
《BI專案筆記》挑選產出分析Cube
資料來源設定:
資料處理邏輯:
--I_GBGradeID SELECT * FROM T_NPick_PkgMov WHERE I_GBGradeID NOT IN ( SELECT I_GBGradeID FROM T_GBGradeCode ) DELETE FROM T_NPick_PkgMov WHERE I_GBGradeID NOT IN ( SELECT I_GBGradeIDFROM T_GBGradeCode ) --V_CustomerID SELECT * FROM T_NPick_PkgMov WHERE V_CustomerID NOT IN ( SELECT C_CustCode FROM T_CustomInfo ) ALTER TABLE T_NPick_PkgMov ALTER COLUMN V_CustomerID VARCHAR(5) NOT NULL--新增業務日期BusinessDate欄位 ALTER TABLE T_NPick_PkgMov ADD BusinessDate INT NULL --將datetime轉為int UPDATE T_NPick_PkgMov SET BusinessDate = CAST(REPLACE(CONVERT(CHAR(10), D_Time, 120), '-', '') AS INT)
主要指標:
N_Weight重量_合計
I_Piece 件數_合計
需要抽取的維度表:
|
序號 |
表名 |
說明 |
備註 |
|
1 |
T_GBGradeCode |
菸葉級別 |
|
|
2 |
T_Distinction |
菸葉等級 |
|
|
3 |
T_Origin |
產地 |
|
|
4 |
T_PurchaseType |
收購型別 |
|
|
5 |
T_TLProcType |
加工型別 |
|
|
6 |
T_CustomInfo |
客戶 |
需要抽取的事實表:
|
序號 |
表名 |
說明 |
備註 |
|
1 |
T_NPick_PkgMov |
挑選產出 |
V_CycleNode 01 挑選產出 |
專案結構:
瀏覽效果: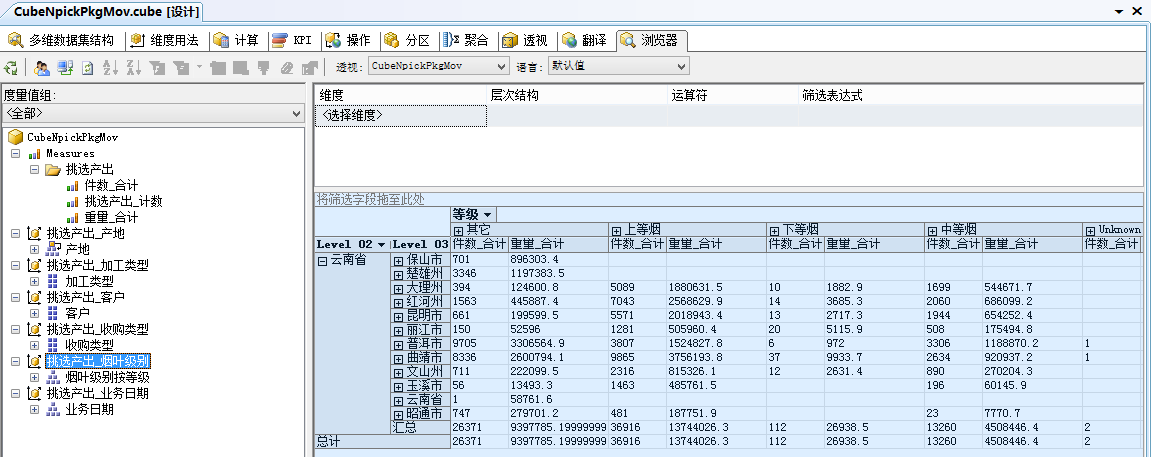
客戶端: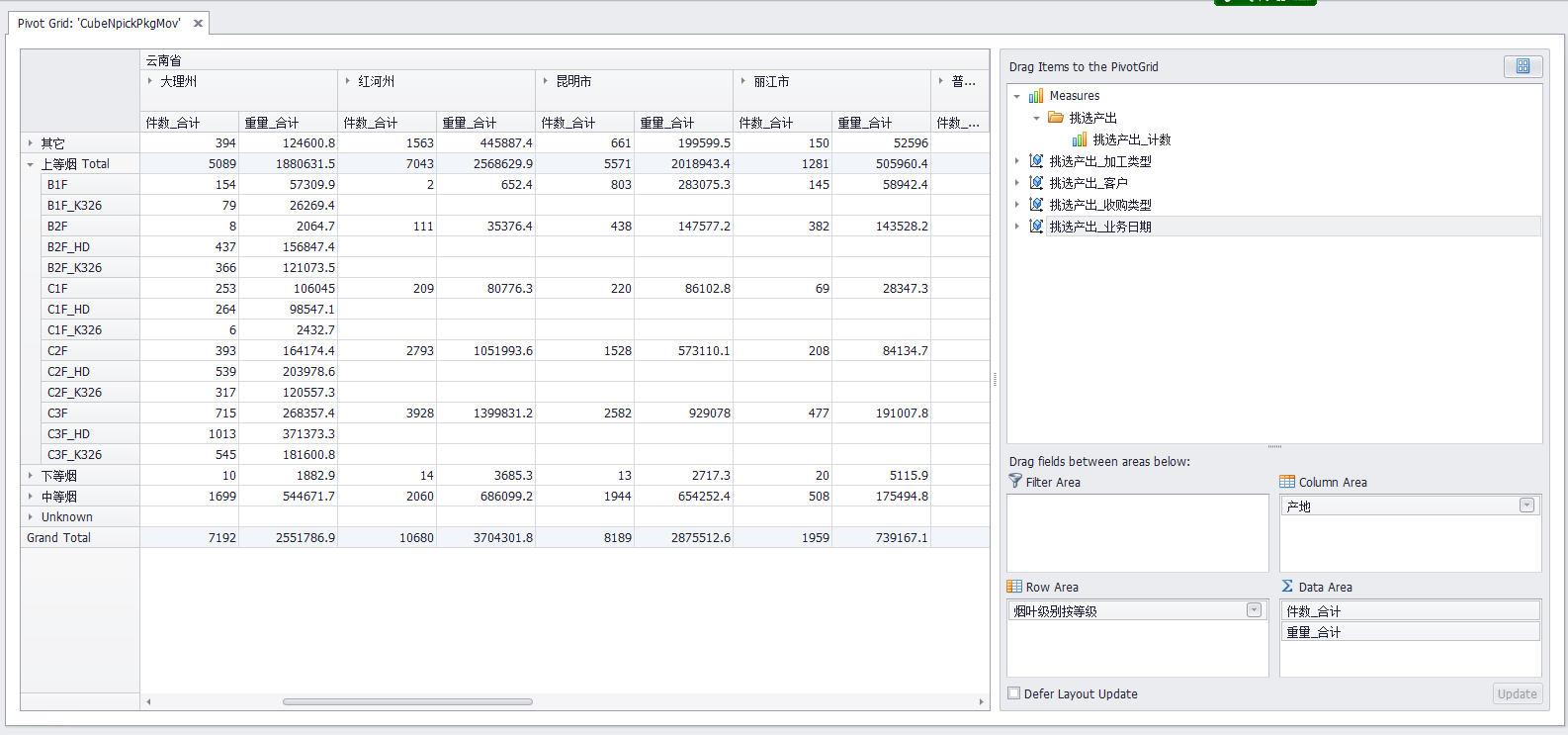
相關推薦
《BI專案筆記》挑選產出分析Cube
資料來源設定: 資料處理邏輯: --I_GBGradeID SELECT * FROM T_NPick_PkgMov WHERE I_GBGradeID NOT IN ( SELECT I_GBGradeID FROM
《BI專案筆記》歷年感官評吸質量均值變化分析Cube的建立
分析主題主要維度:菸葉級別、菸葉級別按等級資訊、菸葉級別按分級標準(標準維度)產地(父子維度)檢測時間(時間維度,以Tqc_Raw_SmokingTest .CheckTime欄位派生CheckDate欄位)樣品維度 主要指標: 香氣特徵_清香_平均值香氣特徵_甜香_平均值香氣特徵_焦香_平均值煙氣特徵_
《BI專案筆記》歷年外觀質量均值變化分析Cube的建立
分析主題主要維度:菸葉級別、菸葉級別按等級資訊、菸葉級別按分級標準(標準維度)產地(父子維度)檢測時間(時間維度,以Tqc_Raw_PresentationQuality . CheckTime欄位派生CheckDate欄位)樣品維度 主要指標:部位_平均值顏色_平均值成熟度_平均值油分_平均值身份_平均值
《BI專案筆記》報到資訊分析Cube
--處理丟失外來鍵關係資料 SELECT * FROM T_ReportLeafGrade WHERE FSubFID NOT IN ( SELECT FID FROM T_RaceLeafReport )
《BI專案筆記》歷年的初煙水分均值變化分析Cube的建立
主要維度: 班組班次檢測項質檢日期(時間維度)加工客戶加工型別收購型別生產線產地菸葉級別 主要指標:慢速測定_平均值快速測定_平均值紅外測定_平均值ETL設計 需要抽取的維度表: 序號 表名 說明 備註 1 T_Departme
《BI專案筆記》建立多維資料集Cube(1)
有兩個事實表,因此就有兩個度量值組,並且嚮導將為非維度鍵的事實表中的每一個數值列建立一個度量值。由於我們這裡不需要那麼多,所以只選擇部分度量值。另外要注意,度量值的名稱源於事實表中的列,所有名稱由可能相同。但是在多維資料集中,由於度量值的名稱必須是唯一的,所以嚮導會在重複的度量值名稱後新增所屬的度量值組名
《BI專案筆記》建立多維資料集Cube(2)
本節建立: 歷年的初煙水分均值變化分析Cube:區域維度:地州,專縣時間維度:年等級維度:大等級,小等級指標:水分均值資料來源檢視: 資料處理: ALTER TABLE T_QualMoisture_Middle ALTER COLUMN V_Produce_ID VARCHAR(50)
《BI專案筆記》多維資料集中度量值設計時的聚合函式
Microsoft SQL Server Analysis Services 提供了幾種函式,用來針對包含在度量值組中的維度聚合度量值。預設情況下,度量值按每個維度進行求和。但是,通過 AggregateFunction 屬性,您可以修改此行為。聚合函式的累加性可確定度量值如何在多維資料集的所有維度中進行聚合
《BI專案筆記》無法解密受保護的 XML 節點“DTS:Password” 解決辦法
說明: 無法解密受保護的 XML 節點“DTS:Password”,錯誤為 0x8009000B“該項不適於在指定狀態下使用。”。可能您無權訪問此資訊。當發生加密錯誤時會出現此錯誤。請確保提供正確的金鑰。 解決辦法:1.在Integration Services中找到要執行的包,右鍵選擇匯出包,在匯出包屬性
《BI專案筆記》建立時間維度(2)
建立步驟: 序號 選擇的屬性 重新命名後的名稱 屬性類別 1 DateKey D
《BI專案筆記》建立時間維度(1)
SSAS Date 維度基本上在所有的 Cube 設計過程中都存在,很難見到沒有時間維度的 OLAP 資料庫。但是根據不同的專案需求, Date 維度的設計可能不大相同,所以在設計時間維度的時候需要搞清楚幾個問題: 你的業務涉及到的最低的細節級別是什麼?比如按季度檢視報表還是按月份,或者按周,或者再甚者
《BI專案筆記》增量ETL資料抽取的策略及方法
增量抽取 增量抽取只抽取自上次抽取以來資料庫中要抽取的表中新增或修改的資料。在ETL使用過程中。增量抽取較全量抽取應用更廣。如何捕獲變化的資料是增量抽取的關鍵。對捕獲方法一般有兩點要求:準確性,能夠將業務系統中的變化資料按一定的頻率準確地捕獲到;效能,不能對業務系統造成太大的壓力,影響現有業務。目前增量資料抽
《BI專案筆記》建立父子維度
建立步驟: 而ParentOriginID其實就是對應的ParentOriginID,它的 Usage 必須是 Parent 才能表示這樣的一個父子維度。 檢視OriginID屬性, Usage 是 Key。 在這裡一定要注意,父子關係層次結構中的子級必須是維度的關鍵屬性,所以OriginID這裡的
《BI專案筆記》基於雪花模型的維度設計
GBGradeCode 外來鍵關係: 1 菸葉等級 T_GBGradeCode.I_DistinctionID=T_Distinction.I_Distinc
《BI專案筆記》SSAS部署時發生的問題——元資料管理器中存在錯誤 解決辦法
在生成和部署期間出錯。是否繼續?解決辦法: 用Microsoft SQL Server Management Studio 連線Analysis Services 然後刪除多維資料庫,重新佈署。這樣就OK的。 (adsbygoogle = window.adsbygoogle
Lucene筆記38-Lucene在專案中的實現分析
一、實時搜尋中存在的問題 上一節我們提到NRT實時搜尋,實時搜尋的提交併不是實時的,可能要好幾個小時才能提交一次,為什麼搜尋這麼快呢,因為索引資料更新都在記憶體中實現的,那麼,假設有這麼一種情況,還沒有提交,機器突然掛掉了,那硬碟上的資料還是舊的,就會存在資料不一致的問題了。現在有一個解決方
[BI專案記]-配置Sharepoint2013支援文件版本管理筆記
做開發或者做方案,寫文件是很重要的一個工作,我們經常需要知道文件被修改的次數,誰在什麼時間修改的文件,以及在某一個版本中,都修改了哪些內容,以及不同版本的文件之間有什麼差別。 如何對文件進行版本管理,除了用我們最基本的原始碼工具之外,用Sharepoint是最好不過的一個選擇。當然如果你有Office365
[BI專案記]-文件版本管理筆記
程式碼的版本管理程式設計師們有專門的工具,那麼作為專案管理人員如何進行文件版本的管理呢,此篇介紹如何通過SharePoint進行文件版本管理。 在沒有SharePoint的時代我們如何管理版本呢?通常我們會在本地建立一個目錄,或者在伺服器上建立一個共享目錄。但隨著專案的進展文件在所難免要更新多次,而每次
LR學習筆記20-LR分析場景
方案 sta files eight 圖表 png run 有助於 .com 進入LR場景分析了,師傅領進門,修行靠個人吧。主要內容如下: ----示例demo ----各個圖表的簡要說明。本次分析和學習的主體就是Analysis。 學習主體為LR自帶的D:\Program
CS224n筆記6 句法分析
png 技術分享 src -1 神經網絡 技術 cnblogs .cn alt 句法分析還算熟悉,就跟著復習了神經網絡句法分析的動機與手法,了解一下比較前沿的動向 CS224n筆記6 句法分析