
HBase(2.1)-HBase介紹
1. HBase介紹
1.1 HBase簡介
Hbase是一個非關係型的、持久的、分散式的、強一致性的儲存結構、面向列的開源資料庫,是一個適合於非結構化資料儲存的資料庫。
Hbase是Hadoop生態系統的一部分,Hbase資料最終是儲存到HDFS檔案系統當中;
Hbase是基於列儲存的資料庫,具有負載均衡和故障恢復功能,同時可以自動擴充套件,具有高效的讀寫功能。
(1)對於定義當中的幾個名詞的解釋:
非關係型的:儲存的資料格式是非結構化的資料
持久的:資料是存放到磁碟(Hbase是儲存在基於HDFS檔案系統的檔案裡面),而不是存於記憶體分散式的:主要是關係型資料庫做對比,不是僅有一個伺服器,資料儲存的方式是分散式的,資料是分佈在多臺伺服器;
強一致性:
一致性查到的概念如下:保證資料庫客戶端操作的正確性,資料庫必須保持每一步操作都是從一個一致的狀態到下一個一致的狀態。
一致性又分為很多級別,強一致性的概念是資料的變化是原子的,一經改變立即生效。
我的理解是放到高併發的場景,資料的狀態的固定的,根據高併發的採取的措施的不同有不同的效果,而出現了不同級別的一致性特徵。
列式儲存:
列式儲存是以列為單位聚合資料,然後將列值順序地存入磁碟;與此相對應的是行式儲存,行式儲存我們腦海當中有一定的印象,列式儲存可以形象的理解為矩陣轉置。
列式儲存自帶的優勢: 1.方便壓縮 2.減少I/O
無模式:每行都有一個可排序的主鍵和任意多的列,列可以根據需要動態的增加,同一張表中不同的行可以有截然不同的列;
面向列:面向列(族)的儲存和許可權控制,列(族)獨立檢索;
稀疏:空(null)列並不佔用儲存空間,表可以設計的非常稀疏;
資料多版本:每個單元中的資料可以有多個版本,預設情況下,版本號自動分配,版本號就是單元格插入時的時間戳。
資料型別單一:HBase中的資料都是字串,沒有型別。
1.2 HBase相關名詞解釋
Hbase位於結構化儲存層,Hadoop HDFS為hbase提供了高可靠性的底層儲存支援,hadoop MapReduce為HBase提供了高效能的計算能力,Zookeeper為HBase提供了穩定服務和failover機制。
1)行鍵(RowKey)
– 行鍵是位元組陣列, 任何字串都可以作為行鍵(”主鍵”);
– 表中的行根據行鍵進行排序,資料按照Row key的位元組序(byte order)排序儲存;
– 所有對錶的訪問都要通過行鍵 (單個RowKey訪問,或RowKey範圍訪問,或全表掃描) (二級索引)
2)列族(ColumnFamily)
– CF必須在表定義時給出
– 每個CF可以有一個或多個列成員(ColumnQualifier),列成員不需要在表定義時給出,新的列族成員可以隨後按需、動態加入
– 資料按CF分開儲存,HBase所謂的列式儲存就是根據CF分開儲存(每個CF對應一個Store),這種設計非常適合於資料分析的情形
3)時間戳(TimeStamp)
– 每個Cell可能又多個版本,它們之間用時間戳區分
4)單元格(Cell)
– Cell 由行鍵,列族:限定符,時間戳唯一決定,資料全部以位元組碼形式儲存
5)區域(Region)
– HBase自動把表水平(按Row)劃分成多個區域(region),每個region會儲存一個表裡面某段連續的資料;
– 每個表一開始只有一個region,隨著資料不斷插入表,region不斷增大,當增大到一個閥值的時候,region就會等分會兩個新的region;
– 當table中的行不斷增多,就會有越來越多的region。這樣一張完整的表被儲存在多個Region 上。
– HRegion是HBase中分散式儲存和負載均衡的最小單元(預設256M)。最小單元表示不同的HRegion可以分佈在不同的HRegionServer上。但一個HRegion不會拆分到多個server上。
1.3 HBase在Hadoop生態圈中的作用
Hbase在Hadoop生態系統當中結構圖如下:
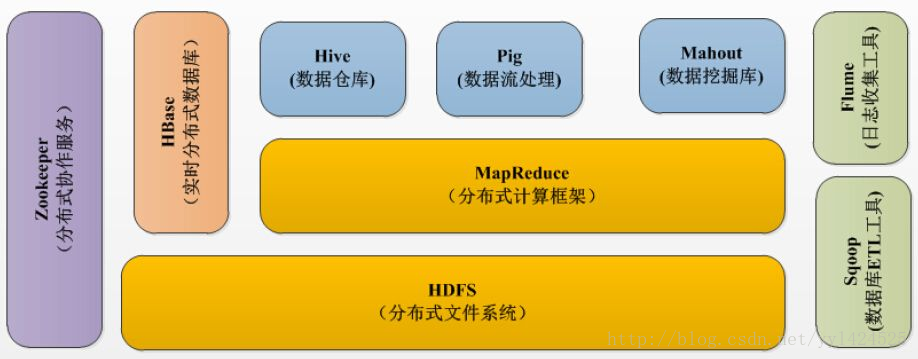
1) HDFS為Hbase 提供了檔案儲存支援,Hbase最終的資料是儲存在HDFS檔案系統當中;
2) HBase是Hadoop 資料庫,儲存了海量資料;
3) MapReduce 提供分析、處理資料的能力;
4) Zookeeper 提供了對穩定的服務和failover機制(對Hbase來說主要是為Master伺服器管理Region)
5) Sqoop可以將關係型資料庫匯入到Hbase裡面
6) Hbaes底層是用Java語言實現,Pig和Hive可以提供其他語言的支援,是操作資料更加的方便。
相關推薦
HBase(2.1)-HBase介紹
1. HBase介紹 1.1 HBase簡介 Hbase是一個非關係型的、持久的、分散式的、強一致性的儲存結構、面向列的開源資料庫,是一個適合於非結構化資料儲存的資料庫。 Hbase是Hadoop生態系統的一部分,Hbase資料最終是儲存到HDFS檔案系統
hbase-2.1.0 原始碼閱讀
1.Hmaster啟動 用了這麼久的hbase,今天開始著手hbase方面的原始碼閱讀 2.1.0版本剛釋出不久,是Hbase 2.x系列的第二次版本。旨在提高 HBase 的穩定性和可靠性,主要更新內容如下: 基於 Procedure v2 的複製對等修改 串
hbase-2.1.0 程式設計 , 缺少 hadoop-auth-2.7.4.jar ?
問題: maven倉庫映象設定為 <mirror> <id>alimaven</id> <mirrorOf>central</mirrorOf> <name>
hive-2.1.1整合hbase-2.1.0
一、環境準備 1、軟體版本 hadoop-2.7.4 hbase-2.1.0 hive-2.1.1 2、hbase與hive的版本相容 hive0.90 與 hbase0.92是相容的,早期的hive版本與hbase0.89/0.90相容 hive1.x 與 hb
十、CentOS7安裝HBase-2.1.0偽分散式
背景:2.1.0版本是當前官網的最新版本,首先確認的是其對Java和Hadoop的支援版本 一、解壓壓縮包 tar -zxvf hbase-2.1.0-bin.tar.gz -C hbase/
redis3.2.1叢集介紹及在Linux作業系統上安裝
一、redis叢集介紹點選開啟連結 Redis3.0版本之後支援Cluster. 二、redis叢集安裝 準備工作: 1. 安裝兩臺虛擬機器,模擬6個節點,一臺機器3個節點,創建出3 master、3 salve 環境。 &nbs
HBase(2):hbase物理模型結構
一.物理結構圖 二.關鍵概念 1.儲存單元Cell (1)儲存單元cell:rowkey+列簇+timestamp+version,確定一個單元格的值 (2)資料無型別,以位元組碼的形式進行儲存 2.Region (1)列分割:table中所有的行都是按照字典序
【HBase-2】HBase的原理和架構
一、邏輯儲存模型 HBase以表的形式儲存資料,表由行和列組成。列劃分為若干個列族, RowKey:Hbase使用Rowkey來唯一的區分某一行的資料。如圖中"rk001" &nb
spark(2.1.0) 操作hbase(1.0.2)
hadoop mon per bsp trac 事先 com maker scala 1、spark中引入外部jar包 1)創建/usr/software/spark_jars目錄,放入spark操作hbase的jar包:hbase-annotations-1.0.2.
hive1.2.1整合hbase遇到的坑
通常我們會整合hive與hbase,通過建立hive外部表,進行一些增刪改查hbase表,hive1.2.1整合hbase1.2.6,遇到了一些坑,通過修改了幾行hive原始碼,重新編譯hive-hbase-handler-1.2.1.jar包替換hive lib目錄下原本那個hive-
使用Hbase協作器(Coprocessor)同步資料到ElasticSearch(hbase 版本 1.2.0-cdh5.8.0, es 2.4.0 版本)
參考 https://gitee.com/eminem89/Hbase-Observer-ElasticSearch 上面的程式碼,但是由於我的es版本是2.4.0 和作者的版本不對應導致功能無法正常使用,所以特此記錄修改成能參考 程式碼如
HBase叢集的搭建(版本:2.1.0)
(004)HBase是一個在HDFS上開發的面向列的分散式資料庫。如果需要實時地隨機訪問超大規模資料集,就可以使用HBase這一Hadoop應用了 HBase叢集的搭建 前提條件 Hadoop叢集 ZooKeeper叢集 JDK 原料 h
從hbase表1中讀取資料,最終結果寫入到hbase表2 ,如何通過MapReduce實現 ?
需要一: 將hbase中‘student’表中的info:name和info:age兩列資料取出並寫入到hbase中‘user’表中的basic:XM和basic:NL class ReadStudentMapper extends Table
Apache Phoenix 4.8.1 + HBase 1.2.3 整合
步驟如下: 1. 下載Phoenix 4.8.1: 2. 解壓後,配置環境變數。 3. 拷貝根目錄下phoenix-4.8.1-HBase-1.2-server.jar檔案到$HBASE_HOME/lib目錄下,然後重啟hbase 4. 執行如下命令: sqlline.p
phoenix-4.8.1-HBase-1.2安裝(詳細圖文)
這次安裝 Phoenix,前提是我們的 hadoop 叢集,zookeeper,hbase 都安裝成功。 準備工作 先是到官網上把安裝包下載下來 具體怎麼操作相信大家肯定都有經驗了,就不介紹那麼詳細了,看著圖片肯定都會。 然後將下載好的安
使用HBase Indexer建立二級索引(整合最新版本的HBase1.2.6及Solr 7.2.1)
這段時間整合HBase,需要為HBase建立二級索引,方便資料的查詢使用,Solr權威指南上面有Hbase與Solr的整合章節,照著書上以及網上的說明折騰了很近才配置成功,HBase Indexer已經有1年多沒有更新了,整合最新的HBase1.2.6,solr7.2.1有
hadoop2.7.2叢集hive-1.2.1整合hbase-1.2.1
本文操作基於官方文件說明,以及其他相關資料,若有錯誤,希望大家指正 根據hive官方說明整合hbase連結如下https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration 文中指出hive0.9.0匹配的
大資料研發(2Hbase)2.1:hbase和傳統資料庫的區別
1.hbase①hbase是一個面向列儲存的分散式儲存系統,可以實現高效能的併發讀寫操作,對資料進行透明的切分。②hbase有兩個主要概念,row key(行健),column family(列簇)。每個列簇包含多個列。row key 是hbase中記錄的唯一標識。③hbas
Hadoop-1.2.1安裝HBase(偽分佈模式)
我是在hadoop1.2.1版本的基礎上安裝0.98.6版本的hbase。 安裝步驟前面和安裝HBase單機模式是一樣的 (可參考我的另一篇文章: http://blog.csdn.net/zhangxbj/article/details/
HBase之二【HBase基礎】hbase介紹(2)
一、簡介 history started by chad walters and jim 2006.11 G release paper on BigTable 2007.2 inital HBase prototype created as Hadoop cont