
資料庫設計(4)_邏輯結構設計_常用技巧
總結一下這些年在專案中一些設計技巧,有些在前面的章節已經提到過。
一、屬性定義
1.1、資料型別
(1)整型還是字元型
在可以為整型的情況下儘量使用整型,通常情況下整型佔的空間小,可以提高I/O及快取命中率。
(2)定長還是變長字元型
定長的好處(也就是變長的壞處):
a)定長欄位不需要額外維護和計算行偏移量,當然這個成本不是很大,可以忽略;
b)如果用變長的話,很有可能會由於更新行資料而帶來頁拆分,這個成本是很大的;
變長的好處:
節省儲存空間,可以提高I/O及快取命中率;
那究竟使用定長還是變長呢?規則就是:同一屬性列的資料長度有明顯差異、且更新不太頻繁的情況,使用變長字元,否則建議使用定長字元,比如:訂單號、MAC地址,這類長度固定的屬性應該毫不猶豫地使用定長。
(3)資料型別的長度
業務的發展總是會出乎人為意料的,所以不要太小氣,在長度不是太大的情況下,大膽去放大資料型別的長度,比如:把smallint(佔2位元組)改為int(佔4位元組)。
(4)資料型別一致性
避免出現:同一個欄位,在A表中為整型,在B表中為字元型,保證資料型別的一致。
1.2、NULL
建議將所有列都設為not null,原因如下:
(1)記錄中存在允許為null的列時,每次都在讀取該行時都需要去檢查null列是否有值;
(2)索引中不會記錄null值,因為這個值根本不存在,所有無論單表還是多表的查詢中,is null/is not null無法使用索引,關於索引的使用可參見《SQL Server 查詢優化(3)_索引的設計與使用》;
(3)null值無法進行比較運算(比如:單表查詢時id=1/id<>1都得不到id為null的行,多表關聯時null與null也是無法對等的)、數學運算、連線運算等,當然可以通過設定一些選項來改變null的運算行為;
(4)null值除了增加程式處理的邏輯外,還有可能在聚合運算中導致bug,比如:count()和avg(),count(col1)如果col1存在null值,則得到的是非null值的行數,avg()也一樣,用count(*)或count(col2),假設col2不可為空,可以得到真實的行數;
那麼對於屬性列不確定的時候怎麼辦呢?答案就是:使用預設值,比如整型為0,字元使用
N/A或N/V,時間使用1900-01-01 00:00:00,這樣以避免null值的使用。
另外,對於布林型的0、1儘量保持邏輯一致,如:0為FALSE,1為TRUE。
DBMS中之所以引入null,只是為了完善數學模型,即3值邏輯,這個有點像cross join。
1.3、FK(外來鍵)
為保證實體完整性,也就是第2正規化,表中主鍵或唯一鍵是一定要有的,否則就可能出現重複紀錄。那麼外來鍵呢?
通常矛盾在於:參照完整性及實現參照完整性的效能問題。
(1)用外來鍵實現參照完整性,保證資料的一致性;
(2)海量資料的情況下,參照完整性檢查的成本很大;
究竟怎麼使用外來鍵呢?對於海量資料的情況,為保證DML的效率,不建議使用外來鍵,參照完整性可以使用after觸發器或關聯屬性來實現;反之就是在不影響效能、或對效能要求不高的情況下使用外來鍵。
1.4、CHECK
CHECK約束用於檢查域完整性,不建議使用,檢查工作完全可以放到介面上去做,比如:java裡的正則表示式,多麼強大。
目前,能夠想到的不得不用CHECK約束的地方就是分割槽檢視,但分割槽檢視是SQL SERVER沒有分割槽表的時候,一個替代品,所以有了分割槽表就再也沒有使用CHECK約束的理由了。
二、實體、關係表
2.1、屬性
(1)簡單屬性還是複合屬性
舉個例子:銀行卡號一個長串,第一反應,它應該是一個字串,但其實,銀行卡號通常只有後四位才是唯一標識,前面都是銀行編號+開戶行等資訊,那麼這樣完全可以把銀行卡號作為多個整型值來儲存。這要取決於業務規則;
再比如前面提到過的姓名,如果需要國際化時,姓名就要考慮FirstName、MiddleName、LastName欄位,而不能像中國人一樣直接就是一個Name欄位;
(2)是否真的是多值屬性
前面提到過多值屬性需要單獨抽象成實體,但有時,需要辨別是否真的是多值屬性,比如:使用者實體的地址、機器實體的所有元器件列表、小說實體的所有章節,它們都是單值的複合屬性;
(3)備註或者描述
資料表設計應該越簡潔越好,像備註或者描述(remark/description)這樣的欄位,如果可有可無時,最好省掉:一是沒有人真正地去維護它,二是佔儲存空間;
(4)實體還是屬性
舉個例子:《資料庫設計(2)_邏輯結構設計》中1:1關係裡的使用者與汽車。
a)如果業務需求中對於汽車的屬性不作限制,只需要知道汽車編號即可,E-R模型如下圖:
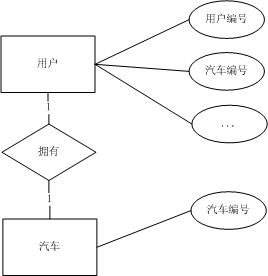
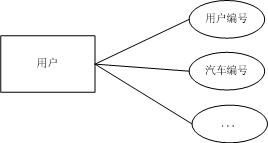
此時可以將使用者與汽車實體合併為一個使用者實體,E-R模型如下圖:
b) 如果業務需求中對於汽車的屬性需要作出描述,比如:產地等,E-R模型如下圖:
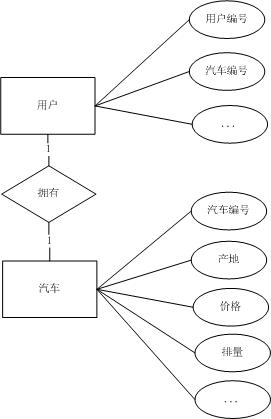
那麼此時就不能實體進行合併,應該獨立描述使用者、汽車實體。
2.2、其他
(1)字典的使用
實體表中的狀態、型別等屬性,如果不是太多,不需要做成字典表。另外、經常變化的元資料不宜作為字典,因為字典這些資訊通常會載入在CACHE中,如果經常變,那就意味著需要經常去更新CACHE。
(2)系統中有哪些使用者
通常需要存在四種使用者:管理員(全部讀寫許可權)、業務操作使用者(部分讀寫許可權)、報表查詢使用者(只讀許可權)、測試使用者(部分讀寫許可權),測試使用者通常供開發人員使用,往往在軟體上線後,需要線上修改一些問題,測試使用者產生的資料,不計入業務資料範圍;
(3)大寫還是小寫
預設ORACLE把所有資料庫物件大寫,如果想指定成小寫或大小寫混寫,需要用”“,但這樣帶來的問題就是在引用這個物件時也要加上”“,很不方便,所以索性全用大寫,這對於異構資料庫的互相訪問很有幫助,比如:從ORACLE訪問SQL SERVER;
另外,在作字元等值比較時,最好使用UPPER/LOWER函式將兩端的字元全轉換成大寫/小寫再作比較;
在後面會分別給出SQL SERVER和ORACLE資料庫的命名和開發規範,
(4)實體行如何刪除
不允許對已發生事實、或建立關係的實體行進行物理刪除,會破壞實體的參照完整性,即使是沒有發生事實、或建立關係的實體行,通常也不進行物理刪除,只是邏輯刪除;
(5)相容B/S和C/S開發方式
設計實體時要考慮到B/S和C/S開發方式的元素,比如:C/S方式中的DLL、FORMNAME、根據B/S的應用使用一些新型的資料型別,比如:XML型別;
(6)資料許可權
除了管理員有所有資料許可權外,資料許可權原則上是誰產生的資料誰有許可權;
(7)如何進行資料同步
資料同步有推、拉兩種方式。
推的方式:在資料發生變化後,立即發出通知給需要更新的點;
拉的方式:由定時任務,定時去資料來源作增量檢查,這種方式就需要在表中建立一個標識增量變化的屬性,比如:時間戳;
(8)不能為了技術而技術
舉個例子:使用者申請編號時,發起申請編號的事務,事務完成時顯示:您申請到的編號為XXX。
但如果併發量較大,即便是採用資料庫自身的序號生成方式(IDENTITY或SEQUENCE),仍然會存在等待,那麼,就可以考慮從客戶端生成此次事務的唯一編號,到資料庫層沒有申請編號的排隊過程,直接寫入;
(9)實體還是關係
舉個例子:《資料庫設計(3)邏輯結構設計常用模組》中許可權實體裡的角色、許可權、控制元件。
a)如果不使用許可權實體,此時許可權通過關係來描述,E-R模型如下圖:

b)如果使用許可權實體,此時許可權以實體來描述,E-R模型如下圖:
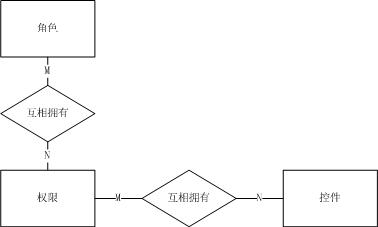
這兩種方式都是可以的,但需要注意的是:一要避免由於實體或關係帶來的資料多次儲存,浪費儲存空間;二要保證資料的一致性;
再重複一次:概念結構設計、邏輯結構設計的結果都不是唯一的。
三、事實
(1)發現及記載事實
在《資料庫設計(2)_邏輯結構設計》中提到過事實的發現,通常,業務相關的事實,通過檢視《需求規格說明書》、與使用者直接交談、自身的行業經驗、問卷調查等方式可以獲得;
但系統業務中用不到或者說暫時用不到的事實,是否就不作記載呢?比如:系統日誌等等,建議在不影響系統性能及使用者體驗的情況下,記載儘量多的事實,日後,它對於做決策分析等這類事情時,會很有幫助;
(2)事實與報表
根據業務需要進行週期性的聚合,產生比如:日報、週報、月報這樣的統計表,而不是等到需要查報表的時候才去事實表中進行彙總;
(3)事實的大類與小類
事實小類即某個具體的業務事實,這點通常都會有事實記載,但有些時候,需要檢視事實大類的明細,是否需要去遍歷各個小類呢?
比如:賬戶事實,大類為進出賬,小類為:充值、提現、消費、利息、扣稅等,如果想要看賬戶的進出賬明細,可以記錄一個賬戶進出賬的大類事實,當中包括進出賬及進出賬的型別,如果想看某一型別的明細,再去小類事實看發生了什麼,比如:消費還可以再分為交電費、交水費、交網費、飯店用餐等,同樣,對於同一小類事實的不同型別,也需要加上型別欄位,比如:消費型別;
再比如:使用者使用系統功能的日誌,大類為使用者操作,小類為:點選各個控制元件所做的事情,如果想要看使用者操作行為,可以記錄一個使用者操作的大類事實,當中包括使用者點選了哪些功能,如果想看某一操作的明細去小類事實看使用者操作的內容;
(4)事實中瞬態屬性
瞬態屬性的記載尤為重要,否則可能會丟失事實的真相,比如:商品的定價、賬戶的卡號等。
相關推薦
資料庫設計(4)_邏輯結構設計_常用技巧
總結一下這些年在專案中一些設計技巧,有些在前面的章節已經提到過。 一、屬性定義 1.1、資料型別 (1)整型還是字元型 在可以為整型的情況下儘量使用整型,通常情況下整型佔的空間小,可以提高I/O及快取命中率。 (2)定長還是變長字元型 定長的
Mysql系列——資料庫設計(4)——實體表之間的關係
幹軟體這一行這麼多年,發現好的程式設計師也更加的好學。 大學時代,舍友放過一個影片,對其中的六度理論印象很深刻。 *六度人脈關係理論(Six Degrees of Separation),是指地球上所有的人都可以通過六層以內的熟人鏈和 任何其他人聯
FPGA學習筆記(六)—— 時序邏輯電路設計
code 是我 使用 param efi sof src img lse 用always@(posedge clk)描述 時序邏輯電路的基礎——計數器(在每個時鐘的上升沿遞增1) 例1.四位計數器(同步使能、異步復位) // Module Nam
從零開始學後端(4)——JDBC的重構設計
重構(Refactoring)就是通過調整程式程式碼,改善軟體的質量、效能,使其程式的設計模式和架構更趨合理,提高軟體的擴充套件性和維護性。 問題1:每個DAO方法中都會寫:驅動名稱/url/賬號/密碼,不利於維護. 如果現在我們從MySQL遷移到Oracle中去,此時就得修
Mysql資料庫學習(4)階段性完結
-- 倒序輸出全部使用者的許可權資訊 SELECT * from users order by powers desc -- 統計女生人數,靈活使用count,看題目要求,你要計算的是什麼? SELECT COUNT(sid) FROM `student` WHERE sse
從零寫分散式RPC框架 系列 1.0 (4)RPC-Client模組設計實現
RPC-Client模組負責建立 動態代理物件 供 服務消費者 使用,而動態代理物件的方法執行則是通過RPC呼叫RPC-Server的服務實現。即RPC-Client遮蔽了底層的通訊過程,使得服務消費者可以基於介面透明使用服務提供者的服務。 系列文章: 從零寫分散式RPC框架 系
計算機組成與設計(二)——算術邏輯運
算術運算 計算機結構的簡化模型(模型機) 演示例項一 以add $8,$9,$10(格式被Latex強行改變,不知道怎麼辦555。。。)演示加法運算 1、首先取指令,即得到得到指令的編碼 查指令編碼表知opcode = 0,function =
java資料庫程式設計(4) 使用execute方法執行SQL語句
Statement的execute()語句可以執行任何SQL語句,但是它比較麻煩,故通常應該使用executeQuery()或者executeUpdate()方法。 使用exrcute()方法執行只是返回boolean值,它表示執行該SQL語句是否返回了ResultSet物
ros中標誌位設計(4)
由於需要涉及控制權的交接事件,需要通過標誌位的方式進行設計。 首先需要自定一個標誌位的資訊在ros中用於標誌位資訊的釋出。 下面是用於標誌位的標頭檔案Flag.h // Generated by gencpp from file xx_msgs/Flag.msg // DO NOT ED
Linux系列(4)- 系統目錄結構
Linux系統目錄結構 登入系統後,輸入cd /,切換到根目錄下,輸入ls,可以看到根目錄下所有的資料夾: 由於CD版的Linux是有桌面應用程式的,也可以在圖形介面中檢視: 目錄結構樹如下(xmind檔案地址): 目錄介紹 /bin:bin是Binary的縮寫,這
資料庫基礎(4)函式依賴公理和推論(Armstrong公理),屬性閉包和求候選鍵的技巧
函式依賴裡面,函式依賴公理,Armstrong公理以及屬性閉包的定義都有必要仔細學習 1.邏輯蘊含基本定義 2.Armstrong公理和推論–可以用來判斷一個函式依賴X -> Y 是否邏輯蘊含
基於dragonboard 410c的智慧魔鏡設計(4)——視訊訊息檢索及自動播放
前面給大家介紹瞭如何自動的檢索指定使用者的文字訊息,並且採用html模板方式在qt控制元件上自動迴圈的播放文字訊息,但是在智慧魔鏡中我們還可以向指定使用者推送視訊訊息,實時顯示視訊訊息,這裡進一步向大家介紹如何在基於dragonboard 410c的智慧魔鏡上實
【20171002】python_語言設計(4)檔案
1.檔案 (1)檔案定義:儲存在外部介質上的資料或資訊集合,有序資訊 (2)文字顯示:計算機顯示功能 (3)編碼:資訊轉化的過程 ASCII碼:7個二進位制位表示128個字元; Unicode編碼:跨語言跨平臺統一且唯一的二進位制編碼,每個字元兩個位元組長,65536個字元的編
Service與Android系統設計(4)-- ServiceManager
System Service的驅動形式 --- ServiceManager 對於ServiceManager的使用,我們在應用程式程式設計時也會經常使用到,比如我們需要使用Sensor時,我們一般會做如下的呼叫: mSensorManager = (SensorMan
資料結構(三):非線性邏輯結構-特殊的二叉樹結構:堆、哈夫曼樹、二叉搜尋樹、平衡二叉搜尋樹、紅黑樹、線索二叉樹
/* 性質1. 節點是紅色或黑色 性質2. 根是黑色 性質3. 每個紅色節點的兩個子節點都是黑色 (從每個葉子到根的所有路徑上不能有兩個連續的紅色節點) 性質4. 從任一節點到其每個葉子的所有路徑都包含相同數目的黑色節點 */ #include #include typedef enum
機器學習回顧篇(4):邏輯迴歸
1 引言 邏輯不邏輯,迴歸非迴歸。 回想當年初次學習邏輯迴歸演算法時,看到”邏輯迴歸“這個名字,第一感覺是這是一個與線性迴歸類似的迴歸類別的演算法,只不過這個演算法突出”邏輯“,或者與某個以”邏輯“命名的知識點有關。可後來卻發現,這是
數據庫設計(一)——數據庫設計
數據庫設計數據庫設計(一)——數據庫設計 一、數據庫設計簡介 按照規範設計,將數據庫的設計過程分為六個階段: A、系統需求分析階段B、概念結構設計階段C、邏輯結構設計階段D、物理結構設計階段E、數據庫實施階段F、數據庫運行與維護階段需求分析和概念結構設計獨立於任何數據庫管理系統。 二、系統需求分析 1、需求分
redis學習(二) redis資料結構介紹以及常用命令
redis資料結構介紹 我們已經知道redis是一個基於key-value資料儲存的資料結構資料庫,這裡的key指的是string型別,而對應的value則可以是多樣的資料結構。其中包括下面五種型別: 1.string 字串 string字串型別是redis最基礎的資料儲存型別。
JavaWeb開發設計(四)高併發方案設計
高併發時要求系統對高QPS併發請求快速處理,並且有足夠的系統容量處理這些資料。 簡單總結一下高併發系統的技術點: 1、請求排程 1)使用CDN CDN即內容分發網路,CDN系統能夠實時地根據網路流量和各節點的連線、負載狀況以及到使用者的距離和響應時間等綜合資訊將使用者的請求重新導向離
JavaWeb開發設計(三)可用性方案設計
可用性方面經驗不足,暫不做總結。 可以先看這篇文章 https://blog.csdn.net/hustspy1990/article/details/78008324 簡單列一下要點: 1、常見高可用問題和解決措施 1)機器、機房故障。通過硬體冗餘、多機