
Python模擬登入(一) requests.Session應用
最近由於某些原因,需要用到Python模擬登入網站,但是以前對這塊並不瞭解,而且目標網站的登入方法較為複雜, 所以一下卡在這裡了,於是我決定從簡單的模擬開始,逐漸深入地研究下這塊。
注:本文僅為交流學習所用。
登入特點:明文傳輸,有特殊標誌資料
會話物件requests.Session能夠跨請求地保持某些引數,比如cookies,即在同一個Session例項發出的所有請求都保持同一個cookies,而requests模組每次會自動處理cookies,這樣就很方便地處理登入時的cookies問題。在cookies的處理上會話物件一句話可以頂過好幾句urllib模組下的操作。即相當於urllib中的:
| 1 2 3 4 |
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
urllib.request.install_opener(opener)
|
模擬登入V站
本篇文章的任務是利用request.Session模擬登入V2EX(http://www.v2ex.com/)這個網站,即V站。
工具: Python 3.5,BeautifulSoup模組,requests模組,Chrome
這個網站登入的時候抓到的資料如下:
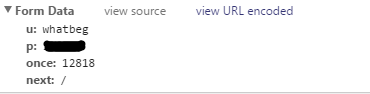
其中使用者名稱(u)、密碼(p)都是明文傳輸的,很方便。once的話從分析登入URL: http://www.v2ex.com/signin 的原始檔(下圖)可以看出,應該是每次登入的特有資料,我們需要提前把它抓出來再放到Form Data裡面POST給網站。

抓出來還是老方法,用BeautifulSoup神器即可。這裡又學到一種抓標籤裡面元素的方法,比如抓上面的"value",用soup.find('input',{'name':'once'})['value']即可
即抓取含有 name="once"的input標籤中的value對應的值。
於是構建postData,然後POST。
怎麼顯示登入成功呢?這裡通過訪問 http://www.v2ex.com/settings 即可,因為這個網址沒有登入是看不了的:
經過上面的分析,寫出原始碼(參考了alexkh的程式碼):
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import requests
from bs4 import BeautifulSoup
url = "http://www.v2ex.com/signin"
UA = "Mozilla/5.0
(Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.13 Safari/537.36"
header = { "User-Agent" :
UA,
"Referer": "http://www.v2ex.com/signin"
}
v2ex_session = requests.Session()
f = v2ex_session.get(url,headers=header)
soup = BeautifulSoup(f.content,"html.parser")
once = soup.find('input',{'name':'once'})['value']
print(once)
postData = { 'u': 'whatbeg',
'p': '*****',
'once':
once,
'next': '/'
}
v2ex_session.post(url,
data = postData,
headers = header)
f = v2ex_session.get('http://www.v2ex.com/settings',headers=header)
print(f.content.decode())
|
然後執行發現成功登入:

上面趴下來的網頁原始碼即為http://www.v2ex.com/settings的程式碼。這裡once為91279.
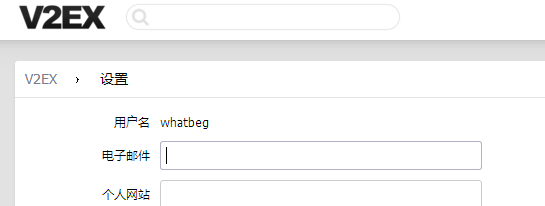
至此,登入成功。
相關推薦
Python模擬登入(一) requests.Session應用
最近由於某些原因,需要用到Python模擬登入網站,但是以前對這塊並不瞭解,而且目標網站的登入方法較為複雜, 所以一下卡在這裡了,於是我決定從簡單的模擬開始,逐漸深入地研究下這塊。 注:本文僅為交流學習所用。 登入特點:明文傳輸,有特殊標誌資料 會話物件re
Python模擬登入豆瓣網,並爬取小組信息
count alias pass spa .post windows chrome apr ror import requests from bs4 import BeautifulSoup from PIL import Image headers = { ‘
Python模擬登入多種實現方式
Python模擬登入多種實現方式 基於Python 3.6 #coding:utf-8 import sys import io import urllib.request import http.cookiejar ################## 第一種登陸方式
python模擬登入豆瓣
from urllib.request import urlretrieve import requests from bs4 import BeautifulSoup from os import remove import http.cookiejar as cook
python模擬登入新浪微博自動獲得呼叫新浪api所需的code
其中client_id是我們的APP_KEY;redirect_url是我們的回撥頁面,就是我們一開始建立應用時設定的;regCallback具體我不知道是哪來的,但是其中有兩個變數,一個是APP_KEY,一個就是我們設定的回撥頁面;其它的表單內容都是固定的。請求程式碼如下:fields={ 'act
python模擬登入寧波大學郵箱
import requests params ={ 'action:login': '', 'uid': '這裡是學號', 'password': '這裡是密碼', 'locale': 'zh_CN' } header
Python 模擬登入知乎
前言 前天看到一個爬取了知乎50多萬評論的帖子, 羨慕的同時也想自己來嘗試一下。看看能不能獲取一些有價值的資訊。 必備知識點 下面簡單的來談談我對常見的防爬蟲的一些技巧的理解。 headers 現在很多伺服器都對爬蟲進行了限制,有一個
選修課有很多有趣的!用Python模擬登入學校教務系統搶課!
最近學校開始選課,但是如果選課時間與自己的事情衝突,這時候就可以使用Python指令碼自助搶課,搶課的第一步即是模擬登入,需要模擬登入後儲存登入資訊然後再進行操作。把css 圖片之類的過濾掉,發現了default.aspx這個東西如果你們學校教務系統不使用Cookie則會是這
Scrapy模擬登入抓資料基本應用
# coding=utf-8 import scrapy from scrapy.selector import Selector class LoginSpidersPyw(scrapy.Spider): #scrapy crawl LoginSpiders
Python模擬登入淘寶
最近想爬取淘寶的一些商品,但是發現如果要使用搜索等一些功能時基本都需要登入,所以就想出一篇模擬登入淘寶的文章! 看了下網上有很多關於模擬登入淘寶,但是基本都是使用scrapy、pyppeteer、selenium等庫來模擬登入,但是目前我們還沒有講到這些庫,只講了requests庫,那我們今天就來使用req
Python-requests-知乎模擬登入
繼續我的python爬蟲旅程,開始寫部落格的時候,說一天一篇,真的只是動動嘴皮子,做起來還真的難,其實是自己給自己找理由… 不管怎樣,今天來更新一篇,寫個知乎的模擬登入,感覺最開始學習爬蟲的時候,大家都期盼著可以寫那種需要登入的網站,或者有各種驗證碼的,那時
Python入門:模擬登入(二)或註冊之requests處理帶token請求
首先說一下使用python模擬登入或註冊時,對於帶token的頁面怎麼登入註冊模擬的思路: 1、對於帶token的頁面,需要先從最開始的頁面獲取合法token 2、然後使用獲取到的合法token進行
Python入門:模擬登入(一)urllib
我們很多時候需要用python寫測試web的指令碼,但現在很多網站都需要登入才能進行下一步操作的,所以python模擬登入在我們的日常操作中很重要,下來我給大家簡單介紹一下python是怎樣實現web登
Python爬蟲學習4:requests.post模擬登入豆瓣(包括獲取驗證碼)
1. 在豆瓣登入網頁嘗試登入後開啟開發者工具,可以查詢後去Headers和Form Data資訊。2. 實現程式碼import requests import html5lib import re from bs4 import BeautifulSoup s = re
python第一百一十八天---ajax--圖片驗證碼 + Session
console lte 狀態 狀態碼 創建 ins .py 上層 成功 原生AJAX Ajax主要就是使用 【XmlHttpRequest】對象來完成請求的操作,該對象在主流瀏覽器中均存在(除早起的IE),Ajax首次出現IE5.5中存在(ActiveX控件)。 1、X
python django學習一:簡單註冊/登陸/session
rfi bmi ews exception eth mar %u objects 未使用 註冊 登陸 session user.html 未使用{{useform}}而使用{{ userform.password }}形式便於後期css樣式 <!DOCTYPE htm
python 爬蟲(一) requests+BeautifulSoup 爬取簡單網頁代碼示例
utf-8 bs4 rom 文章 都是 Coding man header 文本 以前搞偷偷摸摸的事,不對,是搞爬蟲都是用urllib,不過真的是很麻煩,下面就使用requests + BeautifulSoup 爬爬簡單的網頁。 詳細介紹都在代碼中註釋了,大家可以參閱。
python中requests的應用
方式一 response = requests.request(method, url, **kwargs) r = requests.request('GET', url, **kwargs) r = requests.request('HEAD', url, **kwargs) r = r
教務系統模擬登入與成績爬取一
版權宣告:本文為博主原創文章,轉載 請註明出處 https://blog.csdn.net/sc2079/article/details/82563854 -寫在前面 暑假期間學校的學生教務系統大改,好多以前的微信公共號的爬蟲都不能用了。想快速查成績怎麼辦呢?哎,自己動手豐
python requests,bs4應用例項
獲取豆瓣最新電影的ID號和電影名稱 import requests from bs4 import BeautifulSoup url = "https://movie.douban.com/cinema/nowplaying/xian/" # 1). 獲取頁面資訊 response