
網路爬蟲:使用多執行緒爬取網頁連結
前言:
經過前面兩篇文章,你想大家應該已經知道網路爬蟲是怎麼一回事了。這篇文章會在之前做過的事情上做一些改進,以及說明之前的做法的不足之處。
思路分析:
1.邏輯結構圖
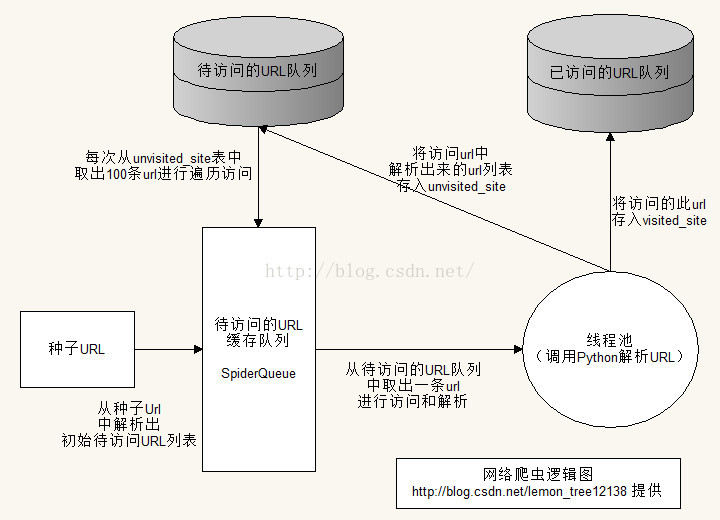
上圖中展示的就是我們網路爬蟲中的整個邏輯思路(呼叫Python解析URL,這裡只作了簡略的展示)。
2.思路說明:
首先,我們來把之前思路梳理一下。之前我們採用的兩個佇列Queue來儲存已經訪問過和待訪問的連結列表,並採用廣度優先搜尋進行遞迴訪問這些待訪問的連結地址。而且這裡使用的是單執行緒操作。在對資料庫的操作中,我們添加了一個輔助欄位cipher_address來進行“唯一”性保證,因為我們擔心MySQL在對過長的url連結操作時會有一些不盡如人意。
我不知道上面這一段能否讓你對之前我們處理Spider的做法有一個大概的瞭解,如果你還沒有太明白這是怎麼一回事。你可以訪問《網路爬蟲初步:從訪問網頁到資料解析》和《網路爬蟲初步:從一個入口連結開始不斷抓取頁面中的網址併入庫》這兩篇文章進行了解。
下面我就來說明一下,之前的做法存在的問題:
1.單執行緒:採用單執行緒的做法,可以說相當不科學,尤其是對付這樣一個大資料的問題。所以,我們需要採用多執行緒來處理問題,這裡會用到多執行緒中的執行緒池。
2.資料儲存方式:如果我們採用記憶體去儲存資料,這樣會有一個問題,因為資料量非常大,所以程式在執行的過種中必然會記憶體溢位。而事實也正是如此:

3.Url去重的方式:如果我們對Url進行MD5或是SHA1進行加密的方式進行雜湊的話,這樣會有一個效率的隱患。不過的確這個問題並不那麼複雜。對效率的影響也很小。不過,還好Java自身就已經對String型的資料有雜湊的函式可以直接呼叫:hashCode()
程式碼及說明:
LinkSpider.java
public class LinkSpider { private SpiderQueue queue = null; /** * 遍歷從某一節點開始的所有網路連結 * LinkSpider * @param startAddress * 開始的連結節點 */ public void ErgodicNetworkLink(String startAddress) { if (startAddress == null) { return; } SpiderBLL.insertEntry2DB(startAddress); List<WebInfoModel> modelList = new ArrayList<WebInfoModel>(); queue = SpiderBLL.getAddressQueue(startAddress, 0); if (queue.isQueueEmpty()) { System.out.println("Your address cannot get more address."); return; } ThreadPoolExecutor threadPool = getThreadPool(); int index = 0; boolean breakFlag = false; while (!breakFlag) { // 待訪問佇列為空時的處理 if (queue.isQueueEmpty()) { System.out.println("queue is null..."); modelList = DBBLL.getUnvisitedInfoModels(queue.MAX_SIZE); if (modelList == null || modelList.size() == 0) { breakFlag = true; } else { for (WebInfoModel webInfoModel : modelList) { queue.offer(webInfoModel); DBBLL.updateUnvisited(webInfoModel); } } } WebInfoModel model = queue.poll(); if (model == null) { continue; } // 判斷此網站是否已經訪問過 if (DBBLL.isWebInfoModelExist(model)) { // 如果已經被訪問,進入下一次迴圈 System.out.println("已存在此網站(" + model.getName() + ")"); continue; } poolQueueFull(threadPool); System.out.println("LEVEL: [" + model.getLevel() + "] NAME: " + model.getName()); SpiderRunner runner = new SpiderRunner(model.getAddress(), model.getLevel(), index++); threadPool.execute(runner); SystemBLL.cleanSystem(index); // 對已訪問的address進行入庫 DBBLL.insert(model); } threadPool.shutdown(); } /** * 建立一個執行緒池的物件 * LinkSpider * @return */ private ThreadPoolExecutor getThreadPool() { final int MAXIMUM_POOL_SIZE = 520; final int CORE_POOL_SIZE = 500; return new ThreadPoolExecutor(CORE_POOL_SIZE, MAXIMUM_POOL_SIZE, 3, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(MAXIMUM_POOL_SIZE), new ThreadPoolExecutor.DiscardOldestPolicy()); } /** * 執行緒池中的執行緒佇列已經滿了 * LinkSpider * @param threadPool * 執行緒池物件 */ private void poolQueueFull(ThreadPoolExecutor threadPool) { while (getQueueSize(threadPool.getQueue()) >= threadPool.getMaximumPoolSize()) { System.out.println("執行緒池佇列已滿,等3秒再新增任務"); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } } /** * 獲得執行緒池中的活動執行緒數 * LinkSpider * @param queue * 執行緒池中承載執行緒的佇列 * @return */ private synchronized int getQueueSize(Queue queue) { return queue.size(); } /** * 接收一個連結地址,並呼叫Python獲取該連結下的關聯的所有連結list * 將list入庫 */ class SpiderRunner implements Runnable { private String address; private SpiderQueue auxiliaryQueue; // 記錄訪問某一個網頁中解析出的網址 private int index; private int parentLevel; public SpiderRunner(String address, int parentLevel, int index) { this.index = index; this.address = address; this.parentLevel = parentLevel; } public void run() { auxiliaryQueue = SpiderBLL.getAddressQueue(address, parentLevel); System.out.println("[" + index + "]: " + address); DBBLL.insert2Unvisited(auxiliaryQueue, index); auxiliaryQueue = null; } } }
在上面的ErgodicNetworkLink方法程式碼中,大家可以看到我們已經把使用Queue儲存資料的方式改為使用資料庫儲存。這樣做的好處就是我們不用再為OOM而煩惱了。而且,上面的程式碼也使用了執行緒池。使用多執行緒來執行在呼叫Python獲得連結列表的操作。
而對於雜湊Url的做法,可以參考如下關鍵程式碼:
/**
* 新增單個model到等待訪問的資料庫中
* DBBLL
* @param model
*/
public static void insert2Unvisited(WebInfoModel model) {
if (model == null) {
return;
}
String sql = "INSERT INTO unvisited_site(name, address, hash_address, date, visited, level) VALUES('" + model.getName() + "', '" + model.getAddress() + "', " + model.getAddress().hashCode() + ", " + System.currentTimeMillis() + ", 0, " + model.getLevel() + ");";
DBServer db = null;
try {
db = new DBServer();
db.insert(sql);
db.close();
} catch (Exception e) {
System.out.println("your sql is: " + sql);
e.printStackTrace();
} finally {
db.close();
}
}PythonUtils.java
這個類是與Python進行互動操作的類。程式碼如下:
public class PythonUtils {
// Python檔案的所在路徑
private static final String PY_PATH = "/root/python/WebLinkSpider/html_parser.py";
/**
* 獲得傳遞給Python的執行引數
* PythonUtils
* @param address
* 網路連結
* @return
*/
private static String[] getShellArgs(String address) {
String[] shellParas = new String[3];
shellParas[0] = "python";
shellParas[1] = PY_PATH;
shellParas[2] = address.replace("\"", "\\\"");
return shellParas;
}
private static WebInfoModel parserWebInfoModel(String info, int parentLevel) {
if (BEEStringTools.isEmptyString(info)) {
return null;
}
String[] infos = info.split("\\$#\\$");
if (infos.length != 2) {
return null;
}
if (BEEStringTools.isEmptyString(infos[0].trim())) {
return null;
}
if (BEEStringTools.isEmptyString(infos[1].trim()) || infos[1].trim().equals("http://") || infos[1].trim().equals("https://")) {
return null;
}
WebInfoModel model = new WebInfoModel();
model.setName(infos[0].trim());
model.setAddress(infos[1]);
model.setLevel(parentLevel + 1);
return model;
}
/**
* 呼叫Python獲得某一連結下的所有合法連結
* PythonUtils
* @param shellParas
* 傳遞給Python的執行引數
* @return
*/
private static SpiderQueue getAddressQueueByPython(String[] shellParas, int parentLevel) {
if (shellParas == null) {
return null;
}
Runtime r = Runtime.getRuntime();
SpiderQueue queue = null;
try {
Process p = r.exec(shellParas);
BufferedReader bfr = new BufferedReader(new InputStreamReader(p.getInputStream()));
queue = new SpiderQueue();
String line = "";
WebInfoModel model = null;
while((line = bfr.readLine()) != null) {
// System.out.println("----------> from python: " + line);
if (BEEStringTools.isEmptyString(line.trim())) {
continue;
}
if (HttpBLL.isErrorStateCode(line)) {
break;
}
model = parserWebInfoModel(line, parentLevel);
if (model == null) {
continue;
}
queue.offer(model);
}
model = null;
line = null;
} catch (IOException e) {
e.printStackTrace();
} finally {
r = null;
}
return queue;
}
/**
* 呼叫Python獲得某一連結下的所有合法連結
* PythonUtils
* @param address
* 網路連結
* @return
*/
public static SpiderQueue getAddressQueueByPython(String address, int parentLevel) {
return getAddressQueueByPython(getShellArgs(address), parentLevel);
}
}遇到的問題:
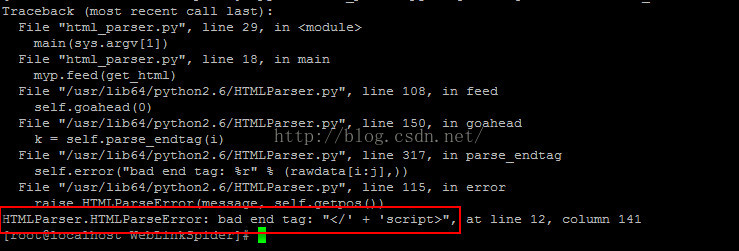
1.請使用Python2.7
因為Python2.6中HTMLParser還是有一些缺陷的,例如下圖中展示的。不過在Python2.7中,這個問題就不再是問題了。
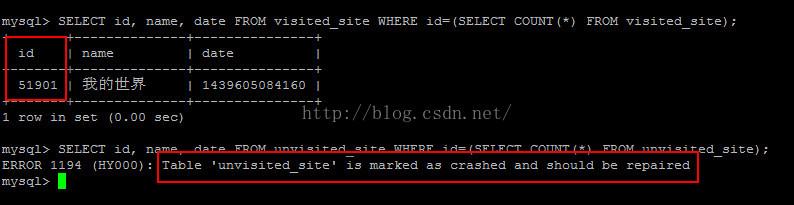
2.資料庫崩潰了
資料庫崩潰的原因可能是待訪問的資料表中的資料過大引起的。
3.對資料庫的同步操作
上面的做法是對資料庫操作進行同步時出現的問題,如果不進行同步,我們會得到資料庫連線數超過最大連線數的異常資訊。對於這個問題有望在下篇文章中進行解決。
不知道大家對上面的做法有沒有什麼疑問。當然,我希望你有一個疑問就是在於,我們去同步資料庫的操作。當我們開始進行同步的時候就已經說明我們此時的同步只是做了單執行緒的無用功。因為我開始以為對資料庫的操作是需要同步的,資料庫是一個共享資源,需要互斥訪問(如果你學習過“作業系統”,對這些概念應該不會陌生)。實際上還是單執行緒,解決的方法就是不要對資料庫的操作進行同步操作。而這些引發的資料庫連線數過大的問題,會在下篇文章中進行解決。
相關推薦
網路爬蟲:使用多執行緒爬取網頁連結
前言: 經過前面兩篇文章,你想大家應該已經知道網路爬蟲是怎麼一回事了。這篇文章會在之前做過的事情上做一些改進,以及說明之前的做法的不足之處。 思路分析: 1.邏輯結構圖 上圖中展示的就是我們網路爬蟲中的整個邏輯思路(呼叫Python解析URL,這裡只作了簡略
Python爬蟲教程:多執行緒爬取電子書
程式碼非常簡單,有咱們前面的教程做鋪墊,很少的程式碼就可以實現完整的功能了,最後把採集到的內容寫到 csv 檔案裡面,( csv 是啥,你百度一下就知道了) 這段程式碼是 IO密集操作 我們採用 aiohttp 模
Jsoup簡單例子2.0——多執行緒爬取網頁內的郵箱
上一篇文章講了利用Jsoup爬取貼吧帖子裡的郵箱,雖然爬取成功了,但我對效率有所追求。10頁的帖子爬取了兩百多個郵箱,最快用時8秒,一般需要9秒。在思考了一下怎麼提升效率後,決定採用多執行緒的方式爬取網頁內的郵箱。廢話不多說,直接上程式碼。 引入Jsoup的jar包此處省略,沒有的可以檢視上篇文
python多執行緒爬取網頁
#-*- encoding:utf8 -*- ''' Created on 2018年12月25日 @author: Administrator ''' from multiprocessing.dummy import Pool as pl import csv import requests fr
Python爬蟲教程:圖蟲網多執行緒爬取
我們這次也玩點以前沒寫過的,使用python中的queue,也就是佇列 下面是我從別人那順來的一些解釋,基本爬蟲初期也就用到這麼多 Python學習資料或者需要程式碼、視訊加Python學習群:960410445 1. 初始化: classQueue.Queue(maxsize)FIFO
【Python3爬蟲-爬圖片】多執行緒爬取中國國家地理全站美圖,多圖可以提高你的審美哦
宣告:爬蟲為學習使用,請各位同學務必不要對當放網站或i伺服器造成傷害。務必不要寫死迴圈。 - 思路:古鎮——古鎮列表(迴圈獲取古鎮詳情href)——xx古鎮詳情(獲取所有img的src) - 1. 單分類爬: from bs4 import BeautifulSo
使用threading,queue,fake_useragent,requests ,lxml,多執行緒爬取嗅事百科13頁文字資料,爬蟲案例
#author:huangtao # coding=utf-8 #多執行緒庫 from threading import Thread #佇列庫 from queue import Queue #請求庫 from fake_useragent import UserAgent
Python爬蟲入門教程 10-100 圖蟲網多執行緒爬取
寫在前面 經歷了一頓噼裡啪啦的操作之後,終於我把部落格寫到了第10篇,後面,慢慢的會涉及到更多的爬蟲模組,有人問scrapy 啥時候開始用,這個我預計要在30篇以後了吧,後面的套路依舊慢節奏的,所以莫著急了,100篇呢,預計4~5個月寫完,常見的反反爬後面也會寫的,還有fuck login類的內容。
Python爬蟲入門教程 13-100 鬥圖啦表情包多執行緒爬取
寫在前面 今天在CSDN部落格,發現好多人寫爬蟲都在爬取一個叫做鬥圖啦的網站,裡面很多表情包,然後瞅了瞅,各種實現方式都有,今天我給你實現一個多執行緒版本的。關鍵技術點 aiohttp ,你可以看一下我前面的文章,然後在學習一下。 網站就不分析了,無非就是找到規律,拼接URL,匹配關鍵點,然後爬取。 擼
Python爬蟲入門教程 14-100 All IT eBooks多執行緒爬取
寫在前面 對一個爬蟲愛好者來說,或多或少都有這麼一點點的收集癖 ~ 發現好的圖片,發現好的書籍,發現各種能存放在電腦上的東西,都喜歡把它批量的爬取下來。 然後放著,是的,就這麼放著.......然後慢慢的遺忘掉..... 爬蟲分析 開啟網址 http://www.allitebooks.c
Python爬蟲入門教程 10-100 圖蟲網多執行緒爬取!
寫在前面 經歷了一頓噼裡啪啦的操作之後,終於我把部落格寫到了第10篇,後面,慢慢的會涉及到更多的爬蟲模組,有人問 scrapy 啥時候開始用,這個我預計要在30篇以後了吧,後面的套路依舊慢節奏的,所以莫著急了,100篇呢,預計4~5個月寫完,常見的反反爬後面也會寫的,還有fuck login類的
Python 爬蟲多執行緒爬取美女圖片儲存到本地
Wanning 我們不是生產者,我們只是搬運工 資源來至於 ,程式碼基於Python 3.5.2 友情提醒:血氣方剛的騷年。請 謹慎 閱圖 !!! 謹慎 閱圖 !!! 謹慎 閱圖 !
python爬蟲進階使用多執行緒爬取小說
Python多執行緒,thread標準庫。都說Python的多執行緒是雞肋,推薦使用多程序。 Python為了安全考慮有一個GIL。每個CPU在同一時間只能執行一個執行緒 GIL的全稱是Global Interpreter
python簡單爬蟲 多執行緒爬取京東淘寶資訊教程
1,需要準備的工作,電腦已經安裝好python,如果沒裝,可以執行去https://www.python.org/官網下載,初學者可以安裝輕量級的wingide python開發工具,python安裝成功後配置好環境變數,在dos環境使用pip install 模組 將需要用
爬蟲記錄(4)——多執行緒爬取圖片並下載
還是繼續前幾篇文章的程式碼。 當我們需要爬取的圖片量級比較大的時候,就需要多執行緒爬取下載了。這裡我們用到forkjoin pool來處理併發。 1、DownloadTask下載任務類 package com.dyw.crawler.util;
spider----利用多執行緒爬取51job案例
程式碼如下 import json from threading import Thread from threading import Lock from queue import Queue import requests from bs4 import BeautifulSoup i
python:多執行緒抓取西刺和快站 高匿代理IP
一開始是打算去抓取一些資料,但是總是訪問次數多了之後被封IP,所以做了一個專門做了個工具用來抓取在西刺和快站的高匿IP。 執行環境的話是在python3.5下執行的,需要requests庫 在製作的過程中也參考的以下網上其他人的做法,但是發現很大一部分都不是多執行緒去抓取有點浪費時間了,又或者
使用python的requests、xpath和多執行緒爬取糗事百科的段子
程式碼主要使用的python中的requests模組、xpath功能和threading多執行緒爬取了糗事百科中段子的內容、圖片和閱讀數、段子作者的性別,年齡和頭像。 # author: aspiring import requests from lxml import
Python3網路爬蟲:requests+mongodb+wordcloud 爬取豆瓣影評並生成詞雲
Python版本: python3.+ 執行環境: Mac OS IDE: pycharm 一 前言 二 豆瓣網影評爬取 網頁分析 程式碼編寫 三 資料庫實裝 四
Python3網路爬蟲:使用Beautiful Soup爬取小說
本文是http://blog.csdn.net/c406495762/article/details/71158264的學習筆記 作者:Jack-Cui 博主連結:http://blog.csdn.net/c406495762 執行平臺: OSX Python版本: Pyth