
深度對抗學習在影象分割和超解析度中的應用
深度學習已經在影象分類、檢測、分割、高解析度影象生成等諸多領域取得了突破性的成績。但是它也存在一些問題。首先,它與傳統的機器學習方法一樣,通常假設訓練資料與測試資料服從同樣的分佈,或者是在訓練資料上的預測結果與在測試資料上的預測結果服從同樣的分佈。而實際上這兩者存在一定的偏差,比如在測試資料上的預測準確率就通常比在訓練資料上的要低,這就是過度擬合的問題。
另一個問題是深度學習的模型(比如卷積神經網路)有時候並不能很好地學到訓練資料中的一些特徵。比如,在影象分割中,現有的模型通常對每個畫素的類別進行預測,畫素級別的準確率可能會很高,但是畫素與畫素之間的相互關係就容易被忽略,使得分割結果不夠連續或者明顯地使某一個物體在分割結果中的尺寸、形狀與在金標準中的尺寸、形狀差別較大。
對抗學習
對抗學習(adversarial learning)就是為了解決上述問題而被提出的一種方法。學習的過程可以看做是我們要得到一個模型(例如CNN),使得它在一個輸入資料X上得到的輸出結果
用於影象分割
Semantic Segmentation using Adversarial Networks (
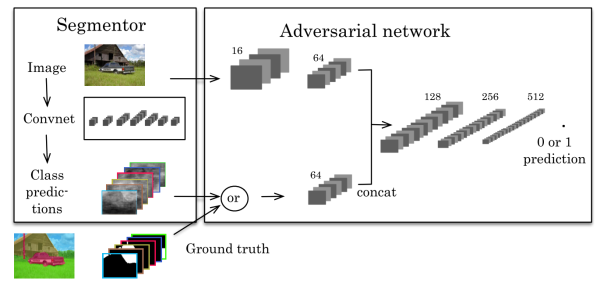
左邊是一個CNN的分割模型,右邊是一個對抗網路。對抗網路的輸入有兩種情況,一是原始影象+金標準,二是原始影象+分割結果。它的輸出是一個分類值(1代表它判斷輸入是第一種情況,0代表它判斷輸入是第二種情況)。代價函式定義為:
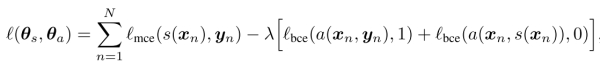
其中
訓練過程中,交替訓練對抗模型(
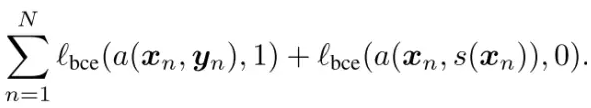
使該函式最小化,得到效能儘可能好的判別器,即對抗模型。訓練分割模型的代價函式為:
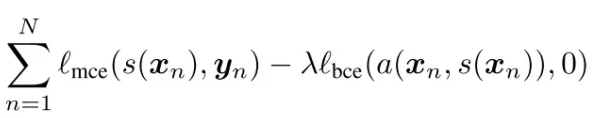
一方面使

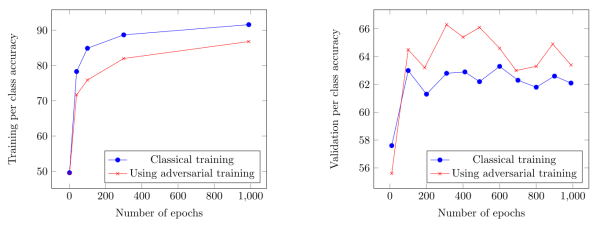
另外從訓練過程中的效能上也可以看出,使用對抗訓練,降低了過度擬合。
用於半監督學習
An Adversarial Regularisation for Semi-Supervised Training of Structured Output Neural Networks(arxiv, 8 Feb 2017)這篇文章中使用對抗網路來做影象分割的半監督學習。半監督學習中一部分資料有標記,而另一部分資料無標記,可以在準備訓練資料的過程中節省大量的人力物力。
假設
訓練過程的代價函式為
該代價函式使分割演算法在標記資料和未標記資料上得到儘可能一致的結果。整個演算法可以理解成通過使用未標記資料,實現對分割網路的引數的規則化。
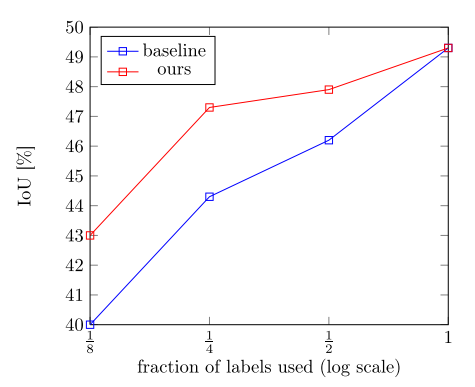
上圖是在CamVid資料集上分別使用1/8, 1/4, 1/2 和1/1的標記資料進行訓練的結果。相比於藍線只使用標記資料進行訓練,該方法得到了較大的效能提高,如紅線所示。
用於域適應
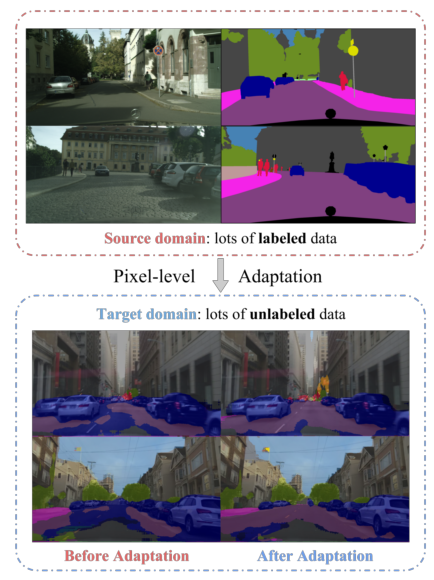
FCNs in the Wild: Pixel-level Adversarial and Constraint-based Adaptation(arxiv, 8 Dec 2016 )這篇文章將對抗學習用到基於域適應的分割中。域適應是指將在一個數據集上A訓練得到的模型用到與之類似的一個數據集B上,這兩個資料集的資料分佈有一定的偏移(distribution shift),也叫做域偏移(domain shift)。A 被稱為源域 source domain,B被稱為目標域 target domain。源域中的資料是有標記的,而目標域的資料沒有標記,這種問題就被稱為非監督域適應。該文章要解決的問題如下圖所示:
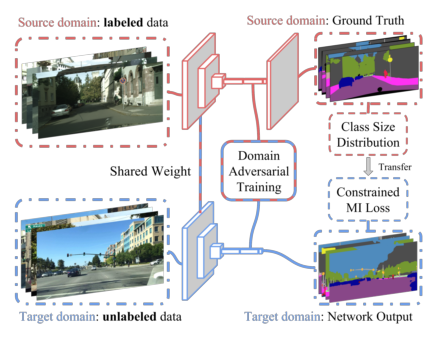
該文章中認為一個好的分割演算法應該對影象是來自於源域還是目標域不敏感。具體而言就是從輸入影象中提取的抽象特徵不受域之間的差異影響,因此從源域中的影象提取的抽象特徵與從目標域中的影象提取的抽象特徵很接近。那麼如果用一個判別器來判斷這個抽象特徵是來自於源域中的影象還是來自於目標域中的影象,這個判別器應該儘量無法判斷出來。方法的示意圖如下:
該文章認為有兩個方面引起了域之間的偏移,一個是全域性性的,比如不同天氣狀況下的街道場景,一個是與特定的類別相關的 ,比如不同國家城市之間的交通標誌。 因此在代價函式中考慮了這兩種情況:
其中第一項是通常的監督學習的代價函式。第二項是對抗學習的目標函式,該函式又包括兩個最小化過程,一個是更新特徵提取網路,使得從兩個域中的影象提取的特徵接近從而判別器無法區分,一個是更新判別器引數,是它能儘可能區分兩個域中的影象的特徵。
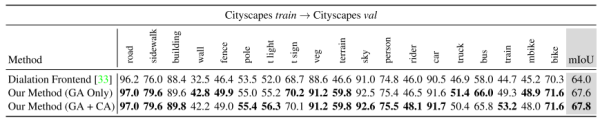
上圖是在Cityscapes資料集上的結果。實驗中把訓練集作為源域,驗證集作為目標域,分別展示了只使用全域性性的域適應(GA)和類別特異性域適應(CA)的結果。
高解析度影象重建
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (arxiv, 21 Nov, 2016)這篇文章將對抗學習用於基於單幅影象的高分辨重建。基於深度學習的高解析度影象重建已經取得了很好的效果,其方法是通過一系列低解析度影象和與之對應的高解析度影象作為訓練資料,學習一個從低解析度影象到高解析度影象的對映函式,這個函式通過卷積神經網路來表示。
傳統的方法一般處理的是較小的放大倍數,當影象的放大倍數在4以上時,很容易使得到的結果顯得過於平滑,而缺少一些細節上的真實感。這是因為傳統的方法使用的代價函式一般是最小均方差(MSE),即
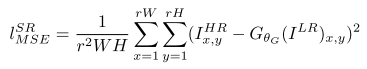
該代價函式使重建結果有較高的信噪比,但是缺少了高頻資訊,出現過度平滑的紋理。該文章中的方法提出的方法稱為SRGAN, 它認為,應當使重建的高解析度影象與真實的高解析度影象無論是低層次的畫素值上,還是高層次的抽象特徵上,和整體概念和風格上,都應當接近。整體概念和風格如何來評估呢?可以使用一個判別器,判斷一副高解析度影象是由演算法生成的還是真實的。如果一個判別器無法區分出來,那麼由演算法生成的影象就達到了以假亂真的效果。
因此,該文章將代價函式改進為
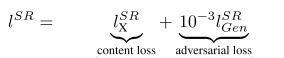
第一部分是基於內容的代價函式,第二部分是基於對抗學習的代價函式。基於內容的代價函式除了上述畫素空間的最小均方差
深度學習已經在影象分類、檢測、分割、高解析度影象生成等諸多領域取得了突破性的成績。但是它也存在一些問題。首先,它與傳統的機器學習方法一樣,通常假設訓練資料與測試資料服從同樣的分佈,或者是在訓練資料上的預測結果與在測試資料上的預測結果服從同樣的分佈。而實際上這兩者
影象分割
深度學習尤其是卷積神經網路在影象處理的許多領域都獲得了很大的成功,在分類,識別等方面都已經獲得了很大的成功.在深度學習把影象分類和識別達到極致之後。深度學習開始在影象分割方面開始進行收割了。影象分割的意思就是對於影象中每個畫素進行分類操作。
超解析度技術(Super-Resolution, SR)是指從觀測到的低解析度影象重建出相應的高解析度影象,在監控裝置、衛星影象和醫學影像等領域都有重要的應用價值。
本文針對端到端的基於深度學習的單張影象超解析度方法(Single Image Super-Resolutio
原文地址:https://blog.csdn.net/abluemouse/article/details/78710553一篇綜述性質的文章,寫的很好。超解析度技術(Super-Resolution, SR)是指從觀測到的低解析度影象重建出相應的高解析度影象,在監控裝置、衛
第一部分
超解析度技術(Super-Resolution, SR)是指從觀測到的低解析度影象重建出相應的高解析度影象,在監控裝置、衛星影象和醫學影像等領域都有重要的應用價值。
本文針對端到端的基於深度學習的單張影象超解析度方法(Single Image Super-R
超解析度技術(Super-Resolution, SR)是指從觀測到的低解析度影象重建出相應的高解析度影象,在監控裝置、衛星影象和醫學影像等領域都有重要的應用價值。本文針對端到端的基於深度學習的單張影象超解析度方法(Single Image Super-Resolutio
轉自github,感謝作者mrgloom的整理
Awesome Semantic Segmentation
Networks by architecture
Semantic segmentation
Instance aware segmentation
分水嶺演算法是比較經典的影象分割演算法。最近看到一副區域檢測和統計的影象,感覺可以通過分水嶺演算法進行實現,於是順便對opencv的分水嶺演算法進行學習。如圖需要分割的影象:
opencv有自帶的分水嶺分割示例,分割影象為硬幣影象,如圖:
由於示例是
當前我們API的內部關聯性都是通過主鍵來代表的,接下來我們要通過超連結的方式來提高內聚和可發現性,意思就是提高關聯性!
給我們API的根目錄建立一個endpoint
找到了endpoint原始碼貼一下:
@property
def
作為行業新人,寫這邊文章主要就是告訴大家學習的時候看看哪些書,這樣其他想入坑的可以少走一些彎路。
就影象來說,岡薩雷斯的《數字影象處理》肯定是必看的,看完這本後,如果還有餘力,可以看看《影象處理、分析與機器視覺》這本書,說實話,這本書真的蠻難的,
背景:
超解析度挑戰賽Super Resolution Challenges (e.g. NTIRE) 降取樣(downscaling)- bicubic interpolation- 是利用Matlab的imresize()函式實現的。
Track info: Track 1:
自己視野狹小,不敢說全部,只是把自己熟悉的方向中的部分經典文章列出來了。經典的論文,讀得怎麼透都不過分。有人說關於配準的文章太多了,其實我也不太關注這方面,不過由於它們引用率都比較高,就都列出來了,不過在zip包裡一篇都沒有。不關注這方面的可以無視之。
文件和論文下載地址:
最近開展影象超解析度( Image Super Resolution)方面的研究,做了一些列的調研,並結合本人的理解總結成本博文~(本博文僅用於本人的學習筆記,不做商業用途)
本博文涉及的paper已經打包,供各位看客下載哈~h
以上就是卷積神經網路的最基礎的知識了,下面我們一起來看看CNN都是用在何處並且如何使用,以及使用原理,本人還沒深入研究他們,等把基礎知識總結完以後開始深入研究這幾個方面,然後整理在寫成部落格,最近的安排是後面把自然語言處理總結一下,強化學習的總結就先往後推一下。再往後是系統的學習一下演算法和資料
單影象超解析度技術涉及到增加小影象的大小,同時儘可能地防止其質量下降。這一技術有著廣泛用途,包括衛星和航天影象分析、醫療影象處理、壓縮影象/視訊增強及其他應用。我們將在本文藉助三個深度學習模型解決這個問題,並討論其侷限性和可能的發展方向。
我們通過網頁應用程式的形式部署
超解析度技術(Super-Resolution)是指從觀測到的低解析度影象重建出相應的高解析度影象,在監控裝置、衛星影象和醫學影像等領域都有重要的應用價值。SR可分為兩類:從多張低解析度影象重建出高解析度影象和從單張低解析度影象重建出高解析度影象。基於深度學習的SR,主要是基
三.Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network(ESPCN)
0.亮點:直接在低解析度圖上進行處理,比
非寧靜無以致遠。
我們在之前兩篇部落格,深度學習應用到影象超解析度重建1, 深度學習應用到影象超解析度重建2已經介紹了一些影象超分辨的基礎了, 下面我們繼續分享一些最新的一些論文。之前只是想稍微簡單介紹一下每一篇文章,但是寫著寫著發現寫的越來越多,聯想的就越來越多了。將所有
超解析度技術(Super-Resolution)是指從觀測到的低解析度影象重建出相應的高解析度影象,在監控裝置、衛星影象和醫學影像等領域都有重要的應用價值。SR可分為兩類:從多張低解析度影象重建出高解析度影象和從單張低解析度影象重建出高解析度影象。基於深度學習的SR,主要是基
二.Deeply-Recursive Convolutional Network for Image Super-Resolution(DRCN),CVPR2016
0.亮點:使用遞迴網路,不增加引數的情況下增加感受野。SRCNN感受野13*13,DRCN感受野為41*41 相關推薦
深度對抗學習在影象分割和超解析度中的應用
基於深度學習的影象分割和keras 的實現
總結深度學習端到端超解析度方法發展歷程
從SRCNN到EDSR,總結深度學習端到端超解析度方法發展歷程
總結深度學習端到端超解析度方法
從SRCNN到EDSR,總結深度學習端到端超解析度方法發展歷程(轉)
深度學習 影象分割開原始碼(附連結,超級全)
Opencv學習——影象分割之分水嶺演算法
Django 之REST framework學習5:關聯性和超連結API(Relationships & Hyperlinked APIs)
如何學習影象處理和三維重建
【超解析度】超解析度中的imresize函式(python, Matlab)
影象處理和計算機視覺中的經典論文(部分)
學習筆記之——基於深度學習的影象超解析度重構
深度學習 --- CNN的變體在影象分類、影象檢測、目標跟蹤、語義分割和例項分割的簡介(附論文連結)
深度學習在單影象超解析度上的應用:SRCNN、Perceptual loss、SRResNet
深度學習在影象超解析度重建中的應用
深度學習用於影象超解析度重建的經典paper彙總(3)
深度學習應用到影象超解析度重建3
深度學習應用到影象超解析度重建
深度學習用於影象超解析度重建的經典paper彙總(2)