
大資料-01-安裝Hadoop
環境
伺服器:ubuntu-16.04.3-desktop-amd64.iso
建立hadoop使用者
sudo useradd -m hadoop -s /bin/bash本文中會大量使用到sudo命令。sudo是ubuntu中一種許可權管理機制,管理員可以授權給一些普通使用者去執行一些需要root許可權執行的操作。當使用sudo命令時,就需要輸入您當前使用者的密碼.
sudo passwd hadoop接著使用如下命令設定密碼,可簡單設定為 hadoop,按提示輸入兩次密碼
sudo adduser hadoop sudo可為 hadoop 使用者增加管理員許可權,方便部署,避免一些對新手來說比較棘手的許可權問題:
更新apt
用 hadoop 使用者登入後,我們先更新一下 apt,後續我們使用 apt 安裝軟體,如果沒更新可能有一些軟體安裝不了。按 ctrl+alt+t 開啟終端視窗,執行如下命令:
sudo apt-get update安裝軟體 vim 用作基本文字編輯
sudo apt-get install vim安裝SSH、配置SSH無密碼登陸
叢集、單節點模式都需要用到 SSH 登陸(類似於遠端登陸,你可以登入某臺 Linux 主機,並且在上面執行命令),Ubuntu 預設已安裝了 SSH client,此外還需要安裝 SSH server:
sudo apt-get install openssh-server
安裝後,這個時候,就可以用Xshell等工具, 以hadoop使用者進行登入進入了:
可以使用如下命令登陸本機:
ssh localhost但這樣登陸是需要每次輸入密碼的,我們需要配置成SSH無密碼登陸比較方便。
首先退出剛才的 ssh,就回到了我們原先的終端視窗,然後利用 ssh-keygen 生成金鑰,並將金鑰加入到授權中:
exit # 退出剛才的 ssh localhost cd ~/.ssh/ # 若沒有該目錄,請先執行一次ssh localhost ssh-keygen -t rsa # 會有提示,都按回車就可以 cat ./id_rsa.pub >> ./authorized_keys # 加入授權
~的含義
在 Linux 系統中,~ 代表的是使用者的主資料夾,即 “/home/使用者名稱” 這個目錄,如你的使用者名稱為 hadoop,則 ~ 就代表 “/home/hadoop/”。 此外,命令中的 # 後面的文字是註釋,只需要輸入前面命令即可。
此時再用 ssh localhost 命令,無需輸入密碼就可以直接登陸了,如下圖所示。
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.10.0-28-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Last login: Sun Apr 15 05:44:46 2018 from 192.168.229.1
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.安裝Java環境
要安裝JDK 7,請使用以下命令:
下載包
wget https://download.java.net/openjdk/jdk7u75/ri/openjdk-7u75-b13-linux-x64-18_dec_2014.tar.gz解壓縮剛才下載的
sudo mkdir /usr/local/java
cp openjdk-7u75-b13-linux-x64-18_dec_2014.tar.gz /usr/local/java
cd /usr/local/java
sudo tar xvf openjdk-7u75-b13-linux-x64-18_dec_2014.tar.gz這裡需要將資料夾進行一個重新命名, 這裡看到的資料夾名字是java-se-7u75-ri, 進行如下重新命名:
sudo mv java-se-7u75-ri java1.7.0_75然後編輯profile檔案,新增路徑,環境變數
sudo vim /etc/profile在vim編輯器中的profile 末尾新增如下內容:
export JAVA_HOME=/usr/local/java/jdk1.7.0_75
export JRE_HOME=/usr/local/java/jdk1.7.0_75/jre
export PATH=$PATH:/usr/local/java/jdk1.7.0_75/bin
export CLASSPATH=./:/usr/local/java/jdk1.7.0_75/lib:/usr/local/java/jdk1.7.0_75/jre/lib輸入:wq儲存並退出,然後再重啟系統.
檢查java版本是否正常:
java -version此時顯示jdk的版本號,我的顯示如下:
openjdk version "1.7.0_75"
OpenJDK Runtime Environment (build 1.7.0_75-b13)
OpenJDK 64-Bit Server VM (build 24.75-b04, mixed mode)安裝Hadoop 2
Hadoop 2 可以通過 http://mirror.bit.edu.cn/apache/hadoop/common/ 或者 http://mirrors.cnnic.cn/apache/hadoop/common/ 下載,一般選擇下載最新的穩定版本,即下載 “stable” 下的 hadoop-2.x.y.tar.gz 這個格式的檔案,這是編譯好的,另一個包含 src 的則是 Hadoop 原始碼,需要進行編譯才可使用。
我們選擇將 Hadoop 安裝至 /usr/local/ 中:
sudo tar -zxf hadoop-2.7.5.tar.gz -C /usr/local # 解壓到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.7.5/ ./hadoop # 將資料夾名改為hadoop
sudo chown -R hadoop ./hadoop # 修改檔案許可權Hadoop 解壓後即可使用。輸入如下命令來檢查 Hadoop 是否可用,成功則會顯示 Hadoop 版本資訊:
cd /usr/local/hadoop
./bin/hadoop version**** 相對路徑與絕對路徑
請務必注意命令中的相對路徑與絕對路徑,本文後續出現的 ./bin/...,./etc/... 等包含 ./ 的路徑,均為相對路徑,以 /usr/local/hadoop 為當前目錄。例如在 /usr/local/hadoop 目錄中執行 ./bin/hadoop version 等同於執行 /usr/local/hadoop/bin/hadoop version。可以將相對路徑改成絕對路徑來執行,但如果你是在主資料夾 ~ 中執行 ./bin/hadoop version,執行的會是 /home/hadoop/bin/hadoop version,就不是我們所想要的了。
Hadoop單機配置(非分散式)
Hadoop 預設模式為非分散式模式(本地模式),無需進行其他配置即可執行。非分散式即單 Java 程序,方便進行除錯。
現在我們可以執行例子來感受下 Hadoop 的執行。Hadoop 附帶了豐富的例子(執行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
在此我們選擇執行 grep 例子,我們將 input 資料夾中的所有檔案作為輸入,篩選當中符合正則表示式 dfs[a-z.]+ 的單詞並統計出現的次數,最後輸出結果到 output 資料夾中。
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 將配置檔案作為輸入檔案
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 檢視執行結果注意,Hadoop 預設不會覆蓋結果檔案,因此再次執行上面例項會提示出錯,需要先將 ./output 刪除。
rm -r ./outputHadoop偽分散式配置
Hadoop 可以在單節點上以偽分散式的方式執行,Hadoop 程序以分離的 Java 程序來執行,節點既作為 NameNode 也作為 DataNode,同時,讀取的是 HDFS 中的檔案。
Hadoop 的配置檔案位於 /usr/local/hadoop/etc/hadoop/ 中,偽分散式需要修改2個配置檔案 core-site.xml 和 hdfs-site.xml 。Hadoop的配置檔案是 xml 格式,每個配置以宣告 property 的 name 和 value 的方式來實現。
修改配置檔案 core-site.xml (通過 gedit 編輯會比較方便: gedit ./etc/hadoop/core-site.xml),將當中的
<configuration>
</configuration>修改為下面配置:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>同樣的,修改配置檔案 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>Hadoop配置檔案說明
Hadoop 的執行方式是由配置檔案決定的(執行 Hadoop 時會讀取配置檔案),因此如果需要從偽分散式模式切換回非分散式模式,需要刪除 core-site.xml 中的配置項。
此外,偽分散式雖然只需要配置 fs.defaultFS 和 dfs.replication 就可以執行(官方教程如此),不過若沒有配置 hadoop.tmp.dir 引數,則預設使用的臨時目錄為 /tmp/hadoo-hadoop,而這個目錄在重啟時有可能被系統清理掉,導致必須重新執行 format 才行。所以我們進行了設定,同時也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否則在接下來的步驟中可能會出錯。
配置完成後,執行 NameNode 的格式化:
./bin/hdfs namenode -format成功的話,會看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若為 “Exitting with status 1” 則是出錯。
如果在這一步時提示 Error: JAVA_HOME is not set and could not be found. 的錯誤,則說明之前設定 JAVA_HOME 環境變數那邊就沒設定好,請按教程先設定好 JAVA_HOME 變數,否則後面的過程都是進行不下去的。如果已經按照前面教程在.bashrc檔案中設定了JAVA_HOME,還是出現 Error: JAVA_HOME is not set and could not be found. 的錯誤,那麼,請到hadoop的安裝目錄修改配置檔案“/usr/local/hadoop/etc/hadoop/hadoop-env.sh”,在裡面找到“export JAVA_HOME=${JAVA_HOME}”這行,然後,把它修改成JAVA安裝路徑的具體地址,比如,“export JAVA_HOME=/usr/lib/jvm/default-java”,然後,再次啟動Hadoop。
接著開啟 NameNode 和 DataNode 守護程序。
./sbin/start-dfs.sh #start-dfs.sh是個完整的可執行檔案,中間沒有空格啟動時可能會出現如下 WARN 提示:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable WARN 提示可以忽略,並不會影響正常使用。
啟動 Hadoop 時提示 Could not resolve hostname
如果啟動 Hadoop 時遇到輸出非常多“ssh: Could not resolve hostname xxx”的異常情況,如下圖所示:
這個並不是 ssh 的問題,可通過設定 Hadoop 環境變數來解決。首先按鍵盤的 ctrl + c 中斷啟動,然後在 ~/.bashrc 中,增加如下兩行內容(設定過程與 JAVA_HOME 變數一樣,其中 HADOOP_HOME 為 Hadoop 的安裝目錄):
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native啟動完成後,可以通過命令 jps 來判斷是否成功啟動,若成功啟動則會列出如下程序: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 沒有啟動,請執行 sbin/stop-dfs.sh 關閉程序,然後再次嘗試啟動嘗試)。如果沒有 NameNode 或 DataNode ,那就是配置不成功,請仔細檢查之前步驟,或通過檢視啟動日誌排查原因。
執行Hadoop偽分散式例項
上面的單機模式,grep 例子讀取的是本地資料,偽分散式讀取的則是 HDFS 上的資料。要使用 HDFS,首先需要在 HDFS 中建立使用者目錄:
./bin/hdfs dfs -mkdir -p /user/hadoop注意
教材《大資料技術原理與應用》的命令是以”./bin/hadoop >dfs”開頭的Shell命令方式,實際上有三種shell命令方式。
- hadoop fs
- hadoop dfs
- hdfs dfs
hadoop fs適用於任何不同的檔案系統,比如本地檔案系統和HDFS檔案系統
hadoop dfs只能適用於HDFS檔案系統
hdfs dfs跟hadoop dfs的命令作用一樣,也只能適用於HDFS檔案系統
接著將 ./etc/hadoop 中的 xml 檔案作為輸入檔案複製到分散式檔案系統中,即將 /usr/local/hadoop/etc/hadoop 複製到分散式檔案系統中的 /user/hadoop/input 中。我們使用的是 hadoop 使用者,並且已建立相應的使用者目錄 /user/hadoop ,因此在命令中就可以使用相對路徑如 input,其對應的絕對路徑就是 /user/hadoop/input:
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input複製完成後,可以通過如下命令檢視檔案列表:
./bin/hdfs dfs -ls input偽分散式執行 MapReduce 作業的方式跟單機模式相同,區別在於偽分散式讀取的是HDFS中的檔案(可以將單機步驟中建立的本地 input 資料夾,輸出結果 output 資料夾都刪掉來驗證這一點)。
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'檢視執行結果的命令(檢視的是位於 HDFS 中的輸出結果):
./bin/hdfs dfs -cat output/*我們也可以將執行結果取回到本地:
rm -r ./output # 先刪除本地的 output 資料夾(如果存在)
./bin/hdfs dfs -get output ./output # 將 HDFS 上的 output 資料夾拷貝到本機
cat ./output/*Hadoop 執行程式時,輸出目錄不能存在,否則會提示錯誤 “org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists” ,因此若要再次執行,需要執行如下命令刪除 output 資料夾:
./bin/hdfs dfs -rm -r output # 刪除 output 資料夾執行程式時,輸出目錄不能存在
執行 Hadoop 程式時,為了防止覆蓋結果,程式指定的輸出目錄(如 >output)不能存在,否則會提示錯誤,因此執行前需要先刪除輸出目錄。在實際開>發應用程式時,可考慮在程式中加上如下程式碼,能在每次執行時自動刪除輸出目錄>,避免繁瑣的命令列操作:Configuration conf = new Configuration(); Job job = new Job(conf); /* 刪除輸出目錄 */ Path outputPath = new Path(args[1]); outputPath.getFileSystem(conf).delete(outputPath, true);
若要關閉 Hadoop,則執行
./sbin/stop-dfs.sh注意
下次啟動 hadoop 時,無需進行 NameNode 的初始化,只需要執行 >./sbin/start-dfs.sh 就可以!
配置叢集/分散式環境
準備工作
本教程簡單的使用兩個節點作為叢集環境: 一個作為 Master 節點,區域網 IP 為 192.168.3.236;另一個作為 Slave 節點,區域網 IP 為 192.168.3.237。
Hadoop 叢集的安裝配置大致為如下流程:
- 選定一臺機器作為 Master
- 在 Master 節點上配置 hadoop 使用者、安裝 SSH server、安裝 Java 環境
- 在 Master 節點上安裝 Hadoop,並完成配置
- 在其他 Slave 節點上配置 hadoop 使用者、安裝 SSH server、安裝 Java 環境
- 將 Master 節點上的 /usr/local/hadoop 目錄複製到其他 Slave 節點上
- 在 Master 節點上開啟 Hadoop
配置 hadoop 使用者、安裝 SSH server、安裝 Java 環境、安裝 Hadoop 等過程已經在之前的單機/偽分散式配置中有詳細介紹,請前往檢視,不再重複敘述
繼續下一步配置前,請先完成上述流程的前 4 個步驟。
網路配置
我的虛擬機器軟體用的是VMware,在已經配置好的一份虛擬機器上,將虛擬機器關機後, 複製一份出來作為另一個虛擬機器。同時需要更改網路連線方式為橋接(Bridge)模式,這個各個虛擬機器上區域網絡上, 才有各自獨立的IP地址。
Linux 中檢視節點 IP 地址的命令為 ifconfig。
首先在 Master 節點上完成準備工作,並關閉 Hadoop (/usr/local/hadoop/sbin/stop-dfs.sh),再進行後續叢集配置。
/usr/local/hadoop/sbin/stop-dfs.sh為了便於區分,可以修改各個節點的主機名(在終端標題、命令列中可以看到主機名,以便區分)。在 Ubuntu/CentOS 7 中,我們在 Master 節點上執行如下命令修改主機名(即改為 Master,注意是區分大小寫的); 我們在 Slave1 節點上執行如下命令修改主機名(即改為 Slave1,注意是區分大小寫的):
sudo vim /etc/hostname然後執行如下命令修改自己所有節點的IP對映:
sudo vim /etc/hosts例如本教程使用兩個節點的名稱與對應的 IP 關係如下:
192.168.3.236 Master
192.168.3.237 Slave1我們在 /etc/hosts 中將該對映關係填寫上去即可,如下圖所示(一般該檔案中只有一個 127.0.0.1,其對應名為 localhost,如果有多餘的應刪除,特別是不能有 “127.0.0.1 Master” 這樣的記錄):
通常就是3條即
127.0.0.1 localhost
192.168.3.236 Master
192.168.3.237 Slave1
修改完成後需要重啟一下,重啟後在終端中才會看到機器名的變化。接下來的教程中請注意區分 Master 節點與 Slave 節點的操作。
配置好後需要在各個節點上執行如下命令,測試是否相互 ping 得通,如果 ping 不通,後面就無法順利配置成功:
ping Master -c 3 # 只ping 3次,否則要按 Ctrl+c 中斷
ping Slave1 -c 3例如我在 Master 節點上 ping Slave1,ping 通的話會顯示 time,顯示的結果如下所示:
PING Slave1 (192.168.3.237) 56(84) bytes of data.
64 bytes from Slave1 (192.168.3.237): icmp_seq=1 ttl=64 time=0.022 ms
64 bytes from Slave1 (192.168.3.237): icmp_seq=2 ttl=64 time=0.031 ms
64 bytes from Slave1 (192.168.3.237): icmp_seq=3 ttl=64 time=0.023 ms--- Slave1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2030ms
SSH無密碼登陸節點
因為我的兩個伺服器是複製的,兩個伺服器中都有一樣的公鑰,所有它們之前已經可以互相訪問了,所有跳過本節(SSH無密碼登陸節點)。 便是在現實的系統中,可能需要給不同的機器生成各自的連線鑰匙,可以參考如下操作。
這個操作是要讓 Master 節點可以無密碼 SSH 登陸到各個 Slave 節點上。
首先生成 Master 節點的公匙,在 Master 節點的終端中執行(因為改過主機名,所以還需要刪掉原有的再重新生成一次):
cd ~/.ssh # 如果沒有該目錄,先執行一次ssh localhost
rm ./id_rsa* # 刪除之前生成的公匙(如果有)
ssh-keygen -t rsa # 一直按回車就可以讓 Master 節點需能無密碼 SSH 本機,在 Master 節點上執行:
cat ./id_rsa.pub >> ./authorized_keys完成後可執行 ssh Master 驗證一下(可能需要輸入 yes,成功後執行 exit 返回原來的終端)。接著在 Master 節點將上公匙傳輸到 Slave1 節點:
scp ~/.ssh/id_rsa.pub [email protected]:/home/hadoop/scp 是 secure copy 的簡寫,用於在 Linux 下進行遠端拷貝檔案,類似於 cp 命令,不過 cp 只能在本機中拷貝。執行 scp 時會要求輸入 Slave1 上 hadoop 使用者的密碼(hadoop),輸入完成後會提示傳輸完畢,如下所示:
idrsa.puib 100% ....
接著在 Slave1 節點上,將 ssh 公匙加入授權:
mkdir ~/.ssh # 如果不存在該資料夾需先建立,若已存在則忽略
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 用完就可以刪掉了如果有其他 Slave 節點,也要執行將 Master 公匙傳輸到 Slave 節點、在 Slave 節點上加入授權這兩步。
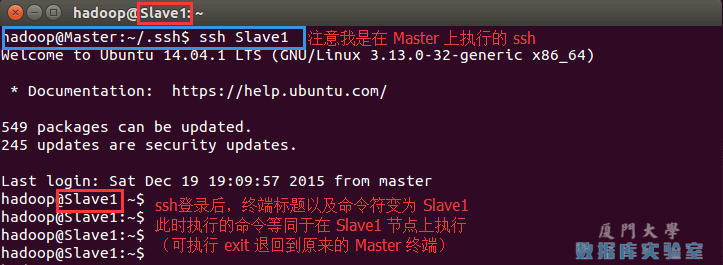
這樣,在 Master 節點上就可以無密碼 SSH 到各個 Slave 節點了,可在 Master 節點上執行如下命令進行檢驗,如下所示:
ssh Slave1這樣,在 Master 節點上就可以無密碼 SSH 到各個 Slave 節點了,可在 Master 節點上執行如下命令進行檢驗,如下圖所示:
配置PATH變數
( 單機配置 Hadoop 的教程中有配置這一項了,這一步可以跳過)
在單機偽分散式配置教程的最後,說到可以將 Hadoop 安裝目錄加入 PATH 變數中,這樣就可以在任意目錄中直接使用 hadoo、hdfs 等命令了,如果還沒有配置的,需要在 Master 節點上進行配置。首先執行 vim ~/.bashrc,加入一行:
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
儲存後執行 source ~/.bashrc 使配置生效。
配置叢集/分散式環境
叢集/分散式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5個配置檔案,更多設定項可點選檢視官方說明,這裡僅設定了正常啟動所必須的設定項: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1, 檔案 slaves,將作為 DataNode 的主機名寫入該檔案,每行一個,預設為 localhost,所以在偽分散式配置時,節點即作為 NameNode 也作為 DataNode。分散式配置可以保留 localhost,也可以刪掉,讓 Master 節點僅作為 NameNode 使用。
本教程讓 Master 節點僅作為 NameNode 使用,因此將檔案中原來的 localhost 刪除,只新增二行內容:
Master
Slave1
2, 檔案 core-site.xml 改為下面的配置:
fs.defaultFS為NameNode的地址。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
</configuration>
3, 檔案 hdfs-site.xml,dfs.replication 一般設為 3,但我們只有一個 Slave 節點,所以 dfs.replication 的值還是設為 1:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Slave1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>4, 檔案 mapred-site.xml (可能需要先重新命名,預設檔名為 mapred-site.xml.template),然後配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>5, 檔案 yarn-site.xml:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>配置好後,將 Master 上的 /usr/local/Hadoop 資料夾複製到各個節點上。因為之前有跑過偽分散式模式,建議在切換到叢集模式前先刪除之前的臨時檔案。在 Master 節點上執行:
cd /usr/local
sudo rm -r ./hadoop/tmp # 刪除 Hadoop 臨時檔案
sudo rm -r ./hadoop/logs/* # 刪除日誌檔案
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先壓縮再複製
cd ~
scp ./hadoop.master.tar.gz Slave1:/home/hadoop
在 Slave1 節點上執行:
sudo rm -r /usr/local/hadoop # 刪掉舊的(如果存在)
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop同樣,如果有其他 Slave 節點,也要執行將 hadoop.master.tar.gz 傳輸到 Slave 節點、在 Slave 節點解壓檔案的操作。
首次啟動需要先在 Master 節點執行 NameNode 的格式化:
/usr/local/hadoop/bin/hdfs namenode -format # 首次執行需要執行初始化,之後不需要系統需要關閉防火牆
CentOS系統預設開啟了防火牆,在開啟 Hadoop >叢集之前,需要關閉叢集中每個節點的防火牆。有防火牆會導致 ping 得通但 >telnet 埠不通,從而導致 DataNode 啟動了,但 Live datanodes 為 0 >的情況。
在 CentOS 6.x 中,可以通過如下命令關閉防火牆:sudo service iptables stop # 關閉防火牆服務 sudo chkconfig iptables off # 禁止防火牆開機自啟,就不用手動關閉了若用是 CentOS 7,需通過如下命令關閉(防火牆服務改成了 firewall):
systemctl stop firewalld.service # 關閉firewall systemctl disable firewalld.service # 禁止firewall開機啟動Ubuntu
ufw disable #關閉ubuntu的防火牆 ufw enable #開啟防火牆
接著可以啟動 hadoop 了,啟動需要在 Master 節點上進行:
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver相應的停止語句如下:
stop-dfs.sh
stop-yarn.sh
mr-jobhistory-daemon.sh stop historyserver
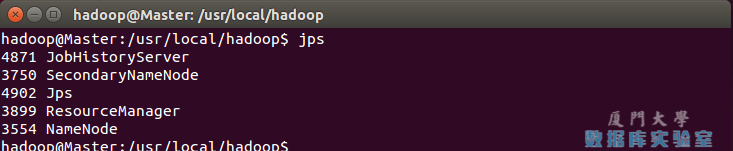
通過命令 jps 可以檢視各個節點所啟動的程序。正確的話,在 Master 節點上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 程序,如下圖所示:
在 Slave 節點可以看到 DataNode 和 NodeManager 程序,如下圖所示:

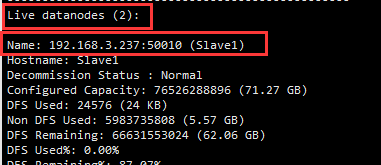
缺少任一程序都表示出錯。另外還需要在 Master 節點上通過命令 hdfs dfsadmin -report 檢視 DataNode 是否正常啟動,如果 Live datanodes 不為 0 ,則說明叢集啟動成功。例如我這邊一共有 2 個 Datanodes:
也可以通過 Web 頁面看到檢視 DataNode 和 NameNode 的狀態:http://192.168.3.236:50070/。如果不成功,可以通過啟動日誌排查原因。
偽分散式、分散式配置切換時的注意事項
1, 從分散式切換到偽分散式時,不要忘記修改 slaves 配置檔案;
2, 在兩者之間切換時,若遇到無法正常啟動的情況,可以刪除所涉及節點的臨時資料夾,這樣雖然之前的資料會被刪掉,但能保證叢集正確啟動。所以如果叢集以前能啟動,但後來啟動不了,特別是 DataNode >無法啟動,不妨試著刪除所有節點(包括 Slave 節點)上的 >/usr/local/hadoop/tmp 資料夾,再重新執行一次 hdfs namenode >-format,再次啟動試試。
執行分散式例項
執行分散式例項過程與偽分散式模式一樣,首先建立 HDFS 上的使用者目錄:
hdfs dfs -mkdir -p /user/hadoop將 /usr/local/hadoop/etc/hadoop 中的配置檔案作為輸入檔案複製到分散式檔案系統中:
hdfs dfs -mkdir input
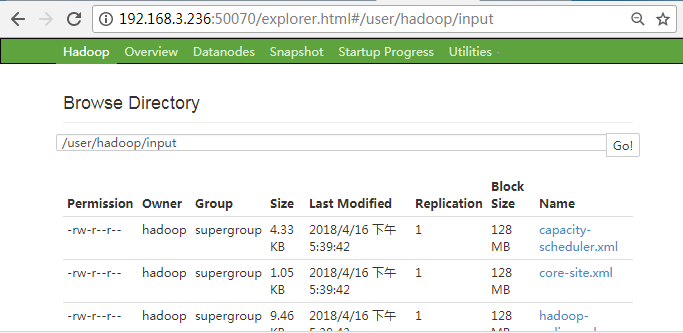
hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input通過檢視 DataNode 的狀態(佔用大小有改變),輸入檔案確實複製到了 DataNode 中,如下圖所示:
接著就可以執行 MapReduce 作業了:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'執行完畢後的輸出結果:
hdfs dfs -cat output/*如圖所示:
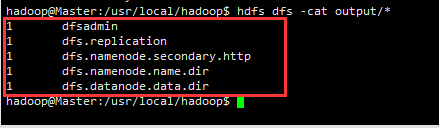
檢視相關命令
hdfs dfs自此,你就掌握了 Hadoop 的叢集搭建與基本使用了。
以上內容主要拷貝自 http://dblab.xmu.edu.cn/blog/install-hadoop/ 感謝原作者
相關推薦
大資料-01-安裝Hadoop
環境 伺服器:ubuntu-16.04.3-desktop-amd64.iso 建立hadoop使用者 sudo useradd -m hadoop -s /bin/bash 本文中會大量使用到sudo命令。sudo是ubuntu中一種許可權管理機制,管理員可以授權給一些普通使用者去執行一些需要root許可權
大資料入門:Hadoop安裝、環境配置及檢測
目錄 1.導包Hadoop包 2.配置環境變數 3.把winutil包拷貝到Hadoop bin目錄下 4.把Hadoop.dll放到system32下 5.檢測Hadoop是否正常安裝 5.1在maven專案中檢測,將配置檔案放入resource包下 5.2然後
【大資料】安裝偽分散式Hadoop叢集
壓縮包: eclipse-jee-photon-R-linux-gtk-x86_64.tar.gz hadoop-2.9.1.tar.gz jdk-10.0.1_linux-x64_bin.tar.gz 配置主機名和網路 配置主機名: #hostnamect
【大資料】安裝完全分散式Hadoop叢集
修改主機名和網路 master: #hostnamectl set-hostname master #vi /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=Ethernet PROXY_METHOD=none BR
Hadoop大資料元件安裝 史上最詳細教程 手把手教會你安裝
Hadoop安裝--大資料元件安裝--史上最完整教程--手把手教會你安裝 ——徹底揭開大資料技術的面紗,讓小白徹底進入大資料技術領域 安裝的Hadoop的生態圈元件有如下幾個(以後會不斷補充完善起來了)。 (1)Hadoop(單機模式獨立,偽分散式偽分散式,全分散式全
大資料平臺入門--hadoop虛擬機器偽分散式安裝
裡面我遇到的幾個問題: 1、因為沒有配置主機名,所以文中所有涉及到配置主機名的地方“bigdata-senior01.chybinmy.com”均應修改成“localhost”,否則啟動namenode的時候會報錯: Failed to start namenode.
大資料叢集安裝系列2:Hadoop HA 模式安裝
1,基本環境配置:依賴zookeeper, 2,hadoop HA 模式安裝 2.1,下載相應的hadoop 安裝包,本文是2.7.2, 放到伺服器目錄下,解壓,類似如下: [[email protected] /opt/bigd
大資料_MapReduce和Hadoop的安裝與配置
谷歌的向量矩陣 MapReduce計算模型 java的序列化是實現Serializable介面(我如果想把一個java的物件作為inputStream和outputSt
【大資料】瞭解Hadoop框架的基礎知識
介紹 此Refcard提供了Apache Hadoop,這是最流行的軟體框架,可使用簡單的高階程式設計模型實現大型資料集的分散式儲存和處理。我們將介紹Hadoop最重要的概念,描述其架構,指導您如何開始使用它以及在Hadoop上編寫和執行各種應用程式。 簡而言之,Hadoop是Apache Softwar
大資料開發之Hadoop篇----pid檔案剖析
這裡我們先看下在我還沒有啟hdfs那三個程序的時候,/tmp目錄下的情況: 現在我啟動一下hdfs三個程序: 這個時候有沒發現在/tmp目錄下多出了幾個檔案 這幾個檔案記錄的是什麼呢? 儲存的就是namenode這個程序的程序號,當我們關掉這幾個程序後,在/t
大資料開發之Hadoop篇----hdfs讀寫許可權操作
由於hdfs的結構和linux是差不多的,所以我們在hdfs的讀寫操作上也是會面臨許可權和路徑問題問題,先讓我們來看下這些都是些什麼問題。 這裡我先上傳了一個README.txt的檔案上去,通過hdfs dfs -ls /user/hadoop命令我們已經可以檢視到hdfs上有了這個檔案了
大資料開發之Hadoop篇----mapreduce概念以及架構
在我們瞭解了hdfs的一些基礎概念以後,我們現在就來進一步瞭解一下mapreduce的相關概念。 首先,mapreduce在hadoop體系裡面充當一個計算者的角色,但如我們之前所演示一樣我們在開啟hdfs和yarn時都有相關的程序,但mapreduce就是沒有的。mapreduce是直接執行在
大資料開發之Hadoop篇----hdfs垃圾回收機制配置
其實要啟動hdfs上的垃圾回收機制只需要配置兩個引數就可以了,也是在core-site.xml上配置就好了,我們先去官網看下這個兩引數的解釋。 官網的解釋是:Number of minutes after which the checkpoint gets deleted. If zero
大資料開發之Hadoop篇----提交作業到yarn上的流程
當一個mapreduce作業被提交到yarn上面的時候,他的流程是這樣的: 1,當client想yarn提交了作業後,就意味著想ResourceManager申請一個ApplicationMaster。這個時候RM(這裡我們將ResourceManager簡稱為RM,同理NodeManager為
大資料開發之Hadoop篇----hdfs讀流程
讀流程所涉及到的有client,NameNode和DataNode這個三個,我們來了解下這三個之間在讀流程裡都是幹什麼的。 1,當我們輸入一條讀入資料的命令的時候,如:hdfs dfs -ls / 或者 hdfs dfs -cat /user/hadoop/xxx時,client就通
大資料開發之Hadoop篇----hdfs dfsadmin命令
今天我們來了解一下hdfs dfsadmin這個命令,前面我們已經多次使用了hdfs dfs這個命令來對hdfs上的檔案進行操作了。而是在生產上面我們還是會遇到不同的情況。今天我們簡單講解一下hdfs dfsadmin中的兩個命令,以及他們在生產當中是怎樣使用的 1,hdfs dfsadmin
大資料開發之Hadoop篇----jps命令的剖析
我們在大資料的日常生產當中會經常使用到jps命令,如果問起很多人他們都會知道jps命令是用來幹什麼的,檢視java相關的程序。但是這個命令是屬於哪個元件提供的呢?最起碼可以肯定不是linux系統自帶的。 jps是屬於jdk自帶的命令,當你機器安裝了jdk同時將jdk配置到系統的環境變數當中後,在
大資料開發之Hadoop篇----YARN設計架構
1,Yarn架構設計 在hadoop當中無論是hdfs還是yarn都是服從主從設計的架構的,就是一個主節點用於管理整個叢集,而一堆的從節點就是實際工作者了。而在yarn當中,主節點程序為ResourceManager,從節點程序為NodeManager。我們簡單回顧一下提交作業到yarn上面的流
大資料開發之Hadoop---初始Hadoop
曾經的你驕橫跋扈,如今你審視人生,重新來過,重新選擇,相比同齡你可能晚了一些,遙看人生路路,你沒有輸,勞動可以改造一個人,堅持勞動,就可以改變人心!無論是腦力勞動還是體力勞動。 ————————————-前言送給努力改變自己的人! Hadoop: 廣義: 以hadoop軟體為主的生態圈 狹義
大資料開發學習Hadoop路線圖(詳細篇)
Hadoop發展到今天家族產品已經非常豐富,能夠滿足不同場景的大資料處理需求。作為目前主流的大資料處理技術,市場上很多公司的大資料業務都是基於Hadoop開展,而且對很多場景已經具有非常成熟的解決方案。 作為開發人員掌握Hadoop及其生態內框架的開發技術,就是進入大資料領域的必經之路。 下