
Lambda表示式和Java集合框架
Java8為容器新增一些有用的方法,這些方法有些是為完善原有功能,有些是為引入函數語言程式設計(Lambda表示式),學習和使用這些方法有助於我們寫出更加簡潔有效的程式碼.本文分別以ArrayList和HashMap為例,講解Java8集合框架(Java Collections Framework)中新加入方法的使用.
前言
為引入Lambda表示式,Java8新增了java.util.funcion包,裡面包含常用的函式介面,這是Lambda表示式的基礎,Java集合框架也新增部分介面,以便與Lambda表示式對接。
首先回顧一下Java集合框架的介面繼承結構:
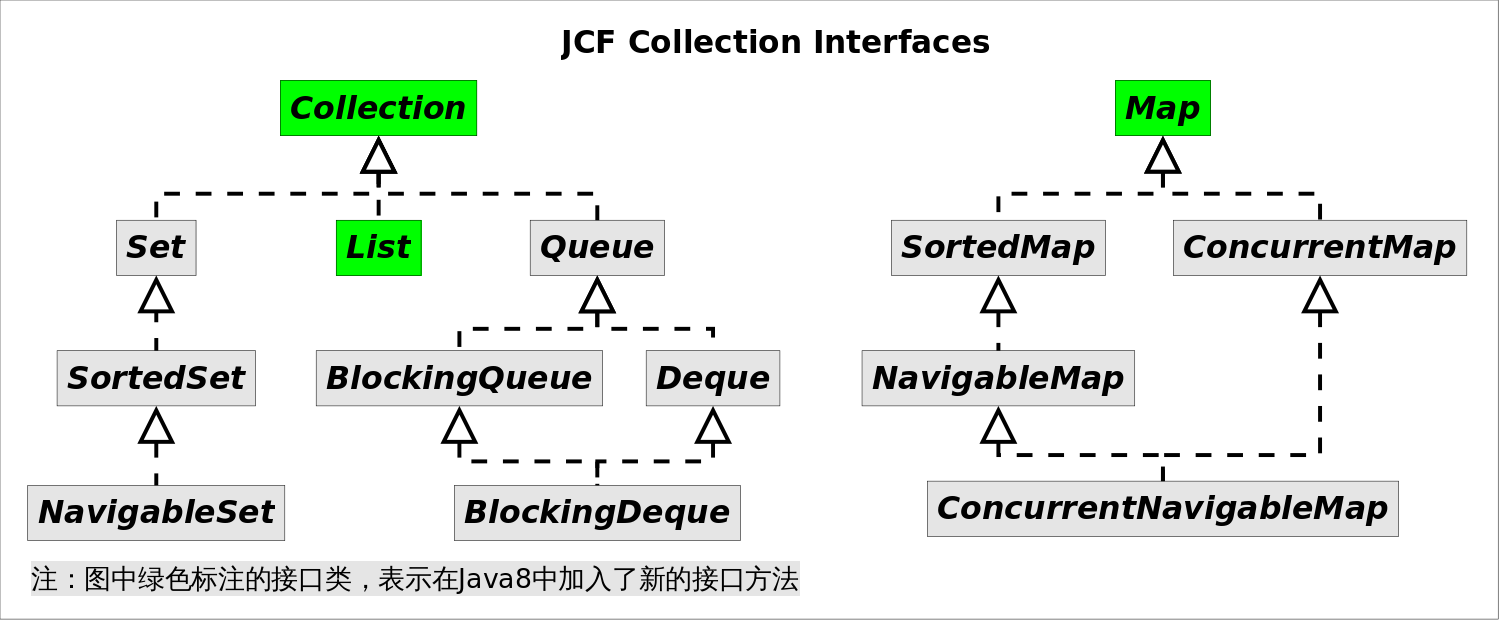
上圖中綠色標註的介面類,表示在Java8中加入了新的介面方法,當然由於繼承關係,他們相應的子類也都會繼承這些新方法。下表詳細列舉了這些方法。
| 介面名 | Java8新加入的方法 |
|---|---|
| Collection | removeIf() spliterator() stream() parallelStream() forEach() |
| List | replaceAll() sort() |
| Map | getOrDefault() forEach() replaceAll() putIfAbsent() remove() replace() computeIfAbsent() computeIfPresent() compute() merge() |
這些新加入的方法大部分要用到java.util.function包下的介面,這意味著這些方法大部分都跟Lambda表示式相關。我們將逐一學習這些方法。
Collection中的新方法
如上所示,介面Collection和List新加入了一些方法,我們以是List的子類ArrayList為例來說明。瞭解Java7ArrayList實現原理,將有助於理解下文。
forEach()
該方法的簽名為void forEach(Consumer<? super E> action),作用是對容器中的每個元素執行action指定的動作,其中Consumer是個函式介面,裡面只有一個待實現方法void accept(T t)(後面我們會看到,這個方法叫什麼根本不重要,你甚至不需要記憶它的名字)。
需求:假設有一個字串列表,需要打印出其中所有長度大於3的字串.
Java7及以前我們可以用增強的for迴圈實現:
// 使用曾強for迴圈迭代
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
for(String str : list){
if(str.length()>3)
System.out.println(str);
}現在使用forEach()方法結合匿名內部類,可以這樣實現:
// 使用forEach()結合匿名內部類迭代
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.forEach(new Consumer<String>(){
@Override
public void accept(String str){
if(str.length()>3)
System.out.println(str);
}
});上述程式碼呼叫forEach()方法,並使用匿名內部類實現Comsumer介面。到目前為止我們沒看到這種設計有什麼好處,但是不要忘記Lambda表示式,使用Lambda表示式實現如下:
// 使用forEach()結合Lambda表示式迭代
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.forEach( str -> {
if(str.length()>3)
System.out.println(str);
});上述程式碼給forEach()方法傳入一個Lambda表示式,我們不需要知道accept()方法,也不需要知道Consumer介面,型別推導幫我們做了一切。
removeIf()
該方法簽名為boolean removeIf(Predicate<? super E> filter),作用是刪除容器中所有滿足filter指定條件的元素,其中Predicate是一個函式介面,裡面只有一個待實現方法boolean test(T t),同樣的這個方法的名字根本不重要,因為用的時候不需要書寫這個名字。
需求:假設有一個字串列表,需要刪除其中所有長度大於3的字串。
我們知道如果需要在迭代過程衝對容器進行刪除操作必須使用迭代器,否則會丟擲ConcurrentModificationException,所以上述任務傳統的寫法是:
// 使用迭代器刪除列表元素
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
Iterator<String> it = list.iterator();
while(it.hasNext()){
if(it.next().length()>3) // 刪除長度大於3的元素
it.remove();
}現在使用removeIf()方法結合匿名內部類,我們可是這樣實現:
// 使用removeIf()結合匿名名內部類實現
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.removeIf(new Predicate<String>(){ // 刪除長度大於3的元素
@Override
public boolean test(String str){
return str.length()>3;
}
});上述程式碼使用removeIf()方法,並使用匿名內部類實現Precicate介面。相信你已經想到用Lambda表示式該怎麼寫了:
// 使用removeIf()結合Lambda表示式實現
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.removeIf(str -> str.length()>3); // 刪除長度大於3的元素使用Lambda表示式不需要記憶Predicate介面名,也不需要記憶test()方法名,只需要知道此處需要一個返回布林型別的Lambda表示式就行了。
replaceAll()
該方法簽名為void replaceAll(UnaryOperator<E> operator),作用是對每個元素執行operator指定的操作,並用操作結果來替換原來的元素。其中UnaryOperator是一個函式介面,裡面只有一個待實現函式T apply(T t)。
需求:假設有一個字串列表,將其中所有長度大於3的元素轉換成大寫,其餘元素不變。
Java7及之前似乎沒有優雅的辦法:
// 使用下標實現元素替換
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
for(int i=0; i<list.size(); i++){
String str = list.get(i);
if(str.length()>3)
list.set(i, str.toUpperCase());
}使用replaceAll()方法結合匿名內部類可以實現如下:
// 使用匿名內部類實現
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.replaceAll(new UnaryOperator<String>(){
@Override
public String apply(String str){
if(str.length()>3)
return str.toUpperCase();
return str;
}
});上述程式碼呼叫replaceAll()方法,並使用匿名內部類實現UnaryOperator介面。我們知道可以用更為簡潔的Lambda表示式實現:
// 使用Lambda表示式實現
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.replaceAll(str -> {
if(str.length()>3)
return str.toUpperCase();
return str;
});sort()
該方法定義在List介面中,方法簽名為void sort(Comparator<? super E> c),該方法根據c指定的比較規則對容器元素進行排序。Comparator介面我們並不陌生,其中有一個方法int compare(T o1, T o2)需要實現,顯然該介面是個函式介面。
需求:假設有一個字串列表,按照字串長度增序對元素排序。
由於Java7以及之前sort()方法在Collections工具類中,所以程式碼要這樣寫:
// Collections.sort()方法
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
Collections.sort(list, new Comparator<String>(){
@Override
public int compare(String str1, String str2){
return str1.length()-str2.length();
}
});現在可以直接使用List.sort()方法,結合Lambda表示式,可以這樣寫:
// List.sort()方法結合Lambda表示式
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.sort((str1, str2) -> str1.length()-str2.length());spliterator()
方法簽名為Spliterator<E> spliterator(),該方法返回容器的可拆分迭代器。從名字來看該方法跟iterator()方法有點像,我們知道Iterator是用來迭代容器的,Spliterator也有類似作用,但二者有如下不同:
Spliterator既可以像Iterator那樣逐個迭代,也可以批量迭代。批量迭代可以降低迭代的開銷。Spliterator是可拆分的,一個Spliterator可以通過呼叫Spliterator<T> trySplit()方法來嘗試分成兩個。一個是this,另一個是新返回的那個,這兩個迭代器代表的元素沒有重疊。
可通過(多次)呼叫Spliterator.trySplit()方法來分解負載,以便多執行緒處理。
stream()和parallelStream()
stream()和parallelStream()分別返回該容器的Stream視圖表示,不同之處在於parallelStream()返回並行的Stream。Stream是Java函數語言程式設計的核心類,我們會在後面章節中學習。
Map中的新方法
相比Collection,Map中加入了更多的方法,我們以HashMap為例來逐一探祕。瞭解Java7HashMap實現原理,將有助於理解下文。
forEach()
該方法簽名為void forEach(BiConsumer<? super K,? super V> action),作用是對Map中的每個對映執行action指定的操作,其中BiConsumer是一個函式介面,裡面有一個待實現方法void accept(T t, U u)。BinConsumer介面名字和accept()方法名字都不重要,請不要記憶他們。
需求:假設有一個數字到對應英文單詞的Map,請輸出Map中的所有對映關係.
Java7以及之前經典的程式碼如下:
// Java7以及之前迭代Map
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
for(Map.Entry<Integer, String> entry : map.entrySet()){
System.out.println(entry.getKey() + "=" + entry.getValue());
}使用Map.forEach()方法,結合匿名內部類,程式碼如下:
// 使用forEach()結合匿名內部類迭代Map
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.forEach(new BiConsumer<Integer, String>(){
@Override
public void accept(Integer k, String v){
System.out.println(k + "=" + v);
}
});上述程式碼呼叫forEach()方法,並使用匿名內部類實現BiConsumer介面。當然,實際場景中沒人使用匿名內部類寫法,因為有Lambda表示式:
// 使用forEach()結合Lambda表示式迭代Map
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.forEach((k, v) -> System.out.println(k + "=" + v));
}getOrDefault()
該方法跟Lambda表示式沒關係,但是很有用。方法簽名為V getOrDefault(Object key, V defaultValue),作用是按照給定的key查詢Map中對應的value,如果沒有找到則返回defaultValue。使用該方法程式設計師可以省去查詢指定鍵值是否存在的麻煩.
需求;假設有一個數字到對應英文單詞的Map,輸出4對應的英文單詞,如果不存在則輸出NoValue
// 查詢Map中指定的值,不存在時使用預設值
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
// Java7以及之前做法
if(map.containsKey(4)){ // 1
System.out.println(map.get(4));
}else{
System.out.println("NoValue");
}
// Java8使用Map.getOrDefault()
System.out.println(map.getOrDefault(4, "NoValue")); // 2putIfAbsent()
該方法跟Lambda表示式沒關係,但是很有用。方法簽名為V putIfAbsent(K key, V value),作用是隻有在不存在key值的對映或對映值為null時,才將value指定的值放入到Map中,否則不對Map做更改.該方法將條件判斷和賦值合二為一,使用起來更加方便.
remove()
我們都知道Map中有一個remove(Object key)方法,來根據指定key值刪除Map中的對映關係;Java8新增了remove(Object key, Object value)方法,只有在當前Map中key正好對映到value時才刪除該對映,否則什麼也不做.
replace()
在Java7及以前,要想替換Map中的對映關係可通過put(K key, V value)方法實現,該方法總是會用新值替換原來的值.為了更精確的控制替換行為,Java8在Map中加入了兩個replace()方法,分別如下:
replace(K key, V value),只有在當前Map中key的對映存在時才用value去替換原來的值,否則什麼也不做.replace(K key, V oldValue, V newValue),只有在當前Map中key的對映存在且等於oldValue時才用newValue去替換原來的值,否則什麼也不做.
replaceAll()
該方法簽名為replaceAll(BiFunction<? super K,? super V,? extends V> function),作用是對Map中的每個對映執行function指定的操作,並用function的執行結果替換原來的value,其中BiFunction是一個函式介面,裡面有一個待實現方法R apply(T t, U u).不要被如此多的函式介面嚇到,因為使用的時候根本不需要知道他們的名字.
需求:假設有一個數字到對應英文單詞的Map,請將原來對映關係中的單詞都轉換成大寫.
Java7以及之前經典的程式碼如下:
// Java7以及之前替換所有Map中所有對映關係
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
for(Map.Entry<Integer, String> entry : map.entrySet()){
entry.setValue(entry.getValue().toUpperCase());
}使用replaceAll()方法結合匿名內部類,實現如下:
// 使用replaceAll()結合匿名內部類實現
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.replaceAll(new BiFunction<Integer, String, String>(){
@Override
public String apply(Integer k, String v){
return v.toUpperCase();
}
});上述程式碼呼叫replaceAll()方法,並使用匿名內部類實現BiFunction介面。更進一步的,使用Lambda表示式實現如下:
// 使用replaceAll()結合Lambda表示式實現
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.replaceAll((k, v) -> v.toUpperCase());簡潔到讓人難以置信.
merge()
該方法簽名為merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction),作用是:
- 如果
Map中key對應的對映不存在或者為null,則將value(不能是null)關聯到key上; - 否則執行
remappingFunction,如果執行結果非null則用該結果跟key關聯,否則在Map中刪除key的對映.
引數中BiFunction函式介面前面已經介紹過,裡面有一個待實現方法R apply(T t, U u).
merge()方法雖然語義有些複雜,但該方法的用方式很明確,一個比較常見的場景是將新的錯誤資訊拼接到原來的資訊上,比如:
map.merge(key, newMsg, (v1, v2) -> v1+v2);compute()
該方法簽名為compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction),作用是把remappingFunction的計算結果關聯到key上,如果計算結果為null,則在Map中刪除key的對映.
要實現上述merge()方法中錯誤資訊拼接的例子,使用compute()程式碼如下:
map.compute(key, (k,v) -> v==null ? newMsg : v.concat(newMsg));computeIfAbsent()
該方法簽名為V computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction),作用是:只有在當前Map中不存在key值的對映或對映值為null時,才呼叫mappingFunction,並在mappingFunction執行結果非null時,將結果跟key關聯.
Function是一個函式介面,裡面有一個待實現方法R apply(T t).
computeIfAbsent()常用來對Map的某個key值建立初始化對映.比如我們要實現一個多值對映,Map的定義可能是Map<K,Set<V>>,要向Map中放入新值,可通過如下程式碼實現:
Map<Integer, Set<String>> map = new HashMap<>();
// Java7及以前的實現方式
if(map.containsKey(1)){
map.get(1).add("one");
}else{
Set<String> valueSet = new HashSet<String>();
valueSet.add("one");
map.put(1, valueSet);
}
// Java8的實現方式
map.computeIfAbsent(1, v -> new HashSet<String>()).add("yi");使用computeIfAbsent()將條件判斷和新增操作合二為一,使程式碼更加簡潔.
computeIfPresent()
該方法簽名為V computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction),作用跟computeIfAbsent()相反,即,只有在當前Map中存在key值的對映且非null時,才呼叫remappingFunction,如果remappingFunction執行結果為null,則刪除key的對映,否則使用該結果替換key原來的對映.
這個函式的功能跟如下程式碼是等效的:
// Java7及以前跟computeIfPresent()等效的程式碼
if (map.get(key) != null) {
V oldValue = map.get(key);
V newValue = remappingFunction.apply(key, oldValue);
if (newValue != null)
map.put(key, newValue);
else
map.remove(key);
return newValue;
}
return null;總結
- Java8為容器新增一些有用的方法,這些方法有些是為完善原有功能,有些是為引入函數語言程式設計,學習和使用這些方法有助於我們寫出更加簡潔有效的程式碼.
- 函式介面雖然很多,但絕大多數時候我們根本不需要知道它們的名字,書寫Lambda表示式時型別推斷幫我們做了一切.
相關推薦
【轉載】Lambda表示式和Java集合框架
Java8為容器新增一些有用的方法,這些方法有些是為完善原有功能,有些是為引入函數語言程式設計(Lambda表示式),學習和使用這些方法有助於我們寫出更加簡潔有效的程式碼.本文分別以ArrayList和HashMap為例,講解Java8集合框架(Java Collec
Lambda表示式和Java集合框架
Java8為容器新增一些有用的方法,這些方法有些是為完善原有功能,有些是為引入函數語言程式設計(Lambda表示式),學習和使用這些方法有助於我們寫出更加簡潔有效的程式碼.本文分別以ArrayList和HashMap為例,講解Java8集合框架(Java Collections Framework)中新加入
Java集合框架的接口和類層次關系結構圖
fly tsv nsh ats cap war sdc groovy fmb %E7%94%A8groovy%E8%84%9A%E6%9C%AC%E8%BF%9B%E8%A1%8C%E6%AF%8F%E6%97%A5%E5%B7%A5%E4%BD%9C%E7%9A%84%E
Java集合框架上機練習題:編寫一個Book類,該類至少有name和price兩個屬性。該類要實現Comparable接口,在接口的compareTo()方法.....
ext .cn 數據庫 識別 方法 屬性 set package compareto 編寫一個Book類,該類至少有name和price兩個屬性。該類要實現Comparable接口,在接口的compareTo()方法中規定兩個Book類實例的大小關系為二者的price屬性的
java集合框架:淺談如何使用LInkedList實現隊列(Queue)和堆棧(Stack)
ets pop pri ring uname tac print str sys Java中的LinkedList?是采用雙向循環列表實現的。利用LinkedList?可以實現棧(stack)、隊列(queue) 下面寫兩個例子學生類:int stuId; public i
5.Java集合框架剖析 之 Hashset和LinkedHashSet原始碼剖析
1 package java.util; 2 3 import java.io.InvalidObjectException; 4 import sun.misc.SharedSecrets; 5 6 public class HashSet<E> extends
Java 知識點整理-11.Java集合框架 Set+HashSet+LinkedHashSet+TreeSet+List和Set迭代方式的區別
目錄 Set HashSet LinkedHashSet TreeSet List和Set迭代方式的區別: Set 1、Set集合概述及特點: public interface Set<E> extends Collection<E>
Java 知識點整理-10.Java集合框架 去除ArrayList中重複字串、自定義物件 棧和佇列 泛型 JDK5新特性 asList() toArray(T[] a) ArrayList迴圈巢狀
詳細標題:去除ArrayList中重複字串、自定義物件元素方式 棧和佇列 泛型 JDK5新特性(增強for迴圈 三種迭代(普通for、迭代器、增強for)中的元素能否刪除 靜態匯入 可變引數)Arrays工具類的asList() Collection中toArray(T[] a) 集合巢狀之Arra
java集合框架第二記LinkedHashSet和LinkHashMap及類的學習方法
昨天CSDN維護,儲存的草稿又不見了,所以今天補上;不過又比較懶,就把兩個合在一塊寫了。 首先是類的學習方法,首先了解類的使用。LinkedHashSet和LinkedHashMap的使用和之前的差不多,都是使用.add()或者.put()等等,但是細節不一樣。在學習中瞭解
java Lambda表示式 和
https://colobu.com/2016/03/02/Java-Stream/ https://blog.csdn.net/IO_Field/article/details/54971761 http://www.runoob.com/java/java8-streams.
java集合框架:淺談如何使用LInkedList實現佇列(Queue)和堆疊(Stack)
Java中的LinkedList 是採用雙向迴圈列表實現的。 利用LinkedList 可以實現棧(stack)、佇列(queue) 感興趣的可以加群:854393687 下面寫兩個例子 學生類: int stuId; public int getStuId()
java:集合框架(ArrayList儲存字串和自定義物件並遍歷泛型版)
A:案例演示 * ArrayList儲存字串並遍歷泛型版 import java.util.ArrayList; import java.util.Iterator; import com.
java:集合框架(可變引數的概述和使用)
* A:可變引數概述 * 定義方法的時候不知道該定義多少個引數 * B:格式 * 修飾符 返回值型別 方法名(資料型別… 變數名){} * C:注意事項: * 這裡的變數其實是
java:集合框架(Arrays工具類的asList()方法的使用)-陣列和集合互轉
import java.util.ArrayList; import java.util.Arrays; import java.util.List; //陣列轉集合,雖然不能增加或刪除元素,但是可以集
java:集合框架(TreeSet保證元素唯一和比較器排序的原理及程式碼實現)
* A:案例演示 * TreeSet保證元素唯一和比較器排序的原理及程式碼實現 按照字串長度排序 重寫了Comparator介面中的方法 class CompareByLen implem
java:集合框架(LinkedHashMap的概述和使用)
import java.util.HashMap; import java.util.LinkedHashMap; import com.heima.bean.Student; public clas
java:集合框架(HashMap和Hashtable的區別)
* HashMap和Hashtable的區別 * Hashtable是JDK1.0版本出現的,是執行緒安全的,效率低,HashMap是JDK1.2版本出現的,是執行緒不安全的,效率高
java:集合框架(Collections工具類的概述和常見方法講解)
public static <T> void sort(List<T> list) 排序-示列程式碼: import java.util.ArrayList; import
Collections.sort()方法和lambda表示式結合實現集合的排序
1.使用Collections.sort()實現集合的排序,這裡的方法具體指的是: Collections.sort(List list, Compatator c) 第一個引數:為要進行排序的集合。 第二個引數:Compatator的實現,指定排序的方式。 2
Java8新特性 利用流和Lambda表示式對List集合進行處理
Lambda表示式處理List 最近在做專案的過程中經常會接觸到 lambda 表示式,隨後發現它基本上可以替代所有 for 迴圈,包括增強for迴圈。也就是我認為,絕大部分的for迴圈都可以用 lambda 表示式改寫。 lambda表示式有它自己的優點:(1)簡潔,(2)易平行計算。尤其適用於遍歷結果