
(c語言)gb2312和utf8轉換
(c語言)unicode和utf8轉換
unicode和utf8轉換規則
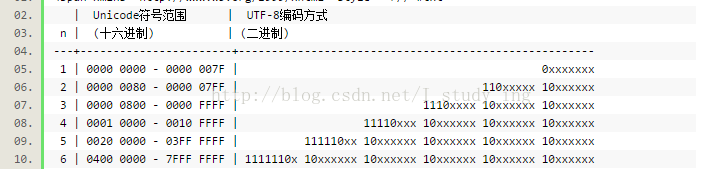
unicode與gb2312有著轉換表
所以,只需要unicode和utf8之間進行轉換即可
一、所以gb2312轉utf8
void Gb2312ToUtf8(const char* input_file, const char *output_file)
{
printf("gb2312->utf8: \n");
//請在此處新增程式碼完成gb2312到utf8的轉換
int byteCount=0;
int i=0;
int j=0;
u16 gbKey=0;
u16 unicodeKey=0;
long len;
FILE *fpIn=fopen(input_file,"rb");
if(fpIn==NULL){
printf("Unable to open the input file!\n");
return;
}
else{
fseek( fpIn, 0L, SEEK_END );
len = ftell( fpIn );
printf( "intput file size: %ldB\n", len );
}
FILE* fpOut=fopen(output_file,"wb");
if(fpOut==NULL)
{
printf("Unable to open the output file!\n");
return;
}
u8 *gb,*temp;
gb=new u8[len*2];
temp=new u8[len*2];
fseek(fpIn,0L,SEEK_SET);
fread(gb,sizeof(u8),len,fpIn);
int count=0;
while(i<len){
memcpy(&gbKey,(gb+i),2);
gbKey=(gbKey >> 8) | (gbKey << 8);
unicodeKey=SearchCodeTable_GB2312(gbKey);
byteCount=0;
//unicodeKey->utf-8
if(unicodeKey==0){
printf("fail:table can not find the key: 0x%x \n",gbKey);
count++;
temp[j]=gb[i];
j++;
}
else {
if(unicodeKey<=0x0000007F){
temp[j]=unicodeKey&0x7F;
byteCount=1;
continue;
}
else if(unicodeKey>=0x00000080&&unicodeKey<0x000007FF){
temp[j+1]=(unicodeKey&0x3F)|0x80;
temp[j]=((unicodeKey>>6)&0x1F)|0xC0;
byteCount=2;
continue;
}
else if(unicodeKey>=0x00000800&&unicodeKey<=0x0000FFFF){
temp[j+2]=(unicodeKey&0x3F)|0x80;
temp[j+1]=((unicodeKey>>6)&0x3F)|0x80;
temp[j]=((unicodeKey>>12)&0x0F)|0xE0;
byteCount=3;
i++;
continue;
}
else if(unicodeKey>=0x00010000&&unicodeKey<=0x0010FFFF){
temp[j+3]=(unicodeKey&0x3F)|0x80;
temp[j+2]=((unicodeKey>>6)&0x3F)|0x80;
temp[j+1]=((unicodeKey>>12)&0x3F)|0x80;
temp[j]=((unicodeKey>>18)&0xF7);
byteCount=4;
continue;
}
else if(unicodeKey>=0x00200000&&unicodeKey<=0x03FFFFFF){
temp[j+4]=(unicodeKey&0x3F)|0x80;
temp[j+3]=((unicodeKey>>6)&0x3F)|0x80;
temp[j+2]=((unicodeKey>>12)&0x3F)|0x80;
temp[j+1]=((unicodeKey>>18)&0x3F)|0x80;
temp[j]=((unicodeKey>>24)&0xF7);
byteCount=5;
continue;
}
else if(unicodeKey>=0x04000000&&unicodeKey<=0x7FFFFFFF){
temp[j+5]=(unicodeKey&0x3F)|0x80;
temp[j+4]=((unicodeKey>>6)&0x3F)|0x80;
temp[j+3]=((unicodeKey>>12)&0x3F)|0x80;
temp[j+2]=((unicodeKey>>18)&0x3F)|0x80;
temp[j+1]=((unicodeKey>>24)&0x3F)|0x80;
temp[j]=((unicodeKey>>30)&0xF7);
byteCount=6;
continue;
}
else{
printf("out of unicodeKey ! \n");
continue;
}
}
j+=byteCount;
i+=1;
}
printf("There are %d wrong!",count);
fwrite(temp, sizeof(u8),j, fpOut);
delete []gb;
delete []temp;
fclose(fpIn);
fclose(fpOut);
}
二、utf8轉gb2312
void Utf8ToGb2312(const char* input_file, const char *output_file)
{
printf("utf8->unicode: \n");
int byteCount = 0;
int i = 0;
int j = 0;
u16 unicodeKey = 0;
u16 gbKey = 0;
long len;
FILE* fpIn=fopen(input_file,"rb");
if(fpIn==NULL)
{
printf("Unabile to open the input file!\n");
return;
}
else
{
// 將指標定位到檔案末尾
fseek( fpIn, 0L, SEEK_END );
len = ftell( fpIn );
printf( "intput file size: %ldB\n", len );
}
FILE* fpOut=fopen(output_file,"wb");
if(fpOut==NULL)
{
printf("Unabile to open the output file!\n");
return;
}
u8 *utf8,*temp;
utf8=new u8[len];
temp=new u8[len];
fseek( fpIn, 0L, SEEK_SET );
fread(utf8, sizeof(u8),len,fpIn);
i=3;
while (i < len)
{
switch(GetUtf8ByteNumForWord((u8)utf8[i]))
{
case 0:
temp[j] = utf8[i];
byteCount = 1;
break;
case 2:
temp[j] = utf8[i];
temp[j + 1] = utf8[i + 1];
byteCount = 2;
break;
case 3:
//這裡就開始進行UTF8->Unicode
temp[j + 1] = ((utf8[i] & 0x0F) << 4) | ((utf8[i + 1] >> 2) & 0x0F);
temp[j] = ((utf8[i + 1] & 0x03) << 6) + (utf8[i + 2] & 0x3F);
//取得Unicode的值
memcpy(&unicodeKey, (temp + j), 2);
//printf("unicode key is: 0x%04X\n", unicodeKey);
//根據這個值查表取得對應的GB2312的值
gbKey = SearchCodeTable(unicodeKey);
//printf("gb2312 key is: 0x%04X\n", gbKey);
if (gbKey != 0)
{
//here change the byte
//不為0表示搜尋到,將高低兩個位元組調換調成我要的形式
gbKey = (gbKey >> 8) | (gbKey << 8);
//printf("after changing, gb2312 key is: 0x%04X\n", gbKey);
memcpy((temp + j), &gbKey, 2);
}
byteCount = 3;
break;
case 4:
byteCount = 4;
break;
case 5:
byteCount = 5;
break;
case 6:
byteCount = 6;
break;
default:
printf("the len is more than 6\n");
break;
}
i += byteCount;
if (byteCount == 1)
{
j++;
}
else
{
j += 2;
}
}
fwrite(temp, sizeof(u8),j, fpOut);
delete []utf8;
delete []temp;
fclose(fpIn);
fclose(fpOut);
}
相關推薦
(c語言)gb2312和utf8轉換
(c語言)unicode和utf8轉換 unicode和utf8轉換規則 unicode與gb2312有著轉換表 所以,只需要unicode和utf8之間進行轉換即可 一、所以gb2312轉utf8 void Gb2312ToUtf8(const char* inp
進位制轉換(c語言)
#include <stdio.h> #include <stdlib.h> void change(int n) { if (n == 0) return; else { // change(n / 8);
求兩個單調不減單鏈表的交集和並集(C語言)
一、思路: 構造struct node* Link(struct node *P,struct node *Q,int sign)函式,當sign=1時,返回P,Q的並集,當sign=0時,返回P,Q的交集,求交併的思路為: ①對P,Q分別賦予兩個指標p和q,初始時分別指向P,Q的頭結點
初夏小談:判斷系統日期和時間(C語言)
計算系統當前日期和時間: #define _CRT_SECURE_NO_WARNINGS 1 #include<stdio.h> #include<stdlib.h> #include<time.h> int main() { int array[] =
計算1~100之間,能被3整除但是不能被7整除的數的和(C語言)
#include<stdio.h> int main(agrc *agrv) { int n,i; int sum=0; scanf("%d",&n); for(i=1;i<=n;i++){ if(i%3==0&&i%7!=0){ sum+=i; &
C語言(C++語言)中##(兩個井號)和#(一個井號)用法[轉]
C語言(C++語言)中的巨集(Macro)屬於編譯器預處理的範疇,屬於編譯期概念(而非執行期概念)。下面對常遇到的巨集的使用問題做了簡單總結。 關 於#和## 在C語言的巨集中,#的功能是將其後面的巨集引數進行字串化操作(Stringfication),簡單說就是在對它所引用的巨集變數通過替換後
PTA-求n以內最大的k個素數以及它們的和(C語言)
輸入樣例1: 1000 10 輸出樣例1: 997+991+983+977+971+967+953+947+941+937=9664 輸入樣例2: 12 6 輸出樣例2: 11+7+5+3+2=28 #include <stdio.h> //判斷素數 int prime(i
PTA-計算階乘和(C語言)
對於給定的正整數N,需要你計算 S=1!+2!+3!+…+N!。 輸入格式: 輸入在一行中給出一個不超過10的正整數N。 輸出格式: 在一行中輸出S的值。 輸入樣例: 3 輸出樣例: 9 #include<stdio.h> int main() { int n=
單鏈表的相關操作和測試(C語言)
“single-LinkList.h” 標頭檔案 #ifndef _SINGLE_LL #define _SINGLE_LL #include<stdlib.h> #include<stdio.h> #define flag -100
資料結構(C語言)棧的建立、入棧、出棧並進行進位制轉換
十進位制數轉換為八進位制: | N |N div 8(商) | N mod 8(餘數) |1348| 168 | 4 | 168 | 21 | 0
以金字塔形列印字母和數字(C語言)
最近剛開始學習C語言迴圈部分,做題C語言實現金字塔輸出。 題目:輸出如下 A ABA ABCBA ABCDCBA ABCDEDCBA 程式碼: #include<stdio.h> #include<math.h> int main() { int i,j;
LeetCode 34. 在排序陣列中查詢元素的第一個和最後一個位置 Find First and Last Position of Element in Sorted Array(C語言)
題目描述: 給定一個按照升序排列的整數陣列 nums,和一個目標值 target。找出給定目標值在陣列中的開始位置和結束位置。 你的演算法時間複雜度必須是 O(log n) 級別。 如果陣列中不存在目標值,返回 [-1, -1]。 示例 1: 輸入: nums = [
(C語言)連結串列的建立、遍歷、插入和刪除
作者:翁鬆秀 (C語言)連結串列的建立、遍歷、插入和刪除 (C語言)連結串列的建立、遍歷、插入和刪除 連結串列結構定義
牛頓法和割線法方程求根(C語言)
1 . 實驗目的 (1) 通過對二分法與牛頓迭代法作程式設計練習與上機運算,進一步體會二分法與牛頓迭代法的不同特點。 (2) 編寫割線迭代法的程式,求非線性方程的解,並與牛頓迭代法作比較。
LeetCode 53. 最大子序和 Maximum Subarray(C語言)
題目描述: 給定一個整數陣列 nums ,找到一個具有最大和的連續子陣列(子陣列最少包含一個元素),返回其最大和。 示例: 輸入: [-2,1,-3,4,-1,2,1,-5,4], 輸出: 6 解釋: 連續子陣列 [4,-1,2,1] 的和最大,為 6。 進
LeetCode 64. 最小路徑和 Minimum Path Sum(C語言)
題目描述: 給定一個包含非負整數的 m x n 網格,請找出一條從左上角到右下角的路徑,使得路徑上的數字總和為最小。 說明:每次只能向下或者向右移動一步。 示例: 輸入: [ [1,3,1], [1,5,1], [4,2,1] ] 輸出: 7 解釋:
結構體的初始化和引用及指向結構體變數的指標變數(C語言)
一、首先我們來了解關於結構體以及結構體陣列的概念。 自定義結構體: struct weapon{ char name[20]; int atk; int price; }; 它是"weapon"型(類似於我們熟知的int型,String型等),裡
(c語言)選擇排序法和氣泡排序法
問題描述: 給定一個數組(或者輸入一個數組),分別運用選擇排序法和氣泡排序法將所要的結果輸出。 程式分析: 選擇排序 1>.對於選擇排序,首先理解排序的思想。給定一個數組,這種思想首先假定
(C語言)整數劃分問題 遞迴和遞推
對於一個正整數n的劃分,就是把n變成一系列正整數之和的表示式。注意,分劃與順序無關,例如6=5+1跟6=1+5是 同一種分劃。另外,單獨這個整數本身也算一種分劃。 例如:對於正整數n=5,可以劃分為: 1+1+1+1+1 1+1+1+2 1+1+3 1+2+2 2+3 1+4 5 輸入描述 輸入一個正整
二叉樹插入和刪除操作的遞迴實現(c語言)
連結串列和陣列是最常見的資料結構,對於資料結構來說,查詢(Find),最大最小值(FindMin,FindMax),插入(Insert)和刪除(Delete)操作是最基本的操作。對於連結串列和陣列來說,這些操作的時間界為O(N),其中N為元素的個數。陣列的插入和刪除需要對其他