
使用java語言中的註解生成器生成程式碼
Code Generation using Annotation Processors in the Java language – part 1: Annotation Types 註解型別
這篇帖子我會開始關於使用java語言中註解處理器來程式碼生成系列文章,它是多麼強大,並在最後展示如何在編譯時使用它們生成程式碼。
在這個系列中會:
- 介紹java中什麼是註解
- 瞭解註解的公共使用和它的範圍
- 瞭解什麼是註解處理器以及它的定義角色
- 學習如何建立註解處理器
- 學習如何通過命令列,Eclipse,Maven執行註解處理器
- 學習如何使用註解處理器生成程式碼
- 學習如何利用一個外部的模板引擎Apache Velocity使用註解處理器生成程式碼
java的註解是在java語言規範第三版中介紹到的,並且在java 5中第一次實現。
通過使用註解,我們能夠新增metadata元資料到我們的原始碼中,如構建或釋出資訊,配置屬性,編譯行為或者質量檢測。
與javadocs不同,註解是強型別,任何一個註解在classpath中都有一個對應的定義好的註解型別。此外,註解可以被定義為執行時可用,但是javadocs絕對不行。
註解語法
註解通常會出現在被註解程式碼段的前面,通常在自己的行,縮排到同一位置。
註解可用於包,型別(classes、interfaces、enums、annotation types),變數(class、instance and local變數–包括定義在for或者while迴圈中的變數),建構函式,方法,引數。
沒有任何元素的註解
@Override()
public void theMethod() {…}在這種情況,括號可以省略
@Override
public void theMethod() {…}註解也可以包含元素,只是name-value對,被逗號隔開。支援基本型別,字串,列舉和陣列
@Author(name = "Albert",
created = "17/09/2010",
revision = 3,
reviewers = {"George", "Fred" 當註解只有一個元素並且它的name是value的話,name可以省略
@WorkProduct("WP00000182")
@Complexity(ComplexityLevel.VERY_SIMPLE)
public class SimpleAnnotationsTest {…}註釋可以為某些或全部元素定義預設值。具有預設值的元素可以從註釋宣告中省略。
例如,假設註解型別的作者定義revision的預設值是1和reviewers的預設值是空的字串陣列,下面兩個註解申明是等價的。
@Author(name = "Albert",
created = "17/09/2010",
revision = 1,
reviewers = {})
public class SimpleAnnotationsTest() {…}
@Author(name = "Albert", // defaults are revision 1
created = "17/09/2010") // and no reviewers
public class SimpleAnnotationsTest() {…}註解的典型用途
在java語言規範(JLS)中定義了三個註解型別,它們被java編譯器使用:
@Deprecated: 表明它標記的元素不應該被使用。當該標記的元素被使用的任何時候編譯器會生成一個警告⚠️。它應該被javadoc沿用 @deprecated,保留在javadoc來解釋
deprecated的動機。@Override: 表明該元素是override了一個在父類中生命的元素。當編譯器發現標記的元素並沒有override任何元素,會生成一個警告⚠️。雖然它不是必須的,但是可以檢查錯誤。
@SuppressWarnings 表明編譯器應該Suppress一些指定的警告⚠️。
以下都可以看到很棒的例子:
- Java Enterprise Edition and its main components – Enterprise JavaBeans, Java Persistence API or Web Services API’s
- Spring Framework 被充分用於配置,依賴注入,以及控制反轉在該框架的核心以及spring的其他專案中
- Seam, Weld, Guice
- Apache Struts 2
註解型別
註解型別是用來定義自定義註解的特定介面
一個註解型別定義是使用@interface來替換interface
public @interface Author {
String name();
String created();
int revision() default 1;
String[] reviewers() default {};
}
public @interface Complexity {
ComplexityLevel value() default ComplexityLevel.MEDIUM;
}
public enum ComplexityLevel {
VERY_SIMPLE, SIMPLE, MEDIUM, COMPLEX, VERY_COMPLEX;
}註解型別與常規的介面有一些不同:
- 只允許是基本資料型別、字串、列舉、class類和陣列。注意Object一般是不允許的,陣列的陣列是不允許的(因為每一個數組是個Object)。
- 註釋元素的定義非常像一個method,但是記住修飾符和引數是不允許的。
- 定義預設值時使用
default關鍵字跟在value後面。
在任何類和介面中,一個列舉型別可以巢狀在註解型別定義中
public @interface Complexity {
public enum Level {
VERY_SIMPLE, SIMPLE, MEDIUM, COMPLEX, VERY_COMPLEX;
}
…用來定義註解的註解
JDK自帶的一些註解用來修改註解型別的行為:
- @Documented: 表示標記的註解型別每次找到的被註解元素通過javadoc文件化
@Inherited(繼承): 表示標記的註解型別會被子類也繼承。就是,如果被標記的註解並沒有出現,那它一定在父類中。該註解只適用類的繼承不適用介面的實現。
@Retention(保留): 表示被標記註解型別要保留到什麼時候。有以下幾種保留策略:
- CLASS 預設——包含在class檔案中,但是允許時不能訪問
- SOURCE 當建立class檔案時被編譯器丟棄
- RUNTIME 執行時可用
@Target: 表示該註解型別可以標註哪種元素。適用以下幾種元素型別:
- ANNOTATION_TYPE
- CONSTRUCTOR
- FIELD
- LOCAL_VARIABLE
- METHOD
- PACKAGE
- PARAMETER
- TYPE
Code Generation using Annotation Processors in the Java language – part 2: Annotation Processors 註解處理器
在第一部分中我們介紹了java語言中什麼是註解以及它們的基本使用。在第二部分中我們介紹註解處理器,如何構建它們以及如何執行它們
註解真的很贊。它具有定義良好的語法以及使用不同的型別來設定任何元資料或者配置。
從目前來看,與javadoc相比有優勢,但是還不足以證明它的作用。那麼有沒有可能與註解互動並獲取更多呢?當然是可以的。
- 在執行時,執行時保留策略的註解可以通過反射訪問。 在Class類中通過方法
getAnnotation()和getAnnotations()來完成。 - 在編譯時,註解處理器(Annotation Processors),一個專業的類,可以在編譯時程式碼裡找到的各種註解
註解處理器 API
當註解在java 5中被介紹的時候,註解處理器的API並沒有成熟或者標準化。在
com.sun.mirror釋出了一個獨立工具叫做apt(Annotation Processor Tool),可以用來寫自定義處理器來處理註解以及映象API(Mirror API)
從java 6開始,註解處理器已經通過JSR 269 (2)標註化,合併到了標準庫中並且無縫整合到了javac(Java Compiler Tool)中。
雖然我們只描述java 6中新的註解處理器API,但是你可以在這裡和這裡以及這篇文章的一個很好的例子,都是關於之前提到的apt以及java 5中的映象api。
一個註解處理器只不過是一個實現了javax.annotation.processing.Processor介面的類並遵守一些規定。javax.annotation.processing.AbstractProcessor提供的類抽象實現了公共方法,更方便自定義處理器。
自定義處理器可以使用三個註解來配置自己:
javax.annotation.processing.SupportedAnnotationTypes:該註解用來註冊處理器支援的註解。有效值是註解型別的完全限定名稱——支援萬用字元javax.annotation.processing.SupportedSourceVersion:該註解用來註冊註解處理器支援的source版本javax.annotation.processing.SupportedOptions:該註解用來註冊支援的自定義選項,可以通過命令列傳入
最後,我們提供自己對process()方法的實現。
寫自己的第一個註解處理器
根據第一部分的介紹,我們建立一個類來處理Complexity annotation。
package sdc.assets.annotations.processors;
import …
@SupportedAnnotationTypes("sdc.assets.annotations.Complexity")
@SupportedSourceVersion(SourceVersion.RELEASE_6)
public class ComplexityProcessor extends AbstractProcessor {
public ComplexityProcessor() {
super();
}
@Override
public boolean process(Set<? extends TypeElement> annotations,
RoundEnvironment roundEnv) {
return true;
}
}這是個不完整的類,當呼叫時不會做任何操作,被註冊支援註解型別是sdc.assets.annotations.Complexity。因此,每次當編譯器找到一個類被該型別註解就會執行該處理器,提供的process在classpath中可以用了。
為了與註解互動,process()方法接收兩個引數:
- 一個包含
java.lang.model.TypeElement物件的set集合:註解處理是在一輪或多輪後完成。在每一輪中,處理器被呼叫並接收在本輪需要被處理的註解型別。 - 一個
javax.annotation.processing.RoundEnvironment物件:通過該物件可以訪問本輪或前一輪被處理的被註解的資源元素。
處理這兩個引數,在processingEnv實力變數中有一個ProcessingEnvironment可以使用。該物件可以訪問log以及一些工具類。後面會討論一些。
使用RoundEnvironment物件以及Element介面的反射方法,我們寫一個簡單的處理器的實現,可以列印complexity每一個註解的元素。
for (Element elem : roundEnv.getElementsAnnotatedWith(Complexity.class)) {
Complexity complexity = elem.getAnnotation(Complexity.class);
String message = "annotation found in " + elem.getSimpleName()
+ " with complexity " + complexity.value();
processingEnv.getMessager().printMessage(Diagnostic.Kind.NOTE, message);
}
return true; // no further processing of this annotation type打包並註冊註解處理器
完成註解處理器的最後一步是打包並註冊它,讓java編譯器或者其他工具可以找到它。
註冊註解處理器的最簡單的方法是利用標準java服務鏈(standard Java services mechanism):
- 將註解處理器打入jar包中
- 包含在jar檔案目錄
META-INF/services下 - 在目錄下包含一個叫
javax.annotation.processing.Processor的檔案 - 在檔案中寫入處理器的全限定名,每行一個
java編譯器以及其他工具會在提供claspath中尋找這個檔案並使用註冊的處理器
在我們的例子中,資料夾結構如下


打包之後,我們開始使用它
通過javac執行處理器
想象一下你有一個java專案使用了一些自定義註解並且有相關的註解處理器。在java 5時,編譯和處理時兩個不同的步驟(使用兩個不同的工具),但是在java 6下所有任務都整合到java編譯器中(javac)。
如果你把註解處理器新增到javac classpath中並使用上面java服務鏈方式註冊,那它們可以被javac執行。
以下例子,命令會編譯並使用Complexity註解處理java原始檔
>javac -cp sdc.assets.annotations-1.0-SNAPSHOT.jar;
sdc.assets.annotations.processors-1.0-SNAPSHOT.jar
SimpleAnnotationsTest.java用來被測試的java類內容是:
package sdc.startupassets.annotations.base.client;
import ...
@Complexity(ComplexityLevel.VERY_SIMPLE)
public class SimpleAnnotationsTest {
public SimpleAnnotationsTest() {
super();
}
@Complexity() // this annotation type applies also to methods
// the default value 'ComplexityLevel.MEDIUM' is assumed
public void theMethod() {
System.out.println("consoleut");
}
}當執行javac命令後,輸入如下:
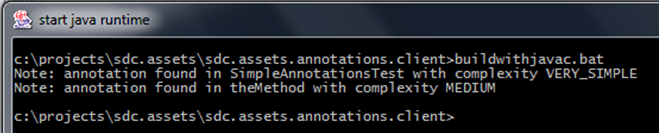
雖然預設的javac通常表現很好,不過還有一些選項能幫助我們執行註解處理器在更多情況。
- -Akey[=value]: 用來向處理器傳遞選項。只有通過
SupportedOptions註冊的選項才有用 - -proc:{none|only}:預設情況下,javac會執行註解處理器並編譯所有資源。
- proc:none 沒有註解處理完成,當你構建註解處理器本身時很有用
- proc:only 只有註解處理完成,當你執行校驗,如質量工具或標準檢查時很有用
- -processorpath path:用來指定註解處理器在哪以及去哪裡找依賴。清楚區分專案依賴和處理器依賴(在執行時並不需要的依賴)是很有用的。
- -s dir: 用來指定生產的程式碼放在哪裡。
- -processor class1[,class2,class3…]: 用來指定哪些處理器被執行。如果沒有會去尋找jva服務鏈提供的。當我們執行限制執行註冊處理器的一小部分時很有用。
通過Eclipse執行處理器
Eclipse IDE以及其他主流IDE都支援註解處理器並整合進了他們的常規構建過程中。
在Eclipse IDE中,當你訪問屬性配置時,你可以發現在Java Compiler group下,有一個叫Annotation Processing的選項。

啟用Annotation Processing(預設是關閉的),就可以通過選項頁的表格出入處理器了。
此外,可以通過Factory Path選項執行選擇的處理器。

只要配置一次,每次構建行為被觸發,就會執行註解處理了
通過Maven執行處理器
註解處理器也可以整合在Apache Maven構建中執行。
這種自動化水平,可以幫助我們無縫整合所以處理型別。標準驗證或者程式碼生成在整個專案生命週期中作為一個單獨的過程。它還可以通過連續整合引擎(Continuous Integration engines)無縫整合。
雖然把註解處理器整合到Maven構建中有很多方式,我們建議使用這裡描述的方式。描述基於Mojo(maven plug-in),Mojo是用來關注編譯任務。
整合Maven需要我們的註解和註解處理器作為Maven工件可用。
我們建議將註解和註解處理器分成不同的工件。因為註解處理器在其他客戶端專案不需要訪問,可以減少跨專案依賴的數量。
通過這種方法,我們設定三個不同的專案,對應每一個不同的Maven工件。
- 註解工件(Annotation artifact): 只包含註解型別
- 註解處理器工件(Annotation Processor artifact):包含註解處理器。他將依賴註解工件,編譯器外掛需要被設定成
proc:none所以在構建該工件時註解處理器不執行。 - 客戶端工程:包含了客戶端程式碼,它依賴上面兩個工件。
下面是註解工件的資料夾結構以及pom檔案

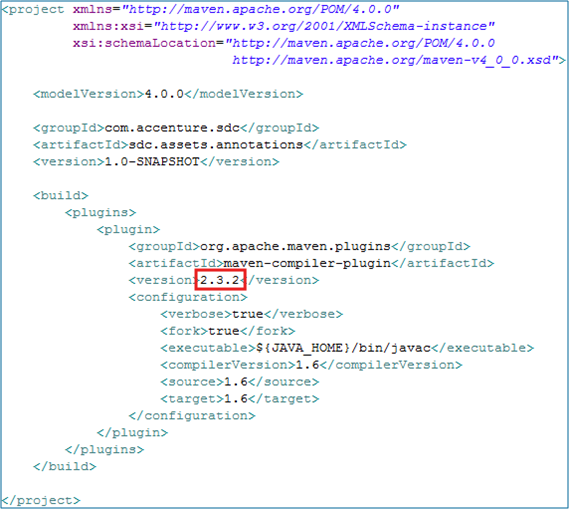
注意: Maven compiler plug-in的版本用來構建該工件
下面是註解處理器工件的資料夾結構以及pom檔案


注意:
- 打包處理器服務資料夾
- Maven compiler plug-in的版本
- proc:none選項
- 依賴註解工件
最後,是客戶端工程的資料夾結構和pom檔案
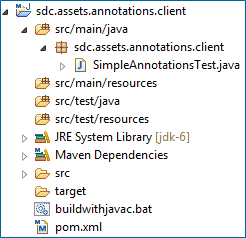

一旦做好,每次在Maven構建執行時,處理器也會按照預期執行。
Code Generation using Annotation Processors in the Java language – part 3: Generating Source Code 生成原始碼
第三部分我們將介紹如何誰用註解處理器生成原始碼
生成程式碼容易,生成對的程式碼就難了。並且用一個優雅又有效的方式是一件很麻煩的任務。
幸運的是,在過去幾年Model-Driven Engineering(MDE,模型驅動工程,有的引用是Model-Driven Development模型驅動開發或者Model-Driven Architecture,模型驅動架構)已經幫助發展成了一種成熟的技術。
Model-Drive Engineering(MDE)遠不止是生成程式碼,雖然我們認為它是MDE方法的自然切入點。
註解處理器就是我們可以用來生成原始碼工具之一。
在MDE中的模型和元模型
在進入如何使用註解處理器生成程式碼之前,我們想提出幾個概念:模型(model)和元模型(meta-model)
MDE的支柱之一是構造抽象(construction of abstractions)。我們給軟體系統建模(model),希望通過不同的方法來建立各個層次的細節。當一個抽象層被建模,我們進行下一層的建模,下一層再下一層,最後以一個完成的可部署的產品結束。
在這個背景下,無論我們使用多少層細節,一個模型只不過用來代表我們系統的抽象。
而meta-model則是我們用來編寫模型的規則。你可以把它理解為模型的scheme或者語義
使用註解處理器生成原始碼
如我們所見,註解是一個很棒的方式來定義一個meta-model並建立一個model。註解型別扮演meta-model的角色,一系列註解的程式碼扮演model的角色。
我們可以利用這個模型來生成配置檔案或者編寫被現有程式碼驅動的新的原始檔。比如:從一個被註解的物件建立一個遠端代理或者一個數據訪問物件。
這種方式的核心就是註解處理器。一個處理器可以讀在原始碼中找到的註解,提取這個模型,然後通過模型做任何我們想做的事(如:開啟一個檔案,傳入內容)。java編譯器會小心驗證模型。
過濾器(Filter)
在第二部分討論過,每個處理器可以訪問一些有用的工具。其中一個就是過濾器。
javax.annotation.processing.Filer介面定義了一些方法,可以建立原始檔,class檔案,或者通用資源。通過過濾器可以確保使用正確的目錄並且在我們的檔案系統中不會丟失生成的有用專案。
如果我們要寫生成器,-d和-s選項在javac或者在Maven pom檔案中配置是很重要的。
下文例子展示了在註解生成器中如何建立java原始檔。生成的class名字是被註解的class名字加上“BeanInfo”。
if (e.getKind() == ElementKind.CLASS) {
TypeElement classElement = (TypeElement) e;
PackageElement packageElement =
(PackageElement) classElement.getEnclosingElement();
JavaFileObject jfo = processingEnv.getFiler().createSourceFile(
classElement.getQualifiedName() + "BeanInfo");
BufferedWriter bw = new BufferedWriter(jfo.openWriter());
bw.append("package ");
bw.append(packageElement.getQualifiedName());
bw.append(";");
bw.newLine();
bw.newLine();
// rest of generated class contents不要像我兄弟一樣建立
上一個例子簡單有趣,但是很混亂。
我們將從註解獲取需要的資訊(model模組)和寫生成檔案的邏輯(view邏輯)混合在了一起。
用這種方式寫一個體面的生成器是很困難的。如果我們需要一些更復雜的任務是很麻煩,容易出錯且很難維護的。
因此,我們需要一個更優雅的方式:
- 將model和view明確分離
- 使用模板來減輕寫生成檔案的任務
我們來看看如何使用Apache Velocity來像我們想要的方式生成。
VELOCITY歷史簡介
Velocity,來自Apache Software Foundation的一個專案,是一個java的模板引擎,可以通過混合模板和java物件的資料生成所有型別的文字檔案。
Velocity在MVC模式下提供view或者作為將資料轉換成XML的XSLT的替代。
Velocity有它自己的語言,叫做Velocity Template Language (VTL)。這是生產豐富且易於閱讀的模板的關鍵。在VTL中,我們可以通過簡單且直觀的方式定義變數,控制流和迭代以及訪問java物件中包含的資訊。
以下是一個Velocity模板的片段:
#foreach($field in $fields)
/**
* Returns the ${field.simpleName} property descriptor.
*
* @return the property descriptor
*/
public PropertyDescriptor ${field.simpleName}PropertyDescriptor() {
PropertyDescriptor theDescriptor = null;
return theDescriptor;
}
#end
#foreach($method in $methods)
/**
* Returns the ${method.simpleName}() method descriptor.
*
* @return the method descriptor
*/
public MethodDescriptor ${method.simpleName}MethodDescriptor() {
MethodDescriptor descriptor = null;正如你所見,VTL是很簡單且容易理解的。粗體高亮的部分#foreach($field in $fields),你可以看到兩個典型的VTL構造:迭代一個物件集合和列印集合中找到的元素的一些屬性。
VELOCITY生成器的方法
現在我們決定使用VELOCITY來加強我們的生成器,我們需要按照以下的計劃重新設計。
- 編寫用於生成程式碼的模板
- 註解處理器會從round environment讀取被註解的元素,並且儲存在易於訪問的java物件中。一個map用於欄位(fields),一個map用於方法(methods),類和包名等等。
- 註解處理器將初始化Velocity上下文(context)
- 註解處理器將載入Velocity模板
- 註解處理器將創造原始檔(使用過濾器filter)並通過context向Velocity模板傳遞一個writer
- Velocity引擎將生成原始碼
通過這些步驟你會發現處理器/生成器程式碼很清楚,結構良好並且易於理解和維護。
我們來一步一步操作
Step1 :寫模板
為了簡單起見,我們不打算展示全部的BeanInfo生成器,只有建立我們處理器需要的欄位和方法。
讓我們建立一個檔案,名字叫beaninfo.vm,並將它放在Maven處理器工件的src/main/resources位置。以下是模板內容:
package ${packageName};
import java.beans.MethodDescriptor;
import java.beans.ParameterDescriptor;
import java.beans.PropertyDescriptor;
import java.lang.reflect.Method;
public class ${className}BeanInfo
extends java.beans.SimpleBeanInfo {
/**
* Gets the bean class object.
*
* @return the bean class
*/
public static Class getBeanClass() {
return ${packageName}.${className}.class;
}
/**
* Gets the bean class name.
*
* @return the bean class name
*/
public static String getBeanClassName() {
return "${packageName}.${className}";
}
/**
* Finds the right method by comparing name & number of parameters in the class
* method list.
*
* @param classObject the class object
* @param methodName the method name
* @param parameterCount the number of parameters
*
* @return the method if found, <code>null</code> otherwise
*/
public static Method findMethod(Class classObject, String methodName, int parameterCount) {
try {
// since this method attempts to find a method by getting all
// methods from the class, this method should only be called if
// getMethod cannot find the method
Method[] methods = classObject.getMethods();
for (Method method : methods) {
if (method.getParameterTypes().length == parameterCount
&& method.getName().equals(methodName)) {
return method;
}
}
} catch (Throwable t) {
return null;
}
return null;
}
#foreach($field in $fields)
/**
* Returns the ${field.simpleName} property descriptor.
*
* @return the property descriptor
*/
public PropertyDescriptor ${field.simpleName}PropertyDescriptor() {
PropertyDescriptor theDescriptor = null;
return theDescriptor;
}
#end
#foreach($method in $methods)
/**
* Returns the ${method.simpleName}() method descriptor.
*
* @return the method descriptor
*/
public MethodDescriptor ${method.simpleName}MethodDescriptor() {
MethodDescriptor descriptor = null;
Method method = null;
try {
// finds the method using getMethod with parameter types
// TODO parameterize parameter types
Class[] parameterTypes = {java.beans.PropertyChangeListener.class};
method = getBeanClass().getMethod("${method.simpleName}", parameterTypes);
} catch (Throwable t) {
// alternative: use findMethod
// TODO parameterize number of parameters
method = findMethod(getBeanClass(), "${method.simpleName}", 1);
}
try {
// creates the method descriptor with parameter descriptors
// TODO parameterize parameter descriptors
ParameterDescriptor parameterDescriptor1 = new ParameterDescriptor();
parameterDescriptor1.setName("listener");
parameterDescriptor1.setDisplayName("listener");
ParameterDescriptor[] parameterDescriptors = {parameterDescriptor1};
descriptor = new MethodDescriptor(method, parameterDescriptors);
} catch (Throwable t) {
// alternative: create a plain method descriptor
descriptor = new MethodDescriptor(method);
}
// TODO parameterize descriptor properties
descriptor.setDisplayName("${method.simpleName}(java.beans.PropertyChangeListener)");
descriptor.setShortDescription("Adds a property change listener.");
descriptor.setExpert(false);
descriptor.setHidden(false);
descriptor.setValue("preferred", false);
return descriptor;
}
#end
}注意:要讓這個模板起作用,我們需要給Velocity傳入以下資訊:
- packageName 生成類的全包名
- className 生成類的名字
- fields欄位 包含源class中欄位的集合
- simpleName 欄位的名字
- type 型別(例子中沒有用到)
- description 自己的解釋(例子中沒有用到)
…
methods 包含源class中方法的集合
- simpleName 方法的名字
- arguments 方法的引數(例子中沒有用到)
- returnType 返回型別(例子中沒有用到)
- description 自己的解釋(例子中沒有用到)
- …
所有這些資訊(model)會在源class中找到的註解提取出來,並存儲在javabean中傳遞給Velocity
Step 2: 讀取model的處理器
讓我們建立一個處理器而且不要忘記註解它來處理一個BeanInfo註解型別
@SupportedAnnotationTypes("example.annotations.beaninfo.BeanInfo")
@SupportedSourceVersion(SourceVersion.RELEASE_6)
public class BeanInfoProcessor
extends AbstractProcessor {process方法需要從註解和源class本身中提取建立model所需的資訊。你可以使用JavaBean儲存儘可能多的需要的資訊,但是在我們的例子中我們會用javax.lang.model.element型別,因為我們沒有機會向Velocity傳遞太多的細節(但是如果有必要,我們會建立一個完整的beaninfo生成器)。
String fqClassName = null;
String className = null;
String packageName = null;
Map<String, VariableElement> fields = new HashMap<String, VariableElement>();
Map<String, ExecutableElement> methods = new HashMap<String, ExecutableElement>();
for (Element e : roundEnv.getElementsAnnotatedWith(BeanInfo.class)) {
if (e.getKind() == ElementKind.CLASS) {
TypeElement classElement = (TypeElement) e;
PackageElement packageElement = (PackageElement) classElement.getEnclosingElement();
processingEnv.getMessager().printMessage(
Diagnostic.Kind.NOTE,
"annotated class: " + classElement.getQualifiedName(), e);
fqClassName = classElement.getQualifiedName().toString();
className = classElement.getSimpleName().toString();
packageName = packageElement.getQualifiedName().toString();
} else if (e.getKind() == ElementKind.FIELD) {
VariableElement varElement = (VariableElement) e;
processingEnv.getMessager().printMessage(
Diagnostic.Kind.NOTE,
"annotated field: " + varElement.getSimpleName(), e);
fields.put(varElement.getSimpleName().toString(), varElement);
} else if (e.getKind() == ElementKind.METHOD) {
ExecutableElement exeElement = (ExecutableElement) e;
processingEnv.getMessager().printMessage(
Diagnostic.Kind.NOTE,
"annotated method: " + exeElement.getSimpleName(), e);
methods.put(exeElement.getSimpleName().toString(), exeElement);
}
}Step 3: 初始化Velocity context並載入模板
以下程式碼片段展示瞭如何初始化Volecity context以及載入模板:
if (fqClassName != null) {
Properties props = new Properties();
URL url = this.getClass().getClassLoader().getResource("velocity.properties");
props.load(url.openStream());
VelocityEngine ve = new VelocityEngine(props);
ve.init();
VelocityContext vc = new VelocityContext();
vc.put("classNameassName);
vc.put("packageNameckageName);
vc.put("fieldselds);
vc.put("methodsthods);
Template vt = ve.getTemplate("beaninfo.vm");velocity配置檔案,在例子中叫velocity.properties,放置在src/main/resources資料夾下。例子的內容如下:
runtime.log.logsystem.class = org.apache.velocity.runtime.log.SystemLogChute
resource.loader = classpath
classpath.resource.loader.class = org.apache.velocity.runtime.resource.loader.ClasspathResourceLoader這裡為Velocity設定了一個log的屬性以及一個基於classpath的資源loader來尋找模板
Step 4:建立新的source並生成內容
最後,讓我們建立一個原始檔並使用這個新檔案作為目標執行模板。以下片段展示瞭如何操作:
JavaFileObject jfo = processingEnv.getFiler().createSourceFile(
fqClassName + "BeanInfo");
processingEnv.getMessager().printMessage(
Diagnostic.Kind.NOTE,
"creating source file: " + jfo.toUri());
Writer writer = jfo.openWriter();
processingEnv.getMessager().printMessage(
Diagnostic.Kind.NOTE,
"applying velocity template: " + vt.getName());
vt.merge(vc, writer);
writer.close();Step 5: 打包並執行
最後,註冊處理器(像在第二部分中service配置檔案那樣),打包並從客戶端的命令列、Eclipse或者Maven構建中呼叫
假設下面是客戶端類:
package example.velocity.client;
import example.annotations.beaninfo.BeanInfo;
@BeanInfo public class Article {
@BeanInfo private String id;
@BeanInfo private int department;
@BeanInfo private String status;
public Article() {
super();
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public int getDepartment() {
return department;
}
public void setDepartment(int department) {
this.department = department;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
@BeanInfo public void activate() {
setStatus("active");
}
@BeanInfo public void deactivate() {
setStatus("inactive");
}
}當我們javac命令出問題時,我們可以在終端中看到註解元素沒有找到和BeanInfo類被生成
Article.java:6: Note: annotated class: example.annotations.velocity.client.Article
public class Article {
^
Article.java:9: Note: annotated field: id
private String id;
^
Article.java:12: Note: annotated field: department
private int department;
^
Article.java:15: Note: annotated field: status
private String status;
^
Article.java:53: Note: annotated method: activate
public void activate() {
^
Article.java:59: Note: annotated method: deactivate
public void deactivate() {
^
Note: creating source file: file:/c:/projects/example.annotations.velocity.client/src/main/java/example/annotations/velocity/client/ArticleBeanInfo.java
Note: applying velocity template: beaninfo.vm
Note: example\annotations\velocity\client\ArticleBeanInfo.java uses unchecked or unsafe operations.
Note: Recompile with -Xlint:unchecked for details.如果我們檢查源目錄會找到期望的BeanInfo類,任務完成。
總結
通過這個系列,我們學習到了如何使用java6中的註解生成器框架來生成原始碼
- 我們學習了什麼是註解和註解型別以及他們的基本使用
- 我們學習了什麼是註解處理器,如何編寫他們以及使用不同的工具執行它,如java編譯器,Eclipse和Maven
- 我們討論一點Model-Drive Engineering和程式碼生成的事
- 我們展示瞭如何通過java編譯器,如何建立程式碼生成器並整合的
- 我們展示瞭如何利用現有的生成器框架如(Apache Velocity)來建立優雅,強大易於維護的程式碼生成器
現在是時候運用到你的專案中了,考慮生成。
相關推薦
Java語言使用註解處理器生成程式碼 —— 第一部分:註解型別
原文作者:deors 原文地址:https://deors.wordpress.com/2011/09/26/annotation-types/ 譯文作者:Jianan - [email protected] 版本資訊:本文基於
使用java語言中的註解生成器生成程式碼
Code Generation using Annotation Processors in the Java language – part 1: Annotation Types 註解型別 這篇帖子我會開始關於使用java語言中註解處理器來程式碼生
Java編譯時註解自動生成程式碼
在開始之前,我們首先申明一個非常重要的問題:我們並不討論那些在執行時(Runtime)通過反射機制執行處理的註解,而是討論在編譯時(Compile time)處理的註解。註解處理器是一個在javac中的,用來編譯時掃描和處理的註解的工具。可以為特定的註解,註冊自己的註解處
從原始碼到機器程式碼,Java語言中發生了什麼?
在上一篇文章中,我們討論了無論程式碼是用什麼語言編寫的,它最終都毫無例外地執行在機器程式碼中。那麼Java語言中發生了什麼,從原始碼到機器程式碼?這就是我們今天要討論的。 如下圖所示,編譯器可以分為前端編譯器、JIT編譯器和AOT編譯器。我們一個接一個地談吧。 前端編譯器:原始碼到位元
JAVA語言中的變量
方法調用 它的 同時 變量的作用域 調用 作用域 必須 數字 -s 1.變量 變量是一個代詞,指代內存中的數據。 變量是可以改變的量---->指代不同的數據。 2.變量的使用 變量必須先聲明後使用: 語法:數據類型 變量名; i
獲取Java類中註解的詳細信息
ons 信息 size pre stat .get 文件 mvc declare 前言:這篇博客主要是為了後續的獲取SpringMVC中的全部請求URL做的準備。 public class AnnotationHelper { private static fi
Java語言中的定義變量、構造函數
java中的類、變量、方法、構造函數的定義day02 Java語言中的定義類、變量、方法、構造函數一、概述: 在Java語言中,變量的定義和使用時非常常見和重要的;同時對後續的操作變量奠定基礎,在這裏定義和使用變量就要使用到我們前一節說到的數據類型了,它們兩個就是綁定在一起使用的。我們回顧一下前一節學的
Java語言中的---訪問說明符
java語言中的---訪問修飾符day03 Java語言中的-----訪問說明符一、訪問說明符的概述: 訪問說明符其實就是設置一個訪問權限,只有設置好這個訪問權限以後才能更好的封裝我們的一些變量或方法。所以學好這個說明符對我們後續學習Java的封裝功能很有幫助。二、訪問說明符: 1、訪問說明符有
Java語言中的----運算符
java語言中的-----運算符day05 Java語言中的----運算符一、運算符概述: 運算符的使用在每一門開發語言中都會使用到,在不同的語言中也會有不同的使用規則。通過運算符我們可以聯想到MySQL數據庫中的運算符,這些都是差不多的,可能有些在使用上是不一樣的。下面就來看看Java中的運算符。二、
Java語言中的----條件循環
java語言中的-----條件循環語句day06 Java語言中的條件循環一、條件循環概述: 條件循環對於我們來說一點也不陌生,在程序中使用循環語句是很普片的事兒,所以說你一定得學會循環語句。二、條件循環 條件循環主要包括兩個循環語句,分別是if...else和switch...case語句。
Java語言中的----數組
java語言中的----數組day07 Java語言中的--數組一、數組的概述: 什麽是數組?數組是幹什麽用的?為啥要學數組?這些都是疑問。再你學完數組以後就知道了,數組是存儲在相鄰內存位置的單一數據類型的元素集合。什麽是單一數據類型?就是在你定義數組的時候的數據類型,就只能存儲這一個類型的數組。那麽
Java語言中的----枚舉
java語言中的-----枚舉day08 Java語言中的----枚舉一、概述: 什麽是枚舉?枚舉有什麽作用?我們又如何來使用這個枚舉。其實枚舉就是不可變的一些成員變量,比如:春夏秋冬、年、十二個月、顏色等等。都是一些固定的常量值。是用來創建預定義列表。枚舉是和類是一個級別的。可以直接以類的方式來定義,
Java語言中的---字符串
java語言中的---string類day09 Java語言中的---字符串一、字符串概述: 字符串在程序中是一個非常重要的知識點,在處理一系列程序的時候都會定義一些字符串來使用。下面我們就來看看如何定義和使用一個字符串。二、字符串(String): 1、字符串的分類:字符串根據能否可以改變被分為
Java語言中的----繼承(一)
java語言中的----繼承(一)day10 Java語言中的繼承(一)一、繼承概述: 繼承:什麽是繼承,程序中的繼承與生活中的繼承還是有區別的,在程序中繼承以後,你的父類和你的子類同樣的也具有某一成員變量。那麽我們為什麽藥學習繼承?是因為我們在編程的時候我們會有大量的代碼需要重寫,從而導致我們代碼比較
Java語言中的----多態和異常處理
java語言中的----多態和異常處理day13 Java語言中的----多態和異常處理一、概述: 學習Java語言就要理解Java中的面向對象的四大特征:分別是封裝、抽象、繼承、多態。前面三個我們已經學完了,下面我們來學一下多態。什麽是多態?不明思議就是具有兩種形態性,一個方法可以定義兩種形態,這就是
java語言中的----正則表達式
java語言中的正則表達式day14 java語言中的----正則表達式一、概述: 正則表達式在Java語言中也算是一個比較重要的模塊,前面我們學習了一些關於正則表達式的基礎,在登錄註冊功能中使用比較廣泛,所以說在這兒我就不做多余的介紹。下面我們就通過一些實例來了解一下正則表達式,二、正則表達式:
Java語言中的泛型
數據 返回值 result public 部分 集合 操作 ava imp 一、泛型的概念及作用 1、泛型的概念 Java中的泛型是Java SE 1.5的新特性,泛型的本質是參數化類型,也就是說所操作的數據類型被指定為一個參數。 這種參數類型可以用在類
Java語言中的集合框架總結
鍵值 gen collect sort jdk1 pri 不能 map 刪除 一、集合框架 集合是ava語言中非常重要的API; 用來存儲多個數據; 實現了不同的數據結構。 三大接口: Collection:所有集合類的根接口;List、set是常用的子
day15 java語言中的-------泛型
day15 java 語言中的-----泛型day15 java語言中的-------泛型一、泛型概述: “泛型”這個概念大家可能有些陌生,其實不然,泛型直面意思你可以理解為多種數據類型、可變的數據類型、不同需求時的數據類型等等。在開發中,泛型的使用時很常見的,同時包含泛型類和泛型方法兩種。掌握好他們之
day17 java 語言中的---list集合
java day17 語言 day17 java 語言中的---List集合一: list集合概述: 在day16中已經講了一下具體的set集合,今天在這個基礎上在說一點list集合。主要包含有“ArrayList集合”和“linkedlist集合”以及“vector集合”,但是目前我們主要