
大資料-02-Scala入門
Scala 簡介
它是一門基於JVM的面向函式和麵向物件的程式語言, 它包含了求值表示式,閉包,切片操作,模式匹配,隱式轉換等特性。
- 可變數/不可變數
- 可變集合/不可變集合、集合操作
- 函式
- 值函式
- 求值表示式
- 函式柯里化
- 偏部分應用函式
- 偏函式
- 閉包
- 類(封裝、繼承、多型)
- 特質
- 單例類
- 伴生單例
- 模式匹配(_, * , reg)
- 隱匿轉換
Scala 安裝
環境
伺服器:ubuntu-16.04.3-desktop-amd64.iso
我們將要安裝的Scala版本是2.10.7, 確保你本地以及安裝了Java 8 JDK 版本,並且設定了 JAVA_HOME 環境變數及 JDK 的bin目錄。
安裝JDK
Ubuntu 16.04安裝Java JDK
Java JDK有兩個版本,一個開源版本Openjdk,還有一個oracle官方版本jdk。下面記錄在Ubuntu 16.04上安裝Java JDK的步驟。
安裝openjdk
更新軟體包列表:
sudo apt-get update安裝openjdk-8-jdk:
sudo apt-get install openjdk-8-jdk檢視java版本:
java -version
直接安裝Scala
下載地址https://downloads.lightbend.com/scala/2.10.7/scala-2.10.7.tgz, 並將其解壓縮到指定位置:
sudo mkdir /usr/local/scala # 建立一個根目錄
sudo tar -zxf scala-2.10.7.tgz -C /usr/local/scala # 解壓縮到指定位置(可選)下載scala整合開發環境
我這裡是下載IntelliJ IDEA >社群版本,https://www.jetbrains.com/idea/download 下載後解壓縮包,在bin資料夾下執行./idea.sh啟動,然後在引導頁面選擇新增Scala支援
新增scala到環境變數
打~/.bashrc檔案,在尾部新增如下內容
export SCALA_HOME=/usr/local/scala/scala-2.10.7 export PATH=${SCALA_HOME}/bin:$PATH
然後使環境變數生效
source ~/.bashrc檢查scala是否安裝成功
scala -version結果如圖所示:

簡單使用
進入命令解釋視窗:
scala 變數
不可變變數 val
val pi = 3.14可變變數 var
在scala中一切皆物件,即使數字都有方法。
var name = "John"
name = "rose"
var age = 30 # 但是沒有age++這種寫法
2.to(5) # res3: ...Inclusive = Range(2, 3, 4, 5)
1.+(1) # 1+1 = 2, 可變與不可變集合的對應關係
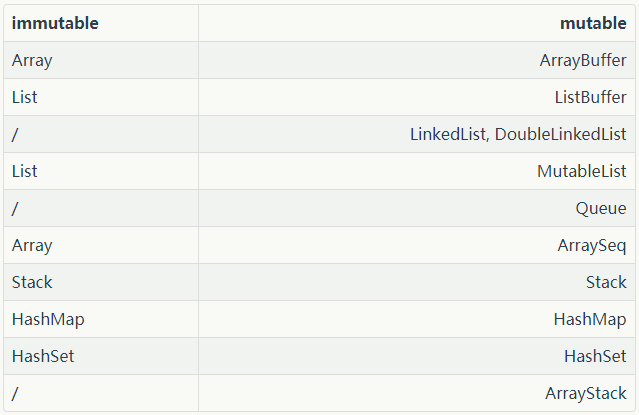
不可變集合
不可變集合一旦被建立,便不能改變;新增,刪除,修改元素操作返回的是新集合。
預設就是不可變集合scala.collection.immutable包。
val arr = Array[Int](10,20)
val arr1 = arr :+ 1 # 返回一個追加了元素的新集合, 這裡:表示原集合,+表示附加操作
val arr1 = 1 :+ arr # 返回一個追加了元素的新集合, 這裡:表示原集合,+表示附加操作
val arr1 = arr ++ arr # ++ 表示連線可變集合
可以新增,刪除,修改元素作用於原集合
如果要使用可變集合import scala.collection.mutable
val arr = mutable.ArrayBuffer[Int](10,20)
arr += 10 # 新增元素
val mutableSet = mutable.Set(1,2,3)定長陣列
陣列的長度在定義時已經確定, 在執行時長度不能被修改。能過new來進行預設初始化
val numArr = new Array[Int](10)
val strArr = new Array[String](10)變長陣列
變長陣列在程式執行過程中, 陣列的長度是可以進行調整的,最常用的變長陣列是ArrayBuffer, 使用它前必需顯示的引用包 import scala.collection.mutable._ 如下所示:
import scala.collection.mutable._
val strArr = ArrayBuffer[String]()
strArr += "hello" # 追加一個物件
# 用++= 來追加一個集合
strArr ++= Array("Welcome", "to", "china")
strArr.trimEnd(2) # 刪除末尾2個物件
# 遍歷陣列
for (i <- 0 until strArr.length) println(i)
# 常用函式
strArr.min
strArr.max
strArr.toString
strArr.mkString列表List
val liststr = List("Spark", "Hive", "Flink")
val liststr = "Spark" ::( "Hive" :: Nil) # 也可以用如下方式進行建立
# 常用函式有:
liststr.isEmpty
liststr.head
liststr.tail
liststr.reverse
# 連線兩個List
List("hello") ::: List("Boys" , "and", "Girls")
# 丟棄前n個元素
liststr.drop(1)
# zip操作
val nums = List(1,2,3)
val chars = List('1','2','3')
val z = nums zip chars #結果為z: List[(Int, Char)] = List((1,1), (2,2), (3,3))
# 伴生對像方法
List.range(2,6) # 構建某一值範圍內的List
List.range(2,6,2) # 加上步長引數
List.make(5, "boy") # 構建多個相同元素的List
List.unzip(z) # unzip 前面的z不變數函式
scala物件的構造可以使用apply函式, 而不需要new操作, 以下兩行是等價的:
val arr = Array(1,2,3,4)
val arr = Array.apply(1,2,3,4) 表示式
在scala表示式的是有結果的
var age = 30
val result = if (age >= 18) "adult" else "child"
val result = if (age >= 18) {1|2|3} # 最後一語句的值就是整個表示式的值
for (i <- 0 to 10 if i%2 == 0) {print(i)} # 產生集合 <- 是生成器generator
for (i <- 0 until (10,2)) {print(i)} # until 不右包含, 步長為2
var x = for (i <- 0 until (10,2)) yeild i # 快取結果i成一個vector集合
import scala.util.control.Breaks._ #SCALA 沒有break, 要引入Break對像
for (i <- 0 to 10) {if (i == 4) break ; print(i)} # 產生集合,輸出,
Scala 函式
Scala 函式宣告格式如下, 方括號為可選
def functionName ([引數列表]) : [return type]
Scala 函式定義格式如下:
def functionName ([引數列表]) : [return type] = {
function body
return [expr] # 最後一句可以省略return 作為返回值
}
例子如下:
def printMe( ) : Unit = {
println("Hello, Scala!")
}def sum(numbers : Int*) = {
var result = 0;
for (elem <- numbers) result += elem;
result
}
Scala 值函式 (函式字面量 or 函式變數 or 函式指標)
Scala 值函式, 本質上它是一個量指向一段計算程式碼,定義格式如下:
val literalName = ([引數列表]) > {
body
expr # 作為結果值
}
它沒有返回類, 而是一個對映, 通過=> 符號將左邊型別轉到右邊型別。如果只有一行是{}可以省略; 形如(x:Int,y:Int)=>{x+y}的表示式稱為Lambda表示式。
將值函式(函式變數)作為另一個函式的輸入引數:
val increment=(x:Int)=>x+1
val arrInt = Array(1,2,3,4)
arrInt.map(increment) # 這是map就是高階函式,即引數或者返回值含有值函式
# 其它高階函式
arrInt.flatMap # 將集合中各元素得到一個集合,並扁平合併成一個集合
arrInt.reduce # 使用2元操作在一個集合上,返回一個值
arrInt.filter # 返回滿足條件的集合值
arrInt.fold # 帶有初始值的reduce
閉包 (Closure)
John D.Cook 給物件和閉包下過一個經典的定義:"An object is data with function. A closure is a function with data", 由此閉包是由函式和執行時資料決定的。 事實上, 閉包可以理解為函式和它的上下文, 例如:
var i = 15
val f=(x:Int)=>x+i
f(10) # 結果是25函式柯里化(currying)(就是括號化, 很多多括號)
在前面所述, 當高價函式返回的是一個函式物件是, 就可能會存在fun(1)(2)這種呼叫方式, 那麼如果顯示宣告這樣一個形式的函式,也就是函式柯里化, 它的定義形式如下:
def curryFunctionName (param_x:Int)(param_y:Int)(param_z:Int):Int = {
}例項如下:
def mul(x:Int)(y:Int):Int={x * y}由此可見, 呼叫柯里化函式時, 引數必須要示完整。所以它不具備傳部分引數,然後返回某個物件的能力。
部分應用函式
為了應對柯里化函式對完整引數的限制, 提出部分應用函式, 即先輸入部分引數, 呼叫返回一箇中間物件, 然後通過中間物件進行後續呼叫, 使得柯里化+部分應用函式類似高階函式的表現形式:
# 生成一個部分應用函式
val paf = mul(10) _
# 呼叫部分應用函式
paf(5) # 結果為50不只柯里化函式有部分應用函式, 普通函式也有部分函式, 例如:
def product (x1:Int, x2:Int, x3:Int) = x1 * x2 * x3
val paf = product(_:Int, 2, 3)
paf(2) # 結果12偏函式
它是數學函式上的,自變數與因變數, 當在值域找不到對應目標時,就報錯。
trait PartialFunction[-A, +B] extends (A) ⇒ B示例如下:
val isEven : PartialFunction[Int, String] = {
case x if x % 2 == 0 => x + "is even"
}
isEven(10) # 這個OK
isEven(11) # 這裡報錯Scala 下劃線
1、存在性型別:Existential types
def foo(l: List[Option[_]]) = ...2、高階型別引數:Higher kinded type parameters
case class AK[_],T3、臨時變數:Ignored variables
val _ = 54、臨時引數:Ignored parameters
List(1, 2, 3) foreach { _ => println("Hi") }5、通配模式:Wildcard patterns
Some(5) match { case Some() => println("Yes") }
match {
case List(1,,) => " a list with three element and the first >element is 1"
case List(*) => " a list with zero or more elements "
case Map[,] => " matches a map with any key type and any value >type "
case _ =>
}
val (a, ) = (1, 2)
for ( <- 1 to 10)6、通配匯入:Wildcard imports
import java.util._7、隱藏匯入:Hiding imports
// Imports all the members of the object Fun but renames Foo to Bar
import com.test.Fun.{ Foo => Bar , _ }// Imports all the members except Foo. To exclude a member rename it to >
import com.test.Fun.{ Foo => , _ }8、連線字母和標點符號:Joining letters to punctuation
def bang_!(x: Int) = 59、佔位符語法:Placeholder syntax
List(1, 2, 3) map (_ + 2)
_ + _
( (: Int) + (: Int) )(2,3)val nums = List(1,2,3,4,5,6,7,8,9,10)
nums map (_ + 2)
nums sortWith(>)
nums filter (_ % 2 == 0)
nums reduceLeft(+)
nums reduce (_ + )
nums reduceLeft( max )
nums.exists( > 5)
nums.takeWhile(_ < 8)10、偏應用函式:Partially applied functions
def fun = {
// Some code
}
val funLike = fun _List(1, 2, 3) foreach println _
1 to 5 map (10 * _)
//List("foo", "bar", "baz").map(_.toUpperCase())
List("foo", "bar", "baz").map(n => n.toUpperCase())11、初始化預設值:default value
var i: Int = _12、作為引數名:
//訪問map
var m3 = Map((1,100), (2,200))
for(e<-m3) println(e._1 + ": " + e._2)
m3 filter (e=>e._1>1)
m3 filterKeys (_>1)
m3.map(e=>(e._1*10, e._2))
m3 map (e=>e._2)//訪問元組:tuple getters
(1,2)._213、引數序列:parameters Sequence
_*作為一個整體,告訴編譯器你希望將某個引數當作引數序列處理。例如val s = >sum(1 to 5:_*)就是將1 to 5當作引數序列處理。
//Range轉換為List
List(1 to 5:_*)//Range轉換為Vector
Vector(1 to 5: _*)//可變引數中
def capitalizeAll(args: String*) = {
args.map { arg =>
arg.capitalize
}
}val arr = Array("what's", "up", "doc?")
capitalizeAll(arr: _*)
Scala 面向物件程式設計
類的定義
Scalal中的類與Java語言一樣通過class來定義:
import scala.beans.BeanProperty // 如果使用BeanProperty需要引入
class Person{
// 成員變數必須初始化, 這裡會生成scala的getter與setter
var name:String = null // getter就是name, setter就是name_
@BeanProperty var age:Int = 0 //這裡會生成Java風格的setAge(),getAge()
}類成員訪問
val p = new Person
p.name_= ("John") // 顯示呼叫setter方法修改成員變數, 這裡是_= () 方法
p.name = "John" // 直接修改成員變數name, 實際也是呼叫p.name_= 方法
p.setAge(1)
p.getAge()主建構函式
為了簡化建構函式與類定義, scala 提供了主建構函式,集定義與構造於一身:
// 注意有個var關鍵字
class Person(var name:String, var age:Int) //這就完成了上述宣告與構造。
class Person(var name:String, var age:Int=18)//這樣就帶預設引數了輔助建構函式
為了實現多個建構函式,且不帶預設引數的, 提出輔助建構函式。連帶好處還避免多處使用類名字的問題, 就是使用this關鍵字:
class Person{
private age:Int = 18
private name:String = null
def this(name:String){ # 這裡就是輔助建構函式
this() # 呼叫無參的預設主建構函式
this.name = name
}
def this(name:String,age:Int){
this(name)
this.age = age
}
}繼承 和 多型
# 注意新新增欄位有var關鍵, 繼承的沒有,構造時為傳遞引數值
class Student(name:String, age:Int, var studentNo:String) extends Person(name,age){
override def toString:String = super.toString + ", studentNo=" + studentNo
}
var p = new Person("bill")
p = new Student("John", 33, "12345")
p.toString注: 如果類或者trait宣告前加sealed 關鍵字,則其所有派生都必須放在同一個檔案中
預設訪問控制(隱藏)
public : 是預設選項, 類,伴生單例,子類, 外部都可以訪問
protected : 類,伴生單例,子類可以訪問,外部不可以訪問
private : 類,伴生單例可以訪問,子類,外部不可以訪問
private[this]: 類可以訪問,伴生單例,子類,外部不可以訪問
訪問控制符,還可以放在主建構函式中,起到相信的效果:
// 這裡name的控制符是protected,而age就是預設的控制符 public
class Person(protected var name:String, var age:Int)
// 如果在主建構函式中, 未使用val ,var關鍵字來定義欄位,就是預設為private[this]
class Person(name:String, age:Int)抽象類
就是用abstract來定義類, 抽象類可以擁有抽象成員,即不初始化成員
abstract class Person{
var age:Int = 0 // 具體成員
var name:String // 抽象成員
def walk() // 抽象成員
override def toString = name // 具體成員
}單例物件(類)
在java中經常會用到靜態成員變數, 但是在Scala沒有並不支援這項特性, 取而代之的是單例物件, 它是通過object 來宣告的, 示例如下:
object GlobalID { var gid:Int = 0 }
GlobalID.gid伴生物件與伴生類
就是名字相同的類與單例物件,可以相互訪問私有成員。它們分別叫做伴生類與伴生物件(單例)。 類似C++的friend關係
class Dog {
private var name = "張"
def printName(): Unit = { //在Dog類中訪問其伴生物件的私有屬性
(Dog.CONSTART + name)
}
}
object Dog {
private val CONSTART = "汪"
def main(args: Array[String]): Unit = {
val p = new Dog
println(p.name)
p.name = "大黃"
p.printName()
}
}trait 特質
Scala用trait關鍵字封裝了成員方法和成員變數, 在類通過extends或with關鍵字來混入trait。一個類可以混入多個trait。
它起到了interface介面的作用,以及struct結構嵌入的作用等。
它的定義示例如下:
// 可克隆特質
trait Closable{
def close():Unit
}
// 通過extends 來實現特質
class File(var name:String) extends Closable{
def close():Unit = println(s"File $name has been closed")
}
// 也可以如下
class File(var name:String) extends java.io.File(name) with Closable{
def close():Unit = println(s"File $name has been closed")
}
// 在trait類似抽象類, 在trait中可以有抽象成員, 成員方法, 具體成員和具體方法。
trait PersonDAO{
// 具體成員變數
var recordNum:Long = _
// 具體成員方法
def add(p:Person):Unit={
println("Invoking add Method..")
}
// 抽象方法 更新方法
def update(p:Person)
// 抽象方法 刪除方法
def delete (id:Int)
}注意, 使用trait出現菱形繼承問題時, 使用的是最右深度優先遍歷演算法查詢呼叫的方法。
提前定義與懶載入
提前定義是指在常規構造之前將變數初始化, 下述的構造會出現空指標。
class FileLogger{
var fileName : String
val fileOutput = new PrintWriter(fileName:String)
def log(msg:String) : Unit = {
fileOutput.print(msg)
fileOutput.flush()
}
}
// 正常構造使用,就會報錯
val s = new {
// 提前定義
override val fileName = "file.log"
} with FileLogger
s.log("predefined variable")懶載入, 上述提前定義的方式不夠優雅, 推薦使用下面的懶載入方式
class FileLogger{
var fileName : String
// 這裡的語句的不會執行,只等真正使用該變數時才會執行
lazy val fileOutput = new PrintWriter(fileName:String)
def log(msg:String) : Unit = {
fileOutput.print(msg)
fileOutput.flush()
}
}
val s = new FileLogger
s.fileName = "file.log"
s.log("predefined variable")
模式匹配
匹配是一個以match關鍵連線的簡單表示式, 結果為match匹配的執行結果
// 1.簡單匹配
val (first, second) = (1,2)
// 2.常量匹配
for (i <- 1 to 5){
i match{
// 常量匹配
case 1 => println(1)
// 3.變數匹配
case x if (x%2 == 0) => println(s"Mode 2 equal zero")
case _ => printlen("other")
}
}
// 4.case類匹配
case class Dog(val name:String, val age:Int) // 以case關鍵字定義開始
case class Person(var name:String, var age:Int)
case class Student(var name:String, var age:Int)
def myMatch(x:AnyRef) = x match{
// 4.1case類構造匹配
case Dog(name, age) => println(s"Dog name=$name, age=$age")
// 4.2case類型別匹配
case x:Person => pringln(s"this is a person")
// 4.3case類變數匹配
case [email protected](_,_) => println(s"Student:" + s)
case _ => println("other")
}
val dog = new Dog("jacky", 11)
val p = new Person("Peter", 22)
val std = new Student("Jim", 33)
myMatch(dog)
myMatch(p)
myMatch(std)
// 5.序列模式
def myMatch(x:AnyRef) = x match{
// 序列模式
case Array(first,second) => println(s"first:$first, second:$second")
case Array(first,_,third,_*) => println(s"first:$first, third:$third")
// 6.元組模式
case (first,second) => println(s"tuple first:$first, second:$second")
case (first,_, third) => println(s"tuple first:$first, third:$third")
case _ =>
}
val arr = Array(1,2,3,4)
myMatch(arr)
val arr = Array(1,2)
myMatch(arr)
val tuple = ("nest",1)
myMatch(tuple)正則表示式
val rgex = """(\d\d\d\d)-(\d\d)-(\d\d)""".r // .r 將字串轉化正則表示式
// 以下是幾個常用方法
for (date <- rgex.findAllIn("2015-12-31 2016-02-30")) println(date)
for (date <- rgex findAllMatchIn "2015-12-31 2016-02-30") println(date.groupCount)for 中的模式匹配
// 常量匹配
for ((name, 18)<-Map("jack"->22, "tom"->18, "ben"->7)) println(name)
// 變數匹配
for ((name,age)<-Map("jack"->22, "tom"->18, "ben"->7)) println(name,age)
// 變數繫結
for ((name, [email protected])<-Map("jack"->22, "tom"->18, "ben"->7)) println(name,e)
// 型別匹配
for ((name, age:Int)<-Map("jack"->22, "tom"->18, "ben"->7)) println(name,age)
// 構造匹配
// 序列匹配隱式轉換
隱式轉換函式 - 將引數型別轉換為返回型別
// 隱式轉換函式的定義
// 它是通過引數型別與返回型別確定的
// 因而不能有這樣的兩個函式,它們引數與返回值型別都相同
implicit def int2float(x:Int):Float = x.toFloat 隱式轉換類 - 將引數型別轉換為隱式類類名型別
// 這就是把字串型別轉換為Dog類
implicit class Dog(val name:String)應用程式物件
object MyApp {
def main(args:Array[String]){
println("App v1")
}
}相關推薦
大資料-02-Scala入門
Scala 簡介 它是一門基於JVM的面向函式和麵向物件的程式語言, 它包含了求值表示式,閉包,切片操作,模式匹配,隱式轉換等特性。 可變數/不可變數 可變集合/不可變集合、集合操作 函式 值函式 求值表示式 函式柯里化 偏部分應用函式 偏函式 閉包 類(封裝、繼承、多型) 特質 單例類 伴生單例 模式匹配
大資料學習 ------ Scala入門
1.1 為什麼要學Scala語言[1] 1.優雅:這是框架設計師第一個要考慮的問題,框架的使用者是應用開發程式設計師,API是否優雅直接影響使用者體驗。 Martin OrderSke (scala發人) Epel瑞士科技大學 Javac是Matin編寫的
大資料之scala(四) --- 模式匹配,變數宣告模式,樣例類,偏函式,泛型,型變,逆變,隱式轉換,隱式引數
一、模式匹配:當滿足case條件,就終止 ---------------------------------------------------------- 1.更好的switch var x = '9'; x match{ case
大資料之scala(三) --- 類的檢查、轉換、繼承,檔案,特質trait,操作符,apply,update,unapply,高階函式,柯里化,控制抽象,集合
一、類的檢查和轉換 -------------------------------------------------------- 1.類的檢查 isInstanceOf -- 包括子類 if( p.isInstanceOf[Employee]) {
大資料之scala(二) --- 對映,元組,簡單類,內部類,物件Object,Idea中安裝scala外掛,trait特質[介面],包和包的匯入
一、對映<Map> ----------------------------------------------------- 1.建立一個不可變的對映Map<k,v> ==> Map(k -> v) scala> val map
大資料之scala(一) --- 安裝scala,簡單語法介紹,條件表示式,輸入和輸出,迴圈,函式,過程,lazy ,異常,陣列
一、安裝和執行Scala解釋程式 --------------------------------------------- 1.下載scala-2.11.7.msi 2.管理員執行--安裝 3.進入scala/bin,找到scala.bat,管理員執行,進入scala命
大資料(一)——概念入門
最近在B站上看一套44集的大資料教程——經典Hadoop分散式系統基礎架構。想通過對Hadoop的學習,跳到大資料領域當中。作為大資料的開篇,主要是做一些大資料掃盲,並且重點介紹Hadoop需要學些什麼。 1.何為大資料 IBM提出大資料具有5V特點:Volume(大量)、Velocit
大資料是什麼?0基礎大資料怎麼進行入門學習?
0基礎我們該怎麼進行大資料入門學習呢?帶你們一起來學習。 一、大資料是什麼? 大資料,big data,《大資料》一書對大資料這麼定義,大資料是指不能用隨機分析法(抽樣調查)這樣捷徑,而採用所有資料進行分析處理。 這句話至少傳遞兩種資訊:。 1、大資料是海量的資料 2、大資料處理
大資料ZooKeeper快速入門
課程介紹 ZooKeeper是一個分散式的,開放原始碼的分散式應用程式協調服務,是Google的Chubby一個開源的實現,是Hadoop和Hbase的重要元件。它是一個為分散式應用提供一致性服務的軟體,提供的功能包括:配置維護、域名服務、分散式同步、組服務等。 ZooKeepe
大資料Hadoop快速入門
Hadoop是一個由Apache基金會所開發的分散式系統基礎架構。 使用者可以在不瞭解分散式底層細節的情況下,開發分散式程式。充分利用叢集的威力進行高速運算和儲存。 Hadoop實現了一個分散式檔案系統(Hadoop Distributed File System),簡稱HDFS
大資料架構師入門學習
經常有初學者在部落格和QQ問我,自己想往大資料方向發展,該學哪些技術,學習路線是什麼樣的,覺得大資料很火,就業很好,薪資很高。如果自己很迷茫,為了這些原因想往大資料方向發展,也可以,那麼我就想問一下,你的專業是什麼,對於計算機/軟體,你的興趣是什麼?是計算機專業,對作業系統、硬體、網路、伺服器感興趣
看完這些乾貨帖,大資料產品從入門到精通
摘要: 看完這些乾貨帖,瞭解大資料產品應用場景 歡迎來到“MVP教你玩轉阿里雲”系列教程,在這裡,你將看到各行各業數字化轉型的一線實踐,學到資深開發者的經驗結晶。 你將以雲端計算領域的技術領袖為師,加速瞭解阿里雲技術產品和各行業數字化轉型的場景。 點選關注,在真實業務場景裡,加快技術成長,看懂數字中
大資料學習初級入門教程(一) —— Hadoop 2.x 的安裝、啟動和測試
大資料最基礎的就是資料的儲存和計算,而 Hadoop 就是為儲存和計算而生,是最基礎的大資料處理工具。這篇簡單寫寫 Hadoop 2.x 的安裝,啟動和測試。 一、準備環境 大資料環境的部署,一般都是叢集,機器數量為奇數,這裡以 5 臺機器為例,作業系統為 CentOS 6.9_x64;
大資料學習入門看什麼書?大資料新手怎麼入門?
大資料意味著我們不能用隨機分析方法(抽樣調查)作為捷徑,而是用所有的資料進行分析和處理。這句話至少傳達了兩種資訊:大資料就是海量資料,大資料處理沒有捷徑,這就對分析和處理技術提出了更高的要求。 事實上,簡單來說,大資料是分析和挖掘非抽樣資料的全部量,以輔助決策。大資料的
大資料學習-scala作業(2)
package com.jn.spark.lesson1 import scala.collection.mutable.ArrayBuffer /** * 作業1:移除一個數組中第一個負數後的所有負數,(第一個負數要保留,其餘的負數都刪除) * @author 江
子雨大資料之Spark入門教程
【版權宣告】部落格內容由廈門大學資料庫實驗室擁有版權,未經允許,請勿轉載!版權所有,侵權必究! Spark最初誕生於美國加州大學伯克利分校(UC Berkeley)的AMP實驗室,是一個可應用於大規模資料處理的快速、通用引擎。2013年,Spark加入Apache孵化器專案後,開始獲得迅猛的發展,如今已
spark大資料架構初學入門基礎詳解
Spark是什麼 a) 是一種通用的大資料計算框架 b) Spark Core 離線計算 Spark SQL 互動式查詢 Spark Streaming 實時流式計算 Spark MLlib 機器學習 Spark GraphX 圖計算 c) 特點:
大資料系列-Scala學習4
問題: 1、Map(對映)的操作 2、Tuple(元組)的操作 1、對映 對映是鍵/值對偶的 val scores=Map("Alice"->10,"Bob"->3,"Cindy"->8) 上述程式碼構造出一個不可變的Map[St
大資料學習——HBase 入門
HBase 學習環境 shiyanlou 《HBase介紹、安裝與應用案例》 - CentOS6.6 64位 - JDK 1.7.0_55 64位 - Hadoop 1.1.2 Hbase 介紹 HBase ——Hadoop Databa
沒有基礎能學大資料嗎 怎麼入門學習比較好
沒有基礎能學大資料嗎,怎麼入門學習比較好?隨著大資料技術的火熱發展,很多企業紛紛高薪誠聘大資料技術人才。不僅很多技術人員紛紛轉型大資料工程師,還有很多零基礎小白也想學習大資料技術。沒有基礎學大資料,要參加鄭州大資料培訓嗎? 答案自然是否定的。參不參加專業學習肯定是要看個人意願還有個