
Redux進階(一)
State的不可變化帶來的麻煩
在用Redux處理深度複雜的資料時會有一些麻煩。由於js的特性,我們知道當對一個物件進行復制時實際上是複製它的引用,除非你對這個物件進行深度複製。Redux要求你每次你返回的都是一個全新的State,而不是去修改它。這就要求我們要對原來的State進行深度複製。這往往帶來複雜的操作(查詢,合併)。一種簡單的情況是通過擴充套件符號或者Object.assign來處理:
return {
...state,
data: {
...state.data,
id: 5
}
}
這種方式在處理簡單的資料來說是比較方便的,但是如果遇到更深一級的資料結構時會顯得很無力,而且程式碼會變得冗長。不僅僅如此,當我們要處理一個包含著物件的陣列時,我們要怎麼辦才好呢?我想,除了深度複製陣列然後修改新的陣列之外大概沒有其他的方法了吧?而且很重要的一點是,如果你對原來整個陣列進行了複製,那麼綁定了資料的UI會自動渲染,即使它們的資料沒有發生變化,簡單來說,就是你修改了某一條表格資料,但是介面上整個表格被重新渲染了:
const TablesSource = {
query: 'tables',
tableId: 10,
data: [{
key: 11,
name: '胡彥斌',
age: 32,//我要修改這裡,要複製整個陣列後修改新的嗎?
address: '西湖區湖底公園1號'
}, {
key: 12,
name: '胡彥祖',
age: 42,
address: '西湖區湖底公園1號'
}]
};
在Redux官方文件中提到了一種解決方案,即正規化化資料:概括起來就一句話:減少層級,唯一id索引,用後端建表的方法構建我們的資料結構。其中最重要原則無非是扁平化和關聯性。最終我們需要將資料形式轉化成以下格式:
{
"entities": {
"bykey": {
"11": {
"key": 11,
"name": "胡彥斌",
"age": 32,
"address": "西湖區湖底公園1號"
},
"12": {
"key": 12,
"name": "胡彥祖",
"age": 42,
"address": "西湖區湖底公園1號"
}
},
"table": {
"10": {
"query": "tables",
"tableId": 10,
"data": [
11,
12
]
}
}
},
"result": 10
}
按照滷煮的理解,正規化化資料無非就是給物件瘦瘦身,再深的層級,我們也儘量將它們扁平化,這樣會減少我們對State的查詢帶來的效能消耗。然後是建立索引表,標識每組資料之間的聯絡。那麼怎麼樣才能得到我們想要的資料呢?
normalizr方法使用指南
官方最薦normalizr模組,它的用法還是需要時間的去研究的。下面我們就以上面的資料為示例,說明它的用法:
$ npm i normalizr -S //下載模組
.........
import {normalize, schema} from 'normalizr';//日常匯入,沒問題
//原始資料
const TablesSource = {
query: 'tables',
tableId: 10,
data: [{
key: 11,
name: '胡彥斌',
age: 32,
address: '西湖區湖底公園1號'
}, {
key: 12,
name: '胡彥祖',
age: 42,
address: '西湖區湖底公園1號'
}]
};
//建立實體,名稱為bykey,我們看到它的第二個引數是undefined,說明它是最後一層級的物件
const bykey = new schema.Entity('bykey', undefined, {
idAttribute: 'key'
});
//建立實體,名字為table,索引是tableid。
const table = new schema.Entity('table', {
data: [bykey] //這裡需要說明這些實體的關係,意思是bykey原來table下面的是一個數組,他對應的是data資料,bykey將會取這裡的資料建立一個以key為索引的物件。
}, {
idAttribute: 'tableId'//以tableId為為索引
});
const normalizedData = normalize(TablesSource, table);//生成新資料結構
說明:new schema.Entity的第一個引數表示你建立的最外層的實體名稱,第二個引數是它和其他新建立的實體的關係,預設是最小的層級,即它只是最後一層,不包含其他層級了。第三個引數裡面有個idAttribute,指的是以哪個欄位為索引,預設是"id",它也可以是個引數,返回你自己構造的唯一值,記住,是唯一值。按照這樣的套路,你可以隨意構建你想要的扁平化資料結構,無論源資料的層級有多深。我們最終都會得到希望的資料結構。
{
"entities": {
"bykey": {、、實體名稱
"11": {//我們之前設定的唯一所用key
"key": 11,
"name": "胡彥斌",
"age": 32,
"address": "西湖區湖底公園1號"
},
"12": {
"key": 12,
"name": "胡彥祖",
"age": 42,
"address": "西湖區湖底公園1號"
}
},
"table": {//實體名
"10": {、、唯一所用tableid
"query": "tables",
"tableId": 10,
"data": [ //data變成了儲存key值索引的集合了!因為在之前我們說明了兩個實體之間的關係 data: [bykey]
11,
12
]
}
}
},
"result": 10//這裡同樣儲存著table實體裡面的索引集合 normalizr(TableSource, table)
}
github上有詳細的官方文件可供查詢,滷煮在此只是簡單的說明一下用法,諸位可以仔細觀察文件上的用法,不需要多少時間就可以熟練掌握。到此為止,萬里長城,終於走完了第一步。
如何將正規化化資料後再次轉化
什麼?好不容易轉化成自己想要的資料結構,還需要再次轉化嗎?很遺憾告訴你,是的。因為正規化化後的資料只便於我們在維護Redux,而介面業務渲染的資料結構往往跟我們處理後的資料是不一樣的,舉個栗子:bootstrap或者ant.design的表格渲染資料結構是這個樣的:
const dataSource = [{
key: '1',
name: '胡彥斌',
age: 32,
address: '西湖區湖底公園1號'
}, {
key: '2',
name: '胡彥祖',
age: 42,
address: '西湖區湖底公園1號'
}];
因而在介面引用State上的資料時,我們需要一箇中介,把正規化化的資料再次轉化成業務資料結構。我相信這個步驟十分簡單,只需要寫一個簡單的轉換器就行了:
const transform = (source) => {
const data = source.entities.bykey;
return Object.keys(data).map(v => data[v]);
};
const mapStateToProps = (state,ownProps) => ({table: transform(state)})
export default connect(mapStateToProps)(view)
如果你在mapStateToProps裡面斷點除錯,你會發現每一次dispatch都會強行執行mapStateProps方法保證物件的最新狀態(除非你引用的是基礎型別資料),因此,不管介面的操作是如何,被connect資料都會被強行執行一次,雖然介面沒有變化,但是顯然,js的效能會有折扣,尤其是對深度物件的複雜處理。因此,官方推薦我們建立可記憶的函式高效計算Redux Store裡面的衍生資料。
Reselect方法使用指南
//快取data裡面的索引
const reNormalDataSource = (state, props) => state.app.entities.table['10'].data;
//快取bykey裡面對得基礎資料
const reNormal = (state, props) => state.app.entities.bykey;
// 快取計算結果
const createNormalTableData = createSelector([reNormalDataSource, reNormal], (keys, source) => keys.map(item => source[item]));
//每次當mapStateToProps重新執行時,會儲存上次計算的結果,它只會重新計算變化的資料,其他非相關變化不做計算
const mapStateToProps = (state, own) => ({source: createNormalTableData(state)});
我在這裡做了個耍了點花樣,你可以看到,我是按照table.data這個陣列來查詢介面業務資料的。這種操作可以使得我們只需要關心table.data這個簡單的一維陣列,在刪除或者新增一條資料的時候顯得尤為有用。
我們最後為了計算state,引用了dot-prop-immutable模組,他是immutable的擴充套件,對於資料計算非常高效。我接著使用了另外一個dot-prop-immutable-chain模組,它增加了dot-prop-immutable的鏈式用法。關於dot-prop-immutable的用法滷煮不再詳細說明,在後面給出的例子中一眼就能看明白,而且官方文件上也有詳細說明。下面我們通過一個表格增刪查改來實際展示我們這次的解決方案。
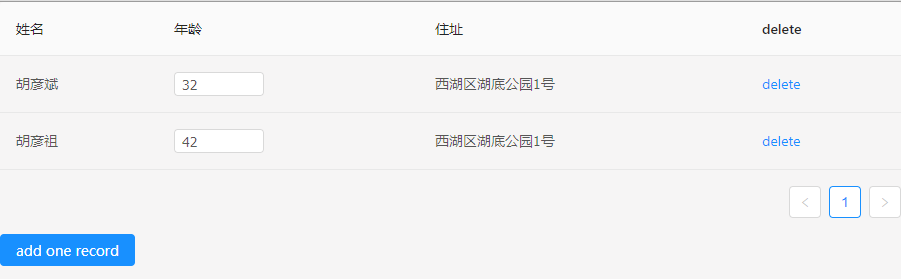
import {normalize, schema} from 'normalizr';
import dotProp from 'dot-prop-immutable-chain';
const reducer = (state = normalizedData, action) => {
switch(action.type) {
//修改一條資料
case 'EDITOR':
return dotProp(state).set(`entities.bykey.${action.key}.age`, action.age).value();
//新增一條資料
case 'ADD':
const newId = UID++;
return dotProp(state).set(`entities.bykey.${newId}`, Object.assign({}, model, {key: newId}))//新增一條新資料
.merge(`entities.table.10.data`, [newId]).value();//新資料的data中的引用
//刪除一條資料
case 'DELETE':
const index = state.entities.table['10'].data.indexOf(Number(action.key));
//可以看到,由於我們介面資料是根據data裡面的項來決定的,因此我們只需要處理data這個簡單的一維陣列,而這顯然要容易維護得多
return dotProp(state).delete(`entities.table.10.data.${index}`).value();
}
return state;
};
瞧,我們展示了整個reducer,相信它已經變得容易維護得多了,並且由於使用了正規化化資料結構以及immutable的擴充套件模組,不僅僅提升了計算效能,減少介面的的渲染,而且還符合Redux的State不可修改的原則。
結束語
React+Redux組合在實際應用過程中需要優化的地方還很多,這裡只是簡單展示其中的一個小點。雖然在計算dom介面變化時React已經做得足夠好,但並不意味著我們可以不用為介面渲染問題背鍋,React肩負了多數介面更新計算的任務,而讓前端開發人員更多地去處理資料,因此,我們可以在這裡層多花點時間把專案做好。
參考資料
相關推薦
Redux進階(一)
State的不可變化帶來的麻煩 在用Redux處理深度複雜的資料時會有一些麻煩。由於js的特性,我們知道當對一個物件進行復制時實際上是複製它的引用,除非你對這個物件進行深度複製。Redux要求你每次你返回的都是一個全新的State,而不是去修改它。這就要求我們要對原來的State進行深度複製。這往往帶來複雜的
mysql進階(一) mysql備份
mysql備份的目的: 實現災難恢復:誤操作、硬件故障、軟件故障、自然災害、黑客攻擊 註意的要點: 1、能夠容忍丟失多少數據 2、恢復數據所用的時間 3、備份需要的時間 4、是否對業務有影響 5、備份時服務器負載 備份類型 完全備份:備份整個
函數進階(一)
並行 自己的 習題 文件 false 聲明 方式 關鍵字 true 1.命名空間 本質:存放名字與值的綁定關系 命名空間的分類:(1)全局命名空間(變量)->位於函數體外 (2)局部命名空間(變量)->
Redis高級進階(一)
具體類 tro 類型 長度 刪除過期數據 專用 影響 生活 設置時間 一、redis中的事務 在關系型數據庫中事務是必不可少的一個核心功能,生活中也是處處可見,比如我們去銀行轉賬,首先需要將A賬戶的錢劃走,然後存到B賬戶上,這兩個步驟必須在同一事務中,要麽都執行,要麽都不執
SQL Server進階(一)T-SQL查詢和編程的背景
.com src 編程 server 分享 bubuko 進階 分享圖片 img SQL Server進階(一)T-SQL查詢和編程的背景
Redis高階進階(一)
一、redis中的事務 在關係型資料庫中事務是必不可少的一個核心功能,生活中也是處處可見,比如我們去銀行轉賬,首先需要將A賬戶的錢划走,然後存到B賬戶上,這兩個步驟必須在同一事務中,要麼都執行,要麼都不執行,不然錢憑空消失了,換了誰也無法接受。 同樣,redis中也為我們提供了事務,原理是:先把一組同一事
SpringCloud從入門到進階(一)——懂生活就懂微服務
避免 發現 官方文檔 隨著 並發 規範 只需要 組合 組件 內容 本文通過生活中的實際場景解釋單體應用和微服務應用的關系,以及SpringCloud中各組件的功能和含義。 適合人群 Java開發人員 說明 轉載請說明出處:SpringCloud從入門到進階(一)
Servlet進階(一)第一個JSP頁面
前言 本章講解JSP的相關知識之JSP初步 方法 1.概念 在以前我們寫網頁的時候,都是用html進行書寫,這種網頁是靜態的,無法和伺服器進行一個互動,那麼怎麼辦呢?JSP技術應運而生,我們在web開發之中,Java和Jsp可以形成完美的
JavaScript進階(一)JS事件機制
前言 做了這麼久的鋪墊,終於迎來了新的篇章,該章介紹JS中的事件機制 方法 1.概念 我們知道,JS是參與網頁互動的一門指令碼語言,之前所說的都是JS的基本概念,那麼怎麼來進行互動呢!那就需要JS的事件機制來進行控制了,如按鈕的點選事件觸
Android進階(一): Launcher啟動過程
1.前言 最近一直在看 《Android進階解密》 的一本書,這本書編寫邏輯、流程都非常好,而且很容易看懂,非常推薦大家去看看(沒有收廣告費,單純覺得作者寫的很好)。 今天就將 Launcher 系統啟動過程 總結一下(基於Android 8.0 系統)。 文章
c語言指標進階(一)
指標也是一種資料型別 指標是一個特殊的變數,它裡面儲存的數值被解釋成為記憶體裡的一個地址。要搞清一個指標需要搞清指標的四方面的內容:指標的型別,指標所指向的型別,指標的值或者叫指標所指向的記憶體區,還有指標本身所佔據的記憶體區。 1)指標是一種變數,佔有記憶體空間,用來儲存記憶體地址
C# 進階(一)Lambda 表示式
Lambda 表示式是一種可用於建立委託或表示式目錄樹型別的匿名函式。通過使用 lambda 表示式,可以寫入可作為引數傳遞或作為函式呼叫值返回的本地函式。 Lambda 表示式對於編寫 LINQ 查詢表示式特別有用。若要建立 Lambda 表示式,需要在 Lambda 運算
egg.js-基於koa2的node.js進階(一)
一、路由進階Egg路由的路由重定向,路由分組 在router.js修改為如下格式require引用 module.exports = app => { const { router, controller } = app; require('./routers/admin')(app); re
python3.5進階(一)-------------------網路通訊(ip、埠,socket)
1. ip地址:如198.168.1.1 ,用於在網路中標記區分每臺電腦,在本地區域網中是唯一的。window下程式->cmd->輸入ipconfig(檢視ipv4就是ip地址)。拓展:ip v4表示ip的第四個版本,目前出現了ipv6,ipv1/2/3/5都
PyQt5進階(一)——讓視窗裝載更多的控制元件
1. QTabWidget的使用 視窗上側有標籤,選擇不同標籤進入不同佈局頁面 import sys from PyQt5.QtWidgets import * class TabDemo(QTabWidget): def __init__(self, parent=No
Android----MVP架構進階(一)
相信大家一定在用mvp架構去設計App,但是在設計運用的過程中,大家有沒有考慮簡化程式碼,View層和Model層會有很多重複的程式碼,在顯示資料之前還需每次判斷View!=null,Presenter層每次需要去new Model層的例項,View層還有可能會對應多個Presenter
java進階(一):泛型
1、泛型簡介 所謂泛型,即通過引數化型別來實現在同一份程式碼上操作多種資料型別,泛型程式設計是一種程式設計正規化,他利用“引數化型別”將型別抽象化,從而實現更為靈活的複用。 先簡單給個例子: //可以想象這裡的T為Integer型別,以便於理解,其實它可以是任何型別 p
學習筆記之MongoDB進階(一)
MongoDB的條件操作符 MongoDB中條件操作符有: (>) 大於 - $gt (<) 小於 - $lt (>=) 大於等於 - $gte (<= ) 小於等於 - $lte $gt -------- greater than
Kotlin系統入門與進階(一)
一、什麼是Kotlin? Kotlin就是一門可以執行在Java虛擬機器、Android、瀏覽器上的靜態語言,他與Java 100%相容,如果對Java熟悉,可以發現Kotlin擁有自己
屬性動畫2:ValueAnimator高階進階(一)
1. 概述 前面一篇屬性動畫1:基礎知識和ValueAnimator寫完,我對屬性動畫基礎知識和ValueAnimator的簡單用法有了一些瞭解。要想把屬性動畫吃透,我感覺需要更加深入的學習。現在,就從ValueAnimator的高階進階開始,繼續攻克