
linux記憶體管理原始碼分析
最近在學習核心模組的框架,這裡做個總結,知識太多了。
分段和分頁
先看一幅圖

也就是我們實際中編碼時遇到的記憶體地址並不是對應於實際記憶體上的地址,我們編碼中使用的地址是一個邏輯地址,會通過分段和分頁這兩個機制把它轉為實體地址。而由於linux使用的分段機制有限,可以認為,linux下的邏輯地址=線性地址。也就是,我們編碼使用的是線性地址,之後只需要經過一個分頁機制就可以把這個地址轉為實體地址了。所以我們更重要的可能是去說明一下linux的分頁模型。
系統會將整個實體記憶體分為多個頁框,每個頁框大小一般是4K(硬體允許的擴充套件分頁(PSE)情況下也可設定為4M,不過linux並不使用PSE,而可能使用PAE),也就是如果我們有1GB的實體記憶體,系統就會將這個實體記憶體分為262144個頁框。當我們提供一個線性地址時,系統就會通過分頁機制將這個線性地址轉換為對應於某個物理頁中的某個記憶體地址。下圖是linux的分頁模型
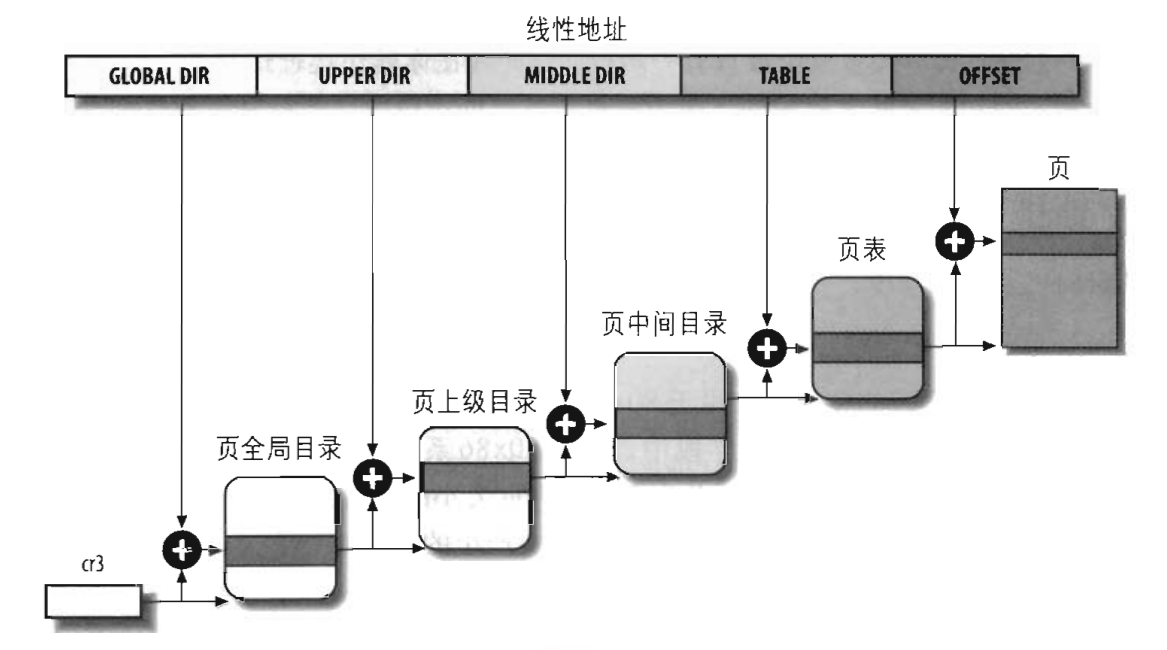
linux採用四級分頁模型,這四種頁表是:頁全域性目錄(PGD)、頁上級目錄(PUD)、頁中間目錄(PMD)、頁表(PTE)。這裡的所有頁全域性目錄、頁上級目錄、頁中間目錄、頁表,它們的大小都是一個頁。linux下各個硬體上並不一定都是使用四級目錄的,當使用於沒有啟動實體地址擴充套件(PAE)的32位系統上時,只使用二級頁表,linux會把頁上級目錄和頁中間目錄置空。而在啟用了實體地址擴充套件的32位系統上時,linux使用的是三級頁表,頁上級目錄被置空。而在64位系統上,linux根據硬體的情況會選擇三級頁表或者四級頁表。這個整個由線性地址轉換到實體地址的過程,是由CPU自動進行的。
每個程序都有它自己的頁全域性目錄,當程序執行時,系統會將該程序的頁全域性目錄基地址儲存到cr3暫存器中;而當程序被換出時,會將這個cr3儲存的頁全域性目錄地址儲存到程序描述符中。之後我們還會介紹一個cr2暫存器,用於缺頁異常處理的。當程序執行時,它使用的是它自己的一套頁表,當它通過系統呼叫或陷入核心態時,使用的是核心頁表,實際上,對於所有的程序頁表來說,它們的線性地址0xC0000000以上所涉及到的頁表都是主核心頁全域性目錄(儲存在init_mm.pgd),它們的內容等於主核心頁全域性目錄的相應表項,這樣就實現了所有程序的程序空間相互隔離,但是核心空間相互共享的情況。當某個程序修改了核心頁表的一些對映情況後,系統只會相應的修改主核心頁全域性目錄中的表項(只能修改高階記憶體中非連續記憶體區的對映),當其他程序訪問這些線性地址時,會出現缺頁異常,然後修改該程序的頁表項重新對映該地址。
因為說到每個程序都有它自己的頁全域性目錄,如果有100個程序,記憶體中就要儲存100個程序的整個頁表集,看起來會耗費相當多的記憶體。實際上,只有程序使用到的情況下系統才會分配給程序一條路徑,比如我們要求訪問一個線性地址,但是這個地址可能對應的頁上級目錄、頁中間目錄、頁表和頁都不存在的,這時系統會產生一個缺頁異常,在缺頁異常處理中再給程序的這個線性地址分配頁上級目錄、頁中間目錄、頁表和頁所需的物理頁框。
地址空間
一個線性地址經過分頁機制轉為一個對應的實體地址,我們稱之為對映,比如我們的一個線性地址0x00000001經過分頁機制處理後,對應的實體地址可能是0xffffff01。
在linux系統中分兩個地址空間,一個是程序地址空間,一個是核心地址空間。對於每個程序來說,他們都有自己的大小為3G的程序地址空間,這些程序地址空間是相互隔離的,也就是程序A的0x00000001線性地址和程序B的0x00000001線性地址並不是同一個地址,程序A也不能通過自己的程序空間直接訪問程序B的程序地址空間。而當線性地址大於3G時(也就是0xC0000000),這裡的線性地址屬於核心空間,核心地址空間的大小為1G,地址從0xC0000000到0xFFFFFFFF。在核心地址空間中,核心會把前896MB的線性地址直接與實體地址的前896MB進行對映,也就是說,核心地址空間的線性地址0xC0000001所對應的實體地址為0x00000001,它們之間相差一個0xC0000000。
linux核心會將實體記憶體分為3個管理區,分別是:
- ZONE_DMA:包含0MB~16MB之間的記憶體頁框,可以由老式基於ISA的裝置通過DMA使用,直接對映到核心的地址空間。
- ZONE_NORMAL:包含16MB~896MB之間的記憶體頁框,常規頁框,直接對映到核心的地址空間。
- ZONE_HIGHMEM:包含896MB以上的記憶體頁框,不進行直接對映,可以通過永久對映和臨時對映進行這部分記憶體頁框的訪問。
整個結構如下圖
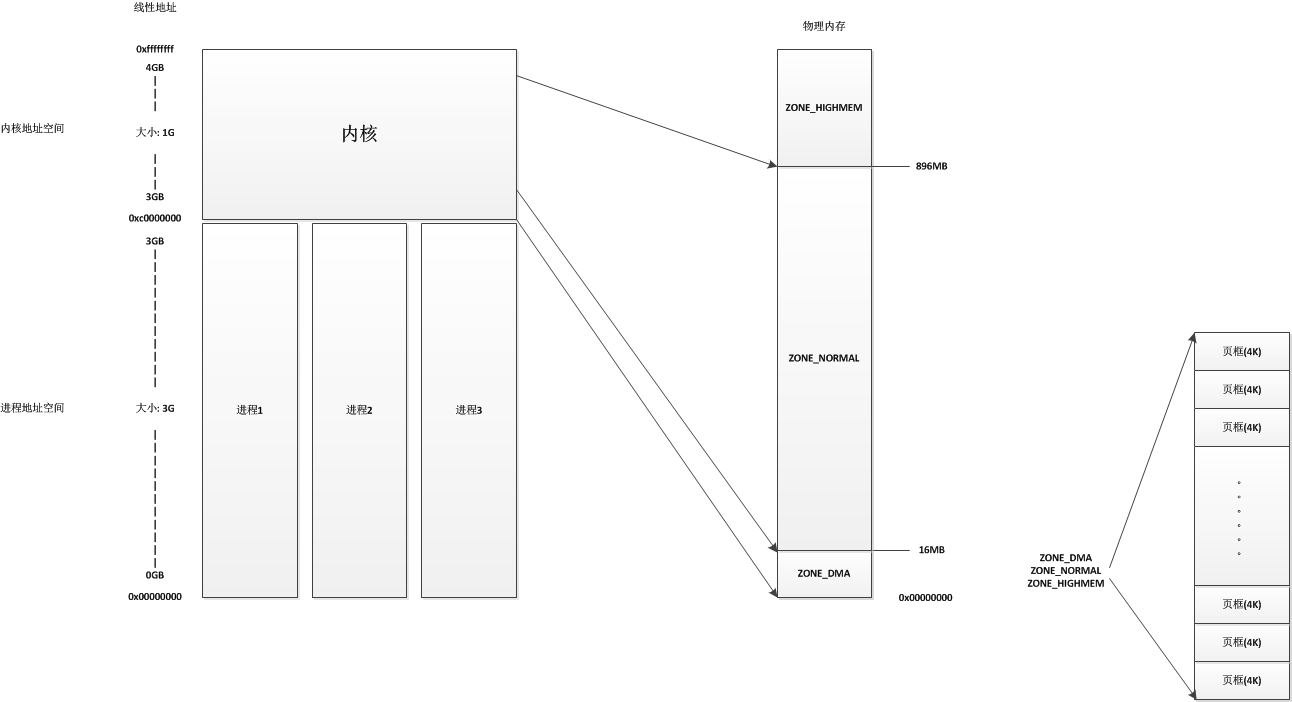
對於ZONE_DMA和ZONE_NORMAL這兩個管理區,核心地址都是進行直接對映,只有ZONE_HIGHMEM管理區系統在預設情況下是不進行直接對映的,只有在需要使用的時候進行對映(臨時對映或者永久對映)。
結點和管理區描述符
為了用於NUMA架構,使用了node用來描述一個地方的記憶體。對於我們PC來說,一臺PC就是一個node。node用struct pglist_data結構表示:
/* 記憶體結點描述符,所有的結點描述符儲存在 struct pglist_data *node_data[MAX_NUMNODES] 中 */ typedef struct pglist_data { /* 管理區描述符的陣列 */ struct zone node_zones[MAX_NR_ZONES]; /* 頁分配器使用的zonelist資料結構的陣列,將所有結點的管理區按一定的關聯連結成一個連結串列,分配記憶體時會按照此連結串列的順序進行分配 */ struct zonelist node_zonelists[MAX_ZONELISTS]; /* 結點中管理區的個數 */ int nr_zones; #ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */ /* 結點中頁描述符的陣列,包含了此結點中所有頁框描述符,實際分配是是一個指標陣列 */ struct page *node_mem_map; #ifdef CONFIG_MEMCG /* 用於資源限制機制 */ struct page_cgroup *node_page_cgroup; #endif #endif #ifndef CONFIG_NO_BOOTMEM /* 用在核心初始化階段 */ struct bootmem_data *bdata; #endif #ifdef CONFIG_MEMORY_HOTPLUG /* 自旋鎖 */ spinlock_t node_size_lock; #endif /* 結點中第一個頁框的下標,在numa系統中,頁框會有兩個序號,所有頁框的一個序號,還有就是在此結點中的一個序號 * 比如結點2中的頁框1,它在結點2中的序號是1,但是在所有頁框中的序號是1001,這個變數就是儲存這個結點首頁框的序號1000,用於方便轉換 */ unsigned long node_start_pfn; /* 記憶體結點的大小,不包括洞(以頁框為單位) */ unsigned long node_present_pages; /* 結點的大小,包括洞(以頁框為單位) */ unsigned long node_spanned_pages; /* 結點識別符號 */ int node_id; /* kswaped頁換出守護程序使用的等待佇列 */ wait_queue_head_t kswapd_wait; wait_queue_head_t pfmemalloc_wait; /* 指標指向kswapd核心執行緒的程序描述符 */ struct task_struct *kswapd; /* Protected by mem_hotplug_begin/end() */ /* kswapd將要建立的空閒塊大小取對數的值 */ int kswapd_max_order; enum zone_type classzone_idx; #ifdef CONFIG_NUMA_BALANCING /* 以下用於NUMA的負載均衡 */ /* Lock serializing the migrate rate limiting window */ spinlock_t numabalancing_migrate_lock; /* Rate limiting time interval */ unsigned long numabalancing_migrate_next_window; /* Number of pages migrated during the rate limiting time interval */ unsigned long numabalancing_migrate_nr_pages; #endif } pg_data_t;
系統中所有的結點描述符都儲存在node_data這個陣列中。在pg_data_t這個結點描述符中,node_zones陣列中儲存了這個結點中所有的管理區描述符,雖然系統將實體記憶體分為三個區,但是在邏輯上,系統分為了四個管理區,多出的一個是ZONE_MOVABLE,這個區是一個虛擬的管理區,它並沒有對應於記憶體的某個區域,它的主要目的就是為了避免記憶體碎片化,它的記憶體要麼全部來自ZONE_HIGHMEM區,要麼全部來自ZONE_NORMAL區。這些我們在後面的初始化函式中將會看到。
每個結點都有一個核心執行緒kswapd,它的作用就是將程序或核心持有的,但是不常用的頁交換到磁碟上,以騰出更多可用記憶體。
我們再看看管理區描述符:
/* 記憶體管理區描述符 */ struct zone { /* Read-mostly fields */ /* zone watermarks, access with *_wmark_pages(zone) macros */ /* 包括pages_min,pages_low,pages_high * pages_min: 管理區中保留頁的數目 * pages_low: 回收頁框使用的下界,同時也被管理區分配器作為閥值使用,一般這個數字是pages_min的5/4 * pages_high: 回收頁框使用的上界,同時也被管理區分配器作為閥值使用,一般這個數字是pages_min的3/2 */ unsigned long watermark[NR_WMARK]; /* 指明在處理記憶體不足的臨界情況下管理區必須保留的頁框數目,同時也用於在中斷或臨界區發出的原子記憶體分配請求(就是禁止阻塞的記憶體分配請求) */ long lowmem_reserve[MAX_NR_ZONES]; #ifdef CONFIG_NUMA int node; #endif /* * The target ratio of ACTIVE_ANON to INACTIVE_ANON pages on * this zone's LRU. Maintained by the pageout code. */ unsigned int inactive_ratio; /* 指向此管理區屬於的結點 */ struct pglist_data *zone_pgdat; /* 實現每CPU頁框快取記憶體,裡面包含每個CPU的單頁框的連結串列 */ struct per_cpu_pageset __percpu *pageset; /* * This is a per-zone reserve of pages that should not be * considered dirtyable memory. */ unsigned long dirty_balance_reserve; #ifndef CONFIG_SPARSEMEM /* * Flags for a pageblock_nr_pages block. See pageblock-flags.h. * In SPARSEMEM, this map is stored in struct mem_section */ unsigned long *pageblock_flags; #endif /* CONFIG_SPARSEMEM */ #ifdef CONFIG_NUMA /* * zone reclaim becomes active if more unmapped pages exist. */ unsigned long min_unmapped_pages; unsigned long min_slab_pages; #endif /* CONFIG_NUMA */ /* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */ /* 管理區第一個頁框下標 */ unsigned long zone_start_pfn; /* 所有正常情況下可用的頁,總頁數(不包括洞)減去保留的頁數 */ unsigned long managed_pages; /* 管理區總大小(頁為單位),包括洞 */ unsigned long spanned_pages; /* 管理區總大小(頁為單位),不包括洞 */ unsigned long present_pages; /* 指向管理區的傳統名稱,"DMA" "NORMAL" "HighMem" */ const char *name; /* 對應於夥伴系統中MIGRATE_RESEVE鏈的頁塊的數量 */ int nr_migrate_reserve_block; #ifdef CONFIG_MEMORY_ISOLATION /* * Number of isolated pageblock. It is used to solve incorrect * freepage counting problem due to racy retrieving migratetype * of pageblock. Protected by zone->lock. */ /* 在記憶體隔離中表示隔離的頁框塊數量 */ unsigned long nr_isolate_pageblock; #endif #ifdef CONFIG_MEMORY_HOTPLUG /* see spanned/present_pages for more description */ seqlock_t span_seqlock; #endif /* 程序等待佇列的hash表,這些程序在等待管理區中的某頁 */ wait_queue_head_t *wait_table; /* 等待佇列散列表的大小 */ unsigned long wait_table_hash_nr_entries; /* 等待佇列散列表陣列大小 */ unsigned long wait_table_bits; ZONE_PADDING(_pad1_) /* Write-intensive fields used from the page allocator */ /* 保護該描述符的自旋鎖 */ spinlock_t lock; /* free areas of different sizes */ /* 標識出管理區中的空閒頁框塊,用於夥伴系統 */ /* MAX_ORDER為11,分別代表包含大小為1,2,4,8,16,32,64,128,256,512,1024個連續頁框的連結串列 */ struct free_area free_area[MAX_ORDER]; /* zone flags, see below */ /* 管理區標識 */ unsigned long flags; ZONE_PADDING(_pad2_) /* Fields commonly accessed by the page reclaim scanner */ /* 活動及非活動連結串列使用的自旋鎖 */ spinlock_t lru_lock; struct lruvec lruvec; /* Evictions & activations on the inactive file list */ atomic_long_t inactive_age; /* * When free pages are below this point, additional steps are taken * when reading the number of free pages to avoid per-cpu counter * drift allowing watermarks to be breached */ unsigned long percpu_drift_mark; #if defined CONFIG_COMPACTION || defined CONFIG_CMA /* pfn where compaction free scanner should start */ unsigned long compact_cached_free_pfn; /* pfn where async and sync compaction migration scanner should start */ unsigned long compact_cached_migrate_pfn[2]; #endif #ifdef CONFIG_COMPACTION /* * On compaction failure, 1<<compact_defer_shift compactions * are skipped before trying again. The number attempted since * last failure is tracked with compact_considered. */ unsigned int compact_considered; unsigned int compact_defer_shift; int compact_order_failed; #endif #if defined CONFIG_COMPACTION || defined CONFIG_CMA /* Set to true when the PG_migrate_skip bits should be cleared */ bool compact_blockskip_flush; #endif ZONE_PADDING(_pad3_) /* 管理區的一些統計資料 */ atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS]; } ____cacheline_internodealigned_in_smp;
此管理區描述符中的實際把所有屬於該管理區的頁框儲存在兩個地方:struct free_area free_area[MAX_ORDER]和struct per_cpu_pageset __percpu * pageset。free_area是這個管理區的夥伴系統,而pageset是這個區的每CPU頁框快取記憶體。對管理區的理解需要結合夥伴系統和每CPU頁框快取記憶體
管理區頁框分配器(管理所有實體記憶體頁框)
ZONE_NORMAL和ZONE_DMA的地址直接對映到了核心地址空間,但是也不代表核心的程式碼可以隨心所欲的通過線性地址直接訪問實體地址。核心通過一個管理區頁框分配器管理著實體記憶體上所有的頁框,在管理區分配器裡的核心繫統就是夥伴系統和每CPU頁框快取記憶體(不是硬體上的快取記憶體,只是名稱一樣)。在linux系統中,管理區頁框分配器管理著所有實體記憶體,無論你是核心還是程序,需要將一些記憶體佔為己有時,都需要請求管理區頁框分配器,這時才會分配給你應該獲得的實體記憶體頁框。當你所擁有的頁框不再使用時,你必須釋放這些頁框,讓這些頁框回到管理區頁框分配器當中。特別的,對於高階記憶體,即使從管理區頁框分配器中獲得了相應的頁框,我們還需要進行對映才能夠使用。
有時候目標管理區不一定有足夠的頁框去滿足分配,這時候系統會從另外兩個管理區中獲取要求的頁框,但這是按照一定規則去執行的,如下:
- 如果要求從DMA區中獲取,就只能從ZONE_DMA區中獲取。
- 如果沒有規定從哪個區獲取,就按照順序從 ZONE_NORMAL -> ZONE_DMA 獲取。
- 如果規定從HIGHMEM區獲取,就按照順序從 ZONE_HIGHMEM -> ZONE_NORMAL -> ZONE_DMA 獲取。
注意系統是不允許在一次分配中從不同的兩個管理區獲取頁框的,並且當請求多個頁框時,從夥伴系統中分配給目標的頁框是連續的,並且請求的頁數必須是2的次方個數。
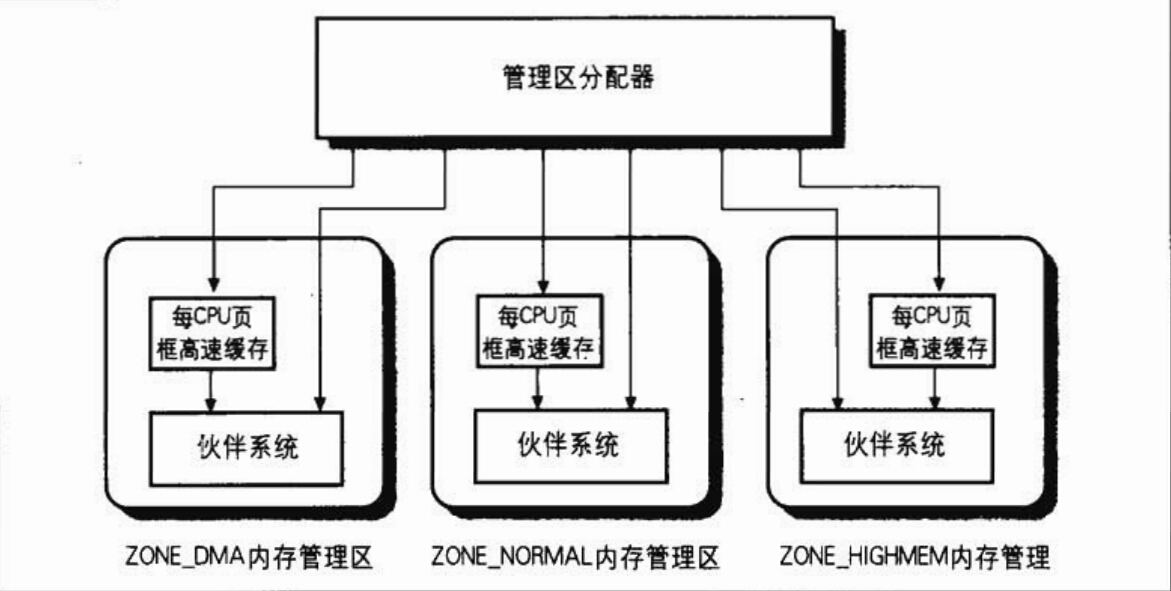
管理區分配器主要做的事情就是將頁框通過夥伴系統或者每CPU頁框快取記憶體分配出去,這裡涉及到三個結構,頁描述符,夥伴系統,每CPU快取記憶體。
我們先說說頁描述符,頁描述符實際上並不專屬於描述頁框,它還用於描述一個SLAB分配器和SLUB分配器,這個之後再說,我們先說關於頁的:
/* 頁描述符,描述一個頁框,也會用於描述一個SLAB,相當於同時是頁描述符,也是SLAB描述符 */ struct page { /* First double word block */ /* 用於頁描述符,一組標誌(如PG_locked、PG_error),也對頁框所在的管理區和node進行編號 */ unsigned long flags; /* Atomic flags, some possibly * updated asynchronously */ union { /* 用於頁描述符,當頁被插入頁快取記憶體中時使用,或者當頁屬於匿名區時使用 */ struct address_space *mapping; /* 用於SLAB描述符,用於執行第一個物件的地址 */ void *s_mem; /* slab first object */ }; /* Second double word */ struct { union { /* 作為不同的含義被幾種核心成分使用。例如,它在頁磁碟映像或匿名區中標識存放在頁框中的資料的位置,或者它存放一個換出頁識別符號 */ pgoff_t index; /* Our offset within mapping. */ /* 用於SLAB描述符,指向第一個空閒物件地址 */ void *freelist; /* 當管理區頁框分配器壓力過大時,設定這個標誌就確保這個頁框專門用於系統釋放其他頁框時使用 */ bool pfmemalloc; }; union { #if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE) /* SLUB使用 */ unsigned long counters; #else /* SLUB使用 */ unsigned counters; #endif struct { union { /* 頁框中的頁表項計數,如果沒有為-1,如果為PAGE_BUDDY_MAPCOUNT_VALUE(-128),說明此頁及其後的一共2的private次方個數頁框處於夥伴系統中,正在使用時應該是0 */ atomic_t _mapcount; struct { /* SLUB使用 */ unsigned inuse:16; unsigned objects:15; unsigned frozen:1; }; int units; /* SLOB */ }; /* 頁框的引用計數,如果為-1,則此頁框空閒,並可分配給任一程序或核心;如果大於或等於0,則說明頁框被分配給了一個或多個程序,或用於存放核心資料。page_count()返回_count加1的值,也就是該頁的使用者數目 */ atomic_t _count; /* Usage count, see below. */ }; /* 用於SLAB描述符 */ unsigned int active; /* SLAB */ }; }; /* Third double word block */ union { /* 包含到頁的最近最少使用(LRU)雙向連結串列的指標,用於插入夥伴系統的空閒連結串列中,只有塊中頭頁框要被插入 */ struct list_head lru;
/* SLAB使用 */ struct { /* slub per cpu partial pages */ struct page *next; /* Next partial slab */ #ifdef CONFIG_64BIT int pages; /* Nr of partial slabs left */ int pobjects; /* Approximate # of objects */ #else short int pages; short int pobjects; #endif }; struct slab *slab_page; /* slab fields */ struct rcu_head rcu_head;
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && USE_SPLIT_PMD_PTLOCKS pgtable_t pmd_huge_pte; /* protected by page->ptl */ #endif }; /* Remainder is not double word aligned */ union { /* 可用於正在使用頁的核心成分(例如: 在緩衝頁的情況下它是一個緩衝器頭指標,如果頁是空閒的,則該欄位由夥伴系統使用,在給夥伴系統使用時,表明的是塊的2的次方數,只有塊的第一個頁框會使用) */ unsigned long private; #if USE_SPLIT_PTE_PTLOCKS #if ALLOC_SPLIT_PTLOCKS spinlock_t *ptl; #else spinlock_t ptl; #endif #endif /* SLAB描述符使用,指向SLAB的快取記憶體 */ struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */ struct page *first_page; /* Compound tail pages */ }; #if defined(WANT_PAGE_VIRTUAL) /* 此頁框第一個實體地址對應的線性地址,如果是沒有對映的高階記憶體的頁框,則為空 */ void *virtual; #endif /* WANT_PAGE_VIRTUAL */ #ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS unsigned long debug_flags; /* Use atomic bitops on this */ #endif #ifdef CONFIG_KMEMCHECK void *shadow; #endif #ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS int _last_cpupid; #endif }
在struct page描述一個頁框時,我們比較關注的成員變數有unsigned long flags、struct list_head lru和atomic_t _count。
- flags:包含有很多資訊,包括此頁框屬於的node結點號,此頁框屬於的zone號和此頁框的屬性。
- lru:用於將此頁描述符放入相應的連結串列,比如夥伴系統或者每CPU頁框快取記憶體。
- _count:代表頁框的引用計數,-1代表此頁框空閒,大於0代表此頁框分配給了多少個程序使用(共享)。
linux為了防止記憶體中產生過多的碎片,一般把頁的型別分為三種:
- 不可移動頁:在記憶體中有固定位置,不能移動到其他地方。核心中使用的頁大部分是屬於這種型別。
- 可回收頁:不能直接移動,但可以刪除,頁中的內容可以從某些源中重新生成。例如,頁內容是對映到檔案資料的頁就屬於這種型別。對於這種型別,在記憶體短缺(分配失敗)時,會發起記憶體回收,將這型別頁進行回寫釋放。
- 可移動頁:可隨意移動,使用者空間的程序使用的沒有對映具體磁碟檔案的頁就屬於這種型別(比如堆、棧、shmem共享記憶體、匿名mmap共享記憶體),它們是通過程序頁表對映的,把這些頁複製到新位置時,只要更新程序頁表就可以了。一般這些頁是從高階記憶體管理區獲取。
夥伴系統
夥伴系統的主要作用就是減少實體記憶體的外部碎片(SLAB/SLUB減少頁框的內部碎片),它實際上是一個struct free_area的陣列,陣列長度是MAX_ORDER,也就是11,代表著每個陣列元素中連結串列上儲存的連續頁框長度是2的order次方。free_area[0]中連結串列儲存的是長度為1的頁框,free_area[1]中連結串列上儲存的是物理上連續的兩個頁框的首頁框連結串列,free_area[2]中連結串列上儲存的是物理上連續4個頁框的首頁框連結串列,free_area[10]中連結串列上儲存的是物理上連續1024個頁框的首頁框連結串列,所以整個夥伴系統中將管理區中的頁框分為連續的1,2,4,8,16,32,64,128,256,512,1024頁框放入不同連結串列中儲存起來。而因為夥伴系統中每個連結串列儲存的頁框都是連續的,所以只有第一個頁框會加入到連結串列中,因為有order,也可以知道此頁框之後的多少個頁框是屬於這一小塊連續頁框的。當需要在普通記憶體區申請4個頁框大小的記憶體時,系統會到普通記憶體管理區的夥伴系統中的free_area[2]中的第一個連結串列結點,這個結點的頁框及其之後3個頁框都是空閒的,然後把首頁框返回給申請者。
/* 夥伴系統的一個塊,描述1,2,4,8,16,32,64,128,256,512或1024個連續頁框的塊 */ struct free_area { /* 指向這個塊中所有空閒小塊的第一個頁描述符,這些小塊會按照MIGRATE_TYPES型別存放在不同指標裡 */ struct list_head free_list[MIGRATE_TYPES]; /* 空閒小塊的個數 */ unsigned long nr_free; };
在夥伴系統中,因為頁的分類關係,在每種長度相同的連續頁框中又會分出多個不同型別的連結串列,如下,
enum { MIGRATE_UNMOVABLE, /* 不可移動頁 */ MIGRATE_RECLAIMABLE, /* 可回收頁 */ MIGRATE_MOVABLE, /* 可移動頁 */ MIGRATE_PCPTYPES, /* 用來表示每CPU頁框快取記憶體的資料結構中的連結串列的可移動型別數目 */ MIGRATE_RESERVE = MIGRATE_PCPTYPES, #ifdef CONFIG_CMA MIGRATE_CMA, #endif #ifdef CONFIG_MEMORY_ISOLATION MIGRATE_ISOLATE, /* 不能從這個連結串列分配頁框,因為這個連結串列專門用於NUMA結點移動實體記憶體頁,將實體記憶體頁移動到使用這個頁最頻繁的CPU */ #endif MIGRATE_TYPES };
儲存連續2個頁框的free_area[2]的結構如下:
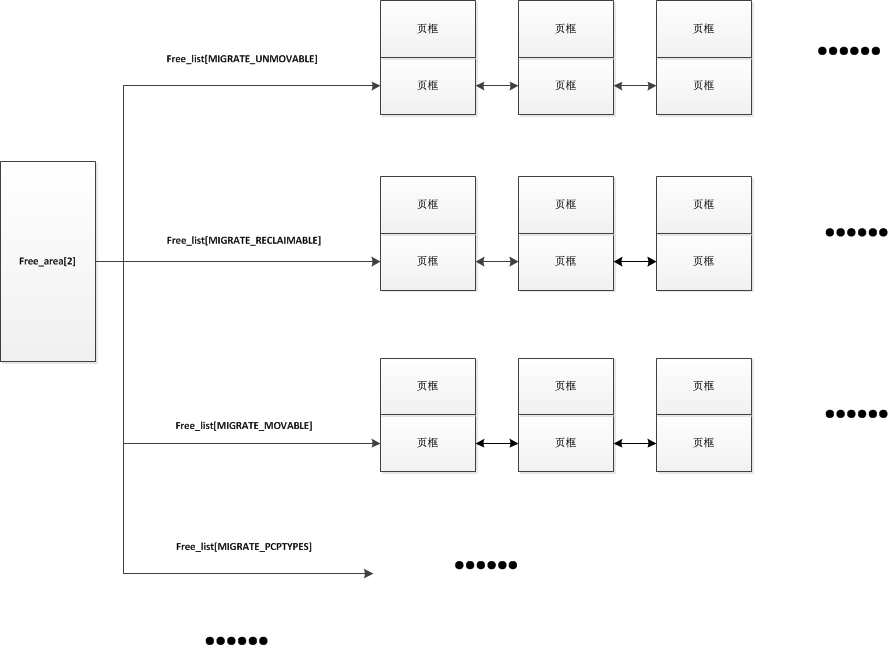
在從夥伴系統中申請頁框時,有可能會遇到一種情況,就是當前需求的連續頁框連結串列上沒有可用的空閒頁框,這時後,夥伴系統會從下一級獲取一個連續長度的頁框塊,將其拆分放入這級列表;當然在擁有者釋放連續頁框時夥伴系統也會適當地進行連續頁框的合併,並放入下一級中。比如:我需要申請4個頁框,但是長度為4個連續頁框塊連結串列沒有空閒的頁框塊,夥伴系統會從連續8個頁框塊的連結串列獲取一個,並將其拆分為兩個連續4個頁框塊,放入連續4個頁框塊的連結串列中。釋放時道理也一樣,會檢查釋放的這幾個頁框的之前和之後的物理頁框是否空閒,並且能否組成下一級長度的塊。
每CPU頁框快取記憶體
每CPU頁框快取記憶體也是一個分配器,配合著夥伴系統進行使用,這個分配器是專門用於分配單個頁框的,它維護一個單頁框的雙向連結串列,為什麼需要這個分配器,因為每個CPU都有自己的硬體快取記憶體,當對一個頁進行讀取寫入時,首先會把這個頁裝入硬體快取記憶體,而如果程序對這個處於硬體快取記憶體的頁進行操作後立即釋放掉,這個頁有可能還儲存在硬體快取記憶體中,這樣我另一個程序需要請求一個頁並立即寫入資料的話,分配器將這個處於硬體快取記憶體中的頁分配給它,系統效率會大大增加。
在每CPU頁框快取記憶體中用一個連結串列來維護一個單頁框的雙向連結串列,每個CPU都有自己的連結串列(因為每個CPU有自己的硬體快取記憶體),那些比較可能處於硬體快取記憶體中的頁被稱為“熱頁”,比較不可能處於硬體快取記憶體中的頁稱為“冷頁”。其實系統判斷是否為熱頁還是冷頁很簡單,越最近釋放的頁就比較可能是熱頁,所以在雙向連結串列中,從連結串列頭插入可能是熱頁的單頁框,在連結串列尾插入可能是冷頁的單頁框。分配時熱頁就從連結串列頭獲取,冷頁就從連結串列尾獲取。
在每CPU頁框快取記憶體中也可能會遇到沒有空閒的頁框(被分配完了),這時候每CPU頁框快取記憶體會從夥伴系統中拿出頁框放入每CPU頁框快取記憶體中,相反,如果每CPU頁框快取記憶體中頁框過多,也會將一些頁框放回夥伴系統。
在核心中使用struct per_cpu_pageset結構描述一個每CPU頁框快取記憶體,其中的struct per_cpu_pages是核心結構體,如下:
/* 描述一個CPU頁框快取記憶體 */ struct per_cpu_pageset { /* 快取記憶體頁框結構 */ struct per_cpu_pages pcp; #ifdef CONFIG_NUMA s8 expire; #endif #ifdef CONFIG_SMP s8 stat_threshold; s8 vm_stat_diff[NR_VM_ZONE_STAT_ITEMS]; #endif }; struct per_cpu_pages { /* 當前CPU快取記憶體中頁框個數 */ int count; /* number of pages in the list */ /* 上界,當此CPU快取記憶體中頁框個數大於high,則會將batch個頁框放回夥伴系統 */ int high; /* high watermark, emptying needed */ /* 在快取記憶體中將要新增或被刪去的頁框個數 */ int batch; /* chunk size for buddy add/remove */ /* Lists of pages, one per migrate type stored on the pcp-lists */ /* 頁框的連結串列,如果需要冷快取記憶體,從連結串列尾開始獲取頁框,如果需要熱快取記憶體,從連結串列頭開始獲取頁框 */ struct list_head lists[MIGRATE_PCPTYPES]; };
關於頁框回收
記憶體中並非所有物理頁面都是可以進行回收的,核心佔用的頁不會被換出,只有與使用者空間建立了對映關係的物理頁面才會被換出。總的來說,以下這些種物理頁面可以被 Linux 作業系統回收:
- 程序對映所佔的頁面,包括程式碼段,資料段,堆疊以及動態分配的“儲存堆”(malloc分配的)。
- 使用者空間中通過mmap()把檔案內容對映到記憶體所佔的頁面。
- 匿名頁面(沒有對映到檔案的都是匿名對映,使用者空間的堆和棧):程序使用者模式下的堆疊以及是使用 mmap 匿名對映的記憶體區(共享記憶體區)。注:堆疊所佔頁面一般不被換出。
- 特殊的用於 slab 分配器的快取,比如用於快取檔案目錄結構 dentry 的 cache,以及用於快取索引節點 inode 的 cache
- tmpfs檔案系統使用的頁。
Linux 作業系統使用如下這兩種機制檢查系統記憶體的使用情況,從而確定可用的記憶體是否太少從而需要進行頁面回收。
- 週期性的檢查:這是由後臺執行的守護程序 kswapd 完成的。該程序定期檢查當前系統的記憶體使用情況,當發現系統內空閒的物理頁面數目少於特定的閾值時,該程序就會發起頁面回收的操作。
- “記憶體嚴重不足”事件的觸發:在某些情況下,比如,作業系統忽然需要通過夥伴系統為使用者程序分配一大塊記憶體,或者需要建立一個很大的緩衝區,而當時系統中 的記憶體沒有辦法提供足夠多的實體記憶體以滿足這種記憶體請求,這時候,作業系統就必須儘快進行頁面回收操作,以便釋放出一些記憶體空間從而滿足上述的記憶體請求。 這種頁面回收方式也被稱作“直接頁面回收”。
如果作業系統在進行了記憶體回收操作之後仍然無法回收到足夠多的頁面以滿足上述記憶體要求,那麼作業系統只有最後一個選擇,那就是使用 OOM( out of memory )killer,它從系統中挑選一個最合適的程序殺死它,並釋放該程序所佔用的所有頁面。
結尾
下篇再說slab了,內容太多。到這裡,記住對於實體記憶體來說,系統都是以頁框作為最小的分配單位,而分配時必定是要通過管理區分配器進行分配的,在管理區分配器中又必定是通過夥伴系統或每CPU頁框分配器進行分配的,而我們程式設計使用到的malloc或者核心中使用的分配小額記憶體的情況,是使用slab實現的,slab的作用就是將一個頁框細分為多個小塊記憶體。
相關推薦
linux記憶體管理原始碼分析
最近在學習核心模組的框架,這裡做個總結,知識太多了。 分段和分頁 先看一幅圖 也就是我們實際中編碼時遇到的記憶體地址並不是對應於實際記憶體上的地址,我們編碼中使用的地址是一個邏輯地址,會通過分段和分頁這兩個機制把它轉為實體地址。而由於linux使用的分段機制有限,可以認為,l
Linux記憶體管理 (透徹分析)
摘要: 本章首先以應用程式開發者的角度審視Linux的程序記憶體管理,在此基礎上逐步深入到核心中討論系統實體記憶體管理和核心記憶體的使用方法。力求從外到內、水到渠成地引導網友分析Linux的記憶體管理與使用。在本章最後,我們給出一個記憶體對映的例項,幫助網友們理解核心記憶體管理
Linux堆記憶體管理深入分析(下)
Linux堆記憶體管理深入分析 (下半部) 作者@走位,阿里聚安全 0 前言回顧 在上一篇文章中,詳細介紹了堆記憶體管理中涉及到的基本概念以及相互關係,同時也著重介紹了堆中chunk分配和釋放策略中使用到的隱式連結串列技術。通過前面的介紹,我們知道使用隱式連結串
Linux堆記憶體管理深入分析(上)
Linux堆記憶體管理深入分析 (上半部) 作者:走位@阿里聚安全 0 前言 近年來,漏洞挖掘越來越火,各種漏洞挖掘、利用的分析文章層出不窮。從大方向來看,主要有基於棧溢位的漏洞利用和基於堆溢位的漏洞利用兩種。國內關於棧溢位的資料相對較多,這裡就不累述了,
Linux記憶體管理(最透徹的一篇)
摘要:本章首先以應用程式開發者的角度審視Linux的程序記憶體管理,在此基礎上逐步深入到核心中討論系統實體記憶體管理和核心記憶體的使用方法。力求從外到內、水到渠成地引導網友分析Linux的記憶體管理與使用。在本章最後,我們給出一個記憶體對映的例項,幫助網友們理解核心記憶體管理與使用者記憶體管理之
【轉】Linux記憶體管理
摘要:本章首先以應用程式開發者的角度審視Linux的程序記憶體管理,在此基礎上逐步深入到核心中討論系統實體記憶體管理和核心記憶體的使用方法。力求從外到內、水到渠成地引導網友分析Linux的記憶體管理與使用。在本章最後,我們給出一個記憶體對映的例項,幫助網友們理解核心記憶體管理與使用者記憶體管理之間的
linux記憶體管理的 夥伴系統和slab機制
夥伴系統 Linux核心中採用了一種同時適用於32位和64位系統的記憶體分頁模型,對於32位系統來說,兩級頁表足夠用了,而在x86_64系統中,用到了四級頁表。四級頁表分別為: 頁全域性目錄(Page Global Directory) 頁上級目錄(Page Upper Director
linux記憶體管理---虛擬地址 邏輯地址 線性地址 實體地址的區別(一)
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Linux記憶體管理之malloc實現
程序虛擬地址空間由一個一個VMA來表示,這裡先接收VMA相關操作. 1.1 查詢VMA函式find_vma() struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addr) 找到的vma結果需滿足條件:
Linux記憶體描述之記憶體節點node--Linux記憶體管理(二)
1 記憶體節點node 1.1 為什麼要用node來描述記憶體 這點前面是說的很明白了, NUMA結構下, 每個處理器CPU與一個本地記憶體直接相連, 而不同處理器之前則通過匯流排進行進一步的連線, 因此相對於任何一個CPU訪問本地記憶體的速度比訪問遠端記憶體的速度要快 Linux適用於各種不同的體系結
Linux記憶體描述之記憶體區域zone--Linux記憶體管理(三)
1 記憶體管理域zone 為了支援NUMA模型,也即CPU對不同記憶體單元的訪問時間可能不同,此時系統的實體記憶體被劃分為幾個節點(node), 一個node對應一個記憶體簇bank,即每個記憶體簇被認為是一個節點 首先, 記憶體被劃分為結點. 每個節點關聯到系統中的一個處理器, 核心中表示為pg_
Linux記憶體描述之記憶體頁面page--Linux記憶體管理(四)
1 Linux如何描述實體記憶體 Linux把實體記憶體劃分為三個層次來管理 層次 描述 儲存節點(Node) CPU被劃分為多個節點(node), 記憶體則被分簇, 每個CPU對應一個本地實體記憶體, 即一個CPU-node對應
Linux分頁機制之概述--Linux記憶體管理(六)
1 分頁機制 在虛擬記憶體中,頁表是個對映表的概念, 即從程序能理解的線性地址(linear address)對映到儲存器上的實體地址(phisical address). 很顯然,這個頁表是需要常駐記憶體的東西, 以應對頻繁的查詢對映需要(實際上,現代支援VM的處理器都有一個叫TLB的硬體級頁表快取部件
Linux記憶體管理 (26)記憶體相關工具
1. vmstat 參照《Linux CPU佔用率監控工具小結-vmstat》 2. memstat memstat可以通過sudo apt install memstat安裝,安裝包括兩個檔案memstat和memstat.conf。 其中memstat.conf是memstat配置
Linux分頁機制之分頁機制的演變--Linux記憶體管理(七)
1 頁式管理 1.1 分段機制存在的問題 分段,是指將程式所需要的記憶體空間大小的虛擬空間,通過對映機制對映到某個實體地址空間(對映的操作由硬體完成)。分段對映機制解決了之前作業系統存在的兩個問題: 地址空間沒有隔離 程式執行的地址不確定 不過分段方法存在一個嚴重的問題:記憶體的使用效率
Linux-記憶體管理子系統
Linux-記憶體管理子系統 記憶體管理子系統職能: 1. 管理虛擬地址和實體地址的對映;2. 管理實體記憶體的分配 虛擬記憶體空間 空間分佈: 1. 使用者空間 如 0-3G地址空間 被使用者程序所使用與核心的直接對映區使用的是同
spring事務管理原始碼分析(一)配置和事務增強代理的生成流程
在本篇文章中,將會介紹如何在spring中進行事務管理,之後對其內部原理進行分析。主要涉及 @EnableTransactionManagement註解為我們做了什麼? 為什麼標註了@Transactional註解的方法就可以具有事務的特性,保持了資料的ACID特性?spring到底是如何具有這樣
啟動期間的記憶體管理之bootmem_init初始化記憶體管理–Linux記憶體管理(十二)
1. 啟動過程中的記憶體初始化 首先我們來看看start_kernel是如何初始化系統的, start_kerne定義在init/main.c?v=4.7, line 479 其程式碼很複雜, 我們只截取出其中與記憶體管理初始化相關的部分, 如下所示 table th:nth-of-type(1){
啟動期間的記憶體管理之build_zonelists初始化備用記憶體域列表zonelists--Linux記憶體管理(十三)
1. 今日內容(第二階段(二)–初始化備用記憶體域列表zonelists) 我們之前講了在memblock完成之後, 記憶體初始化開始進入第二階段, 第二階段是一個漫長的過程, 它執行了一系列複雜的操作, 從體系結構相關資訊的初始化慢慢向上層展開, 其主要執行了如下操作 特定於體系結構的設定 在完成了基
Linux記憶體管理-linuxnote03
linuxnote01和linuxnote02中學習了Linux中程序執行緒的描述,並學習了Linux中如何進行程序管理,學習理解的過程中,我們有收穫也有疑惑,比如什麼是程序的地址空間這個地址空間存在哪兒,什麼是核心棧,頁表是什麼?等等的問題,其中一些問題都是與Linux中記