
MySQL Innodb資料庫效能實踐——熱點資料效能
對於大部分的應用來說,都存在熱點資料的訪問,即:某些資料在一定時間內的訪問頻率要遠遠高於其它資料。
常見的熱點資料有“最新的新聞”、“最熱門的新聞”、“下載量最大”的電影等。
為了瞭解MySQL Innodb對熱點資料的支援情況,我進行了基準測試,測試環境如下:
【硬體配置】
|
硬體 |
配置 |
|
CPU |
Intel(R) Xeon(R) CPU E5620 主頻2.40GHz, 物理CPU 2個,邏輯CPU 16個 |
|
記憶體 |
24G(6塊 * 4G DDR3 1333 REG) |
|
硬碟 |
300G * 3個,SAS硬碟 15000轉,無RAID,有RAID卡,且開了回寫功能 |
|
OS |
RHEL5 |
|
MySQL |
5.1.49/5.1.54 |
|
配置項 |
配置 |
|
innodb_buffer_pool_size |
4G |
|
innodb_log_file_size |
200M |
|
innodb_log_files_in_group |
3 |
|
sync_binlog |
100 |
|
innodb_flush_log_at_trx_commit |
2 |
【熱點資料模型】
為了模擬熱點資料主要儲存在記憶體中的情況,使用範圍查詢將前20%資料作為熱點資料載入到記憶體,例如:SELECT COUNT(*) FROM BT_KV_SHORT_INT_CHAR_10KW WHERE col1 < 20000000
|
專案 |
模型 |
|
表記錄數 |
1KW(3G),2KW(6G),5KW(15G),10KW(30G) |
|
Key |
INT |
|
Value |
CHAR(250) |
|
熱點資料 |
佔總資料20% |
效能測試結果如下:
【查詢】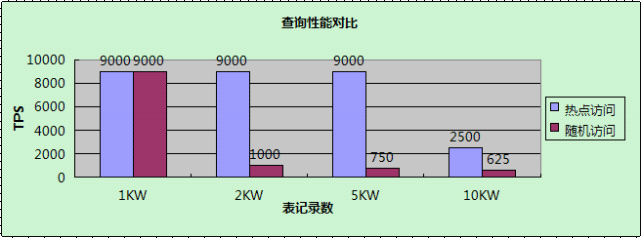
詳細分析如下:
==>當熱點資料小於Innodb buffer pool時(1KW/2KW/5KW),查詢操作的效能很高,和表資料小於Innodb buffer pool時的效能相近;
==> 當熱點資料大於Innodb buffer pool時(10KW),查詢的效能下降明顯;
==> 熱點資料訪問的總體效能優於隨機訪問;
【插入】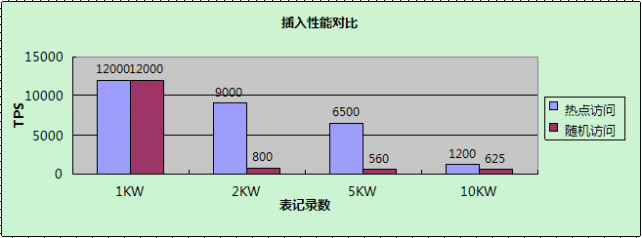
詳細分析如下:
==>
==>當熱點資料超過Innodb buffer pool後(10KW),效能急劇下降,原因是磁碟IO已經成為效能瓶頸;
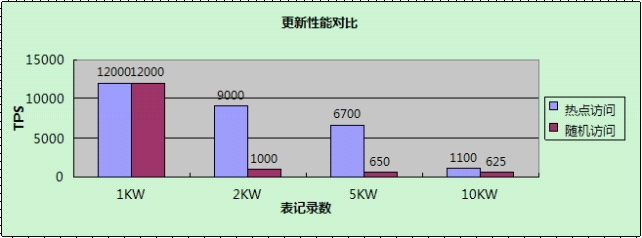
分析同INSERT。
【刪除】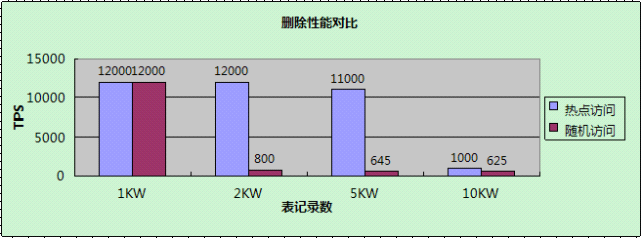
分析如下:
==>和INSERT/UPDATE表現略微不同,當熱點資料小於Innodb buffer pool時,效能變化不大,因為DELETE操作不需要生成新的Page,節省了buffer管理的操作;
==> 當熱點資料大於Innodb buffer pool時,效能下降較大,原因是此時磁碟IO已經成為效能瓶頸。
【總結】
Innodb buffer pool採用LRU的方式管理和淘汰資料,根據LRU演算法,熱點資料都會優先放入記憶體,因此熱點資料的測試效能比隨機訪問的要高出不少。
但熱點資料超出Innodb buffer pool後,磁碟IO成為效能主要瓶頸,效能會急劇下降。
【應用建議】
實際應用中涉及熱點資料訪問時,Innodb是一個高效能的較好的選擇,但前提是要能夠預估熱點資料的大小,只有當熱點資料小於Innodb buffer pool(即熱點資料全部能夠放入記憶體)時,才能夠獲得高效能。
注:
測試資料只為對比用,不代表一般情況下MySQL的效能就這麼高,因為為了能夠對比,測試時做了很多準備工作,測試操作也是比較特殊的
相關推薦
MySQL Innodb資料庫效能實踐——熱點資料效能
對於大部分的應用來說,都存在熱點資料的訪問,即:某些資料在一定時間內的訪問頻率要遠遠高於其它資料。 常見的熱點資料有“最新的新聞”、“最熱門的新聞”、“下載量最大”的電影等。 為了瞭解MySQL In
MySQL Innodb資料庫效能實踐——合適的表記錄數
在實際工作中,經常有同事問道:MySQL Innodb表記錄數多大是合適的? 一般的理解肯定是表越大效能越低,但具體低多少呢,是緩慢下降還是急劇下降,是1000萬就下降還是1億才下降呢? 針對這些問題,我做了一下基準測試,基準測試環境如下: 【硬體配置】 硬體 配置 CPU Intel(R)
windows mysql備份資料庫及清除過期資料
檢視資料庫使用的儲存引擎 MariaDB [(none)]> show engines \G; *************************** 1. row *************************** Engine: CSV Support:
為什麼mysql innodb索引是B+樹資料結構
先從資料結構的角度來答。 題主應該知道B-樹和B+樹最重要的一個區別就是B+樹只有葉節點存放資料,其餘節點用來索引,而B-樹是每個索引節點都會有Data域。這就決定了B+樹更適合用來儲存外部資料,也就是所謂的磁碟資料。 從Mysql(Inoodb)的角度來看,B+樹是用來充當索引的,一般來說索引非常大,尤其是
SpringBoot MySql從資料庫中查出時間資料比實際時間晚八個小時解決方法
springBoot 專案 使用jackson 解析 資料庫中查出時間資料比實際時間晚八個小時 解決方案是因為時區的問題 在配置檔案application.propties 中新增配置spring.jackson.time-zone=GMT+8測試 解決問題
MySQL innoDB資料插入效能優化
起因:有一個innoDB引擎的表Table,在一個大概3000次的foreach迴圈中執行 INSERT INTO Table(columnA, columnB) VALUES (valueA, valueB) 結果居然超出了60S的php執行限制(當然這個限制可以在ph
Mysql資料庫效能優化之查詢效能優化
一、前言:為啥查詢速度會變慢? 通常來說,查詢的生命週期大致分為從客戶端、到伺服器,然後在伺服器上進行解析,生成執行計劃,執行,並返回結果給客戶端。其中執行可以說是最重要的階段,這其中包括了大量為了檢索資料到儲存引擎的呼叫以及呼叫後的資料處理,包括排序和分組等。在每一個消耗大量時間的查
Mysql效能優化之資料型別優化
一、選擇正確的資料型別對於獲得高效能至關重要 1.1更小的通常更好 佔用更少的磁碟、記憶體和CPU快取 1.2儘量避免null 如果查詢中包含可為null的列,對Mysql來說更難優化,因為可為null的列使得索引、索引統計和值都更復雜。會使用更多的儲存空間. 2、整數和實數
mySQL InnoDB 的效能問題討論
https://ncisoft.iteye.com/blog/34676 https://www.douban.com/note/245895324/ MySQL最為人垢病的缺點就是缺乏事務的支援,MyISAM 效能雖然出眾,不是沒有代價的,InnoDB 又如何呢?Inn
MySQL innodb count(*) count(1) 效能比較
EXPLAIN SELECT COUNT(*) FROM gg_bm_o_order; id select_type TABLE TYPE KEY key_len ref ROWS Extra
MySQL的MyISAM和InnoDB的大資料量查詢效能比較
因為工作關係,有一個超過11億記錄的MySQL資料庫,之前一直以為MyISAM引擎的查詢效能會超過InnoDB,這兩天特意測試了一下,不過因為資料量太大,轉換引擎就花了幾天時間。 測試環境: DELL 860伺服器,CPU Xeon3210, 記憶體8G MySQL版本5
關係型資料庫大資料效能優化解決方案之:分表(當前表歷史表)、表分割槽、資料清理原則
原因和目的由於交易量大或者日積月累造成資料庫的資料量越來越大。會導致系統性能大幅下降,所以要對部分業務的表資料作備份和清理減少資料量,來提升請求響應的速度,提升使用者體驗資料是否需要清理的閥值判斷通常當表的磁碟大小超過 5GB,或對於 OLTP 系統(聯機事務處理),表的記錄
Mysql InnoDB 資料更新/刪除導致鎖表
一. 如下對賬表資料結構 create table t_cgw_ckjnl ( CNL_CODE varchar(10) default ' ' not null comment '通道編碼', CNL_PLT_CD varchar(32) default ' ' n
java程式碼實現MySQL資料庫表千萬條資料去重
準備工作: 1.資料庫表:datatest5 2.欄位: id 主鍵自增,val 重複值欄位併為val建立索引 3.設定innodb緩衝池大小 show variables like "%_buffer%"; SET GLOBAL innod
MySQL對資料庫資料進行復制的基本過程詳解
MySQL對資料庫資料進行復制的基本過程詳解 這篇文章主要介紹了MySQL對資料庫資料進行復制的基本過程,解讀了Slave的一些相關配置,需要的朋友可以參考下 複製 複製是從一個MySQL伺服器(master)將資料拷貝到另外一臺或多臺MySQL伺服器(slaves)的過程.複製是非同步進行的--sla
資料效能優化的邏輯順序
原鏈:https://www.zhihu.com/question/19719997 來源:知乎 很多人第一反應是各種切分。 我給的順序是: 第一優化你的sql和索引; 第二加快取,memcached,redis; 第三以上都做了後,還是慢,就做
MySQL更改資料庫資料儲存目錄
MySQL資料庫預設的資料庫檔案位於 /var/lib/mysql 下,有時候由於儲存規劃等原因,需要更改 MySQL 資料庫的資料儲存目錄。下文總結整理了實踐過程的操作步驟。 1 確認MySQL資料庫儲存目錄 1
資料庫SQL實踐34:批量插入資料
思路: 運用insert into 表名 (列名1,列名2,列名3....)values (values1,values2,....),(values1,values2,....)...; 1.當給所有列插入資料時,加粗的列名可以省略不寫 2.每條資料用逗號分隔,從而實現批量插入 i
MySQL資料庫快速造大量資料
這段時間做效能測試,發現數據都是分庫寫進資料庫了,並且要構造大量資料,大概4000萬的資料量,用普通的方法,寫個MySQL函式,之前測試過,大概200萬資料也要跑一個多小時,太慢了. 後面研究發現有個很快的方法, 先寫個Java小工具(這樣比較靈活了, 可以根據自己的需要構造不同的測試資料), 按照分庫規則生
資料庫SQL實踐35:批量插入資料,不使用replace操作
思路: SQLite如果不存在則插入,如果存在則忽略 INSERT OR IGNORE INTO tablename VALUES(...); 如果不存在則插入,如果存在則替換 INSERT OR REPLACE INTO tablename VALUES(...); 這裡指的存