
mysql和oracle的一個漢字佔幾個字元
以前一直使用oracle11g,一個漢字佔3個位元組,所以在操作mysql時也一直這樣分配長度。
今天測試了下發現不對了
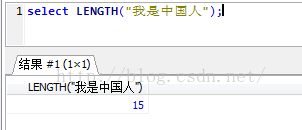
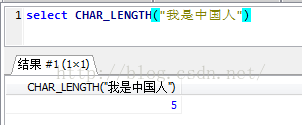
可以看到第一個的長度確實是15,但是第二個為什麼是5?
在網上找到資料:char_length計算的是字元長度,而length計算的是位元組長度,剛好我使用的是utf8,一個漢字佔3個位元組,佔一個字元。

那好了,應該是對的上了,可是好奇心我就試了下
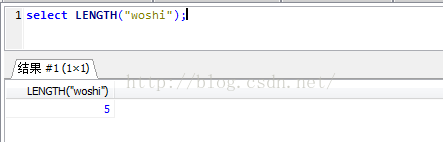
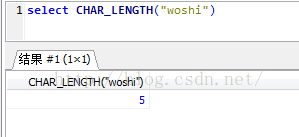
為什麼這是相同的?因為這不是漢字
好了,現在知道原來mysql和oracle一樣的,但是又看到一篇說mysql的varchar與oracle的varchar2是不一樣的,前者是用字元做單位的,後者是用位元組做單位的。對於
總結:oracle 中varchar2(10) 既10個位元組3個漢字
mysql 中varchar(10) 既10個字元10個漢字
所以現在可以將mysql的varchar欄位減小1/3了,效能也能提高哦。
相關推薦
mysql和oracle的一個漢字佔幾個字元
以前一直使用oracle11g,一個漢字佔3個位元組,所以在操作mysql時也一直這樣分配長度。 今天測試了下發現不對了 可以看到第一個的長度確實是15,但是第二個為什麼是5? 在網上找到資料:c
utf-8 中的一個漢字佔幾個位元組
utf-8 中的一個漢字佔幾個位元組 佔 2 個位元組的:〇 佔 3 個位元組的:基本等同於 GBK,含 21000 多個漢字 佔 4 個位元組的:中日韓超大字符集裡面的漢字,有 5 萬多個 1 個 utf8 數字佔 1 個位元組 1 個 utf8 英文字母佔 1 個位元
一個漢字佔幾個位元組
一個漢字佔幾個字元/位元組? 2個,還是3個字元呢? 其實一個漢字可能會佔2~4個字元,佔幾個字元取決於你採用的什麼編碼。漢字在GBK/GB2312編碼中佔2個位元組,在UTF-8/unicode中一般佔用3個位元組(或2~4位元組)。 暫時
ORACLE 中漢字佔幾個位元組?
一直認為中文再oracle中也是佔用兩個字元(一個字元佔用一個位元組),寫pl/sql的時候報緩衝區溢位,被同事糾正,一個漢字不止佔用2個位元組,根據引數的不同,可能佔用多個(2~4個)。 可以用下面的sql: SELECT * FROM v$nls_par
關於Oracle一個漢字代表幾個位元組的問題
在Oracle定義變數時,常有VARCHAR2 (3 Char)或者VARCHAR2 (10 Byte)的資料型別,那麼3char或者10Byte到底代表幾個漢字,幾個字元呢,上次外公司一同事討論這個問題,一下沒給解釋清楚,所以下來以後整理如下: 總結: 當NLS_CHAR
Java一個漢字佔幾個位元組(詳解與原理)
1、先說重點: 不同的編碼格式佔位元組數是不同的,UTF-8編碼下一個中文所佔位元組也是不確定的,可能是2個、3個、4個位元組; 2、以下是原始碼: 1 @Test 2 public void test1() throws UnsupportedEncodingE
mysql和oracle的一個漢字占幾個字符
技術分享 AR == details 應該 gravity 為什麽 tail 計算 轉自:http://blog.csdn.net/u011575570/article/details/47414513 以前一直使用oracle11g,一個漢字占3個字節,所以在操作mysq
utf-8的中文是一個漢字佔三個位元組長度嗎?
英文字母:位元組數 : 1;編碼:GB2312位元組數 : 1;編碼:GBK位元組數 : 1;編碼:GB18030位元組數 : 1;編碼:ISO-8859-1位元組數 : 1;編碼:UTF-8位元組數 : 4;編碼:UTF-16位元組數 : 2;編碼:UTF-16BE位元組數 : 2;編碼:UTF-16LE中
JS判斷字串長度(英文佔1個字元,中文漢字佔2個字元)
//計算字串長度(英文佔1個字元,中文漢字佔2個字元) 方法一: [javascript] view plain copy String.prototype.gblen = function() { var len = 0;
Java 一個數字、字母、漢字各佔幾個位元組
漢字字元 2位元組 英文字元 1位元組 中文標點 2位元組 英文標點 1位元組 中國字比較複雜,1位元組=8位,8位從0000 0000到1111 1111只能表示256個字元,2個位元組是2*8=16位,從0000 0000 0000 0000到1111 11
python通過一個語句分析幾個常用函數和概念
完全 1.4 優點 難解 實現 word 開篇 iter 執行 前言 過年也沒完全閑著,每天用一點點時間學點東西,本文為大家介紹幾個python操作的細節,包含all、any、for in等操作,以及介紹我解決問題的思路。 一、開篇 先從我看到的一個簡單的語句開始。 tex
mysql和oracle查詢出的一條結果中的多個欄位拼接
1,mysql concat('a','b','c')和concat_ws('a','b','c')的區別:前者如果有某個值為空,結果為空;後者如果有某個值為空,可以忽略這個控制 SELECT concat_ws('',FORE_TWO,THIRD_POSITION,FOURTH_POSIT
Oracle 將一個表中幾個欄位更新到另一個表中
UPDATE TEST_TABLE1 T1 SET (T1.AA, T1.BB, T1.CC) =
一個字元佔幾個位元組
ASCII碼: 一個英文字母(不分大小寫)佔一個位元組的空間,一箇中文漢字佔兩個位元組的空間。一個二進位制數字序列,在計算機中作為一個數字單元,一般為8位二進位制數,換算為十進位制。最小值0,最大值255。如一個ASCII碼就是一個位元組。 UTF-8編碼: 一個英文字元等於一個位元
Java語言中一個字元佔幾個位元組?
要區分清楚內碼(internal encoding)和外碼(external encoding)就好了。 內碼是程式內部使用的字元編碼,特別是某種語言實現其char或String型別在記憶體裡用的內部編碼; 外碼是程式與外部互動時外部使用的字元編碼。“外部”相對“內部”而言;不是char或Str
漢字佔兩個位元組,字元佔一個位元組,不設定寬度限制文字的長度
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width,initia
java裡面一個字元佔幾個位元組?
java的字元型別 char 佔用2個直接,因為他是Unicode編碼 Java簡單資料型別 簡單型別 大小 範圍/精度 float 4 位元組 32位IEEE 754單精度 double 8 位元組 64位IEEE 754雙精度 byte 1位元組 -128到127
擷取字串,漢字佔兩個位元組,字母佔一個位元組
/* * 頁面編碼必須為utf-8 */ function esub($str, $length = 0, $ext = "...") { if ($length < 1) { return $str; } //計
php中按位元組擷取字串方法,(漢字佔兩個位元組,字母佔一個位元組,頁面編碼必須為utf-8)
function esub($str, $length = 0) { if($length < 1){ return $str; } //計算字串長度 $strlen = (strlen($str) + mb_str
java 中一個char包含幾個字節
導致 sdn col 會有 2個 tar 防止 clas 記得 背景 ??char包含幾個字節可能記得在上學的時候書上寫的是2個字節,一直沒有深究,今天我們來探究一下到底一個char多少個字節? Char ??char在設計之初的時候被用來存儲字符,可是世界上有那麽多字符,