
solr和hbase結合進行索引搜尋
solrcloud叢集情況
solrcloud叢集已經安裝完成。
solr版本:5.5.0,zookeeper版本:3.4.6
solr的操作使用者、密碼: solr/solr123
solr使用的zookeeper安裝位置:/opt/zookeeper-3.4.6
solr安裝位置:/opt/solr-5.5.0
solr埠:8983
zookeeper埠:9983
5臺機器,每臺機器上安裝的都有solr和zookeeperzookeeper啟動:/opt/zookeeper-3.4.6/bin/zkServer.sh start zookeeper停止:/opt/zookeeper-3.4.6/bin/zkServer.sh stop zookeeper狀態:/opt/zookeeper-3.4.6/bin/zkServer.sh status solr啟動:/opt/solr-5.5.0/bin/solr start solr停止:/opt/solr-5.5.0/bin/solr stop solr狀態:/opt/solr-5.5.0/bin/solr status solr訪問:http://10.1.202.67:8983/solr/ http://10.1.202.68:8983/solr/ http://10.1.202.69:8983/solr/ http://10.1.202.70:8983/solr/ http://10.1.202.71:8983/solr/複製IK分詞到solr中
注意:IK分詞不要用之前IKAnalyzer2012FF_u1.jar的版本,以前版本不支援solr5.0以上,需要用IKAnalyzer2012FF_u2.jar,或者在github上下載原始碼,然後自己編譯,github連線如下:
https://github.com/EugenePig/ik-analyzer-solr5/blob/master/README.md
本人用的是自己編譯的ik分詞包Ik-analyzer-solr5-5.x.jar
scp ./Ik-analyzer-solr5-5.x.jar [email protected]:/opt/solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib
scp ./Ik-analyzer-solr5-5.x.jar[email protected]:/opt/solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib
scp ./Ik-analyzer-solr5-5.x.jar [email protected]:/opt/solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib
scp ./Ik-analyzer-solr5-5.x.jar [email protected]:/opt/solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib
scp ./Ik-analyzer-solr5-5.x.jar[email protected]:/opt/solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib3.managed-schema修改
solr5.5.0版本已經沒有schema.xml的檔案,替代用的是managed-schema,在solr-5.5.0/server/solr/configsets/目錄下,在此目錄下複製sample_techproducts_configs資料夾,命令如下:
cp sample_techproducts_configs poc_configs
編輯poc_configs/conf/managed-schema 增加ik分詞欄位型別和ik分詞欄位
vim managed-schema
<fields>
<field name="title_ik" type="text_general" indexed="true" stored="true"/>
<field name="content_ik" type="text_ik" indexed="true" stored="false"/>
<field name="content_outline" type="text_general" indexed="false" stored="true"/>
</fields>
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>注:content_ik欄位太長,不能夠儲存檔案,只能生產索引,也沒有必要儲存原文,導致資料量加大,搜尋可能會受影響,內容的前50個欄位截取出來儲存到content_outline,方便檢視內容的大致內容
重啟solr伺服器
./solr_stop_all.sh
#!/bin/bash
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin
slaves="dn-1 dn-2 dn-3 dn-4 dn-5"
cmd="/opt/solr-5.5.0/bin/solr stop"
for slave in $slaves
do
echo $slave
ssh $slave $cmd
done./solr_start_all.sh
#!/bin/bash
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin
slaves="dn-1 dn-2 dn-3 dn-4 dn-5"
cmd="/opt/solr-5.5.0/bin/solr start"
for slave in $slaves
do
echo $slave
ssh $slave $cmd
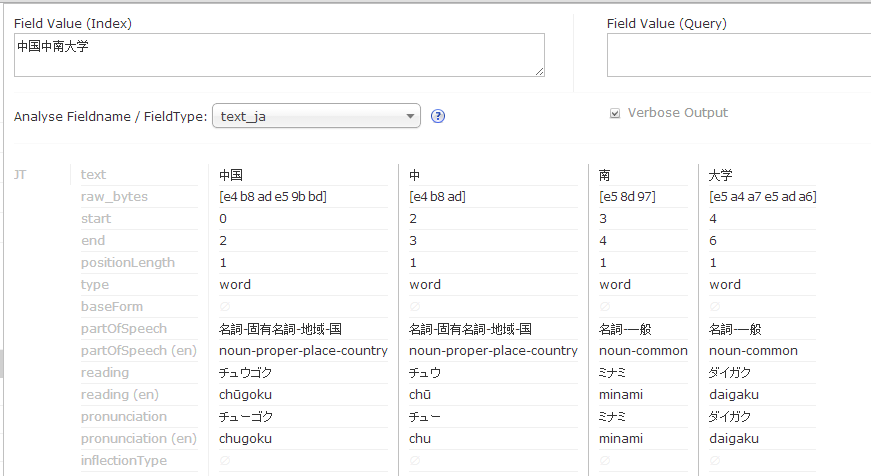
done分詞測試
使用text_ik分詞:
- 建立collection
編輯完成後可以建立collection,命令如下:
/opt/solr-5.5.0/bin/solr create -c collection1 -d /opt/solr-5.5.0/server/solr/configsets/poc_configs/conf -shards 5 -replicationFactor 2
建立完成後在訪問頁面出現一下內容:
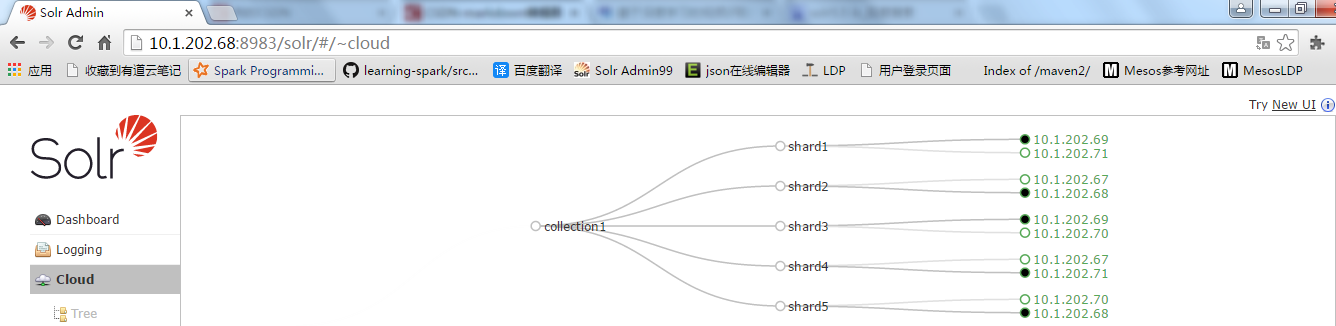
配置檔案並不會生成到solr目錄下,而是增加到zookeeper上
連線zookeeper
/opt/zookeeper-3.4.6/bin/zkCli.sh -server 10.1.202.67:9983

當建立失敗collection時,可以通過命令刪除,命令如下:
/opt/solr-5.5.0/bin/solr delete -c collection1 -deleteConfig true
注:-deleteConfig true是刪除zookeeper上的配置檔案,防止下次建立時直接用此配置項或者報錯
如果還是不行,那說明zookeeper上的配置檔案沒有刪除,直接登入zookeeper,通過rmr /configs/collection1命令刪除配置項。編寫solrCloud通過mapreduce讀取hbase的欄位生成索引
主方法:
public class SolrHBaseMoreIndexer {
public static Logger logger = LoggerFactory.getLogger(SolrHBaseMoreIndexer.class);
private static void hadoopRun(String[] args){
String tbName = ConfigProperties.getHBASE_TABLE_NAME();
try {
Job job = new Job(ConfigProperties.getConf(), "SolrHBaseMoreIndexer");
job.setJarByClass(SolrHBaseMoreIndexer.class);
Scan scan = new Scan();
//開始和結束並不是ID,而是hbase的rowkey,rowkey是通過數字排序,而是通過字串進行排序,所以109在1000的後面,即1 。。。1000 。。。109
scan.setStartRow(Bytes.toBytes("1"));
scan.setStopRow(Bytes.toBytes("109"));
for(String tbFamily:ConfigProperties.getHBASE_TABLE_FAMILY().split(",")){
scan.addFamily(Bytes.toBytes(tbFamily));
logger.info("tbName:"+tbName+",tbFamily:"+tbFamily);
}
scan.setCaching(500); // 設定快取資料量來提高效率
scan.setCacheBlocks(false);
// 建立Map任務
TableMapReduceUtil.initTableMapperJob(tbName, scan,
SolrHBaseMoreIndexerMapper.class, null, null, job);
// 不需要輸出
job.setOutputFormatClass(NullOutputFormat.class);
// job.setNumReduceTasks(0);
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
logger.error("hadoopRun異常", e);
}
}
public static void main(String[] args) throws IOException,
InterruptedException, ClassNotFoundException, URISyntaxException {
SolrHBaseMoreIndexer.hadoopRun(args);
}
}mapper方法:
public class SolrHBaseMoreIndexerMapper extends TableMapper<Text, Text> {
CloudSolrClient cloudSolrServer;
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
cloudSolrServer=SolrServerFactory.getCloudSolrClient();
}
@Override
protected void cleanup(Context context
) throws IOException, InterruptedException {
try {
cloudSolrServer.commit(true, true, true);
cloudSolrServer.close();
} catch (SolrServerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static Logger logger = LoggerFactory.getLogger(SolrHBaseMoreIndexerMapper.class);
public void map(ImmutableBytesWritable key, Result hbaseResult,
Context context) throws InterruptedException, IOException {
SolrInputDocument solrDoc = new SolrInputDocument();
try {
solrDoc.addField("id", new String(hbaseResult.getRow()));
logger.info("id:"+new String(hbaseResult.getRow()));
for (KeyValue rowQualifierAndValue : hbaseResult.list()) {
String fieldName = new String(rowQualifierAndValue.getQualifier());
String family = new String(rowQualifierAndValue.getFamily());
String fieldValue = new String(rowQualifierAndValue.getValue());
if(family.equals("content")){
solrDoc.addField("content_outline",fieldValue.length()>50?fieldValue.substring(0, 50)+"...":fieldValue);
}
for(String tbFamily:ConfigProperties.getHBASE_TABLE_FAMILY().split(",")){
if(family.equals(tbFamily))solrDoc.addField(tbFamily+"_ik", fieldValue);
}
}
//1分鐘提交一次,防止每次提交影響效率
cloudSolrServer.add(null,solrDoc,60000);
} catch (SolrServerException e) {
logger.error("更新Solr索引異常:" + new String(hbaseResult.getRow()),e);
}
}
}配置檔案讀取類:
public class ConfigProperties {
public static Logger logger = LoggerFactory.getLogger(ConfigProperties.class);
private static Properties props;
private static String HBASE_ZOOKEEPER_QUORUM;
private static String HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT;
private static String HBASE_MASTER;
private static String HBASE_ROOTDIR;
private static String DFS_NAME_DIR;
private static String DFS_DATA_DIR;
private static String FS_DEFAULT_NAME;
private static String HBASE_TABLE_NAME; // 需要建立Solr索引的HBase表名稱
private static String HBASE_TABLE_FAMILY; // HBase表的列族
private static String QUERY_FIELD;
private static String SOLR_ZOOKEEPER;
private static String SOLRCLOUD_SERVER1;
private static String SOLRCLOUD_SERVER2;
private static String SOLRCLOUD_SERVER3;
private static String SOLRCLOUD_SERVER4;
private static String SOLRCLOUD_SERVER5;
private static String wordsFilePath;
private static String querySeparator;
private static String COLLECTION;
private static boolean isQueryContent;
private static Configuration conf;
/**
* 從配置檔案讀取並設定HBase配置資訊
*
* @param propsLocation
* @return
*/
static {
props = new Properties();
try {
InputStream in = ConfigProperties.class.getClassLoader().getResourceAsStream("config.properties");
props.load(new InputStreamReader(in,"UTF-8"));
HBASE_ZOOKEEPER_QUORUM = props.getProperty("HBASE_ZOOKEEPER_QUORUM");
HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT = props.getProperty("HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT");
HBASE_MASTER = props.getProperty("HBASE_MASTER");
HBASE_ROOTDIR = props.getProperty("HBASE_ROOTDIR");
DFS_NAME_DIR = props.getProperty("DFS_NAME_DIR");
DFS_DATA_DIR = props.getProperty("DFS_DATA_DIR");
FS_DEFAULT_NAME = props.getProperty("FS_DEFAULT_NAME");
HBASE_TABLE_NAME = props.getProperty("HBASE_TABLE_NAME");
HBASE_TABLE_FAMILY = props.getProperty("HBASE_TABLE_FAMILY");
QUERY_FIELD = props.getProperty("QUERY_FIELD");
SOLR_ZOOKEEPER = props.getProperty("SOLR_ZOOKEEPER");
SOLRCLOUD_SERVER1= props.getProperty("SOLRCLOUD_SERVER1");
SOLRCLOUD_SERVER2= props.getProperty("SOLRCLOUD_SERVER2");
SOLRCLOUD_SERVER3= props.getProperty("SOLRCLOUD_SERVER3");
SOLRCLOUD_SERVER4= props.getProperty("SOLRCLOUD_SERVER4");
SOLRCLOUD_SERVER5= props.getProperty("SOLRCLOUD_SERVER5");
wordsFilePath= props.getProperty("wordsFilePath");
querySeparator= props.getProperty("querySeparator");
isQueryContent=Boolean.parseBoolean(props.getProperty("isQueryContent","false"));
COLLECTION= props.getProperty("COLLECTION");
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", HBASE_ZOOKEEPER_QUORUM);
conf.set("hbase.zookeeper.property.clientPort",HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT);
conf.set("hbase.master", HBASE_MASTER);
conf.set("hbase.rootdir", HBASE_ROOTDIR);
conf.set("mapreduce.job.user.classpath.first","true");
conf.set("mapreduce.task.classpath.user.precedence","true");
} catch (IOException e) {
logger.error("載入配置檔案出錯",e);
} catch (NullPointerException e) {
logger.error("載入檔案出錯",e);
}catch (Exception e) {
logger.error("載入配置檔案出現位置異常",e);
}
}
public static Logger getLogger() {
return logger;
}
public static Properties getProps() {
return props;
}
public static String getHBASE_ZOOKEEPER_QUORUM() {
return HBASE_ZOOKEEPER_QUORUM;
}
public static String getHBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT() {
return HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT;
}
public static String getHBASE_MASTER() {
return HBASE_MASTER;
}
public static String getHBASE_ROOTDIR() {
return HBASE_ROOTDIR;
}
public static String getDFS_NAME_DIR() {
return DFS_NAME_DIR;
}
public static String getDFS_DATA_DIR() {
return DFS_DATA_DIR;
}
public static String getFS_DEFAULT_NAME() {
return FS_DEFAULT_NAME;
}
public static String getHBASE_TABLE_NAME() {
return HBASE_TABLE_NAME;
}
public static String getHBASE_TABLE_FAMILY() {
return HBASE_TABLE_FAMILY;
}
public static String getQUERY_FIELD() {
return QUERY_FIELD;
}
public static String getSOLR_ZOOKEEPER() {
return SOLR_ZOOKEEPER;
}
public static Configuration getConf() {
return conf;
}
public static String getSOLRCLOUD_SERVER1() {
return SOLRCLOUD_SERVER1;
}
public static void setSOLRCLOUD_SERVER1(String sOLRCLOUD_SERVER1) {
SOLRCLOUD_SERVER1 = sOLRCLOUD_SERVER1;
}
public static String getSOLRCLOUD_SERVER2() {
return SOLRCLOUD_SERVER2;
}
public static void setSOLRCLOUD_SERVER2(String sOLRCLOUD_SERVER2) {
SOLRCLOUD_SERVER2 = sOLRCLOUD_SERVER2;
}
public static String getSOLRCLOUD_SERVER3() {
return SOLRCLOUD_SERVER3;
}
public static void setSOLRCLOUD_SERVER3(String sOLRCLOUD_SERVER3) {
SOLRCLOUD_SERVER3 = sOLRCLOUD_SERVER3;
}
public static String getSOLRCLOUD_SERVER4() {
return SOLRCLOUD_SERVER4;
}
public static void setSOLRCLOUD_SERVER4(String sOLRCLOUD_SERVER4) {
SOLRCLOUD_SERVER4 = sOLRCLOUD_SERVER4;
}
public static String getSOLRCLOUD_SERVER5() {
return SOLRCLOUD_SERVER5;
}
public static void setSOLRCLOUD_SERVER5(String sOLRCLOUD_SERVER5) {
SOLRCLOUD_SERVER5 = sOLRCLOUD_SERVER5;
}
public static String getCOLLECTION() {
return COLLECTION;
}
public static void setCOLLECTION(String cOLLECTION) {
COLLECTION = cOLLECTION;
}
public static String getWordsFilePath() {
return wordsFilePath;
}
public static String getQuerySeparator() {
return querySeparator;
}
public static void setQuerySeparator(String querySeparator) {
ConfigProperties.querySeparator = querySeparator;
}
public static boolean getIsQueryContent() {
return isQueryContent;
}
}config.properties配置檔案:
HBASE_ZOOKEEPER_QUORUM=10.1.202.67,10.1.202.68,10.1.202.69
HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT=2181
HBASE_MASTER=10.1.202.67:16000,10.1.202.68:16000
HBASE_ROOTDIR=hdfs://ocdpCluster/apps/hbase/data
DFS_NAME_DIR=/hadoop/hdfs/namenode
DFS_DATA_DIR=/data1/hadoop/hdfs/data,/data2/hadoop/hdfs/data,/data3/hadoop/hdfs/data,/data4/hadoop/hdfs/data,/data5/hadoop/hdfs/data,/data6/hadoop/hdfs/data,/data7/hadoop/hdfs/data
FS_DEFAULT_NAME=hdfs://ocdpCluster
HBASE_TABLE_NAME=td_poc_dynamic_info
HBASE_TABLE_FAMILY=title,content
QUERY_FIELD=content_ik:公司
SOLR_ZOOKEEPER=10.1.202.67:9983,10.1.202.68:9983,10.1.202.69:9983,10.1.202.70:9983,10.1.202.71:9983
SOLRCLOUD_SERVER1=http://10.1.202.67:8983/solr/
SOLRCLOUD_SERVER2=http://10.1.202.68:8983/solr/
SOLRCLOUD_SERVER3=http://10.1.202.69:8983/solr/
SOLRCLOUD_SERVER4=http://10.1.202.70:8983/solr/
SOLRCLOUD_SERVER5=http://10.1.202.71:8983/solr/
COLLECTION=collection1
wordsFilePath=/usr/local/pocProject/queryProject2/querywords.txtpom依賴包
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.1.2</version>
</dependency>
<dependency>
<version>1.6.6</version>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</dependency>
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>5.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-server -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.1.2</version>
</dependency>
</dependencies>建立solrcloud連線:
public class SolrServerFactory {
public static Logger logger = LoggerFactory.getLogger(SolrServerFactory.class);
private static CloudSolrClient cloudSolrServer;
public static synchronized CloudSolrClient getCloudSolrClient(){
if(cloudSolrServer==null){
logger.info("cloudSolrServer怎麼還是空");
createCloudSolrClient();
}
return cloudSolrServer;
}
private static void createCloudSolrClient(){
ModifiableSolrParams params = new ModifiableSolrParams();
params.set(HttpClientUtil.PROP_MAX_CONNECTIONS, 100);//10
params.set(HttpClientUtil.PROP_MAX_CONNECTIONS_PER_HOST, 20);//5
HttpClient httpClient = HttpClientUtil.createClient(params);
LBHttpSolrClient lbHttpSolrClient = new LBHttpSolrClient(httpClient, ConfigProperties.getSOLRCLOUD_SERVER1(),
ConfigProperties.getSOLRCLOUD_SERVER2(),ConfigProperties.getSOLRCLOUD_SERVER3(),
ConfigProperties.getSOLRCLOUD_SERVER4(),ConfigProperties.getSOLRCLOUD_SERVER5());
cloudSolrServer = new CloudSolrClient(ConfigProperties.getSOLR_ZOOKEEPER(),lbHttpSolrClient);
cloudSolrServer.setDefaultCollection(ConfigProperties.getCOLLECTION());
// cloudSolrServer.setZkClientTimeout(SearchConfig.getZookeeperClientTimeout());
// cloudSolrServer.setZkConnectTimeout(SearchConfig.getZookeeperConnectTimeout());
}
}
hbase連線
public class HbaseConnectionFactory {
private static Connection connection = null;
public static synchronized Connection getHTable(){
if(connection ==null){
try {
connection = ConnectionFactory.createConnection(ConfigProperties.getConf());
} catch (IOException e) {
e.printStackTrace();
}
}
return connection;
}
public static Connection getConnection() {
return connection;
}
}
查詢程式碼如下:
public class QueryData {
public static Logger logger = LoggerFactory.getLogger(ConfigProperties.class);
/**
* @param args
* @throws SolrServerException
* @throws IOException
*/
public static void main(String[] args) throws SolrServerException, IOException {
CloudSolrClient cloudSolrServer=SolrServerFactory.getCloudSolrClient();
SolrQuery query = new SolrQuery(new String(ConfigProperties.getQUERY_FIELD()));
query.setStart(0); //資料起始行,分頁用
query.setRows(10); //返回記錄數,分頁用
QueryResponse response = cloudSolrServer.query(query);
SolrDocumentList docs = response.getResults();
System.out.println("文件個數:" + docs.getNumFound()); //資料總條數也可輕易獲取
System.out.println("查詢時間:" + response.getQTime());
cloudSolrServer.close();
HTable table = new HTable(ConfigProperties.getConf(), ConfigProperties.getHBASE_TABLE_NAME());
Get get = null;
List<Get> list = new ArrayList<Get>();
for (SolrDocument doc : docs) {
logger.info("查詢出ID為:"+(String) doc.getFieldValue("id"));
get = new Get(Bytes.toBytes((String) doc.getFieldValue("id")));
list.add(get);
}
Result[] res = table.get(list);
logger.info("查詢出資料個數:"+res.length);
byte[] titleBt = null;
byte[] contentBt = null;
String title = null;
String content = null;
for (Result rs : res) {
if(rs.getRow()==null){
return;
}
titleBt = rs.getValue("title".getBytes(), "".getBytes());
contentBt = rs.getValue("create_date".getBytes(), "".getBytes());
if (titleBt != null && titleBt.length>0) {title = new String(titleBt);} else {title = "無資料";} //對空值進行new String的話會丟擲異常
if (contentBt != null && contentBt.length>0) {content = new String(contentBt);} else {content = "無資料";}
logger.info("id:"+new String(rs.getRow()));
logger.info("title"+title + "|");
logger.info("content"+content + "|");
}
table.close();
}
}
最好在執行時把hdfs-site.xml和hbase-site.xml放入配置檔案中
相關推薦
solr和hbase結合進行索引搜尋
solrcloud叢集情況 solrcloud叢集已經安裝完成。 solr版本:5.5.0,zookeeper版本:3.4.6 solr的操作使用者、密碼: solr/solr123 solr使用的zookeeper安裝位置:/
elasticsearch(一)java 分別使用同步和非同步方法進行索引、更新操作
一、索引或更新基本步驟 1) 建立與elasticsearch服務進行連線的RestHighLevelClient物件 RestHighLevelClient client = new RestHighLevelClient( Res
Unity--PropertyAttribute和PropertyDrawer結合進行配置引用
應用場景,類中引用配置表中的技能id,程式碼如下圖 public class PropertyTest : MonoBehaviour { public string prefabPath = ""; //配置表中的技能id public int s
使用PIN和OD結合進行指令的修改
前言 在經過一次又一次的失敗之後,終於接受了pin不能實現取完整指令,更改,再放回去的實驗要求。 在同學的提一下,我開始了對OlleyDBG的摸索。目前的思路就是,用pin得到CFG,也就是每條分支指令的地址及其目的地址的地址,然後使用OD來進行指令的修改。由
自學大資料:基於Solr實現HBase的文字索引
前言 最近接觸的專案中,需要針對HBase的資料進行索引查詢,主要支援中文查詢,分頁查詢等。在此情況下,學習了搜尋伺服器solr。總結了一些方法和經驗,正好可以分享個大家,鼓勵自己,共同學習。 使用目的 HBase目前只支援對rowkey的一級索引,對於二級索引還不支援,
利用Solr建立HBase的二級索引
public void insertSolr(Put put) { CloudSolrServer cloudSolrServer; final String zkHost = "IP:2181,IP:2181,IP:2181"; final int zkConnectTimeout = 1;
HBase建表高階屬性,hbase應用案例看行鍵設計,HBase和mapreduce結合,從Hbase中讀取資料、分析,寫入hdfs,從hdfs中讀取資料寫入Hbase,協處理器和二級索引
1. Hbase高階應用 1.1建表高階屬性 下面幾個shell 命令在hbase操作中可以起到很到的作用,且主要體現在建表的過程中,看下面幾個create 屬性 1、 BLOOMFILTER 預設是NONE 是否使用布隆過慮及使用何種方式 布隆
利用selenium和Chrome瀏覽器進行自動化網頁搜尋與瀏覽
轉自:https://www.cnblogs.com/liangxuehui/p/5797185.html 功能簡介:利用利用selenium和Chrome瀏覽器,讓其自動開啟百度頁面,並設定為每頁顯示50條,接著在百度的搜尋框中輸入selenium,進行查詢。然後再開啟的頁面中選中“Selenium
Spark SQL中使用StringIndexer和IndexToString來對字串資訊進行索引和反索引
簡介 本篇部落格使用Kaggle上的AdultBase資料集:Machine-Learning-Databases 此資料集雖然歷史比較悠久,但是資料格式比較容易處理,而且資訊比較全面,適合資料處理入門。 本篇部落格使用了Spark SQL的相關語句,實現了以下
用Amber進行能量分解和計算結合自由能——MMPBSA工具
用Amber進行能量分解和計算結合自由能 First release:2018-01-13 Last update: 2018-03-17 Amber是一款適用於生物大分子的動力學模擬的軟體,其官方網站是http://ambermd.org/index.html,目
JavaWeb中利用ModelAndView 和SpringMVC中結合進行資料渲染
package com.by.model; public class testresModel {public int top;public int left;public int width;public int height;public testresModel(){}public void setTo
SQL Server 使用全文索引進行頁面搜尋
建立全文索引 啟動服務 在SQL Server配置管理工具中,找到'SQL Full-text Filter Daemon Launcher'服務用本地使用者啟動。 建立全文目錄 開啟需要建立全文目錄的資料庫-儲存-全文目錄-右鍵新建全文目錄 用語句建立全文目錄 CREA
【Lucene4.8教程之一】使用Lucene4.8進行索引及搜尋的基本操作
在Lucene對文字進行處理的過程中,可以大致分為三大部分: 1、索引檔案:提取文件內容並分析,生成索引 2、搜尋內容:搜尋索引內容,根據搜尋關鍵字得出搜尋結果 3、分析內容:對搜尋詞彙進行分析,生成Quey物件。 注:事實上,除了最基本的完全匹配搜尋以外,其它都需要在
基於Solr的Hbase二級索引
關於Hbase二級索引 HBase 是一個列存資料庫,每行資料只有一個主鍵RowKey,無法依據指定列的資料進行檢索。查詢時需要通過RowKey進行檢索,然後檢視指定列的資料是什麼,效率低下。在實際應用中,我們經常需要根據指定列進行檢索,或者幾個列進行組合檢索,這就提出
solr配置增量更新和定時更新資料庫索引
################################################# # # # dataimport scheduler properties # #
【轉載】Hadoop 2.7.3 和Hbase 1.2.4安裝教程
啟動 運行 property new rop net 文本文 .tar.gz cor 轉載地址:http://blog.csdn.net/napoay/article/details/54136398 目錄(?)[+] 一、機器環境
Hive和Hbase的區別
缺點 每一個 oop 設備 actions 利用 計數 映射 編寫 1. 兩者分別是什麽? Apache Hive是一個構建在Hadoop基礎設施之上的數據倉庫。通過Hive可以使用HQL語言查詢存放在HDFS上的數據。HQL是一種類SQL語言,這種語言最終被轉化為M
Sprint.Net和Mvc結合使用
system http ram container userinfo sprint provider let pri 主要步驟如下 1.UI層中添加連接字符串 從Model層中復制 <connectionStrings> <add name="Da
另一種的SQL註入和DNS結合的技巧
其中 where ets 鏈接 是我 例如 .com bar 導致 這個技巧有些另類,當時某業界大佬提點了一下。當時真的真的沒有理解到那種程度,現在可能也是沒有理解到,但是我會努力。 本文章是理解於:http://netsecurity.51cto.com/art/2015
HDFS的快照原理和Hbase基於快照的表修復
才會 vertical 根據 註意 efault 失敗 機制 soft hot 前一篇文章《HDFS和Hbase誤刪數據恢復》主要講了hdfs的回收站機制和Hbase的刪除策略。根據hbase的刪除策略進行hbase的數據表恢復。本文主要介紹了hdfs的快照原理和根據快照進