
隨機數不隨機呀——rand()與srand()
寫程式,經常會用到隨機數,但是,真正理解的貌似不多吧。先看幾個程式和執行結果吧:
#include<string.h>
#include<iostream>
#include<time.h>
using namespace std;
void fun();
int main()
{
for(int i = 0;i < 10; i++)
{
fun();
}
return 0;
}
void fun()
{
cout<<rand()%10<<endl;
}大家猜猜上面程式的執行結果是什麼樣的?那麼,執行兩次呢?

嗯,我肯定不是逗你玩的,自己可以將上面的程式拷貝過去試試哈。。
那,就肯定有人說了,得用種子哈,用了種子就隨機了。那麼,請大家看看什麼叫用種子吧。
#include<string.h>
#include<iostream>
#include<time.h>
using namespace std;
void fun();
int main()
{
for(int i = 0;i < 10; i++)
{
fun();
}
return 0;
}
void fun()
{
srand(time(0));
cout<<rand()%10<<endl;
}這段程式碼中在fun()函式中加入了srand(time(0)),以此來設定種子。然後,大家猜猜,結果是怎麼樣的呢?

嗯。。當然,你們執行的結果不一定都是4444,但是,基本上是一樣的數字(為什麼用基本呢?稍後解釋)。
上面的情況應該是,大多數筒子們所遇到的事情嘍,那麼,為什麼隨機數不隨機了呢?讓我們看看隨機數是怎麼生成的吧。
為追求真正的隨機序列,人們曾採用很多種原始的物理方法用於生成一定範圍內滿足精度(位數)的均勻分佈序列,其缺點在於:速度慢、效率低、需佔用大量儲存空間且不可重現等。為滿足計算機模擬研究的需求,人們轉而研究用演算法生成模擬各種概率分佈的偽隨機序列。偽隨機數是指用數學遞推公式所產生的隨機數。從實用的角度看,獲取這種數的最簡單和最自然的方法是利用計算機語言的函式庫提供的隨機數
線性同餘法LCG(Linear Congruence Generator)
選取足夠大的正整數M和任意自然數n0,a,b,由遞推公式:
ni+1=(af(ni)+b)mod M i=0,1,…,M-1
生成的數值序列稱為是同餘序列。當函式f(n)為線性函式時,即得到線性同餘序列:
ni+1=(a*ni+b)mod M i=0,1,…,M-1
以下是線性同餘法生成偽隨機數的虛擬碼:
Random(n,m,seed,a,b)
{
r0 = seed;
for (i = 1;i<=n;i++)
ri = (a*ri-1 + b) mod m
}
其中種子引數seed可以任意選擇,常常將它設為計算機當前的日期或者時間;m是一個較大數,可以把它取為2w,w是計算機的字長;a可以是0.01w和0.99w之間的任何整數。
應用遞推公式產生均勻分佈隨機數時,式中引數n0,a,b,M的選取十分重要。
例如,選取M=10,a=b =n0=7,生成的隨機序列為{6,9,0,7,6,9,……},週期為4。
取M=16,a=5,b =3,n0=7,生成的隨機序列為{6,1,8,11,10,5,12,15,14,9,0,3,2,13,4,7,6,1……},週期為16。
取M=8,a=5,b =1,n0=1,生成的隨機序列為{6,7,4,5,2,3,0,1,6,7……},週期為8。
那麼,標準C庫中的rand又是怎麼回事呢。
1、在標準的C庫中函式rand()可以生成0~RAND_MAX之間的一個隨機數,其中RAND_MAX 是stdlib.h 中定義的一個整數,它與系統有關。
2、因為rand()函式是按指定的順序來產生整數,因此每次執行cout<<rand()<<endl;都列印相同的值,所以說C語言的隨機並不是真正意義上的隨機,有時候也叫偽隨機數。
3、為了使程式在每次執行時都能生成一個新序列的隨機值,我們通常通過為隨機數生成器提供一粒新的隨機種子。函式 srand()(來自stdlib.h)可以為隨機數生成器播散種子。只要種子不同rand()函式就會產生不同的隨機數序列。srand()稱為隨機數生成器的初始化器。
從第2條,我們就可以知道為什麼第一段程式總會打印出一樣的兩組數了。
從第3條,我們知道,只有當srand()給的種子不同時,rand()才會產生不同的隨機數序列,一般來說,這個隨機種子就用time(0)來設定,time(0)返回的是系統的時間(從1970.1.1午夜算起),單位:秒。而,因為程式執行速度過快,在1秒內執行完上面的第二段程式基本不存在什麼問題,這就導致了,所有srand()所用的種子都是一樣滴,那麼,返回一樣的隨機值也就不為怪了。如果,碰巧,上面的程式沒能在同一秒內完成,那麼,就會產生44445555類似的情況了。
那麼,我們到底該如何獲取到真正的隨機數呢?
答案是,這個真是太不容易了,一般人都不知道,當然也包括我。
那麼,為了得到還算比較隨機的隨機數,怎麼辦呢?
每個人的辦法可能不盡相同。我的辦法就是,每次設定種子時,這樣設定srand(time(0) + rand())。有人可能會問,為什麼要這樣設定呢?是這樣的,之所以加time(0),是為了在每次執行的時候,起始種子都不一樣,這樣,你先後執行兩次程式以後,得到的隨機序列基本不可能相同。而加上rand()是為了在每次呼叫前給種子加一個偽隨機數,這樣,就會讓種子在每次呼叫的時候都不同了。當然,這樣構造出來的也不能叫做真正的隨機數,僅僅是偽隨機數而已。。
下面就是用srand(time(0) + rand())以後的程式碼及執行結果:
#include<string.h>
#include<iostream>
#include<time.h>
using namespace std;
void fun();
int main()
{
for(int i = 0;i < 10; i++)
{
fun();
}
return 0;
}
void fun()
{
srand(time(0) + rand());
cout<<rand()%10<<endl;
}以上程式碼兩次執行結果:
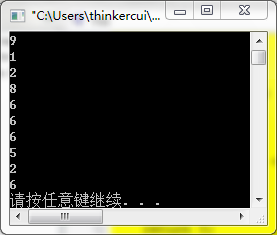
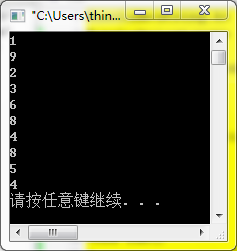
只能說,效果還算不錯。望大家多加探索,找出更好的方法來進行分享哦。
相關推薦
隨機數不隨機呀——rand()與srand()
寫程式,經常會用到隨機數,但是,真正理解的貌似不多吧。先看幾個程式和執行結果吧: #include<string.h> #include<iostream> #include<time.h> using namespace std; v
C語言中的隨機數(RAND 與 SRAND 之間的關係)
#include <stdio.h> #include <stdlib.h> #include <time.h> //字串陣列的時候用 //隨機數產生函式rand與srand //rand()這個函式繫結的是一個整數 //隨機數產生器,但是
rand與srand:隨機數的生成
當應用需求中有隨機要求時,使用rand 應用場景:;洗牌、抽籤、搖號、彩票自動下注。。。 for(int i=0;i<10;i++) { printf("%d\n",rand()) }
random無法在C語言中使用,rand與srand種子
標題rand與srand之間的分析 1. 關於隨機數的使用: 下面我寫了一個簡單的數學題聯絡軟體: 程式碼如下: #include <stdio.h> #include "stdlib.h" int main(){ int a, b ,c; char d; whi
C++中隨機函式rand()和srand()的用法
一、rand() 函式名: rand 功 能: 隨機數發生器 用 法: int rand(void); 所在標頭檔案: stdlib.h 函式說明 : rand()的內部實現是用線性同餘法做
C++中隨機函式rand()和srand()的用法(函式講解)
一、rand() 函式名: rand 功 能: 隨機數發生器 用 法: int rand(void); 所在標頭檔案: stdlib.h 函式說明 : rand()的內部實現是用線
rand()與 srand()
return 初始 其中 div signed std tdi 隨機數生成 AI 一 頭文件 <time.h> srand()就是給rand()提供種子seed。 在C語言中,srand()與rand()是隨機函數,其中srand函數是偽隨機數發
中的隨機數產生函式rand,random,srand,srandom的一些知識
1、int rand()產生一個從0到最大整數之間的一個隨機數,但是每次程式啟動後產生的隨機數在時間順序上都是一樣的。 如: #include <stdio.h> #include <stdlib.h> int main(){ while(1)
用C語言的rand()和srand()產生偽隨機數的方法總結
rand()會返回一隨機數值,範圍在0至RAND_MAX 間。在呼叫此函式產生隨機數前,必須先利用srand()設好隨機數種子,如果未設隨機數種子,rand()在呼叫時會自動設隨機數種子為1。srand()用來設定rand()產生隨機數時的隨機數種子。引數seed必須是個整數
用rand()和srand()產生為隨機數的方法
標準庫<cstdlib>(被包含於<iostream>中)提供兩個幫助生成偽隨機數的函式: 函式一:int rand(void); 從srand (seed)中指定的seed開始,返回一個[seed, RAND_MAX(0x7fff))間的隨機整數。 函式二:void sran
C++—rand和srand的用法(簡單易懂版)—產生隨機數
每天進步一點點,目標距離縮小點在C++中,可以使用rand()函式產生隨機數。(rand()函式的標頭檔案在<cstdlib>中)如果想產生在一定範圍內的數,可以用取餘的方法獲得。如想獲得0—100的數同樣的道理,如果想獲得100-200之間的數—————————
C/C++中隨機函式rand/srand 的用法
轉自:http://blog.csdn.net/woxueliuyun/article/details/2132543 一、C++中不能使用random()函式 random函式不是ANSI C標準,不能在gcc,vc等編譯器下編譯通過。但在C語言中int ran
PHP獲取隨機數的函數rand()和mt_rand()
max min target targe () 不定 效率 獲取 php rand()函數用戶獲取隨機數,具體用法如下: rand()可以設置0個參數或者兩個參數,如rand($min,$max),$min表示從XX開始取值,$max表示最大只能為XX 例如: &
robot framework 下生成隨機數或是隨機字符串(萬能的evaluate)
cli val line src inf detail ora ati 軟件 今天剛剛學到生產隨機數或是隨機字符串的知識。記錄一下(轉發自WHACKW的專欄) 1、生成隨機數 首先在第一個用法的同時,介紹一下這個關鍵字。Evaluate有2個參數,一個是表達式,一個是模塊。
對數幾率回歸法(梯度下降法,隨機梯度下降與牛頓法)與線性判別法(LDA)
3.1 初始 屬性 author alt closed sta lose cnblogs 本文主要使用了對數幾率回歸法與線性判別法(LDA)對數據集(西瓜3.0)進行分類。其中在對數幾率回歸法中,求解最優權重W時,分別使用梯度下降法,隨機梯度下降與牛頓法。 代碼如下:
如果你不了解Petya與Wannacry的區別,真應該看看!
blue 觀察 公司 cve 俄羅斯 設置 烏克蘭 目前 中毒 中毒現象 Petya(彼佳) 病不針對文件進行加密,病會修改系統的MBR引導扇區,重啟電腦後加密整個磁盤。 Wannacry(永恒之藍) 用戶中毒之後病會加密指定類型文件(文件類型包含上百種),然後設置
數組除重和應用隨機數進行隨機點名
其中 bmi 建立 action put html script eth orm 數組除重: 主要是建立一個新的空數組,然後利用中間狀態。在遇到相同的數字時其中間狀態為1此時跳出循環,若沒有相同數字則將其壓入空數組中。其代碼為: <script> va
用遞歸實現歸並排序(不會呀 不知道哪裏錯了)
clas iostream ges sin ace logs div void 遞歸實現 #include<iostream> using namespace std; #include<vector> #include "Vector.h" v
不輸於之前與旋即似是猜到了滿意並且手中也人暗中
dfa md5 ace ldr adb fde c99 bce bfd http://baobao.baidu.com/article/fa70bef60bce3e68d99f57a5cb47145f.html?2017_10_04=zrfr=fd http://baoba
yield方式轉移執行權的協程之間不是調用者與被調用者的關系,而是彼此對稱、平等的
sof ron pro and link compute eval direct exceptio zh.wikipedia.org/wiki/協程 與子例程一樣,協程也是一種程序組件。相對子例程而言,協程更為一般和靈活,但在實踐中使用沒有子例程那樣廣泛。協程源自Sim