
python txt檔案處理
輸入為:
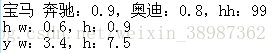
要求輸出為:

程式碼:
file = open('test.txt','rb') file_context = file.read().decode('utf-8') #print ("整個檔案內容:", file_context)#寫檔案 outdata = open('test1.txt', 'w', encoding="utf-8") # 以換行符為分隔符,從而將這個檔案以行為單位進行分割 line = file_context.split('\n') for i in range(0, len(line)): #讀取每一行 line_context = line[i] # print ("line_context:", line_context) 寶馬 賓士:0.9,奧迪:0.8,hh:99# 先以 ,為分割符進行分割 line_context_split = line_context.split(',') #print(line_context_split)['\ufeff寶馬 賓士:0.9', '奧迪:0.8', 'hh:99\r'] #將寶馬取出來 first_split = line_context_split[0].split(" ") first = first_split[0] # print ("first:", first) 寶馬 for j in range(0, len(line_context_split)): # print (j, line_context_split[j])#['\ufeff寶馬 賓士:0.9', '奧迪:0.8', 'hh:99\r'] if j == 0: if "" in line_context_split[j] and ":" in line_context_split[j]: string = line_context_split[j].replace(" ", "\t").replace(":","\t") outdata.write(string+'\n') elif j >= 1: if":" in line_context_split[j]: line_context_split[j] = line_context_split[j].replace(":","\t") string = first + "\t"+ line_context_split[j] outdata.write(string+'\n')
檔案讀取的時候是全文讀取,效率低下,使用按行讀取會出現空行,用另一段程式碼將空行刪除。
file = open('test.txt',encoding='utf-8') #print ("整個檔案內容:", file_context) #print ("--------------------------------") #寫檔案 outdata = open('test1.txt', 'w', encoding="utf-8") # 以換行符為分隔符,從而將這個檔案以行為單位進行分割 for line in file.readlines(): #讀取每一行 #line_context = str(line) #為分割符進行分割 line_context_split = line.split(',') #print(line_context_split)['\ufeff寶馬 賓士:0.9', '奧迪:0.8', 'hh:99\r'] #將寶馬取出來 first_split = line_context_split[0].split(" ") first = first_split[0] # print ("first:", first) 寶馬 for j in range(0, len(line_context_split)): # print (j, line_context_split[j]) #['\ufeff寶馬 賓士:0.9', '奧迪:0.8', 'hh:99\r'] if j == 0: if "" in line_context_split[j] and ":" in line_context_split[j]: string = line_context_split[j].replace(" ", "\t").replace(":","\t") outdata.write(string+'\n') elif j >= 1: if ":" in line_context_split[j]: line_context_split[j] = line_context_split[j].replace(":","\t") string = first + "\t"+ line_context_split[j] outdata.write(string+'\n')
刪除空行程式碼:
# coding:utf-8 def delblankline(infile, outfile): infp = open(infile, "r",encoding='utf-8') outfp = open(outfile, "w",encoding='utf-8') lines = infp.readlines() for li in lines: if li.split(): outfp.writelines(li) infp.close() outfp.close() # 呼叫示例 if __name__ == "__main__": delblankline("test1.txt", "2.txt")
相關推薦
python txt檔案處理
輸入為:要求輸出為:程式碼:file = open('test.txt','rb') file_context = file.read().decode('utf-8') #print ("整個檔案內容:", file_context)#寫檔案 outdata = open(
python:檔案處理之TXT
檔案讀寫 1、讀寫檔案是最常見的IO操作。Python內建了讀寫檔案的函式,用法和C是相容的。 2、讀寫檔案前,我們先必須瞭解一下,在磁碟上讀寫檔案的功能都是由作業系統提供的,現代作業系統不允許普通的程式直接操作磁碟,所以,讀寫檔案就是請求作業系統開啟一個檔案物件(通常稱
Python 關於txt檔案處理
Python 處理txt檔案 1.TXT讀取: path = '/home/0_1.txt' file1 = open(path) read1 = file1.read() print(read1) 2.將TXT內容轉化為array TXT的大小是24*24,轉化為一維向量1*
python .txt檔案讀取及資料處理總結
1、處理包含資料的檔案 最近利用Python讀取txt檔案時遇到了一個小問題,就是在計算兩個np.narray()型別的陣列時,出現了以下錯誤: TypeError: ufunc 'subtract' did not contain a loop wi
python配置檔案處理模組
import configparser class ReadConfig: '''read config file''' def read_config(self,file_path,section,option): cf = configparser.Co
python txt檔案常用讀寫操作
檔案的開啟的兩種方式 f = open("data.txt","r") #設定檔案物件 f.close() #關閉檔案 #為了方便,避免忘記close掉這個檔案物件,可以用下面這種方式替代 with open('data.txt',"r") as f: #
python txt檔案轉換乘excel檔案(轉)
#!/bin/env python # -*- encoding: utf-8 -*- #------------------------------------------------------------------------------- # Pu
python txt檔案轉列表、字典型別
Caltech-UCSD Birds-200-2011資料集類別資訊轉換成列表和字典形式 # 列表型別 f = open('classes.txt', 'r') re = [] for i in f.readlines(): lst = i.strip().spli
python處理行列分明的txt檔案
Rock_path="/media/gfq/dataset/Lakh MIDI Data/dataset/Rock.txt" 行列明顯分離: with open(Rock_path) as f: Rock=[line.split() for line in f] 按行列讀取你需要
利用Python requests庫從網上下載txt檔案時多出一個CR的處理
問題描述 讀1 的Reading word lists小節時,發現需要從thinkpython2/code/words.txt上下載words.txt檔案。我不想利用複製-貼上的方法構造該檔案,想到之前學過的爬蟲技術,於是寫下如下程式碼: import requests r =
python處理txt檔案的一種情況
在txt文字中,以換行符作為標記分段處理txt檔案中的內容的方法: with open(path, 'r', encoding='utf-8') as f: for line in f: if line!='\n': print(line
python處理txt檔案
需求: 給一個txt檔案,經過程式處理後,生成目標txt檔案 例如: 原檔案內容如下: 商戶號|終端號|交易型別|交易子型別|總筆數|總金額|總手續費|清算時間 1201603|38554|04317|00|13|0.31|2.40|2018-01-15 商戶號|終端號|交
python 處理excel檔案、txt檔案
處理excel檔案的python庫有很多,如xlsxwriter、xlrd、openpyxl等。由於經常用pandas處理資料,而且pandas讀寫excel更方便,所以主要講pandas是如何操作excel的。也介紹瞭如何分別使用用xlsxwriter和ope
python讀寫txt檔案中文字元的處理
最近一個專案,需要儲存中文字元和數字英文字母等到txt檔案中,使用的python2.7,說實話,python2的編碼問題真是個大坑! 花了半上午才解決問題,這裡簡單的總結一下。 python開啟txt檔案預設的是ascii編碼,是無法處理中文字元的,所以需要統一轉換為ut
Python實現讀取多個/批量txt檔案合併成一個txt(示例為tcga資料處理)
本程式 功能:將tcga資料的批量txt檔案合併成一個txt原始的第一個txt(代表一個病人)的資料內容 合併之後的txt資料,基因名不變,只是把病人的表達量收集到一起 操作說明:本人測試通過的執行環境:Python 2.7 Windows 7 64bit cmd命令執行
python批量處理txt檔案,為每行資訊追加內容
環境:python3.7。軟體下載自官網,安裝過程參考 廖雪峰的python教程。不過按照其教程安裝,報了api-win-msc-crt-runtime丟失的問題。 後續,我直接到官網下載,以及百度解決問題。具體參考哪個文件,找不到了。 這裡只展示自己寫的簡單指令碼:
Python讀寫txt檔案時的編碼問題
這個問題來自於一個小夥伴,他在處理中文資料時需要先把裡面的文字過濾然後分詞,因為裡面有許多符號,不僅是中文標點符號,還有✳,emoji等奇怪的符號。 正常情況下,中文的str經過encode('utf-8')變成bytes,然後bytes經過decode('utf-8')變回中文。 原始檔案是
第二篇 Python資料型別、字元編碼、檔案處理
一、引子 1、什麼是資料? x=10,10是我們要儲存的資料 2、為何資料要分不同的型別
Python建立檔案報錯OSError:[Errno 22] Invalid argument處理
問題: windows平臺下使用python open函式w模式開啟檔案報錯“OSError: [Errno 22] Invalid argument: '../news/“消費升維”成零售業新風口?渠道多元同步跟進.txt'” 解決: 本來猜測是轉義
Python從txt檔案中逐行讀取資料
Python從txt檔案中逐行讀取資料 # -*-coding:utf-8-*- import os for line in open("./samples/label_val.txt"): print('line=', line, end = '') #後面