
03.SQLServer效能優化之---儲存優化系列
以下內容皆為個人摸索,沒有人專門指導(公司不給力啊!DBA和大牛都木有。。。),所以難免出錯,如有錯誤歡迎指正,小子勇於接受批評~(*^__^*) ~
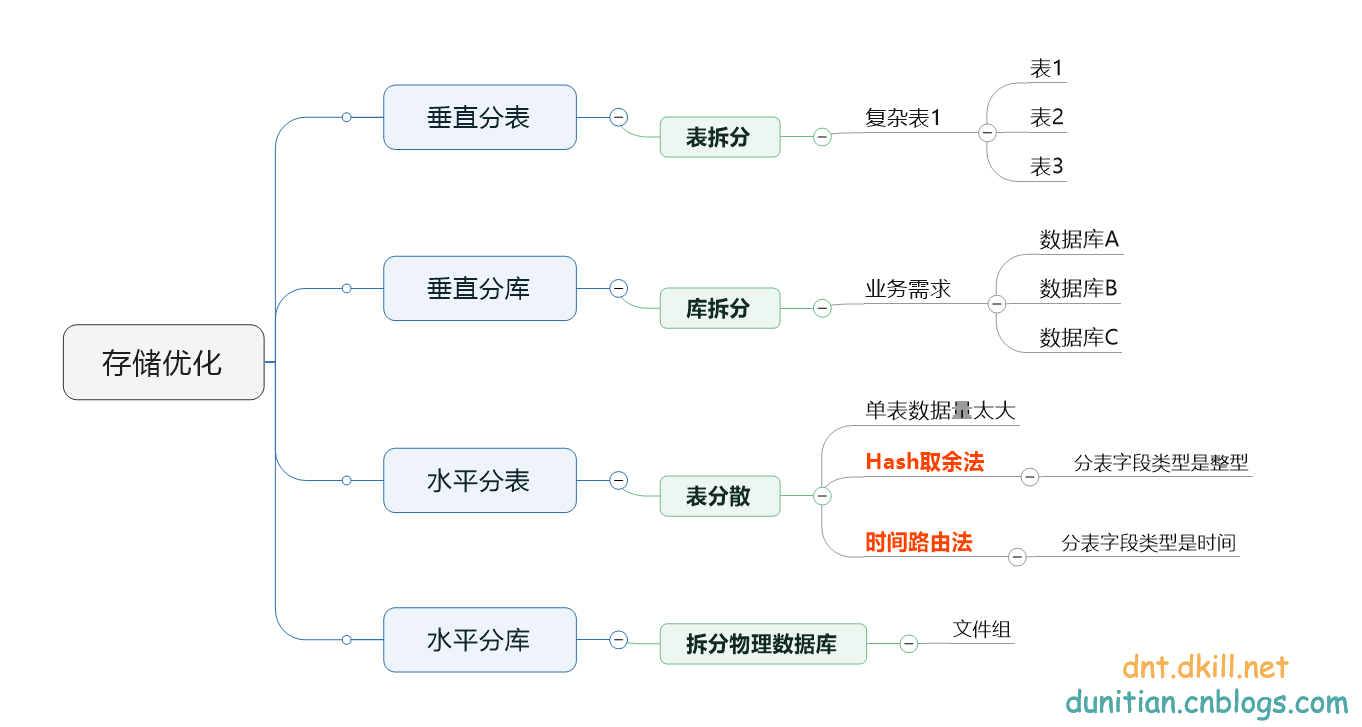
水平分庫分表和垂直分庫分表,大家都經常談,我說下我的理解,看圖:
垂直分表就不用說了,基本上會SQLServer的都會。
垂直分庫就是根據業務需求來分庫,比如教育系列的,可以分為資訊,課程,使用者(學生,學校)三個資料庫。比如電商的可以分為訂單,商品,使用者(商家,消費者)三個資料庫。這邊只是舉個例子,具體的你得根據你們自己業務的實際情況來分,不是分的越多越好,最好是遇到瓶頸了再去做這些事情(這個過程才能學到很多東西)
水平分表主要就兩種方法,Hash取餘法和時間路由法。
我重點說下時間路由的方法,這種方案後期擴容和歷史資料抽離【結合列索引更勁爆哦~】比較方便。舉個簡單的路由表:(時間你可以用傳統的格式,我這邊用的是時間軸)
這個是文章表的時間路由表,每次查詢文章的時候根據查詢的時間看看
比如我現在準備寫入資料,當前時間 2016/11/18 16:37:29 ==》1479458249
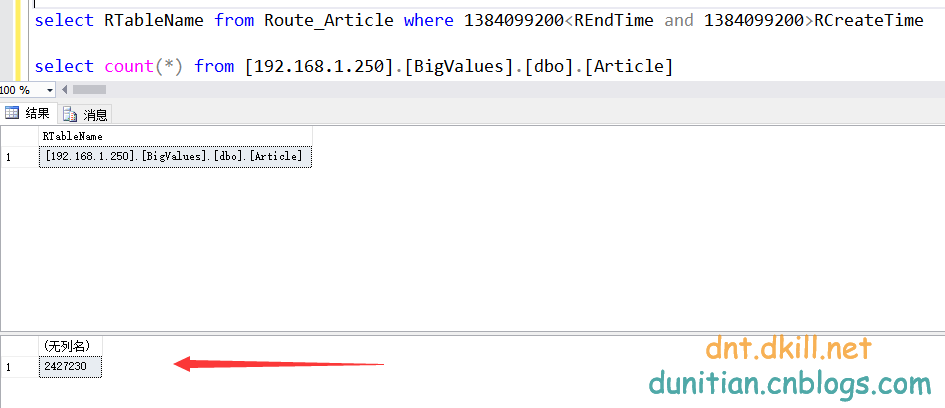
select RTableName from Route_Article where where 1479458249 between RCreateTime and REndTime
就可以知道我應該往哪個表裡面寫資料:==》Article2
同理,想查詢某個時間的資料也是可以通過路由表知道該往哪個表裡面查詢
其實企業裡面用的最多的是複合型的,比如:水平分庫分表 ,水平分庫+垂直分庫+分表
真的有了這方面的瓶頸的話水平分表一般只能緩解,並不能真正解決,畢竟還是在一臺伺服器上。單表的資料量是減少了,但是IO,連線數,頻寬之類的瓶頸並不能有多大的改善。
水平分庫分表可以把IO瓶頸解決一部分,優化效果還是很明顯的:
水平分庫+垂直分庫+分表,這個方案可以利用連結伺服器,這樣路由表就不用改了,把路由表的表名改成完整的名稱(後面會說更好的方法)
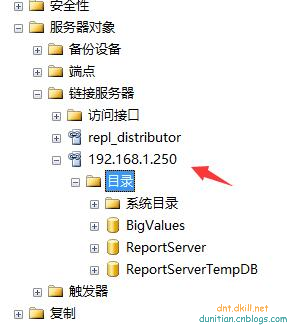
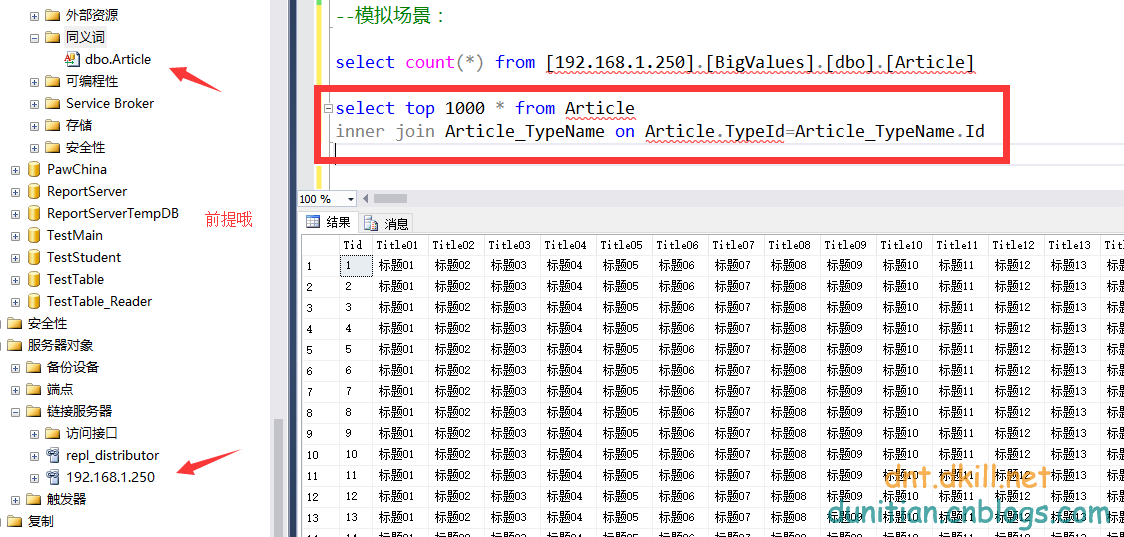
看直觀圖:[192.168.1.250].[BigValues].[dbo].[Article]
我簡單模擬一下:我PC的IP是:192.168.1.9
先在遠端資料庫稍微插點資料:2013-1-1 ~ 2015-1-1的資料,量倒是不多,200W左右
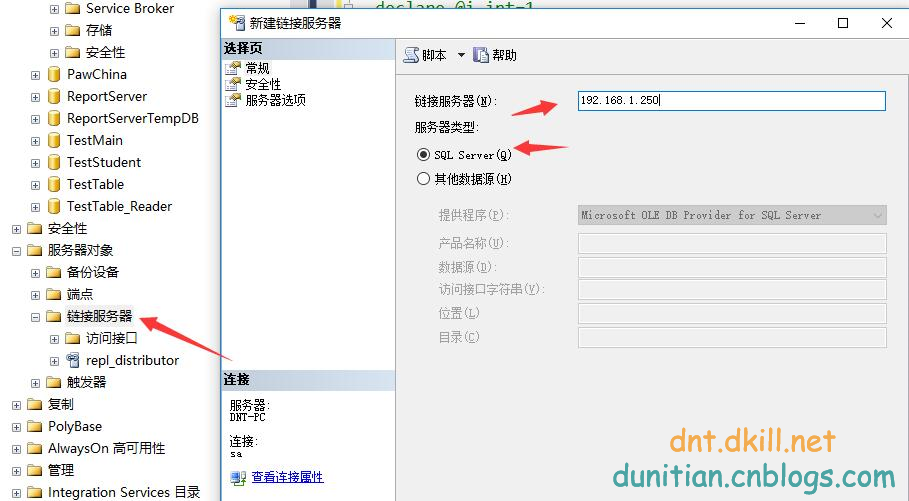
先設定一下連結伺服器。我自己摸索的這個方法可能和網上的不太一樣,不要慌(沒辦法,我按照網上的沒成功啊+_+)
安全性裡面設定一下使用者名稱和密碼
可以了,看看吧:
先看看效果:
這個感覺挺好的,一般情況下都是沒問題的,但是遇到資料庫名字或者表改了就蛋疼了,得改多少東西??關鍵是不太方便,名字那麼長。。。===》so,引入了同義詞
create synonym Article for [192.168.1.250].[BigValues].[dbo].[Article]
再看看效果吧:
-----------------------------------------------------------------------------------------------------
是不是感覺特簡單,也想改革起來了?(⊙o⊙)…,其實我還是建議快到瓶頸的時候再改,不然你會很蛋疼的,現在我就簡單說幾個蛋疼的地方~PS:附帶我的解決方案
簡單說下有哪些問題:
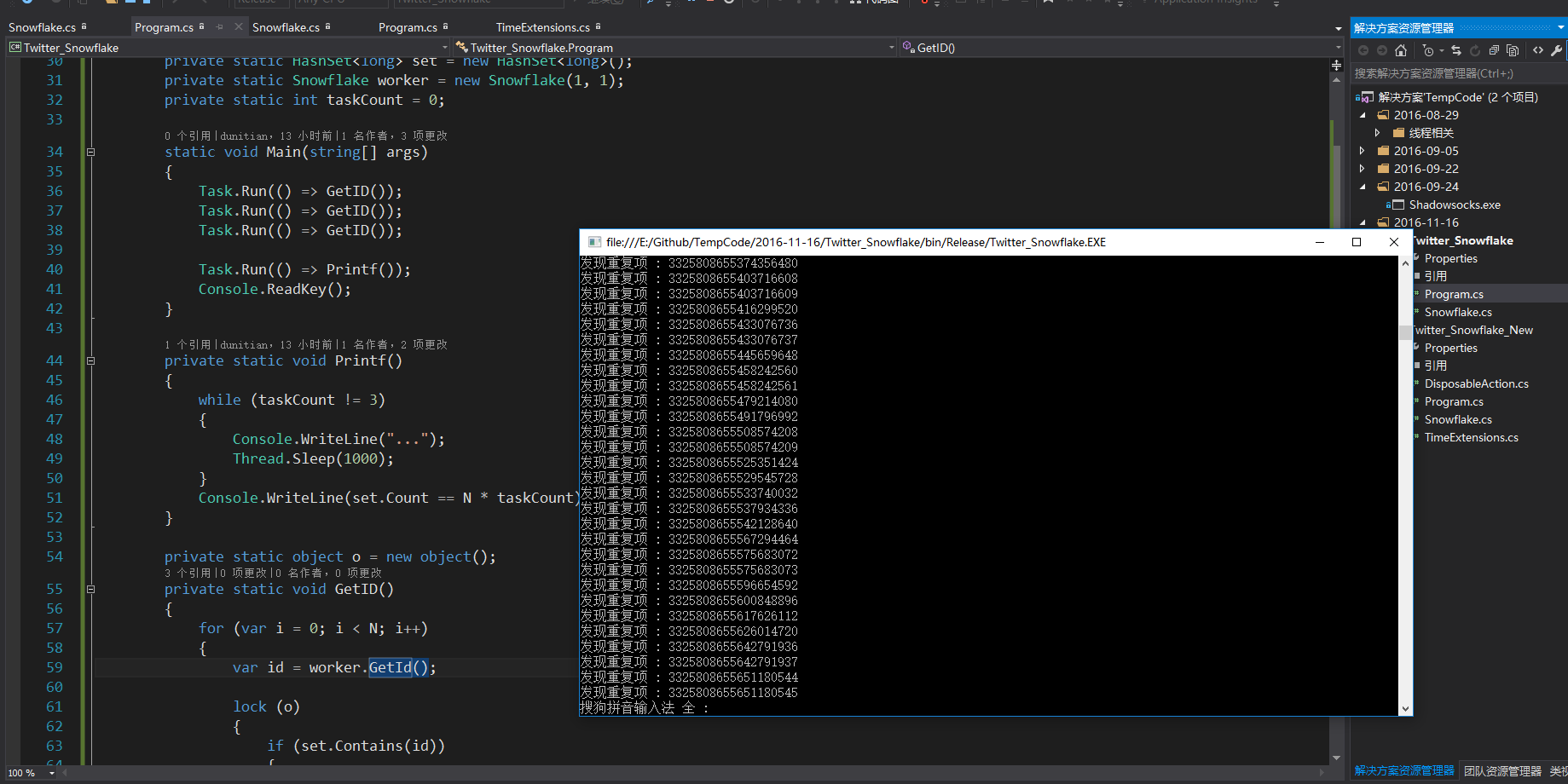
1.全域性ID的問題,既然分表了,那麼第一件事情就是把自增長去掉,(eg:表A,ID為44,表B,ID為44,那我取44的資料時,取哪個呢?)
一開始我是用GUID的方式,一直認為這個不太好,為啥呢,我一般使用者ID或者管理員ID會用GUID,這樣Burp的暴力解猜就比較上門檻了(簡單使用:http://www.cnblogs.com/dunitian/p/5724872.html)
後來發現,GUID的主鍵基本上滿足需求,但是無序列,而且太長了,排序什麼的都各種不方便,後來就找其他方法,很多,比如時間軸,後來發現高併發下還是有重複的(畢竟已經不是單機了)最終採取了雪花演算法(https://github.com/twitter/snowflake)
2.跨庫Join
MySQL比較蛋疼,MSSQL好像沒那麼難,我是用連結伺服器+同義詞的方法解決的(上面演示的),如果有更好方案可以提點一下小子^_^
看圖:
很多時候可以參考MyCat的一些東西,跨庫查詢肯定效率沒有單機高。有時候會做一些處理來儘量避免跨庫Join
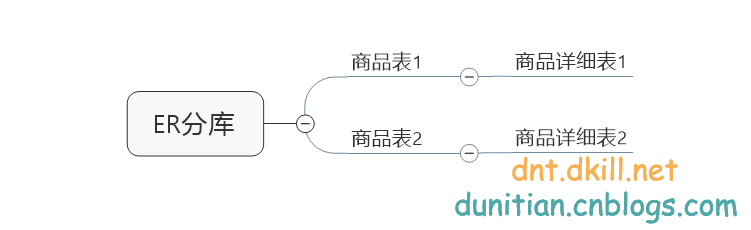
比如說表A,表B,表C...常用的全域性表我會把他們每個資料庫存一遍,這樣就方便多了(注意一下資料同步哦)
還有就是冗餘一些欄位
比如:產品表有這些欄位:商品展圖ID,展圖URL,縮略展圖URL。按理說這是不合理的,但是不這麼幹就得跨庫查詢了,適當犧牲嘛~
再比如:訂單表裡面:使用者ID,使用者名稱,店鋪ID,店鋪名,商品縮略展圖。這樣也是不合理的,但是。。。商品和訂單大家都懂的,牽扯的表太多,有點誇張了~
以後分庫的時候可以參考MyCat的ER分庫 (相關聯的一起分)
3.跨庫排序、聚合等
比如要求Count,那麼每個表都得單獨求一下Count,然後彙總Count。這個過程可以通過應用程式去完成,畢竟可以根據路由表來統一彙總
排序就比較蛋疼了,如果是按時間(分表字段)的還好,因為我們路由表就是按時間分表的,相對簡單。如果按照某個欄位排序的話。。。。。(⊙o⊙)…沒辦法就取每個表裡面的資料吧。
很多人總是疑惑為什麼分頁越往後面越慢(按時間不怕,我們就是按時間分表的,你去對應時間區裡面取就好了)
比如按欄位1排序,每一頁20條資料,要求取第一頁的資料==》
取第五頁的資料==》想想看,這麼搞的話,怎麼不卡?你們有更好的解決方法可以說,小子比較菜O(∩_∩)O
(⊙o⊙)…,最後說下我最近在研究的解決方案:
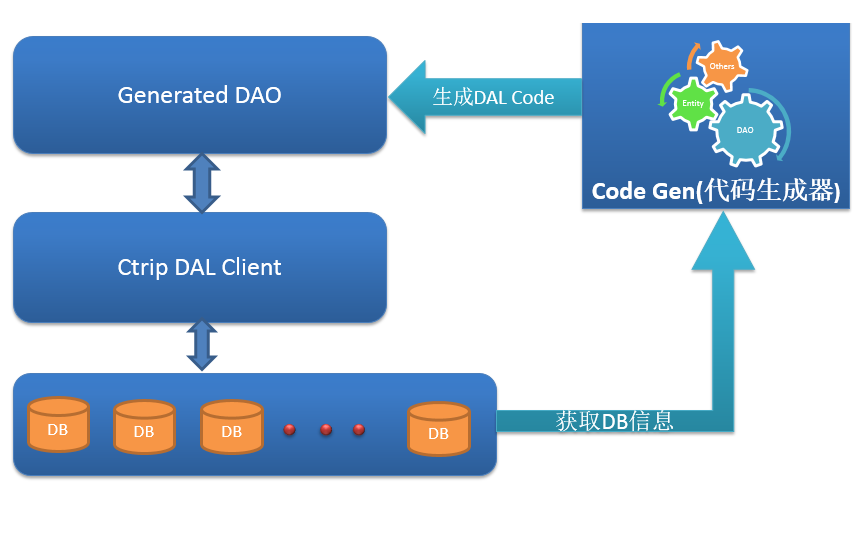
分散式資料庫訪問層:攜程DAL ,支援MySQL,SQLServer。支援Net,Java
Ctrip DAL支援流行的分庫分表操作,支援Java和C#,支援Mysql和MSSqlServer。使用該框架可以在有效地保護企業已有資料庫投資的同時,迅速,可靠地為企業提供資料庫訪問層的橫向擴充套件能力。
這個是後備方案:(下午讓朋友去問了一些MyCat的作者,他說MyCat開發的時候就沒有限定資料庫和開發語言,MySQL,SQLServer都是支援的,換個埠而已,開發語言也沒什麼限制,只要你能連線MyCat就能用)
資料庫中間元件:MyCat (我還沒研究,改天要是可以就發篇文章)












相關推薦
03.SQLServer效能優化之---儲存優化系列
以下內容皆為個人摸索,沒有人專門指導(公司不給力啊!DBA和大牛都木有。。。),所以難免出錯,如有錯誤歡迎指正,小子勇於接受批評~(*^__^*) ~ 水平分庫分表和垂直分庫分表,大家都經常談,我說下我的理解,看圖: 垂直分表就不用說了,基本上會SQLServer的都會。 垂直分庫就是根
效能優化之記憶體優化
效能優化之記憶體優化 計算 APP 獲得的最大記憶體分配值 Runtime rt=Runtime.getRuntime(); long maxMemory=rt.maxMemory(); Log.i("maxMemory:",Long.toString(max
MySQL(三) —— MySQL效能優化之 索引優化
MySQL索引優化 如何選擇合適的列建立索引? 在where從句、group by 從句、order by 從句、on 從句中出現的列 索引欄位越小越好 離散度大的列放在聯合索引的前面 如何判斷列的離散度? 去重查詢看列的唯一值,唯一值越多則離散度越大。 mysql&
Linux效能優化之CPU優化(一)
前言 何為效能優化?個人認為,效能優化是為了提高應用程式或系統能力為目的。那麼如何才能實現對應用程式的效能調優呢?這裡很設計到很多的內容,包括Linux核心、CPU架構以及Linux核心對資源的分配以及管理,瞭解程序的建立過程等。這方面由於篇幅較多,所以我的文章就不過多介紹。接下來的幾篇文章中,
Android效能優化之佈局優化
佈局優化可以通過減少佈局層級來提高,儘量減少使用效能低的佈局,LineaLayout的效率最高,在可以使用LinearLayout或者RelativeLayout時,選擇LinearLayout。因為RelativeLayout測量較為複雜,需要測量水平和
MySQL(三) —— MySQL效能優化之 索引優化
MySQL索引優化 如何檢視mysql資料庫的引擎 一般情況下,mysql會預設提供多種儲存引擎,你可以通過下面的檢視: 看mysql支援哪些儲存引擎: mysql> show engines; mysql> show engines; +--
KVM總結-KVM效能優化之記憶體優化
EPT 技術 大頁和透明大頁 KSM 技術 記憶體限制 EPT技術 EPT也就是擴充套件頁表,這是intel開創的硬體輔助記憶體虛擬化技術。我們知道記憶體的使用,是一個邏輯地址跟實體地址轉換的過程。虛擬機器內部有邏輯地址轉成成實體地址的過程,然後再跳出來,虛擬機器
Unity效能優化之程式碼優化
對於Unity效能優化,目前接觸到的大概有這幾個方面: 1. Draw Call 2. 資源(模型、貼圖、粒子) 3. 渲染(相機、光照、Shader) 4. 網路 5. 程式碼(程式碼編寫、資源載入、物理系統) 可以在Unity自帶的Profiler視窗檢視專案效能消耗主要
2017版:KVM效能優化之CPU優化
前言 任何平臺根據場景的不同,都有相應的優化。不一樣的硬體環境、網路環境,同樣的一個平臺,它跑出的效果也肯定不一樣。就好比一輛法拉利,在高速公路里跑跟鄉村街道跑,速度和激情肯定不同… 所以,我們做運維工作,也是如此。首先你得充分了解你所用的軟體平臺,然後根據你現有的生產環境去充分的測試,最後得出結果
KVM總結-KVM效能優化之CPU優化
前言 任何平臺根據場景的不同,都有相應的優化。不一樣的硬體環境、網路環境,同樣的一個平臺,它跑出的效果也肯定不一樣。就好比一輛法拉利,在高速公路里跑跟鄉村街道跑,速度和激情肯定不同… 所以,我們做運維工作,也是如此。首先你得充分了解你所用的軟體平臺,然後根據你現有的生產環境去充分的測試,最後得出結果,做最
效能優化之佈局優化(ConstraintLayout)
遇到的問題面試的時候,面試官總問我做過效能優化嗎?我這種低階程式設計師當然會說一些基本的防止給自己的挖坑,例如佈局優化啊,減少覆蓋渲染呀啥的,我經常說不要包裹過多的佈局,因為在xml生成view物件的也是需要解析xml解析效率降低,渲染view的層級過多都會導致效能降低,都是
mysql效能優化之配置優化
1、目的: 通過根據伺服器目前狀況,修改MySQL的系統引數,達到合理利用伺服器現有資源,最大合理的提高MySQL效能。 2、伺服器引數: 32G記憶體、4個CPU,每個CPU 8核。 3、MySQL目前安裝狀況。 MySQL目前安裝,用的是MySQL
App效能優化之View優化(2)——UI問題的解決
一.概況 上一篇中App效能優化之View優化(1)——UI問題的檢測主要講的是我們在寫完程式碼之後,如何發現程式碼中的問題。從問題中提取經驗,規範好自己之後的程式碼編寫,本文就是講如何規範的進行UI關聯程式碼的書寫。 二.主要的點 View控制元件
MySQL 資料庫效能優化之索引優化
非常感謝作者。 大家都知道索引對於資料訪問的效能有非常關鍵的作用,都知道索引可以提高資料訪問效率。 為什麼索引能提高資料訪問效能?他會不會有“副作用”?是不是索引建立越多,效能就越好?到底該如何設計索引,才能最大限度的發揮其效能? 這篇文章主要是帶著上面這幾個問題來做一個
Linux效能優化之磁碟優化(三)
前言 關於本章內容,設計的東西比較多。這裡會有關於檔案系統、磁碟、CPU等方面的知識,以及涉及到關於這方面的效能排查等。 術語 檔案系統通過快取和緩衝以及非同步I/O等手段來緩和磁碟的延時對應用程式的影響。為了更詳細的瞭解檔案系統,以下就簡單介紹一些相關術語: 檔案系統:一種把資料組織成檔案和目錄的儲存方式
Linux效能優化之記憶體優化(二)
前言 不知道大家看完前面一章關於CPU優化,是否受到相應的啟發呢?如果遇到任何問題,可以留言和一起探討這方面的問題。接下來我們介紹一些關於記憶體方面的知識。記憶體管理軟體包括虛擬記憶體系統、地址轉換、交換、換頁和分配。與效能密切相關的內容包括:記憶體釋放、空閒連結串列、頁掃描、交換、程序地址空間和記憶體分
效能優化之佈局優化
佈局優化: 1使用抽象標籤 include標籤:用於將公共部分提取出來 viewstub標籤:引入的佈局不顯示也不佔用位置,解析時節省記憶體,主要用於進度佈局、網路失敗顯示的重新整理佈局、資訊出錯出現的提示佈局等,同view的gone merge標籤:使用include時
Android 效能優化之常用優化點
資源類效能分為:磁碟、CPU和記憶體,以及與環境密切相關的網路和因為行動網路而顯得很重要的電池(耗電)。 1、磁碟 1.1 發現定位工具:Strict Mode 和 Systrace。 對於Strict Mode 的原理,主要是在檔案操作(BlockGua
MySQL 資料庫效能優化之SQL優化
有人反饋之前幾篇文章過於理論缺少實際操作細節,這篇文章就多一些可操作性的內容吧。 注:這篇文章是以 MySQL 為背景,很多內容同時適用於其他關係型資料庫,需要有一些索引知識為基礎 優化目標 減少 IO 次數 IO永遠是資料庫最容易瓶頸的地方,這是由資料庫的職責所決
Android 效能優化之記憶體優化
在移動作業系統上,通常實體記憶體有限,儘管 Android 的 Dalvik 虛擬機器扮演了常規的垃圾回收的角色,但這並不意味著我們可以忽略 APP 的記憶體分配與釋放,為了 GC 能夠從 APP 中及時回收記憶體,我們在日常的開發中就需要時刻注意記憶體洩露,並在合適的時候來