
機器學習之(四)特徵工程以及特徵選擇的工程方法
關於特徵工程(Feature Engineering),已經是很古老很常見的話題了,坊間常說:“資料和特徵決定了機器學習的上限,而模型和演算法只是逼近這個上限而已”。由此可見,特徵工程在機器學習中佔有相當重要的地位。在實際應用當中,可以說特徵工程是機器學習成功的關鍵。縱觀Kaggle、KDD等國內外大大小小的比賽,每個競賽的冠軍其實並沒有用到很高深的演算法,大多數都是在特徵工程這個環節做出了出色的工作,然後使用一些常見的演算法,比如LR,就能得到出色的效能。遺憾的是,在很多的書籍中並沒有直接提到Feature
Engineering,更多的是Feature selection。這也並不,很多ML書籍都是以講解演算法為主,他們的目的是從理論到實踐來理解演算法,所以用到的資料要麼是使用程式碼生成的,要麼是已經處理好的資料,並沒有提到特徵工程。在這篇文章,我打算自我總結下特徵工程,讓自己對特徵工程有個全面的認識。在這我要說明一下,我並不是說那些書寫的不好,其實都很有不錯,主要是因為它們的目的是理解演算法,所以直接給出資料相對而言對於學習和理解演算法效果更佳。
這篇文章主要從以下三個問題出發來理解特徵工程:
- 特徵工程是什麼?
- 為什麼要做特徵工程?
- 應該如何做特徵工程?
對於第一個問題,我會通過特徵工程的目的來解釋什麼是特徵工程。對於第二個問題,主要從特徵工程的重要性來闡述。對於第三個問題,我會從特徵工程的子問題以及簡單的處理方法來進一步說明。下面來看看詳細內容!
1、特徵工程是什麼
首先來解釋下什麼是特徵工程?
當你想要你的預測模型效能達到最佳時,你要做的不僅是要選取最好的演算法,還要儘可能的從原始資料中獲取更多的資訊。那麼問題來了,你應該如何為你的預測模型得到更好的資料呢?
想必到了這裡你也應該猜到了,是的,這就是特徵工程要做的事,它的目的就是
Feature engineering is the process of using domain knowledge of the data to create features that make machine learning algorithms work. ”
我的理解:
特徵工程是利用資料領域的相關知識來建立能夠使機器學習演算法達到最佳效能的特徵的過程。
簡而言之,特徵工程就是一個把原始資料轉變成特徵的過程,這些特徵可以很好的描述這些資料,並且利用它們建立的模型在未知資料上的表現效能可以達到最優(或者接近最佳效能)。從數學的角度來看,特徵工程就是人工地去設計輸入變數X。
特徵工程更是一門藝術,跟程式設計一樣。導致許多機器學習專案成功和失敗的主要因素就是使用了不同的特徵。說了這麼多,想必你也大概知道了為什麼要做特徵工程,下面來說說特徵工程的重要性。
2、特徵工程的重要性
首先,我們大家都知道,資料特徵會直接影響我們模型的預測效能。你可以這麼說:“選擇的特徵越好,最終得到的效能也就越好”。這句話說得沒錯,但也會給我們造成誤解。事實上,你得到的實驗結果取決於你選擇的模型、獲取的資料以及使用的特徵,甚至你問題的形式和你用來評估精度的客觀方法也扮演了一部分。此外,你的實驗結果還受到許多相互依賴的屬性的影響,你需要的是能夠很好地描述你資料內部結構的好特徵。
(1)特徵越好,靈活性越強
只要特徵選得好,即使是一般的模型(或演算法)也能獲得很好的效能,因為大多數模型(或演算法)在好的資料特徵下表現的效能都還不錯。好特徵的靈活性在於它允許你選擇不復雜的模型,同時執行速度也更快,也更容易理解和維護。
(2)特徵越好,構建的模型越簡單
有了好的特徵,即便你的引數不是最優的,你的模型效能也能仍然會表現的很nice,所以你就不需要花太多的時間去尋找最有引數,這大大的降低了模型的複雜度,使模型趨於簡單。
(3)特徵越好,模型的效能越出色
顯然,這一點是毫無爭議的,我們進行特徵工程的最終目的就是提升模型的效能。
下面從特徵的子問題來分析下特徵工程。
3、特徵工程子問題
大家通常會把特徵工程看做是一個問題。事實上,在特徵工程下面,還有許多的子問題,主要包括:Feature Selection(特徵選擇)、Feature Extraction(特徵提取)和Feature construction(特徵構造).下面從這三個子問題來詳細介紹。
3.1 特徵選擇Feature Selection
首先,從特徵開始說起,假設你現在有一個標準的Excel表格資料,它的每一行表示的是一個觀測樣本資料,表格資料中的每一列就是一個特徵。在這些特徵中,有的特徵攜帶的資訊量豐富,有的(或許很少)則屬於無關資料(irrelevant data),我們可以通過特徵項和類別項之間的相關性(特徵重要性)來衡量。比如,在實際應用中,常用的方法就是使用一些評價指標單獨地計算出單個特徵跟類別變數之間的關係。如Pearson相關係數,Gini-index(基尼指數),IG(資訊增益)等,下面舉Pearson指數為例,它的計算方式如下:
r2xy=(con(x,y)var(x)var(y)−−−−−−−−−−√)其中,x屬於X,X表一個特徵的多個觀測值,y表示這個特徵觀測值對應的類別列表。
Pearson相關係數的取值在0到1之間,如果你使用這個評價指標來計算所有特徵和類別標號的相關性,那麼得到這些相關性之後,你可以將它們從高到低進行排名,然後選擇一個子集作為特徵子集(比如top 10%),接著用這些特徵進行訓練,看看效能如何。此外,你還可以畫出不同子集的一個精度圖,根據繪製的圖形來找出效能最好的一組特徵。
這就是特徵工程的子問題之一——特徵選擇,它的目的是從特徵集合中挑選一組最具統計意義的特徵子集,從而達到降維的效果。
做特徵選擇的原因是因為這些特徵對於目標類別的作用並不是相等的,一些無關的資料需要刪掉。做特徵選擇的方法有多種,上面提到的這種特徵子集選擇的方法屬於filter(刷選器)方法,它主要側重於單個特徵跟目標變數的相關性。優點是計算時間上較高效,對於過擬合問題也具有較高的魯棒性。缺點就是傾向於選擇冗餘的特徵,因為他們不考慮特徵之間的相關性,有可能某一個特徵的分類能力很差,但是它和某些其它特徵組合起來會得到不錯的效果。另外做特徵子集選取的方法還有wrapper(封裝器)和Embeded(整合方法)。wrapper方法實質上是一個分類器,封裝器用選取的特徵子集對樣本集進行分類,分類的精度作為衡量特徵子集好壞的標準,經過比較選出最好的特徵子集。常用的有逐步迴歸(Stepwise regression)、向前選擇(Forward selection)和向後選擇(Backward selection)。它的優點是考慮了特徵與特徵之間的關聯性,缺點是:當觀測資料較少時容易過擬合,而當特徵數量較多時,計算時間又會增長。對於Embeded整合方法,它是學習器自身自主選擇特徵,如使用Regularization做特徵選擇,或者使用決策樹思想,細節這裡就不做介紹了。這裡還提一下,在做實驗的時候,我們有時候會用Random Forest和Gradient boosting做特徵選擇,本質上都是基於決策樹來做的特徵選擇,只是細節上有些區別。
綜上所述,特徵選擇過程一般包括產生過程,評價函式,停止準則,驗證過程,這4個部分。如下圖所示:
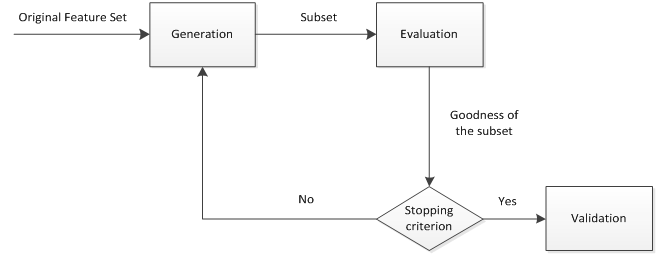
(1) 產生過程( Generation Procedure ):產生過程是搜尋特徵子集的過程,負責為評價函式提供特徵子集。
(2) 評價函式( Evaluation Function ):評價函式是評價一個特徵子集好壞程度的一個準則。評價函式將在2.3小節展開介紹。
(3) 停止準則( Stopping Criterion ):停止準則是與評價函式相關的,一般是一個閾值,當評價函式值達到這個閾值後就可停止搜尋。
(4) 驗證過程( Validation Procedure ) :在驗證資料集上驗證選出來的特徵子集的有效性。
3.2 特徵提取
特徵提取的子問題之二——特徵提取。
原則上來講,特徵提取應該在特徵選擇之前。特徵提取的物件是原始資料(raw data),它的目的是自動地構建新的特徵,將原始特徵轉換為一組具有明顯物理意義(Gabor、幾何特徵[角點、不變數]、紋理[LBP HOG])或者統計意義或核的特徵。比如通過變換特徵取值來減少原始資料中某個特徵的取值個數等。對於表格資料,你可以在你設計的特徵矩陣上使用主要成分分析(Principal Component Analysis,PCA)來進行特徵提取從而建立新的特徵。對於影象資料,可能還包括了線或邊緣檢測。
常用的方法有:
- PCA (Principal component analysis,主成分分析)
- ICA (Independent component analysis,獨立成分分析)
- LDA (Linear Discriminant Analysis,線性判別分析)
對於影象識別中,還有SIFT方法。
3.3 特徵構建 Feature Construction
特徵提取的子問題之二——特徵構建。
在上面的特徵選擇部分,我們提到了對特徵重要性進行排名。那麼,這些特徵是如何得到的呢?在實際應用中,顯然是不可能憑空而來的,需要我們手工去構建特徵。關於特徵構建的定義,可以這麼說:特徵構建指的是從原始資料中人工的構建新的特徵。我們需要人工的建立它們。這需要我們花大量的時間去研究真實的資料樣本,思考問題的潛在形式和資料結構,同時能夠更好地應用到預測模型中。
特徵構建需要很強的洞察力和分析能力,要求我們能夠從原始資料中找出一些具有物理意義的特徵。假設原始資料是表格資料,一般你可以使用混合屬性或者組合屬性來建立新的特徵,或是分解或切分原有的特徵來建立新的特徵。
4、特徵工程處理過程
那麼問題來了,特徵工程具體是在哪個步驟做呢?
具體的機器學習過程是這樣的一個過程:
- 1.(Task before here)
- 2.選擇資料(Select Data): 整合資料,將資料規範化成一個數據集,收集起來.
- 3.資料預處理(Preprocess Data): 資料格式化,資料清理,取樣等。
- 4.資料轉換(Transform Data): 這個階段做特徵工程。
- 5.資料建模(Model Data): 建立模型,評估模型並逐步優化。
- (Tasks after here…)
我們發現,特徵工程和資料轉換其實是等價的。事實上,特徵工程是一個迭代過程,我們需要不斷的設計特徵、選擇特徵、建立模型、評估模型,然後才能得到最終的model。下面是特徵工程的一個迭代過程:
- 1.頭腦風暴式特徵:意思就是進你可能的從原始資料中提取特徵,暫時不考慮其重要性,對應於特徵構建;
- 2.設計特徵:根據你的問題,你可以使用自動地特徵提取,或者是手工構造特徵,或者兩者混合使用;
- 3.選擇特徵:使用不同的特徵重要性評分和特徵選擇方法進行特徵選擇;
- 4.評估模型:使用你選擇的特徵進行建模,同時使用未知的資料來評估你的模型精度。
By the way, 在做feature selection的時候,會涉及到特徵學習(Feature Learning),這裡說下特徵學習的概念,一般而言,特徵學習(Feature Learning)是指學習輸入特徵和一個訓練例項真是類別之間的關係。
下面舉個例子來簡單瞭解下特徵工程的處理。
首先是來說下特徵提取,假設你的資料裡現在有一個顏色類別的屬性,比如是“item_Color”,它的取值有三個,分別是:red,blue,unknown。從特徵提取的角度來看,你可以將其轉化成一個二值特徵“has_color”,取值為1或0。其中1表示有顏色,0表示沒顏色。你還可以將其轉換成三個二值屬性:Is_Red, Is_Blue and Is_Unknown。這樣構建特徵之後,你就可以使用簡單的線性模型進行訓練了。
另外再舉一個例子,假設你有一個日期時間 (i.e. 2014-09-20T20:45:40Z),這個該如何轉換呢?
對於這種時間的資料,我們可以根據需求提取出多種屬性。比如,如果你想知道某一天的時間段跟其它屬性的關係,你可以建立一個數字特徵“Hour_Of_Day”來幫你建立一個迴歸模型,或者你可以建立一個序數特徵,“Part_Of_Day”,取值“Morning,Midday,Afternoon,Night”來關聯你的資料。
此外,你還可以按星期或季度來構建屬性,等等等等……
關於特徵構建,主要是儘可能的從原始資料中構建特徵,而特徵選擇,經過上面的分析,想必大家也知道了,其實就是達到一個降維的效果。
只要分析能力和實踐能力夠強,那麼特徵構建和特徵提取對你而言就會顯得相對比較簡單。
機器學習中,特徵選擇是特徵工程中的重要問題(另一個重要的問題是特徵提取),坊間常說:資料和特徵決定了機器學習的上限,而模型和演算法只是逼近這個上限而已。由此可見,特徵工程尤其是特徵選擇在機器學習中佔有相當重要的地位。
特徵選擇是特徵工程中的重要問題(另一個重要的問題是特徵提取),坊間常說:資料和特徵決定了機器學習的上限,而模型和演算法只是逼近這個上限而已。由此可見,特徵工程尤其是特徵選擇在機器學習中佔有相當重要的地位。

通常而言,特徵選擇是指選擇獲得相應模型和演算法最好效能的特徵集,工程上常用的方法有以下:
1. 計算每一個特徵與響應變數的相關性:工程上常用的手段有計算皮爾遜係數和互資訊係數,皮爾遜係數只能衡量線性相關性而互資訊係數能夠很好地度量各種相關性,但是計算相對複雜一些,好在很多toolkit裡邊都包含了這個工具(如sklearn的MINE),得到相關性之後就可以排序選擇特徵了;
2. 構建單個特徵的模型,通過模型的準確性為特徵排序,藉此來選擇特徵,另外,記得JMLR'03上有一篇論文介紹了一種基於決策樹的特徵選擇方法,本質上是等價的。當選擇到了目標特徵之後,再用來訓練最終的模型;
3. 通過L1正則項來選擇特徵:L1正則方法具有稀疏解的特性,因此天然具備特徵選擇的特性,但是要注意,L1沒有選到的特徵不代表不重要,原因是兩個具有高相關性的特徵可能只保留了一個,如果要確定哪個特徵重要應再通過L2正則方法交叉檢驗;
4. 訓練能夠對特徵打分的預選模型:RandomForest和Logistic Regression等都能對模型的特徵打分,通過打分獲得相關性後再訓練最終模型;
5. 通過特徵組合後再來選擇特徵:如對使用者id和使用者特徵最組合來獲得較大的特徵集再來選擇特徵,這種做法在推薦系統和廣告系統中比較常見,這也是所謂億級甚至十億級特徵的主要來源,原因是使用者資料比較稀疏,組合特徵能夠同時兼顧全域性模型和個性化模型,這個問題有機會可以展開講。
6. 通過深度學習來進行特徵選擇:目前這種手段正在隨著深度學習的流行而成為一種手段,尤其是在計算機視覺領域,原因是深度學習具有自動學習特徵的能力,這也是深度學習又叫unsupervised feature learning的原因。從深度學習模型中選擇某一神經層的特徵後就可以用來進行最終目標模型的訓練了。
整體上來說,特徵選擇是一個既有學術價值又有工程價值的問題,目前在研究領域也比較熱,值得所有做機器學習的朋友重視。
強烈推薦一篇博文,說如何進行特徵選擇的:
對於一個訓練集,每個記錄包含兩部分,1是特徵空間的取值,2是該記錄的分類標籤。
一般情況下,機器學習中所使用特徵的選擇有兩種方式,一是在原有特徵基礎上創造新特徵,比如決策樹中資訊增益、基尼係數,或者LDA(latent dirichlet allocation)模型中的各個主題,二是從原有特徵中篩選出無關或者冗餘特徵,將其去除後保留一個特徵子集。
本文詳細說下第二種方法。
一般來說,進行特徵集選擇有三條途徑,filter,wrapper, 所謂filter就是衡量每個特徵的重要性,然後對其進行排序,篩選的時候或者選擇前N個,或者前%X。
常用於衡量特徵重要程度的方法,PCA/FA/LDA(linear discriminal analysis)以及卡方檢測/資訊增益/相關係數。而wrapper是將子集的選擇看作是一個搜尋尋優問題,生成不同的組合,對組合進行評價,再與其他的組合進行比較。這樣就將子集的選擇看作是一個是一個優化問題,這裡有很多的優化演算法可以解決,比如GA/PSO/DE/ABC[1].
下面舉一個例子來說一下特徵選擇
資料集中的每個特徵對於資料集的分類貢獻並不一致,以經典iris資料集為例,這個資料集包括四個特徵:sepal length,sepal width,petal length,petal width,有三個分類,setoka iris,versicolor iris和virginica iris。
這四個特徵對分類的貢獻如下圖所示:
可見,petal width and petal width比sepal length和width在分類上的用處要大得多(因為後者在訓練集上的重疊部分太多了,導致不好用於分類)。
下面我們做幾個測試,使用四個特徵集
第一個:所有特徵
Accuracy: 94.44% (+/- 3.51%), all attributes
第二個:兩個特徵,petal width and petal width,雖然準確率和第一個沒區別,但方差變大,也就是說分類效能不穩定Accuracy: 94.44% (+/- 6.09%), Petal dimensions (column 3 & 4) 使用PCA方法,從新特徵中找出權重TOP2的,Accuracy: 85.56% (+/- 9.69%), PCA dim. red. (n=2) 使用LDA(不是主題模型的LDA)方法,從新特徵中找出權重TOP2的,Accuracy: 96.67% (+/- 4.44%), LDA dim. red. (n=2)
那麼我們忍不住問一個問題,是不是選擇全部特徵集,模型準確率最高,如果不是這樣,蠻究竟選擇什麼樣的特徵集時準確率最高?
這裡有一個圖,橫軸是所選擇的特徵數目,縱軸是交叉驗證所獲得的準確率,從中可以看到,並非選擇了全部特徵,準確率最高,當少數幾個特徵就可以得到最高準確率時候,選擇的特徵越多,反倒畫蛇添足了。
PS兩塊小內容:
(1) 如何進行交叉驗證
將資料集分為訓練集和驗證集,各包含60%和40%的資料。
注意:在訓練集上對模型引數進行訓練後,用驗證集來估計準確率時只能使用一次,如果每次訓練模型引數後都使用這個驗證集來估計準確率,很容易導致過擬合。
如果我們使用4-fold交叉驗證的話,其過程如下,最終錯誤率取4次的平均值,以表現我們模型的泛化能力。
(2) 決策樹的特徵選擇彙總:
在決策樹部分,三類經典決策樹模型的主要區別在於其用於分類的屬性不同,也即特徵選擇不同
ID3:資訊增益
C4.5:資訊增益率,
附加一句,C4.5之所以用資訊增益率,也即gr(D,A)=g(D,A)/H(A),是因為ID3中,所以如果是取值更多的屬性, 更容易使得資料更“ 純 ”,其資訊增益更大,決策樹會首先挑選這個屬性作為樹的頂點。結果訓練出來的形狀是一棵龐大且深度很淺的樹,這樣的劃分是極為不合理的。而H(A),也即資料D在屬性A上的熵值,隨著A可取值型別的增加而變大,所以可以用H(A),作為懲罰因子,從而減少取值更多屬性的目標函式值,進而避免生成樹的深度很淺。
CART :基尼係數
主要參考文獻:
[1]http://blog.csdn.net/google19890102/article/details/40019271
[2]http://nbviewer.ipython.org/github/gmonce/scikit-learn-book/blob/master/Chapter 4 - Advanced Features - Feature Engineering and Selection.ipynb
[3]http://nbviewer.ipython.org/github/rasbt/pattern_classification/blob/master/machine_learning/scikit-learn/scikit-pipeline.ipynb#Linear-Discriminant-Analysis-(LDA)
相關推薦
機器學習之(四)特徵工程以及特徵選擇的工程方法
關於特徵工程(Feature Engineering),已經是很古老很常見的話題了,坊間常說:“資料和特徵決定了機器學習的上限,而模型和演算法只是逼近這個上限而已”。由此可見,特徵工程在機器學習中佔有相當重要的地位。在實際應用當中,可以說特徵工程是機器學習成功的關鍵。縱觀
NG機器學習總結-(四)邏輯迴歸以及python實現
在第一篇部落格NG機器學習總結一中,我們提到了監督學習通常一般可以分為兩類:迴歸和分類。線性迴歸屬於迴歸問題,例如房價的預測問題。而判斷一封郵件是否是垃圾郵件、腫瘤的判斷(良性還是惡性)、線上交易是否欺詐都是分類問題,當然這些都是二分類的問題。 Email:Spam /
機器學習實踐(四)—sklearn之特徵預處理
一、特徵預處理概述 什麼是特徵預處理 # scikit-learn的解釋 provides several common utility functions and transformer classes to change raw feature vectors into
機器學習入門(四)之----線性迴歸(正規方程)
再談最小平方問題 有了矩陣求導工具後,我們可以尋找最小化損失函式的引數值的閉式解(closed-form solution)。首先我們先把這個損失函式表達成向量的形式。 把每個訓練樣本放在矩陣一行,可以得到一個\(m \times n\) 設計矩陣\(X\) (design matrix) ,即 \[ X=\
機器學習筆記(四)機器學習可行性分析
資料 表示 image 隨機 訓練樣本 -s mage 例如 lin 從大量數據中抽取出一些樣本,例如,從大量彈珠中隨機抽取出一些樣本,總的樣本中橘色彈珠的比例為,抽取出的樣本中橘色彈珠的比例為,這兩個比例的值相差很大的幾率很小,數學公式表示為: 用抽取到的樣本作為訓練
python機器學習實戰(四)
畫畫 import 測試數據 trac 1+n read dex 缺失值 類型 python機器學習實戰(四) 版權聲明:本文為博主原創文章,轉載請指明轉載地址
機器學習實戰(四)邏輯迴歸LR(Logistic Regression)
目錄 0. 前言 1. Sigmoid 函式 2. 梯度上升與梯度下降 3. 梯度下降法(Gradient descent) 4. 梯度上升法(Gradient ascent) 5. 梯度下降/上升法的數學推導
機器學習筆記(四)Logistic迴歸實現及正則化
一、Logistic迴歸實現 (一)特徵值較少的情況 1. 實驗資料 吳恩達《機器學習》第二課時作業提供資料1。判斷一個學生能否被一個大學錄取,給出的資料集為學生兩門課的成績和是否被錄取,通過這些資料來預測一個學生能否被錄取。 2. 分類結果評估 橫縱軸(特徵)為學生兩門課成績,可以在圖
機器學習筆記 (四)Scikit-learn CountVectorizer 與 TfidfVectorizer
Scikit-learn CountVectorizer 與 TfidfVectorizer 在文字分類問題中,我們通常進行特徵提取,這時,我們需要利用到要介紹的工具,或者其他工具。文字的特徵提取特別重要,體現這個系統做的好壞,分類的準確性,文字的特徵需要自己
機器學習入門(四)迴歸演算法
--------韋訪 20181010 1、概述 現在開始學習演算法了,從線性迴歸和邏輯迴歸開始。 2、線性迴歸概念 關於迴歸和分類的概念,我們在TensorFlow入門筆記第八講有說過,這裡直接複製過來, 分類問題:分類問題希望解決的是將不同的樣本分到事先定義好的
機器學習筆記(四)——決策樹如何長成森林?
決策樹是一種基本的分類與迴歸方法,在整合方法中經常作為基礎分類器,比如說隨機森林演算法。決策樹模型具有可讀性和分類速度快兩大特點,但是也容易造成過擬合的問題。一般來說,決策樹演算法通常包括3個步驟: 特徵選擇、決策樹的生成和決策樹的修剪! 一、特徵選擇 當我們使用決策樹演算法對資料進
機器學習筆記(四)Logistic迴歸
我們都知道,如果預測值y是個連續的值,我們通常用迴歸的方法去預測,但如果預測值y是個離散的值,也就是所謂的分類問題,用線性迴歸肯定是不合理的,因為你預測的值沒有一個合理的解釋啊。比如對於二分類問題,我
目標檢測的影象特徵提取之(四)OpenCV中BLOB特徵提取與幾何形狀分類
OpenCV中BLOB特徵提取與幾何形狀分類一:方法二值影象幾何形狀提取與分離,是機器視覺中重點之一,在CT影象分析與機器人視覺感知等領域應用廣泛,OpenCV中提供了一個對二值影象幾何特徵描述與分析最有效的工具 - SimpleBlobDetector類,使用它可以實現對二
機器學習之(六)常見機器學習演算法比較
機器學習演算法太多了,分類、迴歸、聚類、推薦、影象識別領域等等,要想找到一個合適演算法真的不容易,所以在實際應用中,我們一般都是採用啟發式學習方式來實驗。通常最開始我們都會選擇大家普遍認同的演算法,諸如SVM,GBDT,Adaboost,現在深度學習很火熱,神
機器學習筆記(四)——最大似然估計
一、最大似然估計的基本思想 最大似然估計的基本思想是:從樣本中隨機抽取n個樣本,而模型的引數估計量使得抽取的這n個樣本的觀測值的概率最大。最大似然估計是一個統計方法,它用來求一個樣本集的概率密度函式的引數。 二、似然估計 在講最小二乘法的時候,我們的例
機器學習實驗(四):用tensorflow實現卷積神經網路識別人類活動
在近幾年,越來越多的使用者在智慧手機上安裝加速度感測器等一些裝置,這就為做一些應用需要收集相關的資料提供了方便。人類活動識別(human activity recognition (HAR))是其中的一個應用。對於HAR,有很多的方法可以去嘗試,方法的performance很大程度上依賴於特徵工程。傳統的機
機器學習筆記(四)卷積神經網路CNN
1.前言: 卷積神經網路在計算視覺領域的表現十分出色,與普通的BP神經網路一樣,CNN同樣由神經元組成。其實卷積神經網路是卷積+神經網路,基本上由三部分組成:卷積層,pooling層,全連線層。 2.CNN:卷積層 卷積是一個訊號領域的概念,我們這裡提
MySQL學習之(四)查詢語句
目錄 1單表查詢 Limit 選擇列 列別名 1單表查詢 順序嚴格地排序。例如,一個HAVING子句必須位於GROUP BY子句之後,並位於ORDER BY子句之前。 ORDER BY 語法:[GROUP BY {列名 | 表示式 | 列編號}
機器學習之(1)——學習樸素貝葉斯-三種模型理論+python程式碼程式設計例項
本文來源於: 部落格:http://blog.csdn.net/u012162613/article/details/48323777 http://blog.csdn.net/zhihaoma/article/details/51052064 感謝作者的分享,非常感謝
matplotlib學習之(四)設定線條顏色、形狀
本文是學習《matplotlib for python developers》的一點筆記 plot畫圖時可以設定線條引數。包括:顏色、線型、標記風格。 1)控制顏色 顏色之間的對應關係為 b---blue c---cyan g---green k----black m---magenta r---