
jQuery1.11原始碼分析(1)-----Sizzle原始碼概覽[原創]
最近在啃jQuery1.11原始碼,上來就遇到Sizzle這個jQuery的大核心,雖然已經清楚了Sizzle的用途,先繞過去也沒事,但明知山有虎偏向虎山行才是我們要做的。
本文面向的閱讀物件:正在學習Sizzle原始碼或有一定前端基礎的同學們,可以一邊看原始碼一邊看這些文章進行驗證,所以雖然我會分析原始碼中的正則表示式,有大量的註釋,但不會講正則表示式的基本用法!(我會給出一些連結,但不一定全面,請鍛鍊自主搜尋的能力;為了避免歧義,本文的一些詞會採用原始碼中的英文或js中的屬性名)
Sizzle部分的程式碼已經啃完,本系列還有後續,這幾天將會一一放出。本文主要分為兩個部分:什麼是Sizzle
什麼是Sizzle?
簡單地來說,Sizzle是一個可以讓你用CSS 選擇器(selector)形式去獲取DOM元素的引擎。
當我們想了解一個函式的用途和原始碼,必須先看它的要求和效果,就是輸入和輸出。
例如:你提供一個CSS selector 'html > body',Sizzle會返回給你一個數組,陣列中只有一個元素body元素。
還有更復雜的CSS selector,比如 ‘body > div#main div.content input[type="text"]:nth(2)’,更多selector的用法請看
Sizzle的原理
我們先想想,如果讓我們自己寫一個Sizzle,先不考慮其中遇到的設計和細節問題,你會怎麼做?
一個很自然的想法是,從父元素順藤摸瓜往下一層層找下去。比如‘html > body’,我先找到nodeName為html的元素,再檢視html的子元素裡有沒有一個nodeName為body的元素即可。
那麼會面對幾個問題:
你怎麼知道在哪兒找html元素?於是我們需要一個查詢上下文(context),預設為文件節點(document)
你怎麼知道要找的是html元素而非h元素或者ht元素?所以我們需要一個詞法分析器(tokenize),把selector切成三個詞元(token)(一個數組(tokens)),[‘html’,'>','body']。(關於詞法分析器,請學習編譯原理相關知識)
難道處理‘html’和處理‘>’的方式是一樣的?你怎麼知道它要查詢子元素?我們知道它們是不同的型別的詞元(token),所以要記錄詞元的型別,上面的陣列變為[{value:'html',type:'TAG'},{value:'>',type:'>'},{value:'body',type:'TAG'}],再交給對應的處理函式處理
難道每次我們都來上面這麼一套麼?我們經常用的不就是$('#id')或者$('.className')這樣簡單的用法麼?所以我們可以把這種高頻率的特殊情況拿出來先處理,處理不掉再用統一的方法處理。
上面這一套,從左往右匹配,從邏輯上來看是沒什麼問題的。那麼思考下面這種情況:
‘因為DOM是一種樹形結構,所以越往下層,子節點是越多的,那麼會有這樣一種情況,body元素下有10000個div子元素,其中在5000的位置處有一個div的id為suprise。’這時給你一個內容為body > div#suprise的selector,你寫的引擎會怎麼處理?
繼續用上面的方法,先找出body元素,然後一個個遍歷body的子元素?
可以預見的是效能上的悲劇。。。
所以我們的Sizzle採用的是從右向左的匹配方式:
先呼叫getElementById('suprise')來獲得該DOM元素(find過程)(因為瀏覽器低層目測會建立id的索引,所以獲得非常快,即使需要遍歷DOM樹,也比我們自己遍歷DOM樹快),
再根據'>'判斷其父元素是否是body元素(filter過程)即可。
OK,到這裡為止效能方面有了一定的改進,再考慮一種情況:
'當我們需要查詢的層次很深時,比如selector為body > div#main div.content input[type="text"]時,我們需要先找到待選(seed)的input,再依次過濾[type="text"]、div.content 、div#main 、body>,你們會怎麼做?'
判斷不同的token型別,再通過查詢找到對應的過濾函式,並呼叫對應的過濾函式(filter),這是一個正常的想法。
那麼我需要再用該selector來查詢一次呢?(這是使用jQuery非常常見的場景)把上面的過濾過程再重複一遍?
於是另一種提升效能的方式出現了——快取,把上面的多個過濾函式編譯成一個匹配函式(matcher),然後以key-value的形式存在快取裡面,當我們再次查詢同樣的selector時,只需要把編譯好的匹配函式(matcher)給取出來過濾用就可以了。
Sizzle的全部原理大致如上,至於特性檢測、沙盒、bugfix這些細節,後面再說
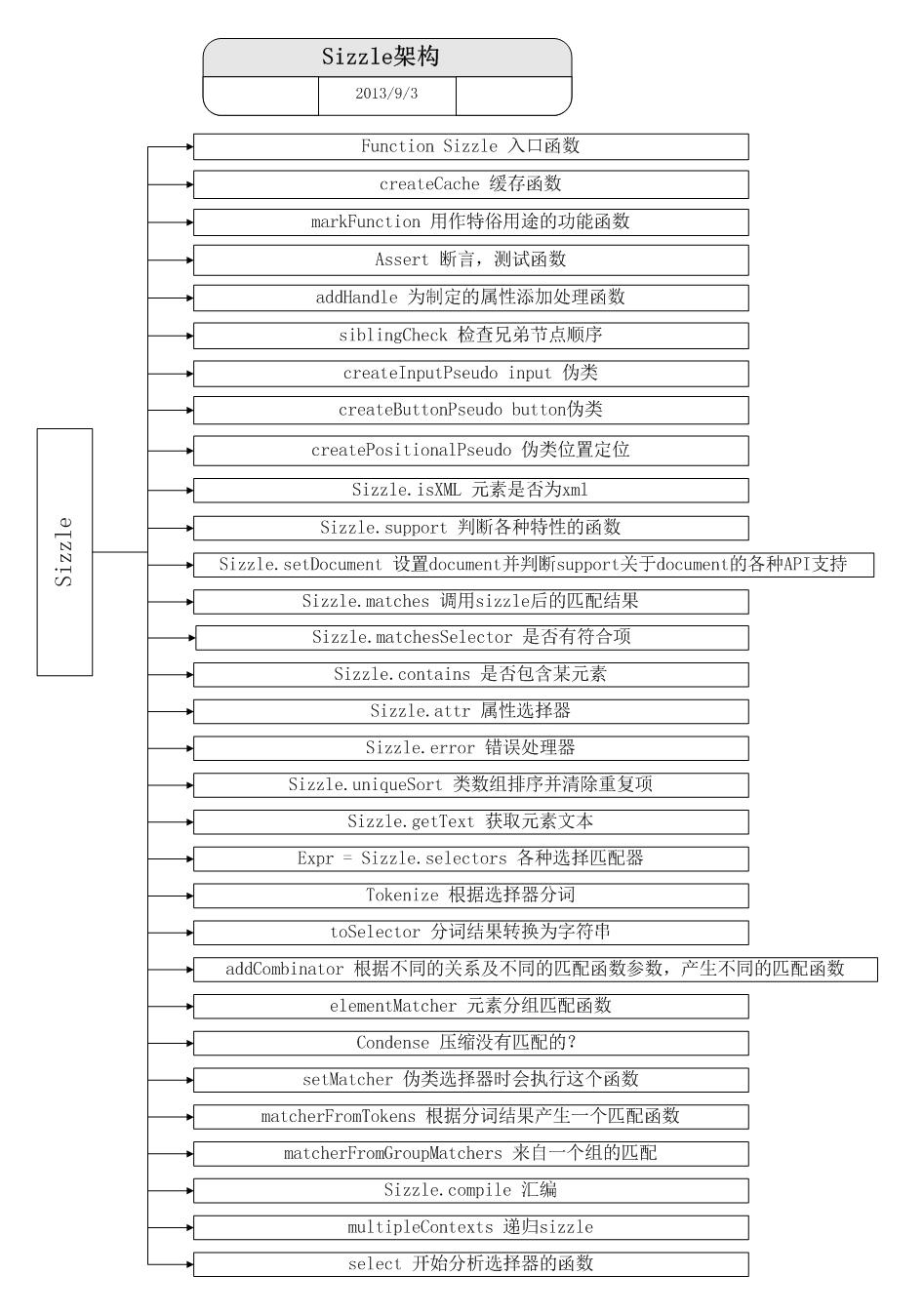
Sizzle的結構概覽
Sizzle的結構不用記,大致看看就好,後面會一一說到的,放一張圖,來源:http://www.cnblogs.com/mufc-go/p/3299261.html
本文完。
剩下的下午健完身回來再發。
感謝@司徒正美(1.3版本原始碼分析),@nuysoft(1.7版本原始碼分析),@Aaron(2.03版本原始碼分析)給我的參考。
如果你喜歡這篇文章,請給我一個推薦,如果覺得有問題,請在評論裡抽打我!
相關推薦
jQuery1.11原始碼分析(1)-----Sizzle原始碼概覽[原創]
最近在啃jQuery1.11原始碼,上來就遇到Sizzle這個jQuery的大核心,雖然已經清楚了Sizzle的用途,先繞過去也沒事,但明知山有虎偏向虎山行才是我們要做的。 本文面向的閱讀物件:正在學習Sizzle原始碼或有一定前端基礎的同學們,可以一邊看原始碼一邊看這些文章進行驗證,所以雖然我會分析原始碼
Netty Pipeline原始碼分析(1)
原文連結:wangwei.one/posts/netty… 前面,我們分析了Netty EventLoop的 建立 與 啟動 原理,接下里我們來分析Netty中另外兩個重要元件—— ChannelHandler 與 Pipeline。Netty中I/O事件的傳播機制均由它負責,下面我們來看看它是如
vue原始碼分析1-new Vue做了哪些操作
首先我們可以看到vue的原始碼在github上有,大家可以克隆下來。 git地址 我們主要看src下的內容。 1.現在我們來分析下 new Vue都做了哪些操作 var app = new Vue({ el: '#app', mounted:{ console.log(t
redis原始碼分析1------dict的實現
1. 總體結構 redis的dict就是hash表,使用鏈式結構來解決key值衝突,典型的資料結構 結構體的定義如下: typedef struct dictEntry { void *key; union { void *val; uint64_t
Netty原始碼分析:1.4伺服器啟動流程
第一章節是主要是伺服器啟動的程式碼分析。章節目錄有: |———1.1初始化NioEventLoopGroup |———1.2初始化NioEventLoop |———1.3初始化NioServerSocketChannel |———1.4伺服器啟動流程 為什麼先從初始化開
Netty原始碼分析:1.3初始化NioServerSocketChannel
第一章節是主要是伺服器啟動的程式碼分析。章節目錄有: |———1.1初始化NioEventLoopGroup |———1.2初始化NioEventLoop |———1.3初始化NioServerSocketChannel |———1.4伺服器啟動流程 為什麼先從初始化開
Netty原始碼分析:1.2初始化NioEventLoop
第一章節是主要是伺服器啟動的程式碼分析。章節目錄有: |———1.1初始化NioEventLoopGroup |———1.2初始化NioEventLoop |———1.3初始化NioServerSocketChannel |———1.4伺服器啟動流程 為什麼先從初始化開
Netty原始碼分析:1.1初始化NioEventLoopGroup
第一章節是主要是伺服器啟動的程式碼分析。章節目錄有: |———1.1初始化NioEventLoopGroup |———1.2初始化NioEventLoop |———1.3初始化NioServerSocketChannel |———1.4伺服器啟動流程 為什麼先從初始化開
《2.uboot和系統移植-第5部分-2.5.uboot原始碼分析1-啟動第一階段》
《2.uboot和系統移植-第5部分-2.5.uboot原始碼分析1-啟動第一階段》 第一部分、章節目錄 2.5.1.start.S引入 2.5.2.start.S解析1 2.5.3.start.S解析2 2.5.4.start.S解析3 2.5.5.start.S解析4 2.5.6.s
MyBatis原始碼分析-1-基礎支援層-反射模組-Reflector/ReflectorFactory
本文主要介紹MyBatis的反射模組是如何實現的。 MyBatis 反射的核心類Reflector,下面我先說明它的建構函式和成員變數。具體方法下面詳解。 org.apache.ibatis.reflection.Reflector public class Reflector {
rxjs 原始碼分析1-(fromEvent)
前言 Rxjs是使用 Observables 的響應式程式設計的庫,它使編寫非同步或基於回撥的程式碼更容易。我們現在針對Rxjs 6 來進行原始碼分析,分析其實現的基本原理, 我們可以根據中文文件來學習Rxjs 的基本使用,但是這個文件是Rxjs 5 的版本。其最基本的使用區別如下,Rxjs 6的操作符都放
谷歌瀏覽器的原始碼分析 1
隨著網路技術的發展,越來越多應用都已經離不開網路,特別像人類大腦一樣的知識庫的搜尋引擎,更加是離不開功能強大的雲端計算。不過,即便雲端計算非常強大,但它還不能直接地把結果呈現給使用者,這樣就需要一個客戶端來呈現出來,這個客戶端就是瀏覽器。現在越來越多人上網,他們每一次上網,都離不開瀏覽的使用,這已經是一
Shiro原始碼分析(1)
簡介 SecurityManager:安全管理器,Shiro最核心元件。Shiro通過SecurityManager來管理內部元件例項,並通過它來提供安全管理的各種服務。 Authenticator:認證器,認證AuthenticationToken是否有
3.21以太貓原始碼分析1
概述: Cryptokitties,眾所周知的迷戀貓的遊戲,是基於以太坊平臺執行的。使用者在遊戲中可以養大、買賣並繁育“電子寵物”小貓,每隻小貓和繁衍的後代都是獨一無二的。由於它是第一款真正意義上的區塊
以太坊原始碼分析(1)go-ethereum的設計思路及模組組織形式
# go-ethereum原始碼解析因為go ethereum是最被廣泛使用的以太坊客戶端, 所以後續的原始碼分析都從github上面的這份程式碼進行分析。 然後我使用的是windows 10 64位的環境。### 搭建go ethereum除錯環境首先下載go安裝包進行安裝,因為GO的網站被牆,所以從下面
[9]【ffmpeg原始碼分析 1】av_register_all()和avcodec_register_all()
日期:2016.10.18 作者:isshe github:github.com/isshe 郵箱:[email protected] 前言 接下來打
SpringMVC原始碼分析1:SpringMVC概述
轉載自:https://blog.csdn.net/a724888/article/details/76014532 Web MVC簡介 1.1、Web開發中的請求-響應模型: 在Web世界裡,具體步驟如下: 1、 Web瀏覽器(如IE)發起請求,如訪問http:/
Leveldb資料Compaction原始碼分析(1)
Leveldb資料Compaction原始碼分析(1) 這一節來講Leveldb的資料壓縮過程,上一節講了Leveldb的資料尋找過程,文章地址為:但是最後在講Leveldb中的Leveln的層級尋找時,我想應該是有沒有看懂的,直接二分法找到sstable,然後載入快取就能找到檔案,
Egg 學習筆記-原始碼分析1
1. Egg在呼叫controller/service資料夾下的模組時,不需要require,如何實現的? 在原生Node/Koa中,當我們需要呼叫其他模組時,需要require, 非常繁瑣。(java體系都是auto import) 但在Egg中,我們可以
coreutils4.5.1 uniq.c原始碼分析1
uniq.c這個檔案其實沒讀懂,不過從程式中發現了幾個支點,下次再細細品。 第一。交換兩行的寫法。 #define SWAP_LINES(A, B) \ do