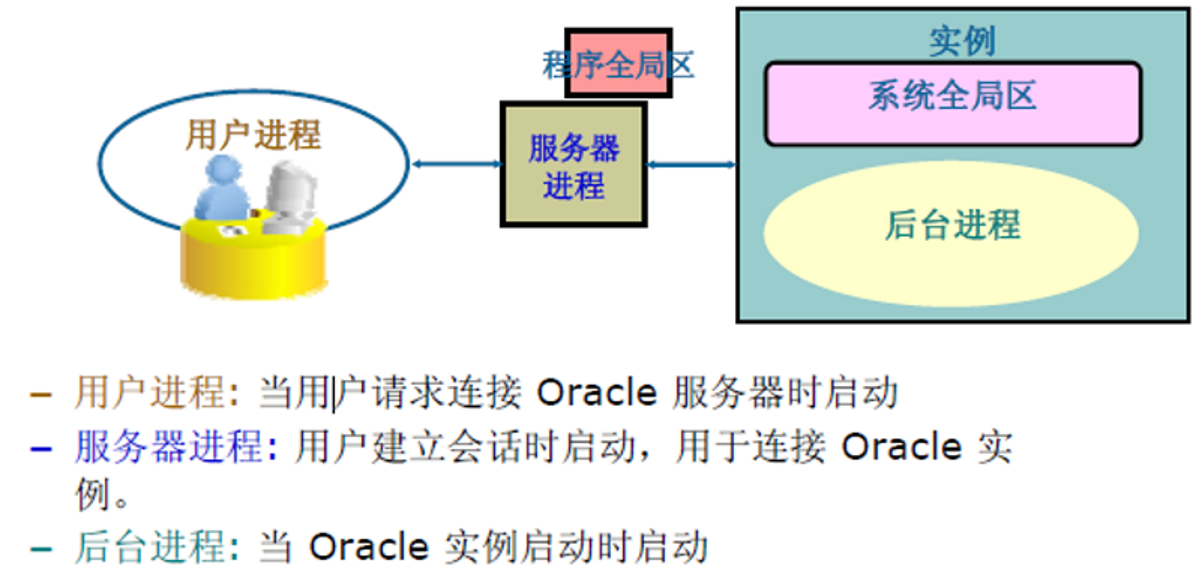
使用者連線程序是連線使用者和Oracle Instance的橋樑。只有在User與Instance建立了連線以後,User才能夠對Oracle Server進行操作。
使用者連線程序 = 使用者程序 + 服務程序 + PGA
使用者程序User Process
當一個Database User請求連線到Oracle Server時,Oracle Server會建立User Process。
User Process的作用:
- 為Database User與Server Process建立連線
- 並不會直接與Oracle Server互動
connect連線:是User和Server Process之間的通訊通道。

Server Process服務程序
用於處理Database User和Oracle Server之間的連線。
當一個User與User Process建立了一個connect後,Oracle Server會建立一個Server Process。然後再由User Process與Server Process建立了連線之後,Server Process會通過使用者提交的請求資訊來確定與oracle instance建立一個會話。
Server Process的作用:
- 與Oracle Server直接互動
- 複製執行和返回結果
Session會話:一個使用者通過User Process(本質是通過Server Process)與Oracle Instance建立連線後稱之為一個會話,一個使用者可以建立多個會話,即同時使用同一個使用者可以多次的連線到同一個例項,也就是說多個session可以使用同一個connect。

程式全域性區PGA
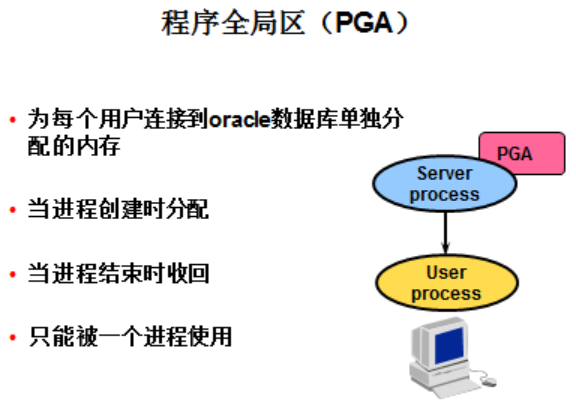
PGA:Oracle Server Process分配來專門用於當前User Session的記憶體區。該區域是私有的,不同的使用者擁有不同的PGA。
PGA包含了Server Process資料和控制資訊的記憶體區域。,由下列3個部分組成:
1. 棧空間:儲存Session的變數、陣列等的記憶體空間。
2. Session Info:如果執行的不是多執行緒伺服器,會話資訊將儲存在PGA中,如果是多執行緒伺服器,則儲存在SGA中。
3. 私有SQL區:用來儲存繫結變數(binding variables)和執行時緩衝區(runtime buffers)等資訊。
Oracle的connect連線和session會話與User Process緊密相關
注意:在RDBMS中由db\_name和instance\_name共同確定一個Database,所以Instance_name被用於Oracle與OS之間的聯絡同時也被用於Oracle Server與外部連線時使用。
所以在User提交連線請求的時候,User Process首先會與Server Process建立Connect,然後Server Process會通過請求中所包含的db\_name和Instance\_name來確定需要且可以被連線的資料庫(RDBMS可以存在多個數據庫),這樣就確保了RDBMS在擁有多個數據庫的情況下,還能夠保證每一個Database的獨立性。而且同一個Database可以被多個屬於這個Databse的不同使用者發起的Instance連線。這一個功能是非常有必要的,因為每一個不同的資料庫中都包含有同名的sys、system等系統使用者。
後臺程序
後臺程序主要是完成資料庫管理任務 ,後臺程序是Oracle Instance和Oracle Database的聯絡紐帶,分為核心程序和非核心程序。
1. 核心程序:核心程序,必須存在,有一個終止,所有資料庫程序全部終止,例項崩潰!其中五大程序全都是核心程序。
2. 非核心程序:完成資料庫的額外功能,非核心程序死亡資料庫不會崩潰!
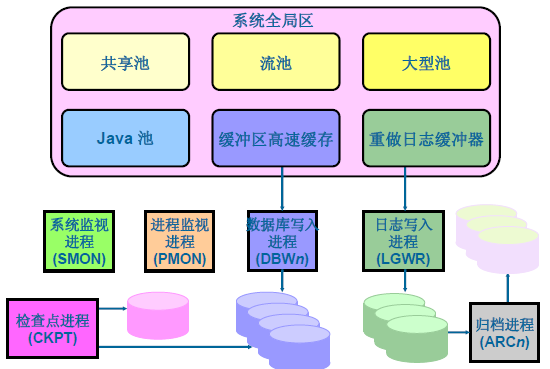
常用的核心程序:
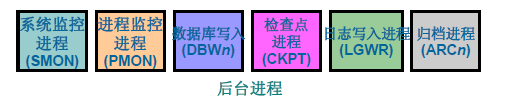
在使用者訪問資料庫時,首先會提交請求,再分配SGA記憶體,建立並啟動後臺程序和例項,最後建立連線和會話。Oracle Server執行過程中必須啟動上面的前五個程序。否則例項無法建立。
檢視後臺程序:
SQL> select name,description from v$bgprocess where paddr<>'00';
NAME DESCRIPTION
----- ----------------------------------------------------------------
PMON process cleanup
PSP0 process spawner 0
MMAN Memory Manager
DBW0 db writer process 0
LGWR Redo etc.
CKPT checkpoint
SMON System Monitor Process
RECO distributed recovery
CJQ0 Job Queue Coordinator
QMNC AQ Coordinator
MMON Manageability Monitor Process
NAME DESCRIPTION
----- ----------------------------------------------------------------
MMNL Manageability Monitor Process 2
資料庫寫入程序(DBWn)
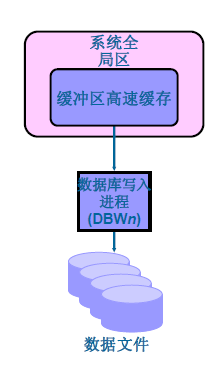
Server process連線Oracle後,通過資料庫寫程序(DBWn)將資料緩衝區中的“髒緩衝區”的資料塊寫入到儲存結構(資料檔案、磁碟檔案)
Database writer (DBWn)資料庫寫程序:
只做一件事,將資料寫到磁碟。就是將資料庫的變化寫入到資料檔案。
該程序最多20 個,即使你有36 個CPU 也只能最多有20 個數據庫寫程序。
程序名稱DBW0-DBW9 DBWa-DBWj
注意:資料庫寫程序越多,寫資料的效率越高。該程序的個數應該和cpu的個數對應,如果設定的資料庫寫程序數大於CPU 的個數也不會有太明顯的效果,因為CPU 是分時的。
檢查點(CKPT)
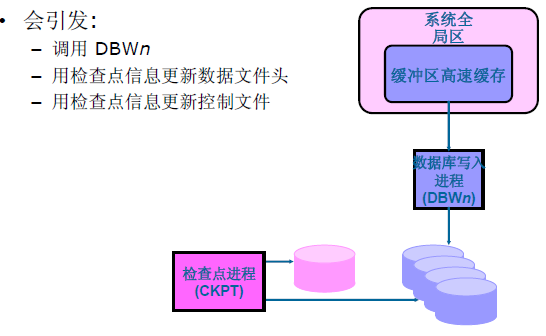
Checkpoint (CKPT)檢查點程序:
主要使用者更新資料檔案頭,更新控制檔案和觸發DBWn資料庫寫程序。
Ckpt 程序會降低資料庫效能,但是提高資料庫崩潰時,自我恢復的效能。我們可以理解為階段性的儲存資料,一定的條件滿足就觸發,執行DBWn存檔操作。
程序監視程序(PMON)
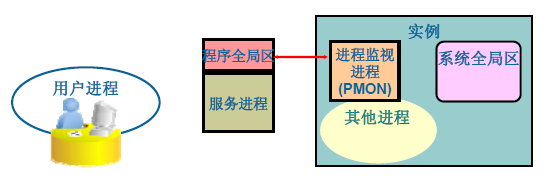
Process monitor (PMON)程序監測程序:
PMON在後臺程序執行失敗後負責清理資料庫快取和閒置資源,是Oracle的自動維護機制。
- 清除死程序
- 重新啟動部分程序(如排程程序)
- 監聽的自動註冊
- 回滾事務
- 釋放鎖
- 釋放其他資
系統監視程序(SMON)
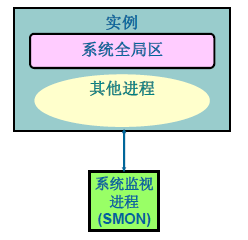
System monitor (SMON)系統監測程序:
SMON啟動後會自動的用於在例項崩潰時進行資料庫例項自動恢復。
清除作廢的排序臨時段,回收整理碎片,合併空閒空間,釋放臨時段,維護閃回的時間點。
在老資料庫版本中,當我們大量刪除表的時候,會觀測到SMON程序很忙,直到把所有的碎片空間都整理完畢。
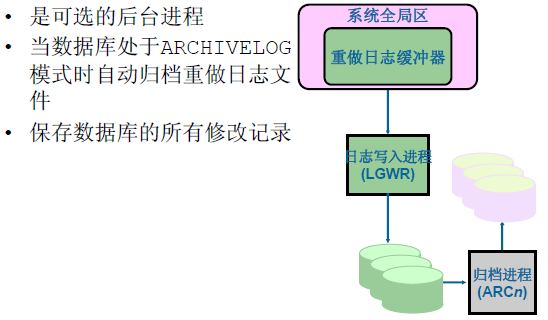
重做日誌檔案和日誌寫入程序
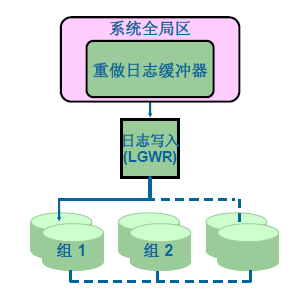
主要用於記錄資料庫的改變和記錄資料庫被改變之前的原始狀態,所以應當對其作多重備份,用於恢復和排錯。
啟用LGWR的情況:
- 提交指令
- 日誌緩衝區超過1/3
- 每三秒
- 每次DBWn執行之前
歸檔程序(ARCn)
歸檔程序(ARCn)是非核心程序。
儲存結構
Oracle RDBMS儲存結構主要由Database組成。
又能夠將Database分為物理結構和邏輯結構來理解。
物理結構
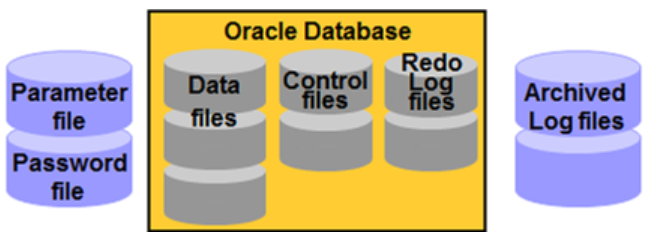
Database物理結構:是Database在作業系統中的檔案集合,即:磁碟上的物理檔案,主要由資料檔案、控制檔案、重做日誌檔案、歸檔日誌檔案、引數檔案、口令檔案組成。
Data Files
資料檔案是資料的儲存倉庫。
• 包括所有的資料庫資料
• 只能屬於一個數據庫
• 來自於被稱為”表空間”的資料庫儲存邏輯單元
• 可以直接被讀進記憶體,在執行SQL語句的時候,會將相關的資料檔案副本載入如資料緩衝區。
• 通過備份策略可以使資料檔案得到保護
Redo Log Files
重做日誌檔案包含對資料庫所做的更改操作記錄,在Oracle發生故障時能夠恢復資料。
能夠恢復資料的原理:重做日誌檔案會按時間的順序,將應用於資料庫的一連串的變更向量(做了什麼操作)儲存起來(即將變更的地方標記起來)。其中包含了所有已經完成操作的資訊和完成操作之前的資料庫狀態。如果資料檔案受損,就可以將這些變更向量應用於資料檔案備份來進行重做(重建)工作,將它恢復到發生故障的那一刻前的狀態。重做日誌檔案又分為下面兩種型別:
- 聯機重做日誌檔案:記錄連續的資料庫操作
- 歸檔日誌檔案Archived Log Files:用於時間點恢復,當RedoLogFiles存滿時,會對這些日誌進行歸檔備份,以便以後還原資料時使用。
- 檢視redo log info:
SQL> select member from v$logfile; # v$logfile資料字典,記錄了redolog檔案的列表
MEMBER
--------------------------------------------------------------------------------
/u01/oradata/demo/redo03.log
/u01/oradata/demo/redo02.log
/u01/oradata/demo/redo01.logControl Files
控制檔案包含維護和驗證資料庫完整性的必要的資訊。
它記錄了聯機重做日誌檔案、資料檔案的位置、更新的歸檔日誌檔案的位置。它還儲存著維護資料庫完整性所需的資訊,如資料庫名。控制檔案是以二進位制型式儲存的,使用者無法修改控制檔案的內容。控制檔案不過數MB,卻起著至關重要的作用。
Parameter File
例項引數檔案,當啟動oracle例項時,SGA結構會根據此引數檔案的設定記憶體,後臺程序會據此啟動。
Password File
使用者通過提交username/password來建立會話,Oracle根據儲存在資料字典的使用者定義對使用者名稱和口令進行驗證。
邏輯結構
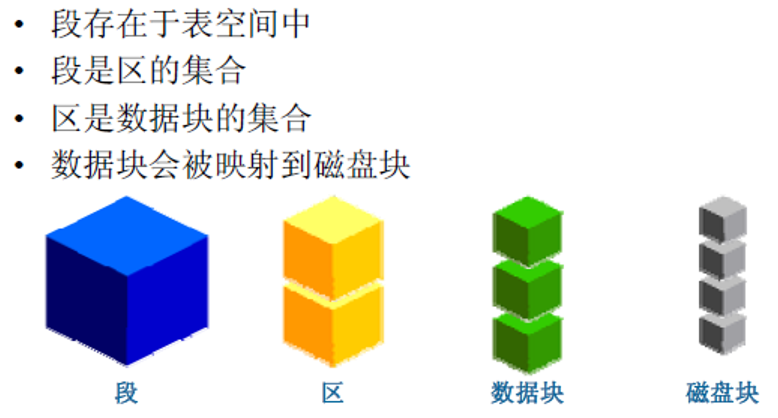
表空間就是典型的Oracle邏輯結構型別 —— 裡面存放著若干的資料檔案
表空間:用於儲存資料庫物件的邏輯空間,表空間是在資料庫中開闢的一個空間,用於存放資料庫的物件,它是資訊儲存的最大邏輯單位,是存放資料庫檔案的地方,其中資料又被存放在表空間中的資料檔案中。一個數據庫可以由多個表空間組成,Oracle的調優就是通過表空間來實現的。(Oracle資料庫獨特的高階應用)
表空間的作用:分類管理、批量處理; 將瑣碎的磁碟檔案整合、抽象處理成為邏輯結構。這樣更加便於我們去管理資料庫。
邏輯空間到物理空間的對映
段、區和塊:
執行一條寫入的SQL語句時在RDBMS中都發生了什麼
1. 將SQL語句載入入資料庫緩衝區
2. 將SQL語句要操作的資料檔案副本載入入資料庫緩衝區
3. 執行SQL語句,修改資料檔案副本,形成“髒緩衝區”
4. CKPT檢測到“髒緩衝區”,呼叫DBWn
5. 在DBWn執行之前,先運行了LGWR,將資料檔案的原始狀態和資料庫的改變記錄到Redo Log Files
6. 執行DBWn,將“髒緩衝區的內容寫入到資料檔案”
7. 同時CKPT修改控制檔案和資料檔案頭
8. SMON回收不必要的空閒資源
最後
最後我們舉個例子來看看Oracle RDBMS是怎麼運作的
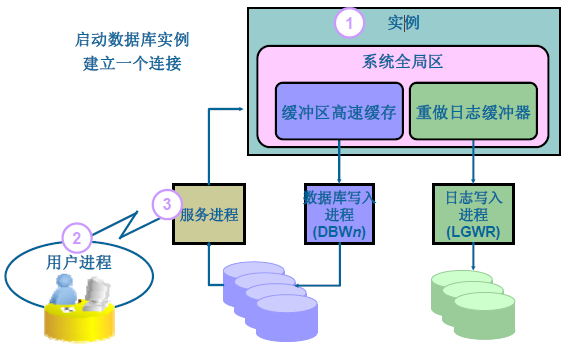
- User訪問Oracle Server之前提交一個請求(包含了db_name、instance_name、username、password等資訊),Oracle Server接收到請求並通過Password File的驗證後,分配SGA記憶體池,啟動後臺程序同時建立並啟動例項。
- 在啟動例項之後User Process與Server Process建立Connect。
- 再通過Server process和Oracle Instance完成建立Sesscion。
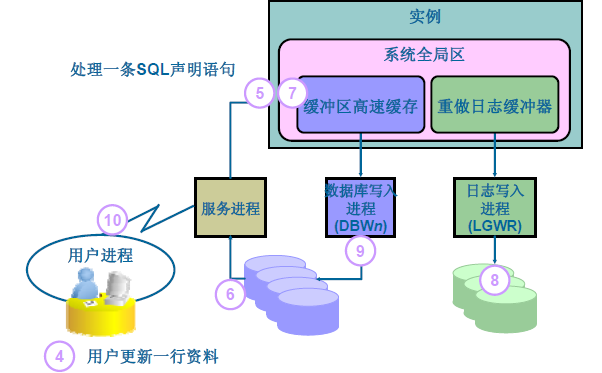
- 使用者執行SQL語句,由server process接收到並直接與Oracle互動。
- SQL語句通過Server Process到達Oracle Instance,再將SQL載入資料庫緩衝區。
- Server Process通知Oracle Database將與SQL語句相關的資料塊副本載入到緩衝區中。
- 在資料庫快取區執行SQL語句,併產生”髒緩衝區”。
- 由CKPT檢查點程序檢查到”髒緩衝區”,並呼叫DBWn資料庫寫程序,但在DBWn執行之前,應該由LGWR先將資料檔案的原始狀態、資料庫的改變等資訊記錄到Redo Log Files。
- 將更新的內容寫入到磁碟中的資料檔案。
- 返回結果給使用者
相關推薦
Oracle架構實現原理、含五大程序解析(圖文詳解)
目錄 前言 Oracle架構,講述了Oracle RDBMS的底層實現原理,是Oracle DBA**調優和排錯的基礎理論。深入理解Oracle架構,能夠讓我們在Oracle的路上走的更遠。本文主要是在對RDBMS的底層元件功能和實現原理有一定的瞭
vi和vim文本編輯器原理、參數及快捷鍵詳解
vi vim linux 運維 系統 vi屬於Linux內核內置命令(vi編輯器)1、 vi/vim工作原理在學習vi/vim編輯器參數與快捷鍵之前首先得了解vi/vim的工作原理。vi/vim命令有三大模式:編輯模式、視圖模式、命令模式;不同模式可以執行不同的命令。 2、vim基於
電腦(Linux/Windows)使用SSH遠端登入安卓(Android)手機實現無線傳輸和管理檔案(圖文詳解)
電腦(Linux/Windows系統)使用SSH遠端登入安卓(Android)手機實現無線傳輸和管理檔案(圖文詳解) 溫馨提示 本文只針對安卓(Android)手機!iPhone或者WP的手機使用者,請不要浪費時間在本文。 前言 在將And
排序(二)鍵索引、桶排序、位示圖、敗者樹等(圖文詳解--敗者樹)
排序(二) 以上排序演算法都有一個性質:在排序的最終結果中,各元素的次序依賴於它們之間的比較。我們把這類排序演算法稱為比較排序。 任何比較排序的時間複雜度的下界是nlgn。 以下排序演算法是用運算而不是比較來確定排序順序的。因此下界nlgn對它們是不適用的。
WebSocket實現線上聊天及常見BUG解決[圖文詳解]
前言 最近在開發時碰到這樣一個需求:使用者瀏覽我們的官網時,存在一個問題反饋的入口,當管理員在PC端的時候可以直接回復,當管理員不在的時候,進行微信推送,管理員在微信端和客戶進行一對一的線上問題解答,由於這個功能塊的收益客戶較小,最終技術選型採用WebSock
Zookeeper之Zookeeper底層客戶端架構實現原理(轉載)
一次 描述 綁定 機制 一個 ini fin 源碼 receive Zookeeper的Client直接與用戶打交道,是我們使用Zookeeper的interface。了解ZK Client的結構和工作原理有利於我們合理的使用ZK,並能在使用中更早的發現問題。本文將在研究源
Lucene全文檢索之倒排索引實現原理、API解析【2018.11】
》 官網 http://lucene.apache.org/ 下載地址:https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/java/7.5.0/ 》 Lucene的全文檢索是指什麼: 程式掃描文件
分散式服務架構:原理、設計與實戰
網站 更多書籍點選進入>> CiCi島 下載 電子版僅供預覽及學習交流使用,下載後請24小時內刪除,支援正版,喜歡的請購買正版書籍 電子書下載(皮皮雲盤-點選“普通下載”) 購買正版 封頁 編輯推薦 本書以分散式服務架構為主線
SpringMVC架構實現原理
一、SpringMVC介紹 Spring mvc是一個基於mvc的web框架。其中核心類是DispatcherServlet,它是一個Servlet,頂層是實現的Servlet介面。 Spring mvc是spring框架的一個模組,spr
Zookeeper實現原理、結構、相關操作命令
一、基本介紹 Zookeeper 是 Google 的 Chubby一個開源的實現,是 Hadoop 的分散式協調服務 。它包含一個簡單的原語集,分散式應用程式可以基於它實現同步服務,配置維護和命名服
ElasticSearch之高亮使用-plian、postings 、fvh 實現原理、差異
很多應用場景下,搜尋帶高亮顯示可以較好的改善使用者體驗。常用的企業搜尋引擎Elasticsearch、Solr中均提供了高亮的功能。Elasticsearch、Solr中的高亮顯示是
薦書:《分散式服務架構:原理、設計與實戰》
全面介紹分散式服務架構的原理與設計 給出保障線上服務健康、可靠的至佳方案 自網際網路誕生以來,其簡單、敏捷的微服務架構開發理念和實踐逐漸成為主流,在逐漸發展的環境下和技術演化的過程中,迅速突破網際網路行業並波及軟體行業的各個領域。然而,這種突飛猛進的表面下卻是龍魚混雜、泥沙俱下。一方面,很多人在這
Socket、XMPP的實現原理、環信的實現原理
Socket又稱"套接字” 網路上的兩端通過建立一個雙向的通訊連線實現資料的交換,這個端就稱為一個Socket端。 應用程式通常通過"套接字"向網路發出請求或者應答網路請求 是否使用過XMPP,X
HashMap的底層實現原理、HashMap與HashTable的區別、HashMap與HashSet的區別
一、HashMap的工作原理: HashMap基於hashing原理,我們通過put()和get()方法儲存和獲取物件。當我們將鍵值對傳遞給put()方法時,它呼叫鍵物件的hashCode()方法來計算hashcode,讓後找到bucket位置來儲存值物件。
+++++++DNS基本工作原理、DNS正反向解析及主從同步
博客 運維 linux dns基礎工作原理bind Berkerley Information Name DomainDNS Domain Name ServerTCP/UDP 53UDP 53 無連接協議,域名解析TCP 53 面向連接協議,區域傳送歷史IANA統一名字,自己hosts中維護(%
微信小程序 WXML、WXSS 和JS介紹及詳解
名單 獲取 hang href 直接 last 1.2 data sub 前幾天折騰了下。然後列出一些實驗結果,供大家參考。 百牛信息技術bainiu.ltd整理發布於博客園 0. 使用開發工具模擬的和真機差異還是比較大的。也建議大家還是真機調試比較靠譜。 1. WXML(
Oracle 12c Windows安裝、介紹及簡單使用(圖文)
htm 編程 閱讀 arch 用戶 upgrade plsql windows安裝 條件 1、下載 地址為:http://www.oracle.com/technetwork/cn/database/enterprise-edition/downloads/inde
DNS簡介、DNS工作原理、DNS正反向解析的搭建、DNS主從備份、DNS子域創建
查找 art 技術分享 c51 找到 tex 文件權限 就會 查詢方式 一、DNS簡介DNS 域名系統(Domain Name System)萬維網上作為域名和IP地址相互映射的一個分布式數據庫,能夠使用戶更方便的訪問互聯網,而不用去記讓人頭疼的一大串數字。根服務器:13組
MyBatis JdbcType 與Oracle、MySql資料型別對應關係詳解
1. Mybatis JdbcType與Oracle、MySql資料型別對應列表 Mybatis JdbcType Oracle MySql JdbcType ARRAY JdbcType B
cloudermanger安裝時需要安裝或徹底正確解除安裝再安裝orcal-java7-installer、oracle-java7-set-default(ubuntu14.04版本)(圖文詳解)
歡迎您的加入! 微信公眾號平臺: 大資料躺過的坑 微信公眾號平臺: 人工智慧躺過的坑 大資料和人工智慧躺過的坑(總群): 161156071 更多QQ技術分群,詳情請見:http://www.cnblogs.com/zls