
大資料-03-Spark入門
Spark 簡介
行業廣泛使用Hadoop來分析他們的資料集。原因是Hadoop框架基於一個簡單的程式設計模型(MapReduce)。這裡,主要關注的是在處理大型資料集時在查詢之間的等待時間和執行程式的等待時間方面保持速度。
Hadoop只是實現Spark的方法之一。Spark以兩種方式使用Hadoop - 一個是儲存,另一個是處理。由於Spark具有自己的叢集管理計算,因此它僅使用Hadoop進行儲存。
Apache Spark是一種快速的叢集計算技術,專為快速計算而設計。它基於Hadoop MapReduce,它擴充套件了MapReduce模型,以有效地將其用於更多型別的計算,包括互動式查詢和流處理。 Spark的主要特性是它的記憶體中叢集計算
Spark安裝
安裝Hadoop
在大資料-01-安裝Hadoop中, 我們已經安裝好了Hadoop 2.7叢集, 現在我們開始安裝Spark, 因為我在上文中裝的是jdk7,然而新的Spark需要JDK8,所有我們升級到JDK8:
# 在叢集所有機器上,備份原JDK7 sudo mv /usr/local/java/jdk1.7.0_75 /usr/local/java/jdk1.7.0_75_bak # 安裝JDK 8 sudo apt-get install openjdk-8-jdk # 安裝成功後 java -version # 會顯示java 1.8版本號 # 更新hadoop環境配置, # hadoop_env.sh修改export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 sudo vim /usr/local/hadoop/etc/hadoop/hadoop_env.sh # 修改了全域性配置 # profile修改export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 sudo vim /etc/profile
安裝Scala
安裝Spark
sudo mkdir /usr/local/spark
sudo mv spark-2.3.0-bin-hadoop2.7.tgz /usr/local/spark
cd /usr/local/spark/
sudo tar -zxf spark-2.3.0-bin-hadoop2.7.tgz 新增環境變數
sudo vim ~/.bashrc新增內容如下:
export SCALA_HOME=/usr/local/scala/scala-2.10.7
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export SPARK_HOME=/usr/local/spark/spark-2.3.0-bin-hadoop2.7
export PATH=${SPARK_HOME}/sbin:${SCALA_HOME}/bin:$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
新增Spark執行環境
cd /usr/local/spark/spark-2.3.0-bin-hadoop2.7/conf
sudo cp spark-env.sh.template spark-env.sh
sudo vim spark-env.sh新增如下內容
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export SCALA_HOME=/usr/local/scala/scala-2.10.7
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
配置Spark伺服器節點
cp slaves.template slaves
sudo vim slaves新增節點, 我們HDFS叢集有2個節點,分別Master和Slave1修改如下
#A Spark Worker will be started on each of the machines listed below.
Master
Slave1
同步Spark配置都其它伺服器
sudo chown -R hadoop /usr/local/spark
scp /etc/profile Slave1:/etc/profile
scp -r /usr/local/spark Slave1:/usr/local/
啟動Spark叢集
cd /usr/local/spark/spark-2.3.0-bin-hadoop2.7/sbin
# 這裡重新命名一個,方便在外面訪問
sudo cp start-all.sh spark-start-all.sh
# 啟動Spark叢集
spark-start-all.sh 然後訪問自己的站點,效果如下
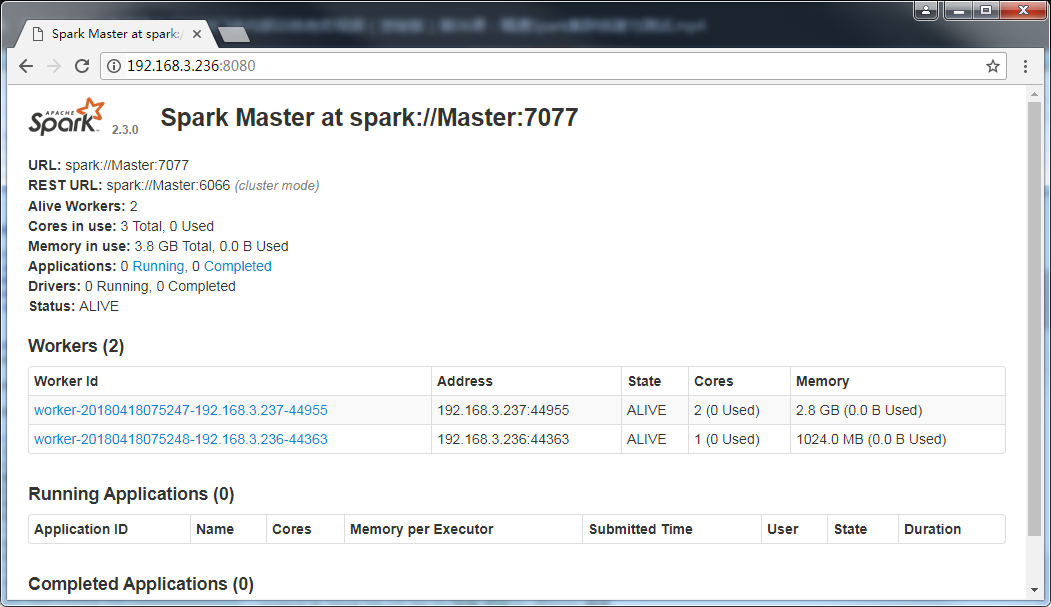
載入檔案到HDFS
為了能夠讀取HDFS中的檔案,請首先啟動Hadoop中的HDFS元件。
start-dfs.sh啟動結束後,HDFS開始進入可用狀態。如果你在HDFS檔案系統中,還沒有為當前Linux登入使用者建立目錄(本教程統一使用使用者名稱hadoop登入Linux系統),請使用下面命令建立:
hdfs dfs -mkdir -p /user/hadoop也就是說,HDFS檔案系統為Linux登入使用者開闢的預設目錄是“/user/使用者名稱”(注意:是user,不是usr),本教程統一使用使用者名稱hadoop登入Linux系統,所以,上面建立了“/user/hadoop”目錄,再次強調,這個目錄是在HDFS檔案系統中,不在本地檔案系統中。建立好以後,下面我們使用命令檢視一下HDFS檔案系統中的目錄和檔案:
hdfs dfs -ls .
hdfs dfs -ls /user
hdfs dfs -ls /user/hadoop
hdfs dfs -ls / # 檢視根目錄上面的一個點號“.”,表示要檢視Linux當前登入使用者hadoop在HDFS檔案系統中與hadoop對應的目錄下的檔案,也就是檢視HDFS檔案系統中“/user/hadoop/”目錄下的檔案。
我們把本地檔案系統中的“/usr/local/spark/spark-2.3.0-bin-hadoop2.7/README.md”上傳到分散式檔案系統HDFS中(放到hadoop使用者目錄下):
hdfs dfs -put /usr/local/spark/spark-2.3.0-bin-hadoop2.7/README.md .我們使用cat命令檢視一個HDFS中的README.md檔案的內容,命令如下:
hdfs dfs -cat ./README.md上面命令執行後,就會看到HDFS中README.md的內容了。
現在,讓我們開啟spark-shell視窗,編寫語句從HDFS中載入檔案,並顯示第一行文字內容:
注意,在後凡是在scala>打頭的命令, 都表示是在Spark Shell中輸入,否則就是Shell !!!
cd /usr/local/spark/spark-2.3.0-bin-hadoop2.7
./bin/spark-shell
scala> val textFile = sc.textFile("hdfs://Master:9000/user/hadoop/README.md")
scala> textFile.first()執行上面語句後,就可以看到HDFS檔案系統中(不是本地檔案系統)的README.md的第一行內容了。
需要注意的是,sc.textFile(“hdfs://Master:9000/user/hadoop/README.md”)中,“hdfs://Master:9000/”是前面介紹Hadoop安裝內容時確定下來的埠地址9000t和伺服器名字。實際上,也可以省略不寫,如下三條語句都是等價的:
val textFile = sc.textFile("hdfs://Master:9000/user/hadoop/README.md")
val textFile = sc.textFile("/user/hadoop/README.md")
val textFile = sc.textFile("README.md")
下面,我們再把textFile的內容寫回到HDFS檔案系統中(寫到hadoop使用者目錄下):
scala> textFile.saveAsTextFile("writeback")執行上面命令後,文字內容會被寫入到HDFS檔案系統的“/user/hadoop/writeback”目錄下,我們可以切換到Linux Shell命令提示符視窗檢視一下:
hdfs dfs -ls .
hdfs dfs -ls ./writeback執行結果中,可以看到存在兩個檔案:part-00000和_SUCCESS。我們使用下面命令輸出part-00000檔案的內容(注意:part-00000裡面有五個零):
hdfs dfs -cat ./writeback/part-00000執行結果中,就可以看到和README.md檔案中一樣的文字內容。
詞頻統計
有了前面的鋪墊性介紹,下面我們就可以開始第一個Spark應用程式:WordCount。
請切換到spark-shell視窗:
scala> val textFile = sc.textFile("hdfs://Master:9000/user/hadoop/README.md")
scala> val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
scala> wordCount.collect()上面只給出了程式碼,省略了執行過程中返回的結果資訊,因為返回資訊很多。
下面簡單解釋一下上面的語句。
- textFile包含了多行文字內容,textFile.flatMap(line => line.split(” “))會遍歷textFile中的每行文字內容,當遍歷到其中一行文字內容時,會把文字內容賦值給變數line
- 並執行Lamda表示式line => line.split(" ")。line => line.split(” “)是一個Lamda表示式,左邊表示輸入引數,右邊表示函式裡面執行的處理邏輯,這裡執行line.split(” “),也就是針對line中的一行文字內容,採用空格作為分隔符進行單詞切分,從一行文字切分得到很多個單詞構成一個單詞集合, 最終,多行文字,就得到多個單詞集合。
- textFile.flatMap()操作就把這多個單詞集合“拍扁”得到一個大的單詞集合。
- 然後,針對這個大的單詞集合,執行map()操作,也就是map(word => (word, 1)),這個map操作會遍歷這個集合中的每個單詞,當遍歷到其中一個單詞時,就把當前這個單詞賦值給變數word,並執行Lamda表示式word => (word, 1),這個Lamda表示式的含義是,word作為函式的輸入引數,然後,執行函式處理邏輯,這裡會執行(word, 1),也就是針對輸入的word,構建得到一個tuple,形式為(word,1),key是word,value是1(表示該單詞出現1次)。
- 程式執行到這裡,已經得到一個RDD,這個RDD的每個元素是(key,value)形式的tuple。最後,針對這個RDD,執行reduceByKey((a, b) => a + b)操作,這個操作會把所有RDD元素按照key進行分組,然後使用給定的函式(這裡就是Lamda表示式:(a, b) => a + b),對具有相同的key的多個value進行reduce操作,返回reduce後的(key,value),比如(“hadoop”,1)和(“hadoop”,1),具有相同的key,進行reduce以後就得到(“hadoop”,2),這樣就計算得到了這個單詞的詞頻。
編寫獨立應用程式執行詞頻統計
(一)編寫Scala獨立應用程式
接著我們通過一個簡單的應用程式 SimpleApp 來演示如何通過 Spark API 編寫一個獨立應用程式。使用 Scala 編寫的程式需要使用 sbt 進行編譯打包,相應的,Java 程式使用 Maven 編譯打包,而 Python 程式通過 spark-submit 直接提交。
- 安裝sbt
sbt是一款Spark用來對scala編寫程式進行打包的工具,這裡簡單介紹sbt的安裝過程,感興趣的讀者可以參考官網資料瞭解更多關於sbt的內容。
Spark 中沒有自帶 sbt,這裡直接給出sbt-launch.jar的下載地址,直接點選下載即可。
我們選擇安裝在 /usr/local/sbt 中:
sudo mkdir /usr/local/sbt
sudo chown -R hadoop /usr/local/sbt # 此處的 hadoop 為你的使用者名稱
cd /usr/local/sbt下載後,執行如下命令拷貝至 /usr/local/sbt 中:
接著在 /usr/local/sbt 中建立 sbt 指令碼(vim ./sbt),新增如下內容:
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java \$SBT_OPTS -jar `dirname $0`/sbt-launch.jar "[email protected]"儲存後,為 ./sbt 指令碼增加可執行許可權:
chmod u+x ./sbt最後執行如下命令,檢驗 sbt 是否可用(請確保電腦處於聯網狀態,首次執行會處於 “Getting org.scala-sbt sbt 0.13.11 …” 的下載狀態,請耐心等待。筆者等待了 7 分鐘才出現第一條下載提示):
./sbt sbt-version只要能得到如下圖的版本資訊就沒問題:

2.編寫Scala應用程式測試一下
在終端中執行如下命令建立一個資料夾 sparkapp 作為應用程式根目錄:
cd ~ # 進入使用者主資料夾
mkdir -p ./sparkapp/src/main/scala # 建立所需的資料夾結構在 ./sparkapp/src/main/scala 下建立一個名為 SimpleApp.scala 的檔案(vim ./sparkapp/src/main/scala/SimpleApp.scala),新增程式碼如下(目前不需要理解程式碼的具體含義,只需要理解如何編譯執行程式碼就可以):
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/spark-2.3.0-bin-hadoop2.7/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}該程式計算 /usr/local/spark/README 檔案中包含 “a” 的行數 和包含 “b” 的行數。程式碼第8行的 /usr/local/spark 為 Spark 的安裝目錄,如果不是該目錄請自行修改。不同於 Spark shell,獨立應用程式需要通過 val sc = new SparkContext(conf) 初始化 SparkContext,SparkContext 的引數 SparkConf 包含了應用程式的資訊。
使用sbt打包Scala程式
該程式依賴 Spark API,因此我們需要通過 sbt 進行編譯打包。 請在./sparkapp 中新建檔案 simple.sbt(vim ./sparkapp/simple.sbt),新增內容如下,宣告該獨立應用程式的資訊以及與 Spark 的依賴關係:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.3.0"
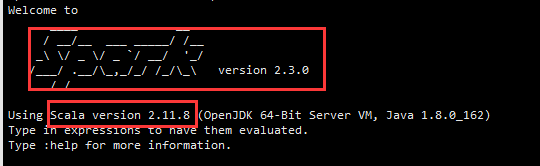
檔案 simple.sbt 需要指明 Spark 和 Scala 的版本。在上面的配置資訊中,scalaVersion用來指定scala的版本,sparkcore用來指定spark的版本,這兩個版本資訊都可以在之前的啟動 Spark shell 的過程中,從螢幕的顯示資訊中找到。下面就是筆者在啟動過程當中,看到的相關版本資訊(備註:螢幕顯示資訊會很長,需要往回滾動螢幕仔細尋找資訊)。
為保證 sbt 能正常執行,先執行如下命令檢查整個應用程式的檔案結構:
cd ~/sparkapp/
find .檔案結構應如下圖所示:

接著,我們就可以通過如下程式碼將整個應用程式打包成 JAR(首次運行同樣需要下載依賴包 ):
/usr/local/sbt/sbt package對於剛安裝好的Spark和sbt而言,第一次執行上面的打包命令時,會需要幾分鐘的執行時間,因為系統會自動從網路上下載各種檔案。後面再次執行上面命令,就會很快,因為不再需要下載相關檔案。
打包成功的話,會輸出如下內容:
........
[info] Done packaging.
[success] Total time: 513 s, completed Apr 19, 2018 1:08:49 AM生成的 jar 包的位置為 ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar。
4.通過 spark-submit 執行程式
最後,我們就可以將生成的 jar 包通過 spark-submit 提交到 Spark 中運行了,命令如下:
/usr/local/spark/spark-2.3.0-bin-hadoop2.7/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
/usr/local/spark/spark-2.3.0-bin-hadoop2.7/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar 2>&1 | grep "Lines with a:"最終得到的結果如下:
Lines with a: 61, Lines with b: 30
自此,你就完成了你的第一個 Spark 應用程式了。
(二)編寫Scala獨立應用程式執行詞頻統計
下面我們編寫一個Scala應用程式來實現詞頻統計。
請登入Linux系統(本教程統一採用使用者名稱hadoop進行登入),進入Shell命令提示符狀態,然後,執行下面命令:
# 這裡加入-p選項,可以一起建立src目錄及其子目錄
mkdir -p /usr/local/spark/mycode/wordcount/src/main/scala 請在“/usr/local/spark/mycode/wordcount/src/main/scala”目錄下新建一個test.scala檔案,裡面包含如下程式碼:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "hdfs://Master:9000/user/hadoop/README.md"
val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}注意,SparkConf().setAppName(“WordCount”).setMaster(“local2”)這句語句,也可以刪除.setMaster(“local2”),只保留 val conf = new SparkConf().setAppName(“WordCount”)。
如果test.scala沒有呼叫SparkAPI,那麼,只要使用scalac命令編譯後執行即可。但是,這個test.scala程式依賴 Spark API,因此我們需要通過 sbt 進行編譯打包(前面的這個章節已經介紹過如何使用sbt進行編譯打包)。下面我們再演示一次。
請執行如下命令:
cd /usr/local/spark/mycode/wordcount/
vim simple.sbt通過上面程式碼,新建一個simple.sbt檔案,請在該檔案中輸入下面程式碼:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.3.0"
注意, “org.apache.spark”後面是兩個百分號,千萬不要少些一個百分號%,如果少了,編譯時候會報錯。
下面我們使用 sbt 打包 Scala 程式。為保證 sbt 能正常執行,先執行如下命令檢查整個應用程式的檔案結構:
find .應該是類似下面的檔案結構:
.
./simple.sbt
./src
./src/main
./src/main/scala
./src/main/scala/test.scala
接著,我們就可以通過如下程式碼將整個應用程式打包成 JAR(首次運行同樣需要下載依賴包 ):
/usr/local/sbt/sbt package上面執行過程需要消耗幾分鐘時間,螢幕上會返回一下資訊:
生成的 jar 包的位置為 /usr/local/spark/mycode/wordcount/target/scala-2.11/simple-project_2.11-1.0.jar。
最後,通過 spark-submit 執行程式。我們就可以將生成的 jar 包通過 spark-submit 提交到 Spark 中運行了,命令如下:
/usr/local/spark/spark-2.3.0-bin-hadoop2.7/bin/spark-submit --class "WordCount" /usr/local/spark/mycode/wordcount/target/scala-2.11/simple-project_2.11-1.0.jar下面是筆者的word.txt進行詞頻統計後的結果(你的結果應該和這個類似):
(For,3)
(Programs,1)
(Spark,16)
(particular,2)
(The,1)
(than,1)
(processing.,1)
(APIs,1)
(computation,1)
(Try,1)
([Configuration,1)
(./bin/pyspark,1)
(A,1)
(through,1)
以上內容主要自 http://dblab.xmu.edu.cn/blog/spark/ 感謝原作者
相關推薦
大資料-03-Spark入門
Spark 簡介 行業廣泛使用Hadoop來分析他們的資料集。原因是Hadoop框架基於一個簡單的程式設計模型(MapReduce)。這裡,主要關注的是在處理大型資料集時在查詢之間的等待時間和執行程式的等待時間方面保持速度。 Hadoop只是實現Spark的方法之一。Spark以兩種方式使用Hadoop -
子雨大資料之Spark入門教程
【版權宣告】部落格內容由廈門大學資料庫實驗室擁有版權,未經允許,請勿轉載!版權所有,侵權必究! Spark最初誕生於美國加州大學伯克利分校(UC Berkeley)的AMP實驗室,是一個可應用於大規模資料處理的快速、通用引擎。2013年,Spark加入Apache孵化器專案後,開始獲得迅猛的發展,如今已
子雨大資料之Spark入門教程---Spark2.1.0入門:第一個Spark應用程式:WordCount 2.2
前面已經學習了Spark安裝,完成了實驗環境的搭建,並且學習了Spark執行架構和RDD設計原理,同時,我們還學習了Scala程式設計的基本語法,有了這些基礎知識作為鋪墊,現在我們可以沒有障礙地開始編寫一個簡單的Spark應用程式了——詞頻統計。 任務要求 任務:
零基礎入門大資料之spark中rdd部分運算元詳解
先前文章介紹過一些spark相關知識,本文繼續補充一些細節。 我們知道,spark中一個重要的資料結構是rdd,這是一種並行集合的資料格式,大多數操作都是圍繞著rdd來的,rdd裡面擁有眾多的方法可以呼叫從而實現各種各樣的功能,那麼通常情況下我們讀入的資料來源並非rdd格式的,如何轉
零基礎入門大資料之spark中的幾種key-value操作
今天記錄一下spark裡面的一些key-value對的相關運算元。 key-value對可以簡單理解為是一種認為構造的資料結構方式,比如一個字串"hello",單看"hello"的話,它是一個字串型別,現在假設我想把它在一個文字中出現的次數n作為一個值和"hello"一起操作,那麼可
[大資料之Spark]——快速入門
本篇文件是介紹如何快速使用spark,首先將會介紹下spark在shell中的互動api,然後展示下如何使用java,scala,python等語言編寫應用。 為了良好的閱讀下面的文件,最好是結合實際的練習。首先需要下載spark,然後安裝hd
spark大資料架構初學入門基礎詳解
Spark是什麼 a) 是一種通用的大資料計算框架 b) Spark Core 離線計算 Spark SQL 互動式查詢 Spark Streaming 實時流式計算 Spark MLlib 機器學習 Spark GraphX 圖計算 c) 特點:
大資料開發-Spark-初識Spark-Graph && 快速入門
# 1.Spark Graph簡介 GraphX 是 Spark 一個元件,專門用來表示圖以及進行圖的平行計算。GraphX 通過重新定義了圖的抽象概念來拓展了 RDD: 定向多圖,其屬性附加到每個頂點和邊。為了支援圖計算, GraphX 公開了一系列基本運算子(比如:mapVertices、mapEdge
大資料之Spark(五)--- Spark的SQL模組,Spark的JDBC實現,SparkSQL整合MySQL,SparkSQL整合Hive和Beeline
一、Spqrk的SQL模組 ---------------------------------------------------------- 1.該模組能在Spack上執行Sql語句 2.可以處理廣泛的資料來源 3.DataFrame --- RDD --- tabl
大資料之Spark(四)--- Dependency依賴,啟動模式,shuffle,RDD持久化,變數傳遞,共享變數,分散式計算PI的值
一、Dependency:依賴:RDD分割槽之間的依存關係 --------------------------------------------------------- 1.NarrowDependency: 子RDD的每個分割槽依賴於父RDD的少量分割槽。 |
大資料之Spark(三)--- Spark核心API,Spark術語,Spark三級排程流程原始碼分析
一、Spark核心API ----------------------------------------------- [SparkContext] 連線到spark叢集,入口點. [HadoopRDD] extends RDD 讀取hadoop
大資料之Spark(二)--- RDD,RDD變換,RDD的Action,解決spark的資料傾斜問題,spark整合hadoop的HA
一、Spark叢集執行 ------------------------------------------------------- 1.local //本地模式 2.standalone //獨立模式 3.yarn //yarn模式
大資料之Spark(一)--- Spark簡介,模組,安裝,使用,一句話實現WorldCount,API,scala程式設計,提交作業到spark叢集,指令碼分析
一、Spark簡介 ---------------------------------------------------------- 1.快如閃電的叢集計算 2.大規模快速通用的計算引擎 3.速度: 比hadoop 100x,磁碟計算快10x 4.使用: java
大資料(一)——概念入門
最近在B站上看一套44集的大資料教程——經典Hadoop分散式系統基礎架構。想通過對Hadoop的學習,跳到大資料領域當中。作為大資料的開篇,主要是做一些大資料掃盲,並且重點介紹Hadoop需要學些什麼。 1.何為大資料 IBM提出大資料具有5V特點:Volume(大量)、Velocit
學習大資料課程 spark 基於記憶體的分散式計算框架(二)RDD 程式設計基礎使用
學習大資料課程 spark 基於記憶體的分散式計算框架(二)RDD 程式設計基礎使用 1.常用的轉換 假設rdd的元素是: {1,2,2,3} 很多初學者,對大資料的概念都是模糊不清的,大資料是什麼,能做什麼,學的時候,該按照什麼線路去學習,學完
大資料是什麼?0基礎大資料怎麼進行入門學習?
0基礎我們該怎麼進行大資料入門學習呢?帶你們一起來學習。 一、大資料是什麼? 大資料,big data,《大資料》一書對大資料這麼定義,大資料是指不能用隨機分析法(抽樣調查)這樣捷徑,而採用所有資料進行分析處理。 這句話至少傳遞兩種資訊:。 1、大資料是海量的資料 2、大資料處理
大資料之Spark(七)--- Spark機器學習,樸素貝葉斯,酒水評估和分類案例學習,垃圾郵件過濾學習案例,電商商品推薦,電影推薦學習案例
一、Saprk機器學習介紹 ------------------------------------------------------------------ 1.監督學習 a.有訓練資料集,符合規範的資料 b.根據資料集,產生一個推斷函式
大資料之Spark(六)--- Spark Streaming介紹,DStream,Receiver,Streamin整合Kafka,Windows,容錯的實現
一、Spark Streaming介紹 ----------------------------------------------------------- 1.介紹 是spark core的擴充套件,針對實時資料的實時流處理技術 具有可擴充套件、高吞吐量、
大資料之Spark(八)--- Spark閉包處理,部署模式和叢集模式,SparkOnYarn模式,高可用,Spark整合Hive訪問hbase類載入等異常解決,使用spark下的thriftserv
一、Spark閉包處理 ------------------------------------------------------------ RDD,resilient distributed dataset,彈性(容錯)分散式資料集。 分割槽列表,function,dep Op
大資料學習 ------ Scala入門
1.1 為什麼要學Scala語言[1] 1.優雅:這是框架設計師第一個要考慮的問題,框架的使用者是應用開發程式設計師,API是否優雅直接影響使用者體驗。 Martin OrderSke (scala發人) Epel瑞士科技大學 Javac是Matin編寫的