
流式計算--Kafka詳解
理解storm、spark streamming等流式計算的資料來源、理解JMS規範、理解Kafka核心元件、掌握Kakfa生產者API、掌握Kafka消費者API。對流式計算的生態環境有深入的瞭解,具備流式計算專案架構的能力。所以學習kafka要掌握以下幾點:
1、 kafka是什麼?2、 JMS規範是什麼?
3、 為什麼需要訊息佇列?
4、 Kafka核心元件
5、 Kafka安裝部署
6、 Kafka生產者Java API
7、 Kafka消費者Java API
8、 Kafka整體結構圖
9、 Consumer與topic關係
10、 Kafka Producer訊息分發
11、 Consumer 的負載均衡
12、 Kafka檔案儲存機制
13、 Kafka自定義partition
(一)kafka簡介
1、簡介
Kafka是一種分散式的、基於釋出/訂閱的訊息系統。在流式計算中,Kafka一般用來快取資料,Storm通過消費Kafka的資料進行計算(KAFKA + STORM+REDIS)。 Apache Kafka是一個開源訊息系統,由Scala寫成。是由Apache軟體基金會開發的一個開源訊息系統專案。它最初是由LinkedIn開發,並於2011年初開源。2012年10月從ApacheIncubator畢業。該專案的目標是為處理實時資料提供一個統一、高通量、低等待的平臺。
– 訊息持久化:通過O(1)的磁碟資料結構提供資料的持久化
– 高吞吐量:每秒百萬級的訊息讀寫
– 分散式:擴充套件能力強
– 多客戶端支援:java、php、python、c++ ……
– 實時性:生產者生產的message立即被消費者可見
-Kafka是一個分散式訊息佇列:生產者、消費者的功能。它提供了類似於JMS的特性,但是在設計實現上完全不同,此外它並不是JMS規範的實現。
- Kafka對訊息儲存時根據Topic進行歸類,傳送訊息者稱為Producer,訊息接受者稱為Consumer,此外kafka叢集有多個kafka例項組成,每個例項(server)成為
-無論是kafka叢集,還是producer和consumer都依賴於zookeeper叢集儲存一些meta資訊,來保證系統可用性
2、JMS是什麼
2.1、JMS的基礎
JMS是什麼:JMS是Java提供的一套技術規範
JMS幹什麼用:用來異構系統 整合通訊,緩解系統瓶頸,提高系統的伸縮性增強系統使用者體驗,使得系統模組化和元件化變得可行並更加靈活
通過什麼方式:生產消費者模式(生產者、伺服器、消費者)
jdk,kafka,activemq……
2.2、JMS訊息傳輸模型
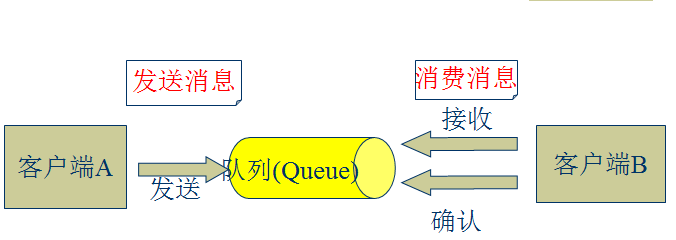
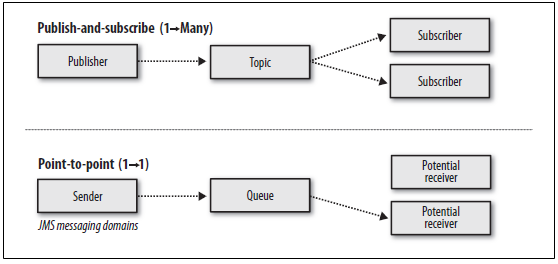
l 點對點模式(一對一,消費者主動拉取資料,訊息收到後訊息清除)
點對點模型通常是一個基於拉取或者輪詢的訊息傳送模型,這種模型從佇列中請求資訊,而不是將訊息推送到客戶端。這個模型的特點是傳送到佇列的訊息被一個且只有一個接收者接收處理,即使有多個訊息監聽者也是如此。
l 釋出/訂閱模式(一對多,資料生產後,推送給所有訂閱者)
釋出訂閱模型則是一個基於推送的訊息傳送模型。釋出訂閱模型可以有多種不同的訂閱者,臨時訂閱者只在主動監聽主題時才接收訊息,而持久訂閱者則監聽主題的所有訊息,即時當前訂閱者不可用,處於離線狀態。
queue.put(object) 資料生產
queue.take(object) 資料消費
2.3、JMS核心元件
l Destination:訊息傳送的目的地,也就是前面說的Queue和Topic。
l Message [m1] :從字面上就可以看出是被髮送的訊息。
l Producer: 訊息的生產者,要傳送一個訊息,必須通過這個生產者來發送。
l MessageConsumer: 與生產者相對應,這是訊息的消費者或接收者,通過它來接收一個訊息。
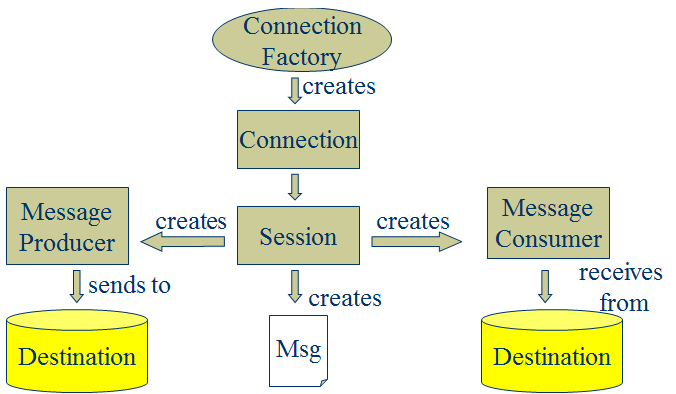
通過與ConnectionFactory可以獲得一個connection
通過connection可以獲得一個session會話。
其中message又細分為如下幾類
StreamMessage:Java 資料流訊息,用標準流操作來順序的填充和讀取。MapMessage:一個Map型別的訊息;名稱為 string 型別,而值為 Java 的基本型別。
TextMessage:普通字串訊息,包含一個String。
ObjectMessage:物件訊息,包含一個可序列化的Java 物件
BytesMessage:二進位制陣列訊息,包含一個byte[]。
XMLMessage: 一個XML型別的訊息。
最常用的是TextMessage和ObjectMessage。
2.4、常見的類JMS訊息伺服器
2.4.1、JMS訊息伺服器 ActiveMQ
ActiveMQ 是Apache出品,最流行的,能力強勁的開源訊息匯流排。ActiveMQ 是一個完全支援JMS1.1和J2EE 1.4規範的。
主要特點:
l 多種語言和協議編寫客戶端。語言: Java, C, C++, C#, Ruby, Perl, Python, PHP。應用協議:OpenWire,Stomp REST,WS Notification,XMPP,AMQPl 完全支援JMS1.1和J2EE 1.4規範 (持久化,XA訊息,事務)
l 對Spring的支援,ActiveMQ可以很容易內嵌到使用Spring的系統裡面去,而且也支援Spring2.0的特性
l 通過了常見J2EE伺服器(如 Geronimo,JBoss 4, GlassFish,WebLogic)的測試,其中通過JCA 1.5resource adaptors的配置,可以讓ActiveMQ可以自動的部署到任何相容J2EE 1.4 商業伺服器上
l 支援多種傳送協議:in-VM,TCP,SSL,NIO,UDP,JGroups,JXTA
l 支援通過JDBC和journal提供高速的訊息持久化
l 從設計上保證了高效能的叢集,客戶端-伺服器,點對點
l 支援Ajax
l 支援與Axis的整合
l 可以很容易得呼叫內嵌JMS provider,進行測試
2.4.2、分散式訊息中介軟體 Metamorphosis
Metamorphosis(MetaQ) 是一個高效能、高可用、可擴充套件的分散式訊息中介軟體,類似於LinkedIn的Kafka,具有訊息儲存順序寫、吞吐量大和支援本地和XA事務等特性,適用於大吞吐量、順序訊息、廣播和日誌資料傳輸等場景,在淘寶和支付寶有著廣泛的應用,現已開源。
主要特點:
l 生產者、伺服器和消費者都可分佈l 訊息儲存順序寫
l 效能極高,吞吐量大
l 支援訊息順序
l 支援本地和XA事務
l 客戶端pull,隨機讀,利用sendfile系統呼叫,zero-copy ,批量拉資料
l 支援消費端事務
l 支援訊息廣播模式
l 支援非同步傳送訊息
l 支援http協議
l 支援訊息重試和recover
l 資料遷移、擴容對使用者透明
l 消費狀態儲存在客戶端
l 支援同步和非同步複製兩種HA
l 支援group commit
2.4.3、分散式訊息中介軟體 RocketMQ
RocketMQ 是一款分散式、佇列模型的訊息中介軟體,具有以下特點:
l 能夠保證嚴格的訊息順序l 提供豐富的訊息拉取模式
l 高效的訂閱者水平擴充套件能力
l 實時的訊息訂閱機制
l 億級訊息堆積能力
l Metaq3.0 版本改名,產品名稱改為RocketMQ
2.4.4、其他MQ
l .NET訊息中介軟體DotNetMQl 基於HBase的訊息佇列 HQueue
l Go 的 MQ 框架 KiteQ
l AMQP訊息伺服器RabbitMQ
l MemcacheQ 是一個基於MemcacheDB 的訊息佇列伺服器。
3、為什麼需要訊息佇列(重要)
訊息系統的核心作用就是三點:解耦,非同步和並行
以使用者註冊的案列來說明訊息系統的作用
3.1、使用者註冊的一般流程
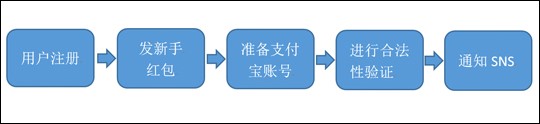
問題:隨著後端流程越來越多,每步流程都需要額外的耗費很多時間,從而會導致使用者更長的等待延遲。
3.2、使用者註冊的並行執行

問題:系統並行的發起了4個請求,4個請求中,如果某一個環節執行1分鐘,其他環節再快,使用者也需要等待1分鐘。如果其中一個環節異常之後,整個服務掛掉了。
3.3、使用者註冊的最終一致

1、 保證主流程的正常執行、執行成功之後,傳送MQ訊息出去。
2、 需要這個destination的其他系統通過消費資料再執行,最終一致。

(二)Kafka基本元件
• Broker:每一臺機器叫一個Broker• Producer:日誌訊息生產者,用來寫資料
• Consumer:訊息的消費者,用來讀資料
• Topic:不同消費者去指定的Topic中讀,不同的生產者往不同的Topic中寫
• Partition:在Topic基礎上做了進一步區分分層
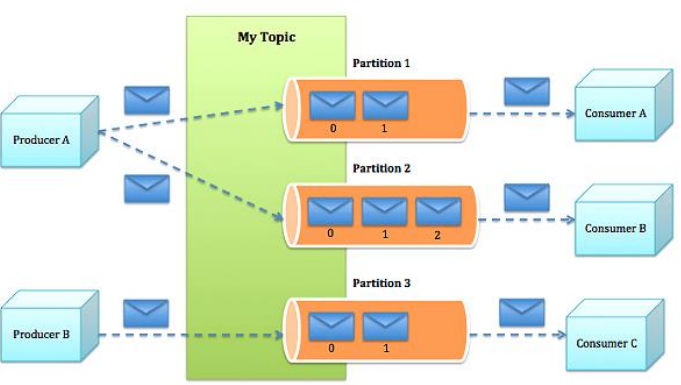
• Kafka內部是分散式的、一個Kafka叢集通常包括多個Broker
• 負載均衡:將Topic分成多個分割槽,每個Broker儲存一個或多個Partition
• 多個Producer和Consumer同時生產和消費訊息
2.1 topic

• commit的log可以不斷追加。訊息在每個分割槽中都分配了一個叫offset的id序列來唯一識別分割槽中的訊息。
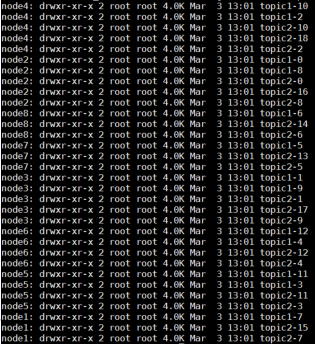
• 舉例:若建立topic1和topic2兩個topic,且分別有13個和19個分割槽,則整個叢集上會相應會生成共32個資料夾,如圖
• 在每個消費者都持久化這個offset在日誌中。通常消費者讀訊息時會使offset值線性的增長,但實際上其位置是由消費者控制,它可以按任意順序來消費訊息。比如復位到老的offset來重新處理。
• 每個分割槽代表一個並行單元。
2.2 message
• message(訊息)是通訊的基本單位,每個producer可以向一個topic(主題)釋出一些訊息。如果consumer訂閱了這個主題,那麼新發布的訊息就會廣播給這些consumer。• DFS的基本單位:block
• Flume的基本單位:event
• Hadoop task程序
• Spark task/partition 執行緒
• messageformat(磁碟上的儲存格式):
– message length :4 bytes (value: 1+4+n)
– "magic"value : 1 byte
– crc : 4 bytes
– payload : n bytes
2.3 Producer
• 生產者可以釋出資料到它指定的topic中,並可以指定在topic裡哪些訊息分配到哪些分割槽(比如簡單的輪流分發各個分割槽或通過指定分割槽語義分配key到對應分割槽)key%3(partition)• 生產者直接把訊息傳送給對應分割槽的broker,而不需要任何路由層。
• 批處理髮送,當message積累到一定數量或等待一定時間後進行傳送。
生產者常用API:

2.4 Consumer
• 一種更抽象的消費方式:消費組(consumer group)• 該方式包含了傳統的queue和釋出訂閱方式
– 首先消費者標記自己一個消費組名。訊息將投遞到每個消費組中的某一個消費者例項上。
– 如果所有的消費者例項都有相同的消費組,這樣就像傳統的queue方式。
– 如果所有的消費者例項都有不同的消費組,這樣就像傳統的釋出訂閱方式。
– 消費組就好比是個邏輯的訂閱者,每個訂閱者由許多消費者例項構成(用於擴充套件或容錯)。
• 相對於傳統的訊息系統,kafka擁有更強壯的順序保證。
• 由於topic採用了分割槽,可在多Consumer程序操作時保證順序性和負載均衡。
消費者常用API:

(三)kafka core
3.1 持久化
• Kafka儲存佈局簡單:Topic的每個Partition對應一個邏輯日誌(一個日誌為相同大小的一組分段檔案)
• 每次生產者釋出訊息到一個分割槽,代理就將訊息追加到最後一個段檔案中。當釋出的訊息數量達到設定值或者經過一定的時間後,段檔案真正flush磁碟中。寫入完成後,訊息公開給消費者。
• 與傳統的訊息系統不同,Kafka系統中儲存的訊息沒有明確的訊息Id。
• 訊息通過日誌中的邏輯偏移量來公開。

3.2 傳輸效率
• 生產者提交一批訊息作為一個請求。消費者雖然利用api遍歷訊息是一個一個的,但背後也是一次請求獲取一批資料,從而減少網路請求數量。• Kafka層採用無快取設計,而是依賴於底層的檔案系統頁快取。這有助於避免雙重快取,及即訊息只快取了一份在頁快取中。同時這在kafka重啟後保持快取warm也有額外的優勢。因kafka根本不快取訊息在程序中,故gc開銷也就很小
• zero-copy:kafka為了減少位元組拷貝,採用了大多數系統都會提供的sendfile系統呼叫
• 太多小的IO操作(message)以及過多的位元組拷貝
--sendfile:實現頁快取和

2、應用(application)將資料從核心空間讀到使用者空間的頁快取
3、application將資料使用者空間寫到 socket buffer中
4、作業系統將資料從socket快取寫到網絡卡快取中
Zero copy:1、作業系統將資料從磁碟讀到核心空間的頁快取
2、read buffer (核心頁快取)socket buffer
3、socket buffer快取到NIC buffer (網絡卡快取)
頁快取和塊快取的區別:(核心為塊裝置提供的兩個通用的方案)為了加快到後端裝置的IO效率
3.3無狀態的Broker
• Kafka代理是無狀態的:意味著消費者必須維護已消費的狀態資訊。這些資訊由消費者自己維護,代理完全不管。這種設計非常微妙,它本身包含了創新– 從代理刪除訊息變得很棘手,因為代理並不知道消費者是否已經使用了該訊息。Kafka創新性地解決了這個問題,它將一個簡單的基於時間的SLA協議應用於保留策略。當訊息在代理中超過一定時間後,將會被自動刪除。
– 這種創新設計有很大的好處,消費者可以故意倒回到老的偏移量再次消費資料。這違反了佇列的常見約定,但被證明是許多消費者的基本特徵。
3.4 交付保證
• Kafka預設採用at least once的訊息投遞策略。即在消費者端的處理順序是獲得訊息->處理訊息->儲存位置。這可能導致一旦客戶端掛掉,新的客戶端接管時處理前面客戶端已處理過的訊息。• 三種保證策略:
– At most once 訊息可能會丟,但絕不會重複傳輸
– At least one 訊息絕不會丟,但可能會重複傳輸
– Exactly once 每條訊息肯定會被傳輸一次且僅傳輸一次
3.5 副本管理
• kafka將日誌複製到指定多個伺服器上。
• 複本的單元是partition。在正常情況下,每個分割槽有一個leader和0到多個follower。
• leader處理對應分割槽上所有的讀寫請求。分割槽可以多於broker數,leader也是分散式的。
• follower的日誌和leader的日誌是相同的, follower被動的複製leader。如果leader掛了,其中一個follower會自動變成新的leader.
– 節點在zookeeper註冊的session還在且可維護(基於zookeeper心跳機制)
– 如果是slave則能夠緊隨leader的更新不至於落得太遠。
• kafka採用in sync來代替“活著”
– 如果follower掛掉或卡住或落得很遠,則leader會移除同步列表中的in sync。至於落了多遠才叫遠由replica.lag.max.messages配置,而表示複本“卡住”由replica.lag.time.max.ms配置
• 所謂一條訊息是“提交”的,意味著所有in sync的複本也持久化到了他們的log中。這意味著消費者無需擔心leader掛掉導致資料丟失。另一方面,生產者可以選擇是否等待訊息“提交”。
• kafka動態的維護了一組in-sync(ISR)的複本,表示已追上了leader,只有處於該狀態的成員組才是能被選擇為leader。這些ISR組會在發生變化時被持久化到zookeeper中。通過ISR模型和f+1複本,可以讓kafka的topic支援最多f個節點掛掉而不會導致提交的資料丟失。
3.6 分散式協調
• 由於kafka中一個topic中的不同分割槽只能被消費組中的一個消費者消費,就避免了多個消費者消費相同的分割槽時會導致額外的開銷(如要協調哪個消費者消費哪個訊息,還有鎖及狀態的開銷)。kafka中消費程序只需要在代理和同組消費者有變化時時進行一次協調(這種協調不是經常性的,故可以忽略開銷)。
• kafka使用zookeeper做以下事情:
– 探測broker和consumer的新增或移除
– 當1發生時觸發每個消費者程序的重新負載。
– 維護消費關係和追蹤消費者在分割槽消費的訊息的offset。
3.7 與zookkeeper的使用
• Broker Node Registry• /brokers/ids/[0...N] --> host:port (ephemeral node)
– broker啟動時在/brokers/ids下建立一個znode,把broker id寫進去。
– 因為broker把自己註冊到zookeeper中實用的是瞬時節點,所以這個註冊是動態的,如果broker宕機或者沒有響應該節點就會被刪除。
• Broker Topic Registry
• /brokers/topics/[topic]/[0...N] --> nPartions (ephemeral node)
– 每個broker把自己儲存和維護的partion資訊註冊到該路徑下。
• Consumers and Consumer Groups
– consumers也把它們自己註冊到zookeeper上,用以保持消費負載平衡和offset記錄。
– group id相同的多個consumer構成一個消費租,共同消費一個topic,同一個組的consumer會盡量均勻的消費,其中的一個consumer只會消費一個partion的資料。
• Consumer Id Registry
• /consumers/[group_id]/ids/[consumer_id] --> {"topic1": #streams, ...,"topicN": #streams} (ephemeral node)
– 每個consumer在/consumers/[group_id]/ids下建立一個瞬時的唯一的consumer_id,用來描述當前該group下有哪些consumer是alive的,如果消費程序掛掉對應的consumer_id就會從該節點刪除。
• Consumer Offset Tracking
• /consumers/[group_id]/offsets/[topic]/[partition_id] -->offset_counter_value ((persistent node)
– consumer把每個partition的消費offset記錄儲存在該節點下。
• Partition Owner registry
• /consumers/[group_id]/owners/[topic]/[broker_id-partition_id] -->consumer_node_id (ephemeral node)
– 該節點維護著partion與consumer之間的對應關係。
3.8 Kafka對比其他訊息服務
• LinkedIn團隊做了個實驗研究,對比Kafka與Apache ActiveMQ V5.4和RabbitMQ V2.4的效能。他們使用ActiveMQ預設的訊息持久化庫Kahadb。LinkedIn在兩臺Linux機器上執行他們的實驗,每臺機器的配置為8核2GHz、16GB記憶體,6個磁碟使用RAID10。兩臺機器通過1GB網路連線。一臺機器作為代理,另一臺作為生產者或者消費者。
• 生產者測試:
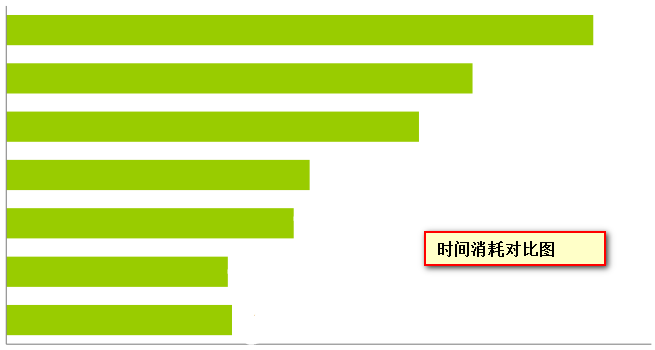
– 對每個系統,執行一個生產者,總共釋出1000萬條訊息,每條訊息200位元組。Kafka生產者以1和50批量方式傳送訊息。ActiveMQ和RabbitMQ似乎沒有簡單的辦法來批量傳送訊息,LinkedIn假定它的批量值為1。結果如下圖所示:
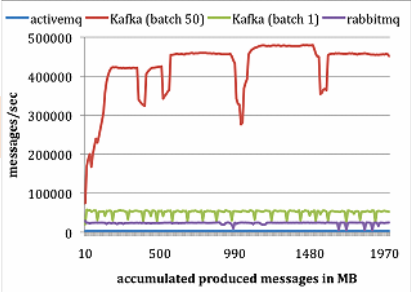
Kafka 效能要好很多的主要原因包括:
1. Kafka不等待代理的確認,以代理能處理的最快速度傳送訊息。
2. Kafka有更高效的儲存格式。平均而言,Kafka每條訊息有9位元組的開銷,而ActiveMQ有144位元組。其原因是JMS所需的沉重訊息頭,以及維護各種索引結構的開銷。LinkedIn注意到ActiveMQ一個最忙的執行緒大部分時間都在存取B-Tree以維護訊息元資料和狀態。
• 消費者測試:
– 為了做消費者測試,LinkedIn使用一個消費者獲取總共1000萬條訊息。LinkedIn讓所有系統每次讀取請求都預獲取大約相同數量的資料,最多1000條訊息或者200KB。對ActiveMQ和RabbitMQ,LinkedIn設定消費者確認模型為自動。結果如圖所示。

1. Kafka有更高效的儲存格式,在Kafka中,從代理傳輸到消費者的位元組更少。
2. ActiveMQ和RabbitMQ兩個容器中的代理必須維護每個訊息的傳輸狀態。LinkedIn團隊注意到其中一個ActiveMQ執行緒在測試過程中,一直在將KahaDB頁寫入磁碟。與此相反,Kafka代理沒有磁碟寫入動作。最後,Kafka通過使用sendfileAPI降低了傳輸開銷
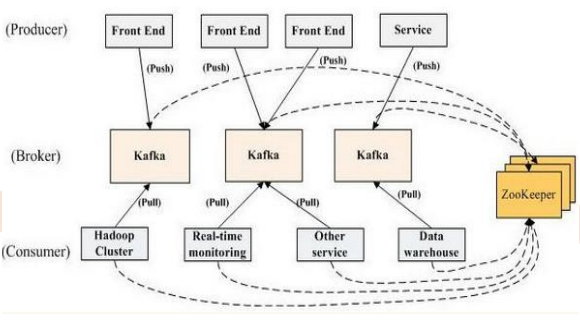
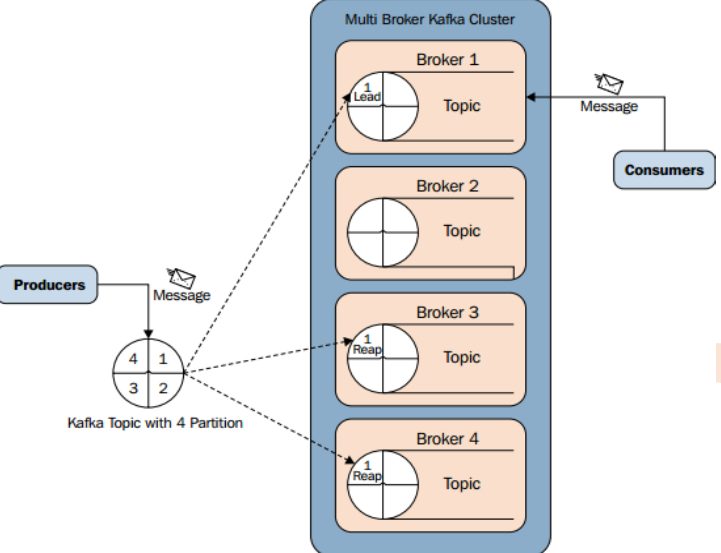
(四)Kafka整體結構圖
l Producer :訊息生產者,就是向kafka broker發訊息的客戶端。l Consumer :訊息消費者,向kafka broker取訊息的客戶端
l Topic :咋們可以理解為一個佇列。
l Consumer Group (CG):這是kafka用來實現一個topic訊息的廣播(發給所有的consumer)和單播(發給任意一個consumer)的手段。一個topic可以有多個CG。topic的訊息會複製(不是真的複製,是概念上的)到所有的CG,但每個partion只會把訊息發給該CG中的一個consumer。如果需要實現廣播,只要每個consumer有一個獨立的CG就可以了。要實現單播只要所有的consumer在同一個CG。用CG還可以將consumer進行自由的分組而不需要多次傳送訊息到不同的topic。
l Broker :一臺kafka伺服器就是一個broker。一個叢集由多個broker組成。一個broker可以容納多個topic。
l Partition:為了實現擴充套件性,一個非常大的topic可以分佈到多個broker(即伺服器)上,一個topic可以分為多個partition,每個partition是一個有序的佇列。partition中的每條訊息都會被分配一個有序的id(offset)。kafka只保證按一個partition中的順序將訊息發給consumer,不保證一個topic的整體(多個partition間)的順序。
l Offset:kafka的儲存檔案都是按照offset.kafka來命名,用offset做名字的好處是方便查詢。例如你想找位於2049的位置,只要找到2048.kafka的檔案即可。當然the first offset就是00000000000.kafka
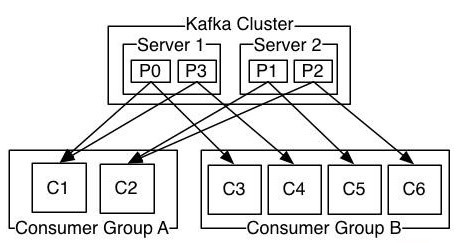
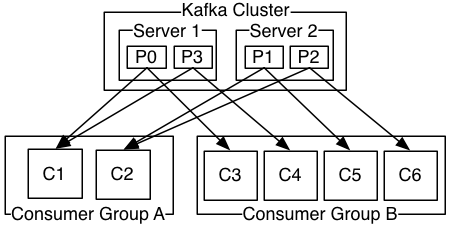
(五)Consumer與topic關係
本質上kafka只支援Topic;l 每個group中可以有多個consumer,每個consumer屬於一個consumergroup;
通常情況下,一個group中會包含多個consumer,這樣不僅可以提高topic中訊息的併發消費能力,而且還能提高"故障容錯"性,如果group中的某個consumer失效那麼其消費的partitions將會有其他consumer自動接管。
l 對於Topic中的一條特定的訊息,只會被訂閱此Topic的每個group中的其中一個consumer消費,此訊息不會發送給一個group的多個consumer;
那麼一個group中所有的consumer將會交錯的消費整個Topic,每個group中consumer訊息消費互相獨立,我們可以認為一個group是一個"訂閱"者。
l 在kafka中,一個partition中的訊息只會被group中的一個consumer消費(同一時刻);
一個Topic中的每個partions,只會被一個"訂閱者"中的一個consumer消費,不過一個consumer可以同時消費多個partitions中的訊息。
l kafka的設計原理決定,對於一個topic,同一個group中不能有多於partitions個數的consumer同時消費,否則將意味著某些consumer將無法得到訊息。
kafka只能保證一個partition中的訊息被某個consumer消費時是順序的;事實上,從Topic角度來說,當有多個partitions時,訊息仍不是全域性有序的。
(六)Kafka訊息的分發
6.1、Producer客戶端負責訊息的分發
l kafka叢集中的任何一個broker都可以向producer提供metadata資訊,這些metadata中包含"叢集中存活的servers列表"/"partitions leader列表"等資訊;l 當producer獲取到metadata資訊之後,producer將會和Topic下所有partition leader保持socket連線;
l 訊息由producer直接通過socket傳送到broker,中間不會經過任何"路由層",事實上,訊息被路由到哪個partition上由producer客戶端決定;
比如可以採用"random""key-hash""輪詢"等,如果一個topic中有多個partitions,那麼在producer端實現"訊息均衡分發"是必要的。
l 在producer端的配置檔案中,開發者可以指定partition路由的方式。
6.2、Producer訊息傳送的應答機制
設定傳送資料是否需要服務端的反饋,有三個值0,1,-10: producer不會等待broker傳送ack
1: 當leader接收到訊息之後傳送ack-1: 當所有的follower都同步訊息成功後傳送ack
request.required.acks=0
(七)Consumer的負載均衡
當一個group中,有consumer加入或者離開時,會觸發partitions均衡.均衡的最終目的,是提升topic的併發消費能力,步驟如下:1、 假如topic1,具有如下partitions: P0,P1,P2,P3
2、 加入group中,有如下consumer: C1,C2
3、 首先根據partition索引號對partitions排序: P0,P1,P2,P3
4、 根據consumer.id排序: C0,C1
5、 計算倍數: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
6、 然後依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i *M),P((i + 1) * M -1)]
(八)Kafka檔案存儲機制
8.1、Kafka檔案儲存基本結構
l 在Kafka檔案儲存中,同一個topic下有多個不同partition,每個partition為一個目錄,partiton命名規則為topic名稱+有序序號,第一個partiton序號從0開始,序號最大值為partitions數量減1。l 每個partion(目錄)相當於一個巨型檔案被平均分配到多個大小相等segment(段)資料檔案中。但每個段segmentfile訊息數量不一定相等,這種特性方便oldsegment file快速被刪除。預設保留7天的資料。
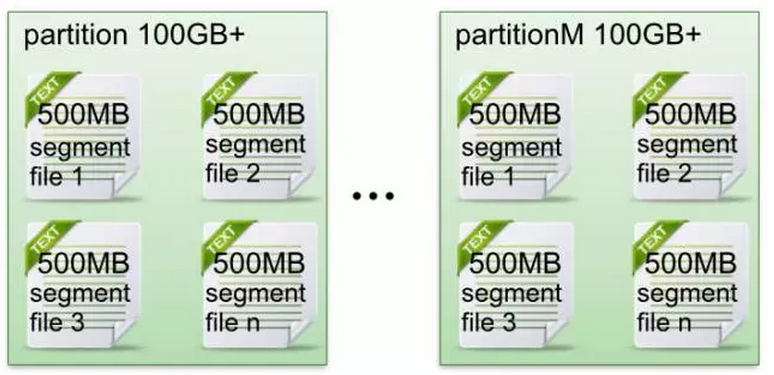
l 每個partiton只需要支援順序讀寫就行了,segment檔案生命週期由服務端配置引數決定。(什麼時候建立,什麼時候刪除)

一個partition的資料是否是有序的? 間隔性有序,不連續
針對一個topic裡面的資料,只能做到partition內部有序,不能做到全域性有序。
特別加入消費者的場景後,如何保證消費者消費的資料全域性有序的?偽命題。
只有一種情況下才能保證全域性有序?就是隻有一個partition。
8.2、Kafka Partition Segment
l Segment file組成:由2大部分組成,分別為index file和data file,此2個檔案一一對應,成對出現,字尾".index"和“.log”分別表示為segment索引檔案、資料檔案。l Segment檔案命名規則:partion全域性的第一個segment從0開始,後續每個segment檔名為上一個segment檔案最後一條訊息的offset值。數值最大為64位long大小,19位數字字元長度,沒有數字用0填充。
l 索引檔案儲存大量元資料,資料檔案儲存大量訊息,索引檔案中元資料指向對應資料檔案中message的物理偏移地址。

3,497:當前log檔案中的第幾條資訊,存放在磁碟上的那個地方
其中以索引檔案中元資料3,497為例,依次在資料檔案中表示第3個message(在全域性partiton表示第368772個message)、以及該訊息的物理偏移地址為497。
l segment data file由許多message組成, qq物理結構如下:

8.3、Kafka 查詢message
讀取offset=368776的message,需要通過下面2個步驟查詢。
8.3.1、查詢segment file
00000000000000000000.index表示最開始的檔案,起始偏移量(offset)為000000000000000368769.index的訊息量起始偏移量為368770= 368769 + 1
00000000000000737337.index的起始偏移量為737338=737337+ 1
其他後續檔案依次類推。
以起始偏移量命名並排序這些檔案,只要根據offset**二分查詢**檔案列表,就可以快速定位到具體檔案。當offset=368776時定位到00000000000000368769.index和對應log檔案。
8.3.2、通過segment file查詢message
當offset=368776時,依次定位到00000000000000368769.index的元資料物理位置和00000000000000368769.log的物理偏移地址然後再通過00000000000000368769.log順序查詢直到offset=368776為止。
(九)、Kafka自定義Partition
package cn.itcast;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import java.util.Properties;
public class MyKafkaProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("metadata.broker.list","mini1:9092");
// 預設的序列化為byte改為string
properties.put("serializer.class","kafka.serializer.StringEncoder");
/**
* 自定義parition的基本步驟
* 1、實現partition類
* 2、加一個構造器,MyPartitioner(VerifiableProperties properties)
* 3、將自定義的parititoner加入到properties中
* properties.put("partitioner.class","cn.itcast.MyPartitioner")
* 4、producer.send方法中必須指定一個paritionKey
*/
properties.put("partitioner.class","cn.itcast.MyPartitioner");
Producer producer = new Producer(new ProducerConfig(properties));
while (true){
producer.send(new KeyedMessage("order4","zhang","我愛我的祖國"));
// producer.send(new KeyedMessage("order","我愛我的祖國"));
}
}
}
package cn.itcast;
import kafka.producer.Partitioner;
import kafka.utils.VerifiableProperties;
public class MyPartitioner implements Partitioner {
public MyPartitioner(VerifiableProperties properties) {
}
public int partition(Object key, int numPartitions) {
return 2;
}
}(十一)、Kafka常用操作命令
• 檢視當前伺服器中的所有topic
bin/kafka-topics.sh --list --zookeeper zk01:2181
• 建立topic
./kafka-topics.sh --create --zookeeper mini1:2181--replication-factor 1 --partitions 3 --topic first
• 刪除topic
sh bin/kafka-topics.sh --delete --zookeeper zk01:2181 --topic test
– 注意:如果kafaka啟動時載入的配置檔案中server.properties沒有配置delete.topic.enable=true,那麼此時的刪除並不是真正的刪除,而是把topic標記為:marked for deletion
– 此時你若想真正刪除它,可以登入zookeeper客戶端,進入終端後,刪除相應節點
• 通過shell命令傳送訊息
kafka-console-producer.sh --broker-list kafka01:9092--topic itheima
• 通過shell消費訊息
sh bin/kafka-console-consumer.sh --zookeeper zk01:2181--from-beginning --topic test1
• 檢視消費位置
sh kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeperzk01:2181 --group testGroup
• 檢視某個Topic的詳情
sh kafka-topics.sh --topic test --describe --zookeeper zk01:2181
12、Flume&Kafka結合應用
• 啟動FLume
– 略
• 啟動Kafka Server ./bin/kafka-server-start.sh config/server.properties
• 傳送訊息
# echo 'XXXX' | nc -u master 8285
• 啟動Consumer進行資料監控
– bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
相關推薦
流式計算--Kafka詳解
理解storm、spark streamming等流式計算的資料來源、理解JMS規範、理解Kafka核心元件、掌握Kakfa生產者API、掌握Kafka消費者API。對流式計算的生態環境有深入的瞭解,具備流式計算專案架構的能力。所以學習kafka要掌握以下幾點
構建流式應用—RxJS詳解
最近在 Alloyteam Conf 2016 分享了《使用RxJS構建流式前端應用》,會後在線上線下跟大家交流時發現對於 RxJS 的態度呈現出兩大類:有用過的都表達了 RxJS 帶來的優雅編碼體驗,未用過的則反饋太難入門。所以,這裡將結合自己對 RxJS
流式計算--kafka1(kafka叢集搭建)
1、Kafka是什麼 在流式計算中,Kafka一般用來快取資料,Storm通過消費Kafka的資料進行計算。KAFKA + STORM +REDIS Kafka是一個分散式訊息佇列:生產者、消費者的功能。它提供了類似於JMS的特性,但是在設計實現上完全不同
流式計算--整合kafka+flume+storm
1.資料流向 日誌系統=>flume=>kafka=>storm 2.安裝flume 1.我們在storm01上安裝flume1.6.0,上傳安裝包 2.解壓到 /export/servers/flume,
java實現spark streaming與kafka整合進行流式計算
背景:網上關於spark streaming的文章還是比較多的,可是大多數用scala實現,因我們的電商實時推薦專案以java為主,就踩了些坑,寫了java版的實現,程式碼比較意識流,輕噴,歡迎討論。流程:spark streaming從kafka讀使用者實時點選資料,過濾資
Jmeter正則表達式提取器詳解
正整數 image $1 默認值 應用 貪婪模式 ria 多次 正則 名稱:次正則提取器的名稱,最好取名唯一且有意義,為了方便與其他正則提取器區分。 Apply to:應用範圍 Main sample and sub_samples Main sample only
Mysql數據庫分布式事務XA詳解
oar 存儲引擎 成了 from get 分布式事務 value ive 進展 XA事務簡介 XA 事務的基礎是兩階段提交協議。需要有一個事務協調者來保證所有的事務參與者都完成了準備工作(第一階段)。如果協調者收到所有參與者都準備好的消息,就會通知所有的事務都可以提交了(第
H264碼流中SPS PPS詳解<轉>
擴展 vlc 地址 逗號 部分 級別 軟件 第一個 bottom 轉載地址:https://zhuanlan.zhihu.com/p/27896239 1 SPS和PPS從何處而來? 2 SPS和PPS中的每個參數起什麽作用? 3 如何解析SDP中
Selenium Grid分布式測試入門詳解
lena 客戶端 odi before ons cycle lean efault 命令 本文對Selenium Grid進行了完整的介紹,從環境準備到使用Selenium Grid進行一次完整的多節點分布式測試。 運行環境為Windows 10,Selenium版本為
大數據入門第十七天——storm上遊數據源 之kafka詳解(一)入門
不同 這也 接受 blog 存儲 發送 records ant post 一、概述 1.kafka是什麽 根據標題可以有個概念:kafka是storm的上遊數據源之一,也是一對經典的組合,就像郭德綱和於謙 根據官網:http://kafka.apa
身份證號碼的正則表達式及驗證詳解(JavaScript,Regex)
新疆 選擇 ade 理學 澳門 如果 span card div 簡言 在做用戶實名驗證時,常會用到身份證號碼的正則表達式及校驗方案。本文列舉了兩種驗證方案,大家可以根據自己的項目實際情況,選擇適合的方案。 身份證號碼說明 居民身份證號碼,正確、正式的稱謂應該是“公民身份
storm 流式計算框架
大數據 storm 流式計算 一:storm 簡介 二:storm 的原理與架構 三:storm 的 安裝配置 四:storm 的啟動腳本 一: storm 的簡介: 1.1 storm 是什麽: 1. Storm是Twitter開源的分布式實時大數據處理框架,被業界稱為實時版Hadoo
Storm簡介——實時流式計算介紹
大數據 bsp 要求 角度 size 計算 spa 流量 使用場景 概念 實時流式計算: 大數據環境下,流式數據將作為一種新型的數據類型,這種數據具有連續性、無限性和瞬時性。是實時數據處理所面向的數據類型,對這種流式數據的實時計算就是實時流式計算。 特
流式計算簡介
1、資料的時效性 日常工作中,我們一般會先把資料儲存在一張表中,然後對這張表的資料進行加工、分析。那這裡是先儲存在表中,那就會涉及到時效性這個概念。 如果我們處理以年,月為單位的級別的資料處理,進行統計分析,個性化推薦,那麼資料的的最新日期離當前有幾個甚至上月都沒有問題。但是如果我們處理的是
hadoop(十三)storm流式計算(實時處理)
storm介紹 說明+安裝文件 Storm是一個開源的分散式實時計算系統,可以簡單、可靠的處理大量的資料流。被稱作“實時的hadoop”。Storm有很多使用
響應式佈局 meta詳解
響應式佈局詳解之head標籤新增的屬性詳解 <meta name="viewport" content="width=device-width,initial-scale=1,maximum-scale=1,user-scalable=no"> 表示:設定螢幕按1
Flink 流式計算框架(學習一)
開源流計算引擎,兼顧效能和可靠性。 Flink資料集型別 有邊資料集:最終不再發生改變 無邊資料集
Java程式設計師從笨鳥到菜鳥之(八十)細談Spring(九)spring+hibernate宣告式事務管理詳解
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
流式計算基礎-1-1
本文介紹:Storm是什麼 目標: 通過該課程的學習能夠了解離線計算與流式計算的區別、掌握Storm框架的基礎知識、瞭解流式計算的一般架構圖。 大綱: 離線計算是
流式計算基礎-2-2
本文名稱: Kafka技術增強 注:請先學習Kafka基礎