
CUDA8.0安裝和vs2015配置
1、新建空專案
2、新增test.cu
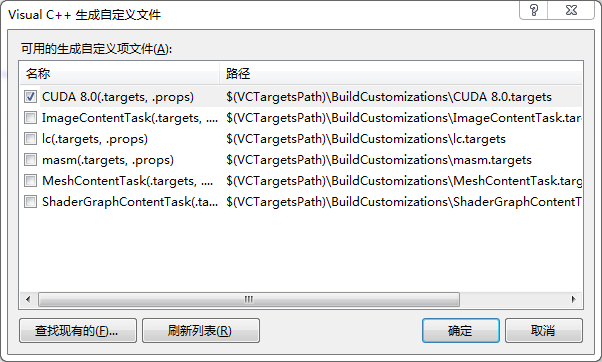
3、右鍵專案---生成依賴項--生成自定義---CUDA8.0打鉤
4、右鍵test.cu---屬性--選擇CUDA C/C++

5、包含目錄
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\include
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\common\inc
6、庫目錄
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\lib\x64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\common\lib\x64
7、輸入
cublas.lib
cublas_device.lib
cuda.lib
cudadevrt.lib
cudart.lib
cudart_static.lib
cufft.lib
cufftw.lib
curand.lib
cusparse.lib
nppc.lib
nppi.lib
npps.lib
nvcuvid.lib
OpenCL.lib
8、新增一個test.h
#pragma once
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
int xx();
9、新增一個main.cpp
#include <iostream>
#include "test.h"
#include <iostream>
#include <fstream>
#include <time.h>
#include <windows.h>
using namespace std;
int main()
{
Mat pad_Img = imread("./data/5X(1).bmp", CV_LOAD_IMAGE_GRAYSCALE);
xx();
return 0;
}
10、test.cu中新增
//#include "cuda_runtime.h"
//#include "device_launch_parameters.h"
//
//#include <stdio.h>
#include "larch_cuda.h"
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int xx()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
c[0], c[1], c[2], c[3], c[4]);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
addKernel << <1, size >> >(dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
11、跑起來

相關推薦
CUDA8.0安裝和vs2015配置
1、新建空專案2、新增test.cu3、右鍵專案---生成依賴項--生成自定義---CUDA8.0打鉤4、右鍵test.cu---屬性--選擇CUDA C/C++5、包含目錄C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\
CentOS6.8下Nagios-4.2.0安裝和配置
因此 figure 問題 usermod linux文件 httpd的配置 pen kconfig etc 1實驗目標 掌握Nagios的安裝 2實驗環境 主機名:Nagios-Server 操作系統:CentOS release 6.8 (Final) IP地址:19
zabbix4.0安裝和配置
以下為master端安裝,開始 核心$ cat /etc/centos-release CentOS Linux release 7.4.1708 (Core) $ uname -r 3.10.0-693.el7.x86_64 IP
linux ubuntu 下 mongodb 4.0 安裝和配置遠端連線
安裝 搬運: 安裝教程 選擇對應版本,複製貼上命令即可,這裡就不涉及了。 安裝完成後啟動服務:sudo service mongod start 如果提示Unit mon
Ubuntu16.04 禁用nouveau驅動和cuda8.0安裝
1.sudo apt-get update 2.sudo gedit /etc/modprobe.d/blacklist.conf (開啟檔案) blacklist nouveau (在檔案中新增該命令,然後儲存退出) sudo update-ini
node.js學習1.0-安裝和配置
1、開啟NodeJS的官網,下載和自己系統相配的NodeJS的安裝程式,包括32位還是64位一定要選擇好,否則會出現安裝問題。 我選擇的是Window版本64位的安裝程式,也有MAC平臺的安裝程式。 下載完成,如圖: 2、接下來就是安裝了,
ubuntu下解除安裝cuda8.0,和安裝cuda9.0,cudnn7.0,tensorflow-gpu=1.8
簡介最近使用tensorflow object detection訓練自己的資料集時,出現了AttributeError: module 'tensorflow.contrib.data' has no attribute 'parallel_interleave'主要的原因
ubuntu16.04 + cuda8.0安裝配置
此次安裝參考了幾位前輩的安裝方法,然後將他們合在一起講述自己的安裝過程: 一.更換ubuntut16.04的源,自己使用的是中科大的源 終端輸入 cd /etc/apt/ sudo cp sources.list sources.list.b
Win10+VS2015+cuda8.0+theano+keras的配置過程
本blog記錄了在windows10下配置theano的過程,以便以後有需要的情況下查詢。 首先說明配置的環境: 1.win10 64bit 2.VS2015 3.Anaconda2 64bit 一、
[親測經驗分享] ubuntu16.04 + cuda8.0安裝配置
1,ubuntu16.04從官網上下載,正常安裝,本人用的是 64位的版本,製作了U盤啟動安裝。 2,nvidia 驅動安裝 如果從nvidia官網下載驅動安裝時,有可能重啟後進入不了系統,輸入我的登入密碼會發現螢幕一閃,然後又重新跳回到登入介面,就是進入了login l
win10+caffe+CUDA8.0安裝配置
安裝配置caffe花了我好長時間,搞得我欲哭無淚,看了網上各種教程,自己配的時候總出現各種各樣的錯誤。 剛開始我裝的是happynear大神的版本,但是之後出現各種問題,看了網上的解決方案也沒解決,所
Spark2.1.0安裝和配置
Spark主要使用HDFS充當持久化層,所以完整地使用Spark需要預先安裝Hadoop Spark在生產環境中,主要部署在安裝Linux系統的叢集中。在Linux系統中安裝Spark需要預先安裝JDK、Scala等所需要的依賴。 由於
Centos7 Redis5.0.5 三主三從叢集安裝和環境配置
Centos7 Redis5.0.5 三主三從叢集安裝和環境配置 1.下載Redis 開啟redis官網https://red
jdk安裝和環境配置
stat png string 改變 ima 繼續 out lib jar public class test{ public static void main(String[] args){ System.out.println("hello w
IDEA 學習筆記之 安裝和基本配置
window eclipse 自動 ref size 工作 ips ctr line 安裝和基本配置: 下載:https://www.jetbrains.com/idea/download/#section=windows 下載Zip安裝包: 基礎知識:
PHP_CodeSniffer 安裝和phpstorm配置
說明 pst bat 安裝 img path sni 點擊 water 安裝 1.mac安裝 sudo pear install PHP_CodeSniffer phpstorm配置 1. 點擊菜單:File->Settings 或 按快捷鍵 Ctrl+Alt+S 2
Puppet的安裝和初配置
puppet一、前言:Puppet是Puppet Labs基於ruby語言開發的自動化系統配置工具,可以以C/S模式或獨立模式運行,支持對所有UNIX及類UNIX系統的批量配置和管理,最新版本也開始支持對Windows操作系統有限的一些管理。Puppet適用於服務器管理的整個過程,比如初始安裝、配置、更新以及
Python2.7.14安裝和pip配置安裝及虛擬環境搭建
%20 環境變量path 網上 之前 安裝文件 script 記得 關於 過程 目錄 前言 1 Python2.7.14安裝 2 pip配置安裝 3 虛擬環境安裝 前言 今天在搭建阿裏雲服務器,需要安裝Python相關環境,之前在本機都已
1. PostgreSQL-安裝和基本配置(學習筆記)
安裝和配置 日常使用 buffer java、 note 安裝完成 for ora har 1 PostgreSQL簡介1.1 概述??PostgreSQL數據庫是目前功能最強大的開源數據庫,支持豐富的數據類型(如JSON和JSONB類型,數組類型)和自定義類型。而且它提供
nodejs之路-[0]安裝及簡易配置
路徑 AC 創建 環境 開篇 nload ubun 版本 .net 題外話: 之前寫過ubuntu下編譯nodejs… 傳送門:Ubuntu15.04編譯安裝no