
Tensorflow 原始碼分析-會話與執行緒池之間的關係
1. Tensorflow 的sessionFactory
建立新的會話,tensorflow使用了多工廠模式,在不同的場景下使用不同的工廠, 使用什麼工廠模式由傳遞進來的SessionOptions來決定。
1.1 註冊工廠
Tensorflow 提供了可以註冊多會話工廠的模式,允許不同的模組註冊自己的會話工廠
void SessionFactory::Register(const string& runtime_type, SessionFactory* factory) { mutex_lock l(*get_session_factory_lock()); if (!session_factories()->insert({runtime_type, factory}).second) { LOG(ERROR) << "Two session factories are being registered " << "under" << runtime_type; } }
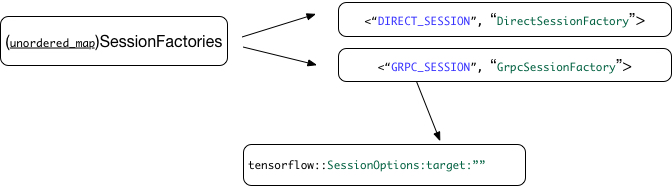
預設的tensorflow提供了兩種factoy,一個是DirectSession單機,一個是GrpcSession叢集。
使用什麼factory由傳遞的sessionoptions的target來決定
2. Tensorflow 的session
2.1 初始化Session
在session.cc程式碼中,通過NewSession來初始化會話
在程式碼中,我們可以看到通過factory來newSession,對單機來說也就是在前面提到的DirectSessionSession* NewSession(const SessionOptions& options) { SessionFactory* factory; const Status s = SessionFactory::GetFactory(options, &factory); if (!s.ok()) { LOG(ERROR) << s; return nullptr; } return factory->NewSession(options); }
Session* NewSession(const SessionOptions& options) override { // Must do this before the CPU allocator is created. if (options.config.graph_options().build_cost_model() > 0) { EnableCPUAllocatorFullStats(true); } std::vector<Device*> devices; const Status s = DeviceFactory::AddDevices( options, "/job:localhost/replica:0/task:0", &devices); if (!s.ok()) { LOG(ERROR) << s; return nullptr; } DirectSession* session = new DirectSession(options, new DeviceMgr(devices), this); { mutex_lock l(sessions_lock_); sessions_.push_back(session); } return session; }
2.2 平行計算
對Tensorflow的每個執行(op)都是需要進行計算的,對同一個會話來說,為了快速計算需要將op進行平行計算,對叢集來說就是叢集運算,而對單機版來說就是使用多執行緒來進行運算,也就是常說的執行緒池。
接下的部落格主要是增對單機的並行運算,也就是directsession中的執行緒池
在tensorflow中有三種session和執行緒池的關係
- 單個會話可以設定多個執行緒池,在初始化會話池的時候,會依據sessionoptions的配置,讀取多個執行緒池的配置,生成多個執行緒池的vector, 如果 thread_pool_options. global_name為空,代表是自己owned的需要自己關閉
- 單個會話設定單個執行緒池,在初始化會話池的時候,會依據sessionoptions的配置use_per_session_threads,讀取單執行緒池的配置,生成單個會話相關的獨立執行緒池, 需要自己關閉
- 多個會話共享相同的執行緒池,在初始化會話池的時候,建立所有會話共享的執行緒池,該執行緒池是全域性共享,無法關閉。
在config.proto protocol buffer我們可以看到定義的配置協議的格式: ConfigProto,ThreadPoolOptionProto
message ThreadPoolOptionProto {
// The number of threads in the pool.
//
// 0 means the system picks a value based on where this option proto is used
// (see the declaration of the specific field for more info).
int32 num_threads = 1;
// The global name of the threadpool.
//
// If empty, then the threadpool is made and used according to the scope it's
// in - e.g., for a session threadpool, it is used by that session only.
//
// If non-empty, then:
// - a global threadpool associated with this name is looked
// up or created. This allows, for example, sharing one threadpool across
// many sessions (e.g., like the default behavior, if
// inter_op_parallelism_threads is not configured), but still partitioning
// into a large and small pool.
// - if the threadpool for this global_name already exists, then it is an
// error if the existing pool was created using a different num_threads
// value as is specified on this call.
// - threadpools created this way are never garbage collected.
string global_name = 2;
};message ConfigProto {
// Map from device type name (e.g., "CPU" or "GPU" ) to maximum
// number of devices of that type to use.If a particular device
// type is not found in the map, the system picks an appropriate
// number.
map<string, int32> device_count = 1;
// The execution of an individual op (for some op types) can be
// parallelized on a pool of intra_op_parallelism_threads.
// 0 means the system picks an appropriate number.
int32 intra_op_parallelism_threads = 2;
// Nodes that perform blocking operations are enqueued on a pool of
// inter_op_parallelism_threads available in each process.
//
// 0 means the system picks an appropriate number.
//
// Note that the first Session created in the process sets the
// number of threads for all future sessions unless use_per_session_threads is
// true or session_inter_op_thread_pool is configured.
int32 inter_op_parallelism_threads = 5;
// If true, use a new set of threads for this session rather than the global
// pool of threads. Only supported by direct sessions.
//
// If false, use the global threads created by the first session, or the
// per-session thread pools configured by session_inter_op_thread_pool.
//
// This option is deprecated. The same effect can be achieved by setting
// session_inter_op_thread_pool to have one element, whose num_threads equals
// inter_op_parallelism_threads.
bool use_per_session_threads = 9;
// This option is experimental - it may be replaced with a different mechanism
// in the future.
//
// Configures session thread pools. If this is configured, then RunOptions for
// a Run call can select the thread pool to use.
//
// The intended use is for when some session invocations need to run in a
// background pool limited to a small number of threads:
// - For example, a session may be configured to have one large pool (for
// regular compute) and one small pool (for periodic, low priority work);
// using the small pool is currently the mechanism for limiting the inter-op
// parallelism of the low priority work.Note that it does not limit the
// parallelism of work spawned by a single op kernel implementation.
// - Using this setting is normally not needed in training, but may help some
// serving use cases.
// - It is also generally recommended to set the global_name field of this
// proto, to avoid creating multiple large pools. It is typically better to
// run the non-low-priority work, even across sessions, in a single large
// pool.
repeated ThreadPoolOptionProto session_inter_op_thread_pool = 12;
// Assignment of Nodes to Devices is recomputed every placement_period
// steps until the system warms up (at which point the recomputation
// typically slows down automatically).
int32 placement_period = 3;
// When any filters are present sessions will ignore all devices which do not
// match the filters. Each filter can be partially specified, e.g. "/job:ps"
// "/job:worker/replica:3", etc.
repeated string device_filters = 4;
// Options that apply to all GPUs.
GPUOptions gpu_options = 6;
// Whether soft placement is allowed. If allow_soft_placement is true,
// an op will be placed on CPU if
// 1. there's no GPU implementation for the OP
// or
// 2. no GPU devices are known or registered
// or
// 3. need to co-locate with reftype input(s) which are from CPU.
bool allow_soft_placement = 7;
// Whether device placements should be logged.
bool log_device_placement = 8;
// Options that apply to all graphs.
GraphOptions graph_options = 10;
// Global timeout for all blocking operations in this session.If non-zero,
// and not overridden on a per-operation basis, this value will be used as the
// deadline for all blocking operations.
int64 operation_timeout_in_ms = 11;
// Options that apply when this session uses the distributed runtime.
RPCOptions rpc_options = 13;
// Optional list of all workers to use in this session.
ClusterDef cluster_def = 14;
// If true, any resources such as Variables used in the session will not be
// shared with other sessions.
bool isolate_session_state = 15;
// Next: 16
};
而關於單個會話建立多個執行緒池,主要適用於在會話執行的過程中,可以主動選擇不同的執行緒池,還記得在呼叫session.run的時候可以傳遞runoption麼?我們還是直接來看協議
message RunOptions {
// TODO(pbar) Turn this into a TraceOptions proto which allows
// tracing to be controlled in a more orthogonal manner?
enum TraceLevel {
NO_TRACE = 0;
SOFTWARE_TRACE = 1;
HARDWARE_TRACE = 2;
FULL_TRACE = 3;
}
TraceLevel trace_level = 1;
// Time to wait for operation to complete in milliseconds.
int64 timeout_in_ms = 2;
// The thread pool to use, if session_inter_op_thread_pool is configured.
int32 inter_op_thread_pool = 3;
// Whether the partition graph(s) executed by the executor(s) should be
// outputted via RunMetadata.
bool output_partition_graphs = 5;
// EXPERIMENTAL. Options used to initialize DebuggerState, if enabled.
DebugOptions debug_options = 6;
// When enabled, causes tensor alllocation information to be included in
// the error message when the Run() call fails because the allocator ran
// out of memory (OOM).
//
// Enabling this option can slow down the Run() call.
bool report_tensor_allocations_upon_oom = 7;
reserved 4;
}就是引數inter_op_thread_pool,在tensorflow中通訊協議,配置都是基於google 的protocol buffer的,所以物件的相關函式和程式碼,是通過編譯協議後長生的,比如:
thread::ThreadPool* pool =
thread_pools_[run_options.inter_op_thread_pool()].first;中的inter_op_thread_pool函式,這個在原始碼中無法找到,tensorflow在編譯過程中會基於config.proto,自動生成c++的程式碼 目錄在genfiles/tensorflow/core/protobuf/config.pb.h 和config.pb.cc
2.2.1 執行緒池的執行緒數
int32 NumInterOpThreadsFromSessionOptions(const SessionOptions& options) {
const int32 t = options.config.inter_op_parallelism_threads();
if (t != 0) return t;
// Default to using the number of cores available in the process.
return port::NumSchedulableCPUs();
}通過配置中的inter_op_parallelism_threads,在多個執行緒池的化的情況下,讀取的就是每個執行緒池的num_threads了,如果沒有配置,那麼預設的數量將是系統有效的cpu數目
2.2.2 執行緒池的實現
tensowflow的執行緒池的實現是呼叫Eigen的執行緒池
struct ThreadPool::Impl : Eigen::ThreadPoolTempl<EigenEnvironment> {
Impl(Env* env, const ThreadOptions& thread_options, const string& name,
int num_threads, bool low_latency_hint)
: Eigen::ThreadPoolTempl<EigenEnvironment>(
num_threads, low_latency_hint,
EigenEnvironment(env, thread_options, name)) {}
void ParallelFor(int64 total, int64 cost_per_unit,
std::function<void(int64, int64)> fn) {
CHECK_GE(total, 0);
CHECK_EQ(total, (int64)(Eigen::Index)total);
Eigen::ThreadPoolDevice device(this, this->NumThreads());
device.parallelFor(
total, Eigen::TensorOpCost(0, 0, cost_per_unit),
[&fn](Eigen::Index first, Eigen::Index last) { fn(first, last); });
}
};相關推薦
Tensorflow 原始碼分析-會話與執行緒池之間的關係
1. Tensorflow 的sessionFactory建立新的會話,tensorflow使用了多工廠模式,在不同的場景下使用不同的工廠, 使用什麼工廠模式由傳遞進來的SessionOptions來決定。1.1 註冊工廠Tensorflow 提供了可以註冊多會話工廠的模式,
muduo原始碼分析:ThreadPool 執行緒池的實現
原始碼: https://github.com/chenshuo/muduo/blob/master/muduo/base/ThreadPool.h https://github.com/chenshuo/muduo/blob/master/muduo/base/ThreadPool.cc
Android中的執行緒與執行緒池
執行緒與執行緒池 概括 執行緒分為主執行緒和子執行緒. 主執行緒主要是用來處理和介面相關的事情, 子執行緒主要是用來做耗時的操作,比如 載入遠端資料,資料庫操作等。 在android 中,處理直接使用 Thread以外。 android 還提供了很多類似執行緒的操作便於我們
第三十八天 GIL 程序池與執行緒池
今日內容: 1.GIL 全域性直譯器鎖 2.Cpython直譯器併發效率驗證 3.執行緒互斥鎖和GIL對比 4.程序池與執行緒池 一.全域性直譯器鎖 1.GIL:全域性直譯器鎖 GIL本質就是一把互斥鎖,是夾在直譯器身上的 統一程序內的所有執行緒都需要先搶到GIL鎖,才能執
併發新特性—Executor 框架與執行緒池
蘭亭風雨 · 更新於 2018-11-14 09:00:31 併發新特性—Executor 框架與執行緒池 Executor 框架簡介 在 Java 5 之後,併發程式設計引入了一堆新的啟動、排程和管理執行緒的API。Executor 框架便是 Java 5 中引入的,其內部使用了執行緒池機
執行緒的建立與執行緒池ThreadPoolExecutor,Executors
執行緒的建立與執行緒池及執行緒池工具類 1.執行緒的建立方式 1.1繼承Thread類重寫run方法 public class Test { p
【JVM第九篇】:Executor框架與執行緒池
Executor框架簡介 在Java 5之後,併發程式設計引入了一堆新的啟動、排程和管理執行緒的API。Executor框架便是Java 5中引入的,其內部使用了執行緒池機制,它在java.util.cocurrent 包下,通過該框架來控制執行緒的啟動、執行和關閉,可以簡化併發程式設計
池與執行緒池 技術點 目錄 1. 執行緒池作用: 提升效能 1 2. 使用流程 1 3. 執行緒與執行緒池的監控 jvisual 1 4. 執行緒常用方法 2 5. 執行緒池相關概念 2 5.1. 佇列
池與執行緒池 技術點 目錄 1. 執行緒池作用: 提升效能 1 2. 使用流程 1 3. 執行緒與執行緒池的監控 jvisual 1 4. 執行緒常用方法 2 5. 執行緒池相關概念 2 5.1. 佇列 &n
c++11多執行緒與執行緒池
最近需要開發一個高效能運算庫,涉及到c++多執行緒的應用,上次做類似的事情已經是4年多以前了,印象中還頗有些麻煩。悔當初做了就算了,也沒想著留點記錄什麼的。這次又研究了一番,發現用上c++11特性之後,現在已經比較簡單了,在此記錄一下。 最簡單的多執行緒情況,不涉及公共變數,各個執行緒之間獨
執行緒與執行緒池
1.Callable和Runnable I Callable定義的方法是call,而Runnable定義的方法是run。 II Callable的call方法可以有返回值,而Runnable的run方法不能有返回值。 III Callable的call方法可丟擲異常,而Runnable的ru
再入鎖,執行緒安全佇列與執行緒池串想
題中這三者是有一環扣一環的聯絡的,在此做一個總結加深理解。 再入鎖Reentrantlock主要是和synchronized關鍵字作區別,都是加鎖但是排程單位不同。synchronized是以呼叫次數為單位,即被synchronized修飾的方法或者程式碼塊每被執行緒執行一次,都有一個獲取鎖釋放
Hystrix 服務的隔離策略對比,訊號量與執行緒池隔離的差異
支援的隔離策略 Hystrix支援的 hytrix支援執行緒池隔離和訊號量隔離 訊號量的隔離: it executes on the calling thread and concurrent requests are limited by the semaphore count - 引自
Dubbo學習筆記8:Dubbo的執行緒模型與執行緒池策略
Dubbo預設的底層網路通訊使用的是Netty,服務提供方NettyServer使用兩級執行緒池,其中 EventLoopGroup(boss) 主要用來接受客戶端的連結請求,並把接受的請求分發給 EventLoopGroup(worker) 來處理,boss和worker執
Java操作Shell指令碼 + Java.lang.Process的原理分析 + 程序與執行緒的分析 + 多執行緒理解
目錄 什麼是程序 什麼是執行緒 總結: 參考連結 java程式中要執行linux命令主要依賴2個類:Process和Runtime 程序執行緒的關係 什麼是程序 簡單理解,在多工系統中,每一個獨立執行的程式就是一個程
詳解 Tomcat 的連線數與執行緒池
前言 在使用tomcat時,經常會遇到連線數、執行緒數之類的配置問題,要真正理解這些概念,必須先了解Tomcat的聯結器(Connector)。 在前面的文章 詳解Tomcat配置檔案server.xml 中寫到過:Connector的主要功能,是接收連線請求,建立R
【胡思亂想】JNI與執行緒池的維護
JNI中,C/C++程式碼裡建立的資源不由Java GC處理,故這裡的資源必須由C/C++程式碼明確釋放。在JNI中,C/C++回撥Java的方法是呼叫一個CallXXMethod函式來實現的,如果回撥的方法結束,C/C++執行下一行程式碼。 故猜測,由C/C++建立的OS執行緒應該會在執行完run方法後釋放
java socket 服務端併發處理 與 執行緒池的使用
package yiwangzhibujian.threadserver; import java.io.InputStream; import java.net.ServerSocket; import java.net.Socket; import java.util.
java執行緒之Executor框架與執行緒池
執行緒雖然在web開發中用的不算特別多,但在特定的情況下還是能發揮重要重要作用的,因此即使用的少還是掌握下比較好;下面先回顧下比較執行緒的常規實現方法 1 繼承Thread類 2 實現runnable介面(使用較多) java5之後有了新的執行緒實現方式,java5可以使用
Tomcat 連線數與執行緒池詳解 | BIO/NIO有何不同 | 簡談Kafka中的NIO網路通訊模型
前言 在使用tomcat時,經常會遇到連線數、執行緒數之類的配置問題,要真正理解這些概念,必須先了解Tomcat的聯結器(Connector)。 在前面的文章 詳解Tomcat配置檔案server.xml 中寫到過:Connector的主要功能,是接收連線請求,建立Req
HTML5 Web Worker 多執行緒與執行緒池
筆者最近對專案進行優化,順帶就改了些東西,先把請求方式優化了,使用到了web worker。筆者發現目前還沒有太多深入對web worker的使用的文章,除了涉及到一些WebGL的文章,所以總結了這個文章,給大家參考參考。一下內容以預設你對web worker已經有了初步瞭解,不會講解基礎知