
《BI那點兒事》資料流轉換——透視
這個和T-SQL中的PIVOT和UNPIVOT的作用是一樣的。資料透視轉換可以將資料規範或使它在報表中更具可讀性。
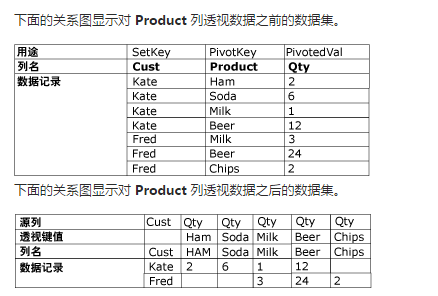
通過透視列值的輸入資料,透視轉換將規範的資料集轉變成規範程度稍低、但更為簡潔的版本。例如,在列有客戶名稱、產品和購買數量的規範的 Orders 資料集中,任何購買多種產品的客戶都有多行,每一行顯示一種產品的詳細訂購資訊。此時,如果對產品列透視資料集,透視轉換可以輸出每個客戶只有一行的資料集。這一行列出該客戶購買的所有產品,產品名稱顯示為列名,而數量則顯示為產品列的值。並非每個客戶都購買所有產品,所以很多列可能包含空值。
透視資料集時,輸入列在透視過程中扮演不同的角色。列可以按以下方式參與:
- 將列原封不動地傳遞到輸出。因為有許多輸入行只能產生一個輸出行,所以轉換隻複製列的第一個輸入值。
- 列作為一組記錄的標識鍵或標識鍵的一部分。
- 列定義透視。此列中的值與已透視資料集中的列相關聯。
- 列包含置於透視所建立的列中的值。
生成測試資料:
CREATE TABLE FactOrders ( Id INT IDENTITY , Cust VARCHAR(50) , Product VARCHAR(50) , Qty INT ) INSERT INTO FactOrders ( Cust , Product , Qty )SELECT 'Kate' , 'Ham' , 2 UNION ALL SELECT 'Kate' , 'Soda' , 6 UNION ALL SELECT 'Kate' , 'Milk' , 1 UNION ALL SELECT 'Kate' ,'Beer' , 12 UNION ALL SELECT 'Fred' , 'Milk' , 3 UNION ALL SELECT 'Fred' , 'Beer' , 24 UNION ALL SELECT 'Fred' , 'Chips' , 2 SELECT * FROM FactOrders
配置示例資料集
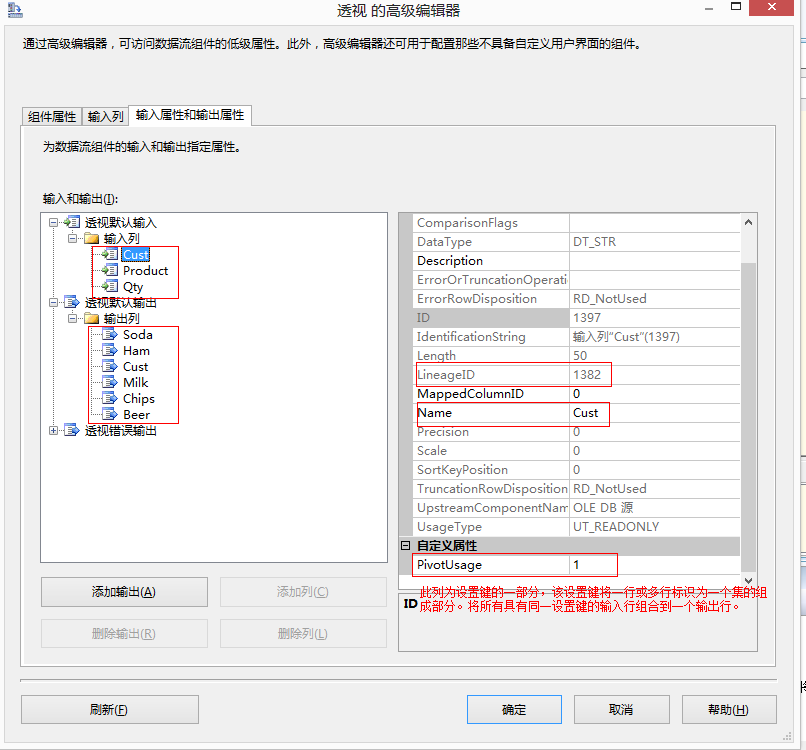
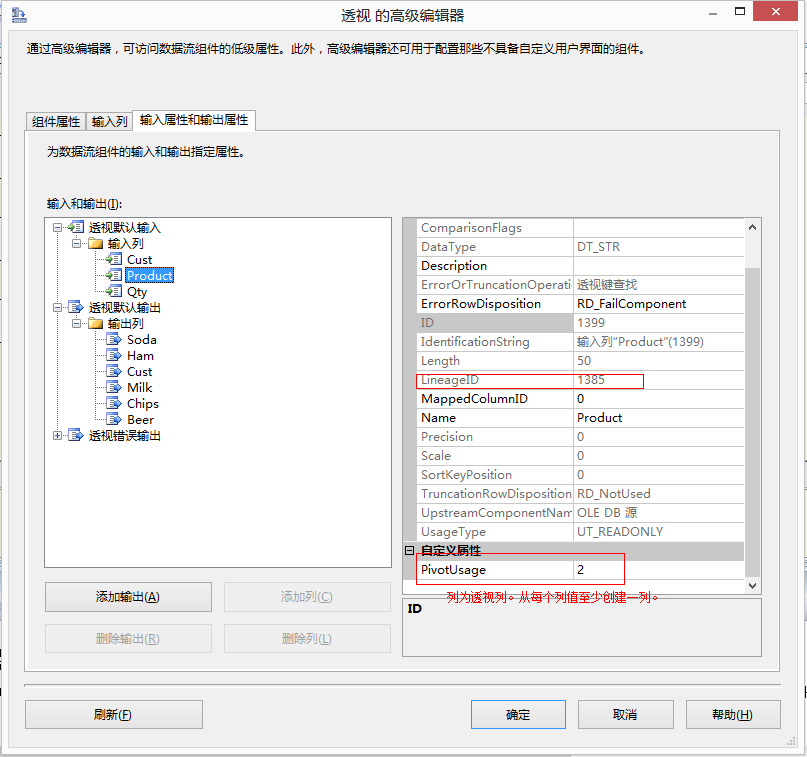
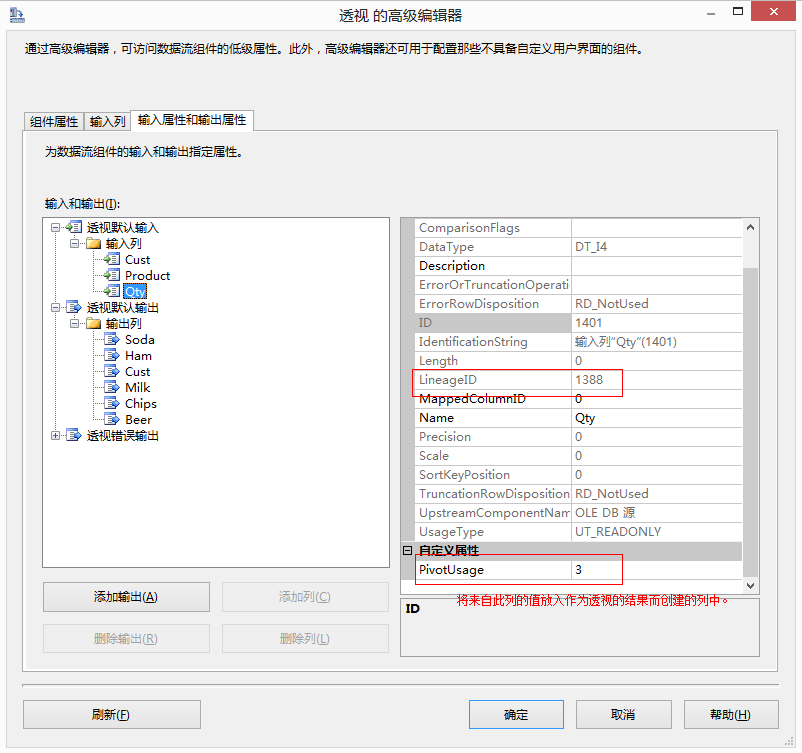
關係圖中顯示的示例資料集的具體配置如下:將 Cust 列的 PivotUsage 屬性設定為 1,以指示這是設定鍵列;將 Product 輸入列的 PivotUsage 屬性設定為 2,以指示必須為每個產品建立一列;將 Qty 輸入列的 PivotUsage 屬性設定為 3,以指示將數量值放入透視列。
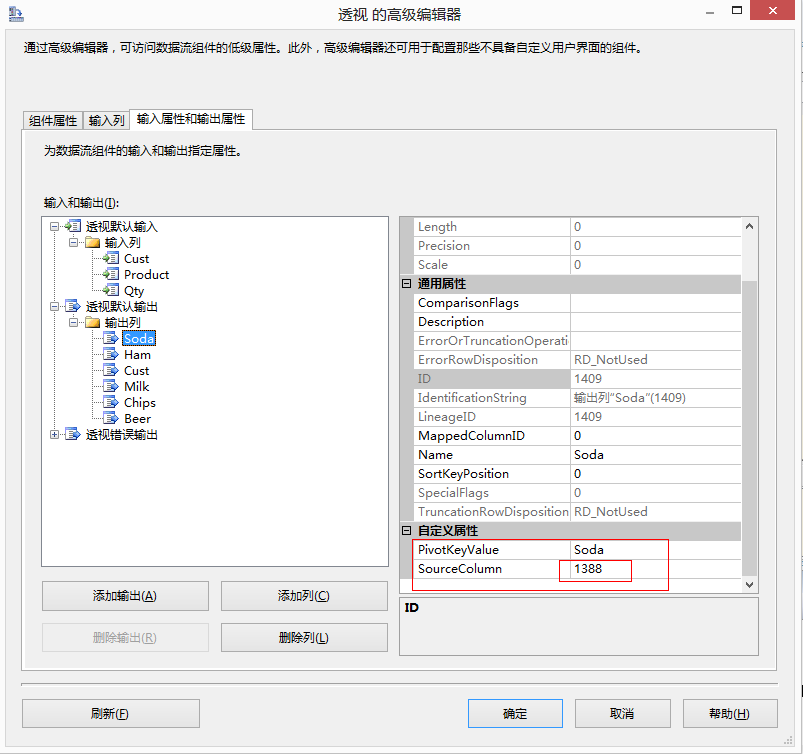
將轉換輸出設定為包含六個列。這些列可以使用“高階編輯器”對話方塊進行新增,分別命名為 Cust、Ham、Soda、Milk、Beer 和 Chips。將 Ham 列的 PivotKeyValue 屬性設定為 Ham,以指示轉換應在輸入列中查詢該值。同樣,將 Soda 列的 PivotKeyValue 屬性設定為 Soda,依此類推。
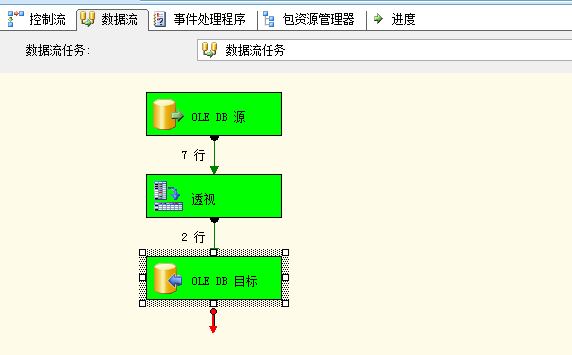
然後將轉換輸入中的列對映到輸出中的列。
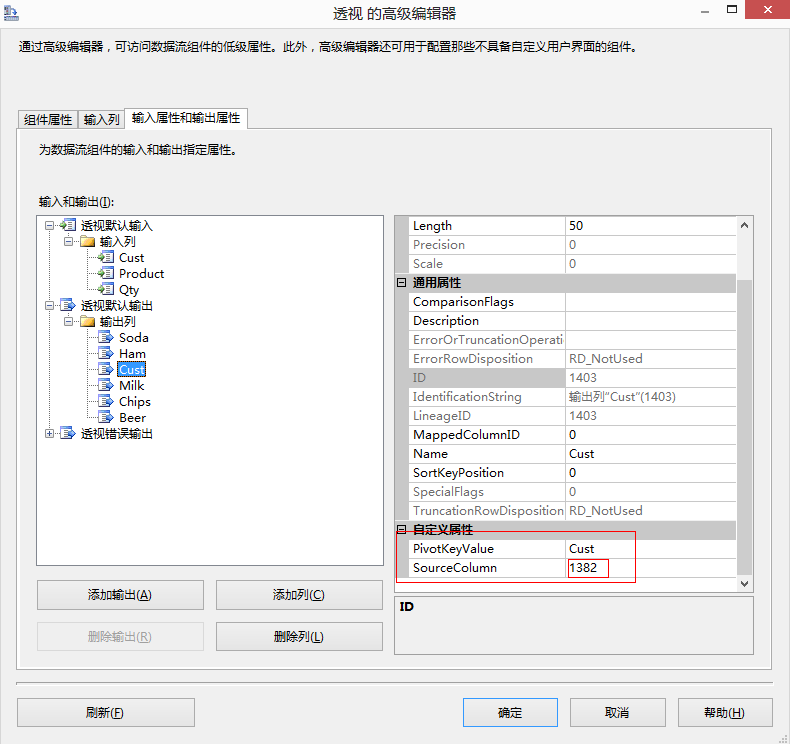
將 Cust 列的 SourceColumn 屬性配置為使用 Cust 輸入列的沿襲識別符號。將 Ham、Soda、Milk、Beer 和 Chips 各列的 SourceColumn 屬性配置為使用 Qty 輸入列的沿襲識別符號。進行此配置的另一種方法是將 Ham、Soda、Milk、Beer 和 Chips 各列的 SourceColumn 屬性設定為 -1,這將插入 True 值而非資料值。例如,這樣 Beer 列就不會包含值 12 和 24 而是包含值 True,以便僅指示該客戶購買了產品,但不顯示購買數量。
轉換輸出中的行包含來自 Cust 和 Qty 輸入列的值。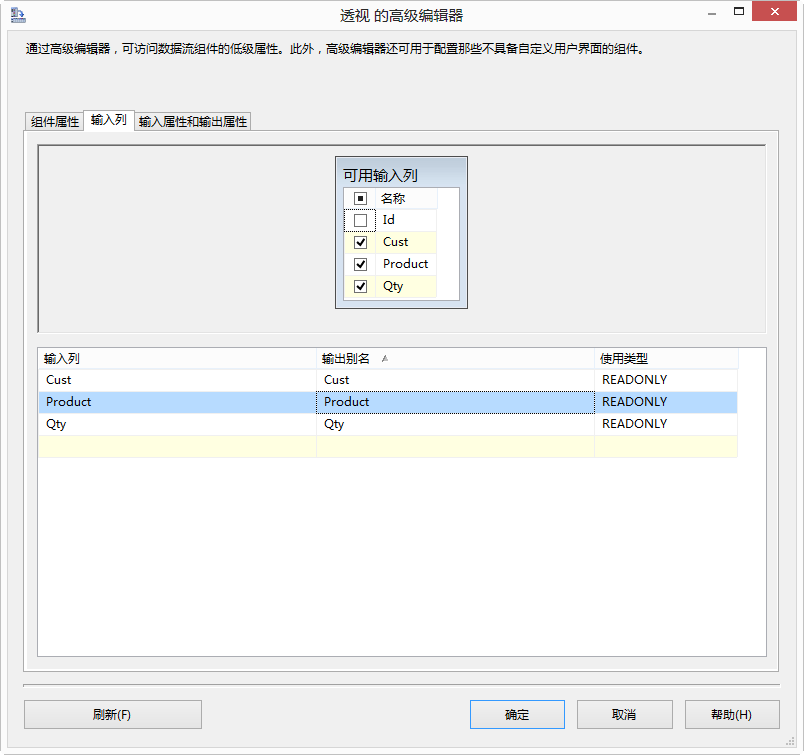
相關推薦
《BI那點兒事—資料的藝術》理解維度資料倉庫——事實表、維度表、聚合表
事實表 在多維資料倉庫中,儲存度量值的詳細值或事實的表稱為“事實表”。一個按照州、產品和月份劃分的銷售量和銷售額儲存的事實表有5個列,概念上與下面的示例類似。 Sate Product Mouth Units Dollars
《BI那點兒事》資料流轉換——逆透視轉換
逆透視轉換將來自單個記錄中多個列的值擴充套件為單個列中具有同樣值的多個記錄,使得非規範的資料整合為較規範的版本。例如,每個客戶在列出客戶名的資料集中各佔一行,在該行的各列中顯示購買的產品和數量。逆透視轉換將資料集規範之後,客戶購買的每種產品在該資料集中各佔一行。 我們下一步是進行逆透視。與透視配置不
《BI那點兒事》資料流轉換——透視
這個和T-SQL中的PIVOT和UNPIVOT的作用是一樣的。資料透視轉換可以將資料規範或使它在報表中更具可讀性。 通過透視列值的輸入資料,透視轉換將規範的資料集轉變成規範程度稍低、但更為簡潔的版本。例如,在列有客戶名稱、產品和購買數量的規範的 Orders 資料集中,任何購買多種產品的客戶都有多行,每一行
《BI那點兒事》資料流轉換——查詢轉換
查詢轉換通過聯接輸入列中的資料和引用資料集中的列來執行查詢。是完全匹配查詢。在源表中查詢與字表能關聯的所有源表記錄。準備資料。源表 T_QualMoisture_Middle_Detail字典表 T_DIC_QualProcess資料流任務設計圖: 設計步驟: (adsbygo
《BI那點兒事》資料流轉換——多播、Union All、合併、合併聯接
建立測試資料: CREATE TABLE FactResults ( Name VARCHAR(50) , Course VARCHAR(50) , Score INT ) INSERT INTO FactResults
《BI那點兒事》資料流轉換——OLE DB 命令轉換
OLE DB命令對資料流中的資料行執行一個OLE DB命令。它針對資料表中的每一行進行更新操作,可以事先將要更新的資料存放在表中。或者針對一個有輸入引數的儲存過程,可以將這些引數存放在一個數據表中,不用每次都輸入引數。示例資料準備: CREATE TABLE SourceParametersForSt
《BI那點兒事》資料流轉換——排序
排序轉換允許對資料流中的資料按照某一列進行排序。這是五個常用的轉換之一。連線資料來源開啟編輯介面,編輯這種任務。不想設定為排序列的欄位不要選中,預設情況下所有列都會選中。如圖所示,按照TotalSugar_Cnt排序,並將所有列輸出。 在底部的表格中,可以設定輸出列的別名,是否按照列來排序。Sort Ord
《BI那點兒事》資料流轉換——資料轉換
資料轉換執行類似於T-SQL中的函式CONVERT或CAST的功能。資料轉換的編輯介面如圖,選擇需要轉換的列,在DataType下拉列表中選擇需要的資料型別。Output Alias欄內設定輸出時使用的別名。 (adsbygoogle = window.adsbygoogle |
《BI那點兒事》資料流轉換——匯入列、匯出列
匯入列: 匯入列例子現在來做一個例子:建立路徑D:\Pictures隨便在路徑D:\Pictures中貼上4個比較小的影象檔案命名為01.png、02.png、03.png、04.png在路徑D:\Pictures內建立一個txt檔案命名為filelist.txt,檔案內容如下D:\Pictures\01.
《BI那點兒事》資料流轉換——字詞查詢轉換
字詞查詢轉換將從轉換輸入列的文字中提取的字詞與引用表中的字詞進行匹配,然後計算出查詢表中的字詞在輸入資料集中出現的次數,並將計數與引用表中的此字詞一併寫入轉換輸出的列中。此轉換對於建立基於輸入文字並帶有詞頻統計資訊的自定義詞列表很有用。 本章功能:取出一個表中某欄位的資料,並取出另一個表中的關鍵詞,判斷關鍵
《BI那點兒事》資料流轉換——條件性拆分
根據條件分割資料是一個在資料流中新增複雜邏輯的方法,它允許根據條件將資料輸出到其他不同的路徑中。例如,可以將TotalSugar< 27.4406的輸出到一個路徑,TotalSugar >= 27.4406的輸出到另一個路徑。如圖。可以從上面的屬性結構中拖放一個列或者程式碼段,然後根據邏輯重新命名
《BI那點兒事》資料流轉換——派生列
派生列轉換通過對轉換輸入列應用表示式來建立新列值。 表示式可以包含來自轉換輸入的變數、函式、運算子和列的任意組合。 結果可作為新列新增,也可作為替換值插入到現有列。 派生列轉換可定義多個派生列,任何變數或輸入列都可以出現在多個表示式中。可以使用此轉換執行下列任務: 將不同列的資料連線到一個派生列中。 例
《BI那點兒事》資料流轉換——百分比抽樣、行抽樣
百分比抽樣和行抽樣可以從資料來源中隨機選擇一組資料。這兩種task都可以產生兩組輸出,一組是隨機選擇的,另一組是沒有被選擇的。可以將這些選擇出的資料傳送到開發或者測試伺服器上。這個Task的最合適的應用是建立資料探勘模型然後,使用這些抽樣資料來驗證這個模型。 編輯這種task,選擇要抽取的行數或者 百分比,
《BI那點兒事》資料流轉換——模糊分組轉換
在模糊查詢中我們提到髒資料是怎樣進入到表中的事情,主要還是由於一些“Lazy-add”造成的。這種情況我們的肉眼很容易被欺騙,看上去是同一個單詞,其實就差那麼一個字母,變成了兩個不同的單詞。一個簡單的例子是X-Ray Tech和xRey,我們很有可能認為他們是同一個職務,CT操作員,但是如果讓計算機來處理的話
《BI那點兒事》資料探勘各類演算法——準確性驗證
準確性驗證示例1:——基於三國志11資料庫 資料準備: 挖掘模型:依次為:Naive Bayes 演算法、聚類分析演算法、決策樹演算法、神經網路演算法、邏輯迴歸演算法、關聯演算法提升圖: 依次排名為: 1. 神經網路演算法(92.69% 0.99)2. 邏輯迴歸演算法(92.39% 0.99)3. 決策
《BI那點兒事》淺析十三種常用的資料探勘的技術
一、前沿 資料探勘就是從大量的、不完全的、有噪聲的、模糊的、隨機的資料中,提取隱含在其中的、人們事先不知道的但又是潛在有用的資訊和知識的過程。資料探勘的任務是從資料集中發現模式,可以發現的模式有很多種,按功能可以分為兩大類:預測性(Predictive)模式和描述性(Descriptive)模式。在應用
《BI那點兒事》資料探勘初探
什麼是資料探勘? 資料探勘(Data Mining),又稱資訊發掘(Knowledge Discovery),是用自動或半自動化的方法在資料中找到潛在的,有價值的資訊和規則。 資料探勘技術來源於資料庫,統計和人工智慧。 資料探勘能夠做什麼 對企業中產生的大量的資料進行分析,找出其中潛藏的規
《BI那點兒事》資料探勘的主要方法
一、迴歸分析目的:設法找出變數間的依存(數量)關係, 用函式關係式表達出來。所謂迴歸分析法,是在掌握大量觀察資料的基礎上,利用數理統計方法建立因變數與自變數之間的迴歸關係函式表示式(稱迴歸方程式)。迴歸分析中,當研究的因果關係只涉及因變數和一個自變數時,叫做一元迴歸分析;當研究的因果關係涉及因變數和兩個或兩個
《BI那點兒事》SSRS圖表和儀表——雷達圖分析三國超一流謀士、統帥資料(圖文並茂)
雷達圖分析三國超一流謀士、統帥資料,獻給廣大的三國愛好者們,希望喜歡三國的朋友一起討論,加深對傳奇三國時代的瞭解 建立資料環境: -- 抽取三國超一流謀士TOP 10資料 DECLARE @t1 TABLE ( [姓名] NVARCHAR(255) , [統率]
《BI那點兒事》運用標準計分和離差——分析三國超一流統帥綜合實力排名 絕對客觀,資料說話
資料分析基礎概念:標準計分: 1、無論作為變數的滿分為幾分,其標準計分的平均數勢必為0,而其標準差勢必為1。2、無論作為變數的單位是什麼,其標準計分的平均數勢必為0,而其標準差勢必為1。公式為: 離差:離差就是應用標準計分所得的數值。1、無論作為變數的滿分為幾分,其離差的平均數勢必為50,而其標準差勢必為1